AAAI-24 | EarnHFT:针对高频交易的分层强化学习(RL)框架
摘要(Abstract):高频交易(HFT)使用计算机算法在短时间内(例如秒级)做出交易决策,在加密货币市场(例如比特币)中被广泛使用。尽管在金融研究中的强化学习在许多量化交易任务上表现出色,但大多数方法集中在低频交易,如日级别,不能直接应用于HFT,因为存在两个挑战:一是RL在HFT中涉及处理极长轨迹(例如每月240万步),难以优化和评估;二是加密货币的剧烈价格波动和市场趋势变化使现有算法难以保持令人满意的性能。为了应对这些挑战,作者提出了EarnHFT,这是一个新颖的三阶段分层RL框架,用于HFT。

引言(Introduction):HFT占据了金融市场超过73%的交易量,通过复杂的计算机算法或数学模型在极短的时间内下单或取消订单。尽管强化学习算法在传统金融市场的低频交易中取得了杰出成果,但在HFT环境下,由于上述两个挑战,很少有算法能够保持稳健的性能。
相关工作(Related Works):介绍了在HFT中使用的传统的金融方法和用于量化交易的RL方法。讨论了在HFT中使用的高频技术指标,以及在量化交易中提出的各种深度强化学习方法。
问题表述(Problem Formulation):介绍了用于描述状态、奖励和行动的基本金融概念,并提出了HFT的分层马尔可夫决策过程(MDP)框架。
EarnHFT方法(EarnHFT):详细介绍了EarnHFT的三个阶段:
-
1. 第一阶段:高效的RL与Q-teacher
-
在这一阶段,EarnHFT计算一个Q-teacher,即基于动态规划和未来价格信息的最优动作价值。Q-teacher作为正则化器,用于训练RL代理,以便每秒提供目标位置,从而提高性能和训练效率。Q-teacher的引入可以加速代理的探索速度,并帮助代理更快地获得正奖励。


-
2. 第二阶段:构建多样化代理池
-
EarnHFT在这一阶段训练数百个二级RL代理,这些代理根据市场趋势偏好进行训练,其中买入持有(buy and hold)回报率被用作偏好指标。通过使用动态时间规整(DTW)对市场进行分类,并根据每个市场类别下的盈利性能来选择一小部分训练过的二级RL代理,构建出一个策略池。
-

