0、引言
在很多应用场景中,我们会将富文本内容(如 HTML 格式的网页内容)存储到 Elasticsearch 中,以实现全文检索。
然而,在实际使用过程中,我们可能会遇到一些问题,比如在检索时,HTML 标签被截断,或者检索结果中会显示部分 HTML 标签内容。这种现象不仅影响了检索体验,还可能对页面展示造成困扰。
本文将详细介绍如何解决这种富文本处理中的常见问题,帮助大家在使用 Elasticsearch 时更加高效地处理和展示富文本内容。
1、具体问题描述
Elasticsearch 所存储的数据包含但不限于:
业务数据
日志数据
互联网采集数据
其他数据 如果遇到互联网采集数据场景,Elasticsearch 的 content 字段极大可能需要存储的是富文本内容(HTML)。
遇到这种情况,咱们得非常的慎重。
不信,你看!如下 QQ 群群友出现的问题可见一斑。
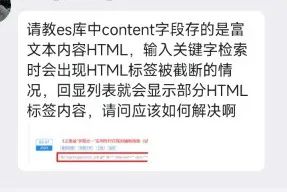
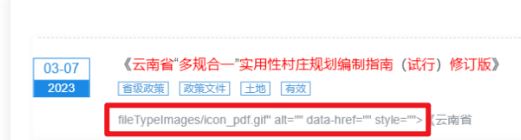
什么问题呢?
在输入关键词进行检索时,可能会出现 HTML 标签被截断的情况,导致返回的结果中显示部分 HTML 标签内容。
这种情况对用户展示极为不友好。
那么,我们应该如何处理这种问题呢?
2、原因分析
Elasticsearch 本质上是一个文本检索引擎,它会对输入的文本进行分析、分词、索引,并对用户的搜索关键词进行相应匹配。
富文本(HTML)的特殊性在于,它不仅包含可见的文字,还包含大量的标记语言(如 <div>、<p>、<span> 等标签),这些标签在检索过程中可能会被 Elasticsearch 解析和处理,进而影响检索结果。
3、解决方案
针对这种情况,我们可以通过以下几个步骤来解决问题,确保检索结果更加干净、准确。
3.1. 清洗 HTML 内容
在将 HTML 内容写入 Elasticsearch 之前,最好先对其进行清洗。
清洗操作的目的是去除不必要的 HTML 标签,提取其中的有用文本信息。这可以通过编写自定义算法或使用 HTML 解析库来实现。
常用的 HTML 解析库包括 Jsoup、BeautifulSoup 等,其实采集团队或许已经做过处理。
如果公司采集团队和存储不是一个团队,建议深入交流一下字段细节内容。
3.2. 利用 Elasticsearch 的 HTML Strip 字符过滤器
Elasticsearch 提供了 html_strip 字符过滤器,可以用来自动去除 HTML 标签。
详细参见:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-htmlstrip-charfilter.html
通过该过滤器,我们可以确保在索引过程中,HTML 标签不会被保留下来,只有纯文本内容会被处理和检索。
示例如下:
PUT my-index
{"settings": {"analysis": {"char_filter": {"html_strip": {"type": "html_strip"}},"analyzer": {"html_analyzer": {"type": "custom","char_filter": ["html_strip"],"tokenizer": "standard"}}}},"mappings": {"properties": {"content": {"type": "text","analyzer": "html_analyzer"}}}解释:
char_filter 部分定义了 HTML 过滤器,用于去除 HTML 标签。
html_analyzer 是自定义的分析器,首先使用 html_strip 过滤器去除 HTML 标签,随后通过标准分词器 standard 进行分词和处理。
使用这个分析器进行索引和搜索时,HTML 标签会自动被过滤掉,确保只有纯文本内容参与搜索,进而避免了 HTML 标签截断的问题。
3.3 存储多版本的内容
为了兼顾搜索和展示,推荐在存储时将富文本内容存为两个字段:
原始 HTML 内容:用于在前端完整展示。
纯文本版本:用于索引和检索。
并且负责任告诉大家,真实互联网采集数据存储与展示场景,就得这么干!
