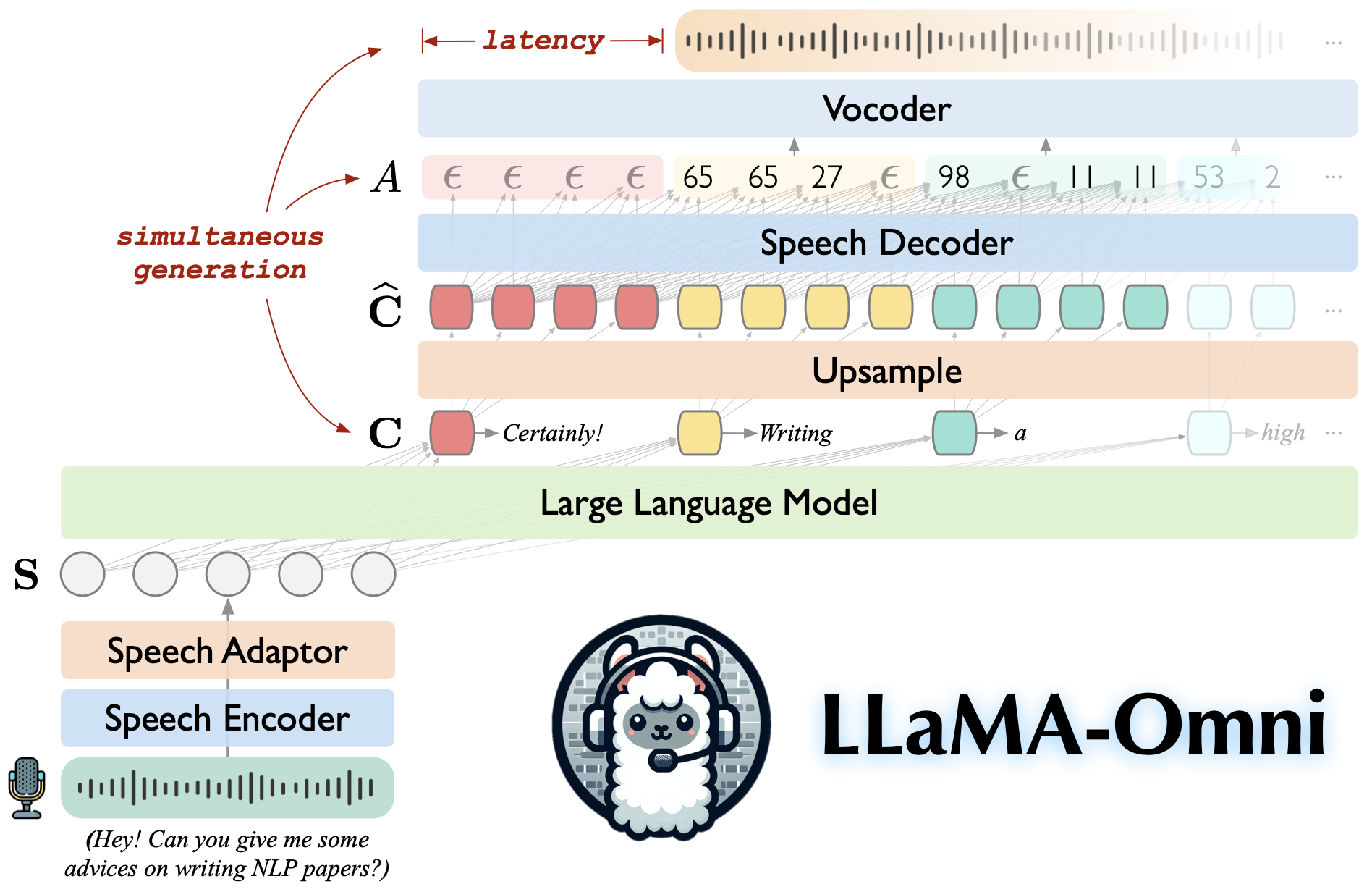
0. 文章传送
学习>机器学习之监督学习(一)线性回归、多项式回归、算法优化[巨详细笔记]
学习>机器学习之监督学习(二)二元逻辑回归
学习>机器学习之监督学习(三)神经网络基础
学习>机器学习之监督学习(四)决策树和随机森林
学习>机器学习之实战篇——预测二手房房价(线性回归)
学习>机器学习之实战篇——肿瘤良性/恶性分类器(二元逻辑回归)
学习>机器学习之实战篇——MNIST手写数字0~9识别(全连接神经网络模型)
学习>机器学习之非监督学习(一)K-means 聚类算法
学习>机器学习之实战篇——图像压缩(K-means聚类算法)
1.案例引入
假设你是飞机生产商,生产了一批飞机发动机,并记录其两个特征x1(heat)和x2(vibration)。由于我们的生产技术过硬,可以相信其中大多数发动机能够正常工作。从学习>机器学习的角度出发,那么我们能否充分利用已有的发动机数据,用来检测后续生产的发动机是否异常呢?这就是典型的异常监测任务。
如下图所示,可以根据数据建立概率密度分布模型,对于新的测试数据,若其位置对应的概率小于某个设定阈值,则可将其标记为‘异常。’