例如,我们可以在 Elasticsearch 中定义两种字段:
"mappings": {"properties": {"html_content": {"type": "text", "index": false // 不参与索引,仅用于展示},"cleaned_content": {"type": "text", "analyzer": "html_analyzer" // 纯文本版本,参与检索}}
}这样,html_content 字段保留原始 HTML,用于页面回显;
而 cleaned_content 字段则经过清洗处理,专用于检索操作。
3.4. 通过前端处理回显内容
为了避免搜索结果中显示部分 HTML 标签的情况,我们可以在前端对回显的内容进行进一步处理:
使用前端的 HTML 渲染器,比如 Vue.js 或 React.js 的 v-html 和 dangerouslySetInnerHTML,确保内容正确渲染。
结合高亮功能,确保用户能够清晰地看到与查询关键词匹配的文本部分,而非 HTML 标签。
3.5. 关键词高亮功能
为了增强用户体验,Elasticsearch 提供了高亮显示功能,可以在返回结果时高亮显示与关键词匹配的部分。
通过以下 DSL 语句,我们可以实现对匹配部分的高亮显示:
POST my-index/_search
{"query": {"match": {"cleaned_content": "搜索关键词"}},"highlight": {"fields": {"cleaned_content": {}}}
}这样,在展示时,只会高亮纯文本部分,HTML 标签将不会出现在检索结果中。
4、完整示例,彻底解决富文本存储
Elasticsearch 处理富文本内容(HTML)的方案如下:
4.1 创建索引并配置 HTML 过滤器
如前方案探讨所述,我们首先创建一个新的索引,使用 Elasticsearch 的 html_strip 过滤器来去除 HTML 标签,并配置两个字段:一个存储清洗后的纯文本内容用于检索,另一个存储原始 HTML 内容用于展示。
PUT html_content_index
{"settings": {"analysis": {"char_filter": {"html_strip": {"type": "html_strip"}},"analyzer": {"html_analyzer": {"type": "custom","char_filter": ["html_strip"],"tokenizer": "standard"}}}},"mappings": {"properties": {"html_content": {"type": "text","index": false // 原始 HTML 内容不参与索引,仅用于展示},"cleaned_content": {"type": "text","analyzer": "html_analyzer" // 清洗后用于检索的纯文本}}}
}4.2 向索引中写入数据
我们将两种不同的内容分别写入到 html_content 和 cleaned_content 字段。
html_content 保存的是原始 HTML,而 cleaned_content 保存的是清洗后的纯文本。
POST /html_content_index/_doc
{"html_content": "<p>这是一段关于<strong>Elasticsearch</strong>的文章。</p>","cleaned_content": "这是一段关于 Elasticsearch 的文章。"
}在这个例子中,html_content 保留了 HTML 标签,而 cleaned_content 则去除了 HTML 标签,只保留了纯文本内容。
4.3 进行搜索并返回高亮结果