再举一个例子,数据中心可以通过用户电脑工作的实时数据(例如内存使用、CPU使用率)监测用户电脑是否异常,发现潜在的风险,例如计算机被攻击或感染恶意软件。一旦检测到异常,系统可以自动提醒用户注意,或向 IT 支持团队发送警报进行进一步检查,以保障用户体验和数据安全性。

2.高斯正态分布

高斯正态分布(Gaussian Normal Distribution)是概率统计中最重要和最常用的分布之一。它在许多自然现象中都有广泛的应用。以下是关于高斯正态分布的详细介绍:
- 定义
高斯正态分布是一个连续概率分布,其概率密度函数(PDF)由以下公式给出:
p ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 p(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x - \mu)^2}{2\sigma^2}} p(x)=2πσ1e−2σ2(x−μ)2
其中:
μ 是均值(mean),决定了分布的中心位置。
σ 是标准差(standard deviation),影响分布的宽度和形状。
σ^2是方差(variance),表示数据的离散程度。
- 特性
对称性:高斯正态分布是一个对称分布,均值 \muμ 是其对称中心。
钟形曲线:概率密度函数图形呈现为钟形曲线,具有单峰性,意味着大多数数据集中在均值附近。
68-95-99.7法则:在高斯分布中,约68%的数据点位于均值的一个标准差内 ( μ − σ 到 μ + σ ) (\mu - \sigma到 \mu + \sigma) (μ−σ到μ+σ),约95%位于两个标准差内,99.7%位于三个标准差内。
渐近性:分布在无限远处趋向于零,但永远不会等于零。 - 标准正态分布
标准正态分布是特殊的高斯分布,其均值为0,标准差为1。其概率密度函数为:
p ( z ) = 1 2 π e − z 2 2 p(z) = \frac{1}{\sqrt{2\pi}} e^{-\frac{z^2}{2}} p(z)=2π1e−2z2
其中 z 是标准分数(z-score),定义为: z = x − μ σ z = \frac{x - \mu}{\sigma} z=σx−μ.
通过标准化,可以将任意高斯分布转换为标准正态分布。
关于多元高斯分布,参照下图:

3.异常检测算法
在异常检测中,我们需要建立概率密度分布模型,通常假设每个特征满足正态分布。
x i ~ N ( μ i , σ i 2 ) , p ( x i ) = 1 2 π σ i e − ( x − μ i ) 2 2 σ i 2 x_i~N(\mu_i,\sigma_i^2),p(x_i)=\frac{1}{\sqrt{2\pi}\sigma_i}e^{-\frac{(x-\mu_i)^2}{2\sigma_i^2}} xi~N(μi,σi2),p(xi)=2πσi1e−2σi2(x−μi)2
其中均值和标准差(无偏估计)的计算公式为:
μ i = 1 m ∑ k = 1 m x i ( k ) , σ i = 1 m − 1 ∑ k = 1 m ( μ i − x i ( k ) ) 2 \mu_i=\frac{1}{m}\sum_{k=1}^{m}x_i^{(k)},\sigma_i=\sqrt{\frac{1}{m-1}\sum_{k=1}^{m}(\mu_i-x_{i}^{(k)})^2} μi=m1k=1∑mxi(k),σi=m−11k=1∑m(μi−xi(k))2
考虑多个特征,理想情况是考虑各个特征之间相互独立,则由概率公式可得
p ( x ) = ∏ j p ( x j ; μ j , σ j 2 ) p(x)=\prod_j{p(x_j;\mu_j,\sigma_j^2)} p(x)=j∏p(xj;μj,σj2)
尽管通常情况下各个特征之间不完全独立,但事实表明这种计算方式能取得较好的模型效果。
设置异常检测的临界概率(阈值) ϵ \epsilon ϵ,对于待检测样本,计算其概率p(x)并与 ϵ \epsilon ϵ比较,如果p(x)< ϵ \epsilon ϵ,则将其检测为异常样本。
在异常检测中,如何确定合适的阈值 ϵ \epsilon ϵ?在前面的系列文章中我们提到,对于参数选择,一种有效方式是引入验证集,通过验证效果来决定理想的参数。
如下图所示,假设我们已知有10000台正常发动机和20台异常发动机,这时可以选择6000台正常发动机作为训练集(符合算法假设);然后选择2000台正常发动机和10台异常发动机作为验证集;剩下的部分作为测试集。
由于异常检测任务归类于分类问题,因此评估的参数包括混淆矩阵、召回率、精确率、F1-score等等。通过选取不同的阈值,比较验证效果,来选择最优阈值。
同样的,测试集上的表现可以用这些分类指标进行评估。

4.异常检测 vs 监督学习
异常检测属于非监督学习,训练集中的数据均未带标签(默认正常),但我们可能拥有少量带标签的数据(例如发动机案例中已知少量异常发动机),这时候使用监督学习分类算法也可行,那如何在监督学习和基于概率的异常检测之间进行选择呢?
一般来说,异常检测通常适用的情况如下:
①我们只有少量异常数据和大量正常数据
②异常种类很多,未来新的样本可能出现新的异常情况,算法很难从已有数据中捕获足够的异常信息。
监督学习更适用的情况如下:
①我们有大量的正常和异常数据
②异常种类可枚举或未来新的样本呈现的异常情况具有重复性。

适合两种算法的典型场景如下图所示:

5.算法优化
在异常检测任务中,选取和构建合适的特征非常重要,因为基本假设是特征满足正态分布,因此对于偏离正态分布较大的特征,我们希望通过特征处理,将其分布趋近于正态分布。
如下图所示,绘制了某个特征的直方图,可以看到分布曲线向左偏移,偏离正态分布较大。这时候可以通过取对数函数 l o g ( x + c ) log(x+c) log(x+c),或取幂函数 x c ( 0 < c < 1 ) x^c(0<c<1) xc(0<c<1),调整分布接近正态分布。这一过程可以通过编程尝试不同参数c实现。

异常检测中另一种有效的优化方法是通过误差分析引入新的特征。例如在线上交易安全检测器中,我们选取了特征x1(表示交易量)作为特征,训练好模型后进行验证时发现一个错误的案例,发现该案例用户打字速度异常快,因此可以引入新的特征x2:打字速度。这样建立的模型取得了更好的分类效果。

再比如在电脑检测案例中,如果发现一台电脑具有很的高CPU使用率,却使用了很少的网络流量,基于此异常情况可以构建新的特征(如下图,可以取比值)。

特征工程的手段灵活而丰富,但最终的目的都是提升模型的检测能力,在验证集和测试集中都能取得满意的表现。
6.代码实现
计算各个特征高斯分布的均值与标准差函数
def estimate_gaussian(X): """Calculates mean and variance of all features in the datasetArgs:X (ndarray): (m, n) Data matrixReturns:mu (ndarray): (n,) Mean of all featuresvar (ndarray): (n,) Variance of all features"""m, n = X.shapemu=np.average(X,axis=0)var=np.var(X,axis=0,ddof=0) #无偏估计return mu, var
计算所有输入数据对应的概率密度
def multivariate_gaussian(X, mu, var):"""Computes the probability density function of the examples X under the multivariate gaussian distribution with parameters mu and var. If var is a matrix, it istreated as the covariance matrix. If var is a vector, it is treatedas the var values of the variances in each dimension (a diagonalcovariance matrix"""k = len(mu)if var.ndim == 1:var = np.diag(var)X = X - mup = (2* np.pi)**(-k/2) * np.linalg.det(var)**(-0.5) * \np.exp(-0.5 * np.sum(np.matmul(X, np.linalg.pinv(var)) * X, axis=1))return p
根据F1-score选择最佳阈值(阈值取值范围从 p m i n 到 p m a x , 取 1000 个值 p_{min}到p_{max},取1000个值 pmin到pmax,取1000个值)
def select_threshold(y_val, p_val): """Finds the best threshold to use for selecting outliers based on the results from a validation set (p_val) and the ground truth (y_val)Args:y_val (ndarray): Ground truth on validation setp_val (ndarray): Results on validation setReturns:epsilon (float): Threshold chosen F1 (float): F1 score by choosing epsilon as threshold""" best_epsilon = 0best_F1 = 0F1 = 0step_size = (max(p_val) - min(p_val)) / 1000for epsilon in np.arange(min(p_val), max(p_val), step_size):### START CODE HERE ### y_pred=(p_val < epsilon)tp=np.sum((y_val==1)&(y_pred==1))fp=np.sum((y_val==0)&(y_pred==1))fn=np.sum((y_val==1)&(y_pred==0))prec=tp/(tp+fp)rec=tp/(tp+fn)F1=(2*prec*rec)/(prec+rec)### END CODE HERE ### if F1 > best_F1:best_F1 = F1best_epsilon = epsilonreturn best_epsilon, best_F1
实例用法
# Estimate the Gaussian parameters
mu, var = estimate_gaussian(X_train)# Evaluate the probabilites for the training set
p = multivariate_gaussian(X_train, mu, var)# Evaluate the probabilites for the cross validation set
p_val = multivariate_gaussian(X_val, mu, var)# Find the best threshold
epsilon, F1 = select_threshold(y_val, p_val)# Compute the probabilities and detection results for the testing set
p_test=multivariate_gaussian(X_test,mu,var)
y_test=(p_test<epsilon).astype('int')