接下来,我们对 cleaned_content 字段进行全文检索,同时启用高亮功能,确保关键词匹配部分能够在前端得到突出显示。
GET /html_content_index/_search
{"query": {"match": {"cleaned_content": "Elasticsearch"}},"highlight": {"fields": {"cleaned_content": {}}}
}返回结果示例如下:
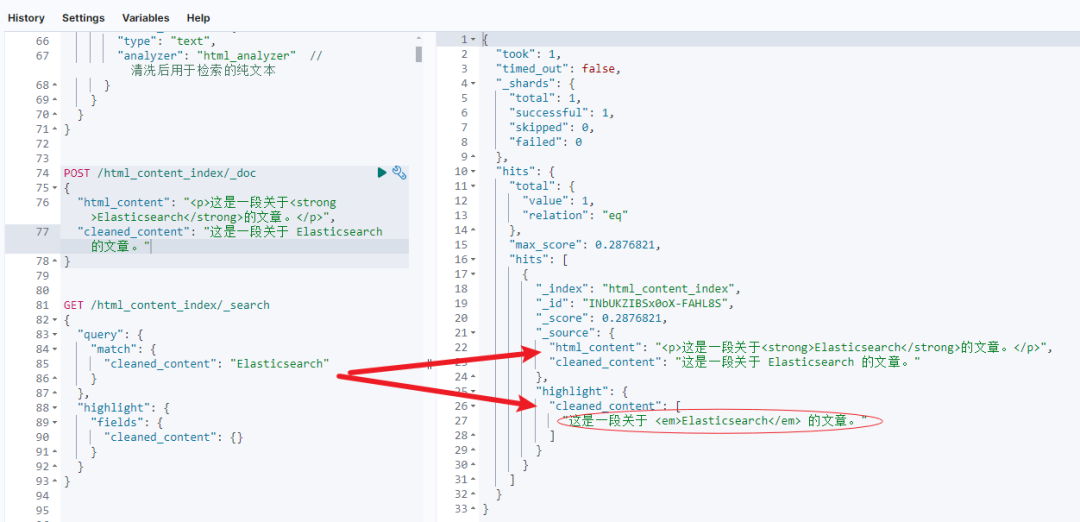
{"took": 34,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0.2876821,"hits": [{"_index": "html_content_index","_id": "INbUKZIBSx0oX-FAHL8S","_score": 0.2876821,"_source": {"html_content": "<p>这是一段关于<strong>Elasticsearch</strong>的文章。</p>","cleaned_content": "这是一段关于 Elasticsearch 的文章。"},"highlight": {"cleaned_content": ["这是一段关于 <em>Elasticsearch</em> 的文章。"]}}]}
}4.4 前端展示:结合原始 HTML 和高亮结果
在前端,我们可以使用 html_content 字段来展示完整的 HTML 内容,而使用 highlight 字段来突出显示用户搜索的关键词。这样,用户既可以看到完整的富文本格式的内容,又能清楚地识别出匹配的关键词。
伪代码:
<!-- 显示原始 HTML 内容 -->
<div v-html="html_content"></div><!-- 高亮显示匹配的关键词 -->
<div v-html="highlighted_cleaned_content"></div>4.5 预处理 HTML 清洗
除了在 Elasticsearch 中使用 html_strip 过滤器,我们还可以在存入 Elasticsearch 之前预先清洗 HTML 内容。
以下是使用 Java 的 Jsoup 库来清洗 HTML 的示例:
import org.jsoup.Jsoup;public class HTMLCleaner {public static String cleanHTML(String html) {return Jsoup.parse(html).text(); // 将 HTML 内容转换为纯文本}
}在保存数据到 Elasticsearch 之前,先调用 cleanHTML 方法去除不必要的 HTML 标签,然后将纯文本存入 cleaned_content 字段。
5、小结
在处理富文本内容时,合理的清洗和过滤是避免 HTML 标签影响检索结果的关键。
处理 HTML 内容的关键在于:清洗 + 分离存储 + 高亮展示。
通过预处理富文本内容,使用 html_strip 过滤器,以及前端渲染和高亮展示,可以有效地避免 HTML 标签截断问题,从而确保用户获得干净、准确的搜索体验。
富文本不做处理直接写入是 Elasticsearch 使用中的常见误区之一,希望本文提供的解决方案能够帮助大家在日常工作中更好地应对类似问题。
更多推荐
Elasticsearch 使用误区之一——将 Elasticsearch 视为关系数据库!
Elasticsearch 使用误区之二——频繁更新文档
Elasticsearch 使用误区之三——分片设置不合理
Elasticsearch 使用误区之四——不合理的使用 track_total_hits
Elasticsearch 使用误区之五——单次请求获取大量数据
《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!