-
3. 第三阶段:动态路由优化
-
在这一阶段,EarnHFT训练一个分钟级路由器,该路由器能够根据当前市场状况从策略池中动态选择一个二级代理。这种方法允许系统在不同市场条件下保持稳定的性能。路由器的训练使用DDQN算法,但由于代理池中的代理数量仍然很大,EarnHFT利用代理池的先验知识来细化交易中的选择。具体来说,在选择低级代理之前,系统会确保所选模型的初始位置与当前位置相同,从而将可能的低级代理数量减少到m个。
实验设置(Experiment Setup):描述了在四个加密货币上进行的测试,包括数据集、评估指标和训练设置。
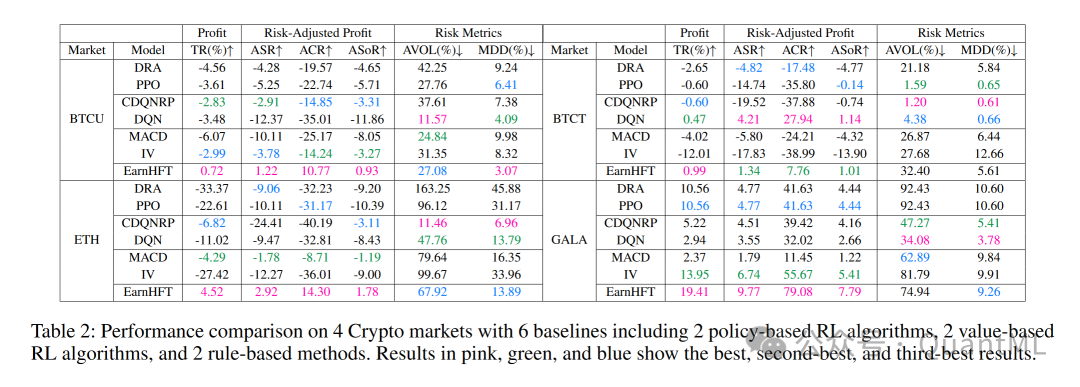
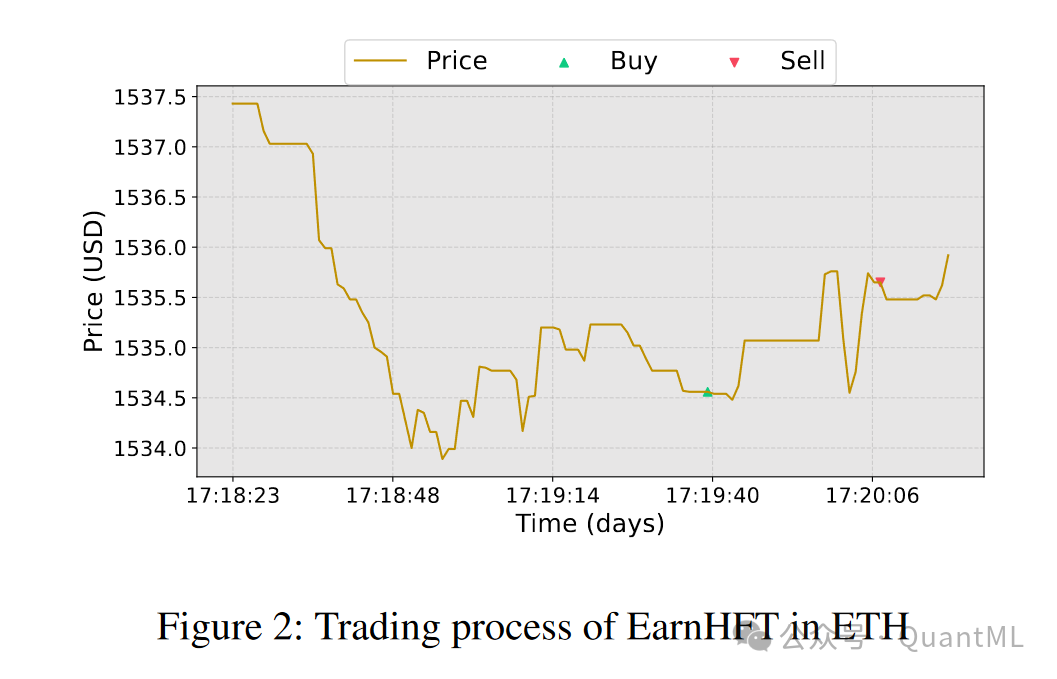
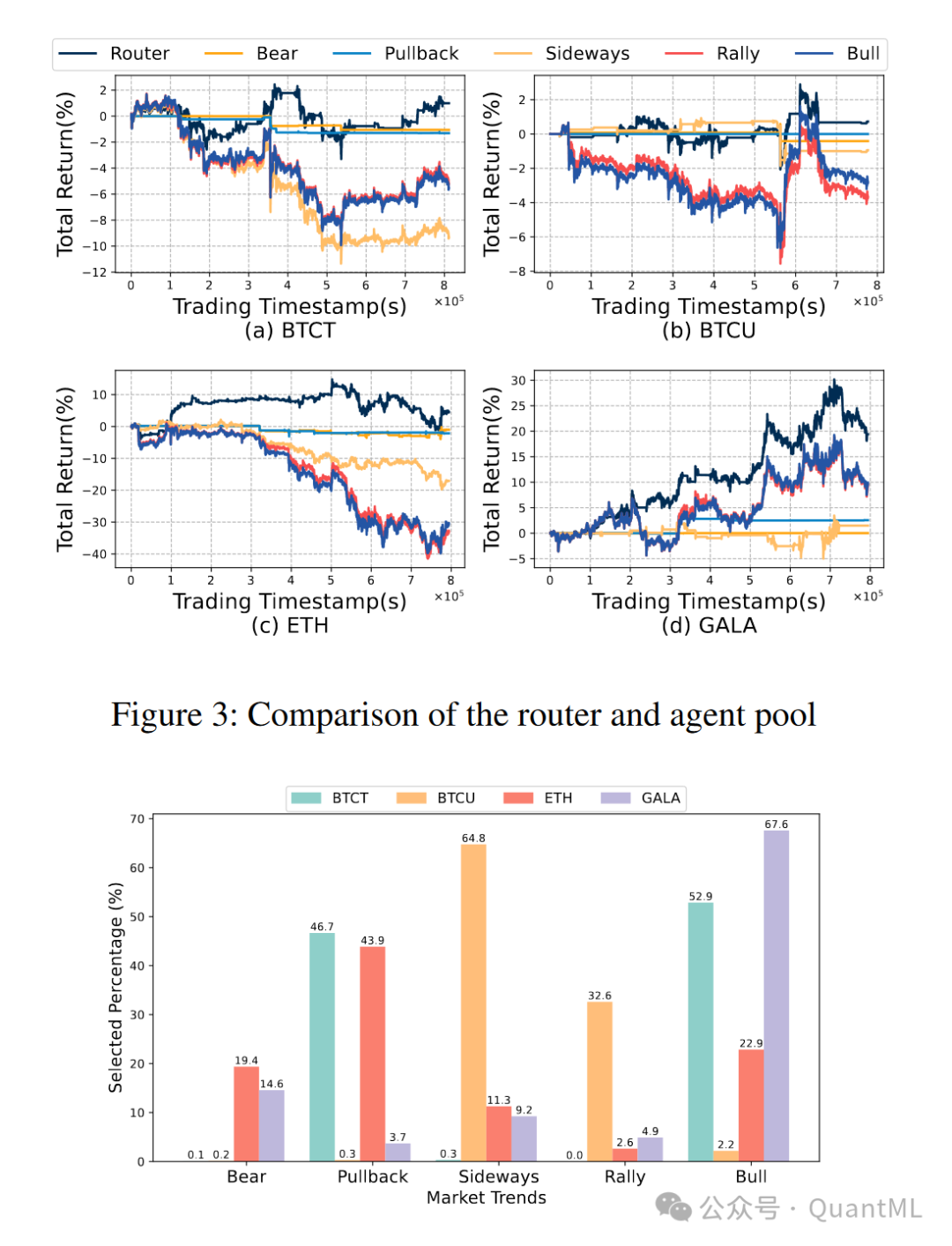
结果与分析(Results and Analysis):展示了EarnHFT与六个基线算法的比较结果,并分析了分层框架和最优动作价值的有效性。
AAAI 2024 EarnHFT:高频交易的高效分层强化学习正式实施。
数据
数据预处理部分请参考data_preprocess/README.md。
我们从tardis下载数据。您可能需要购买 API 密钥才能充分利用我们的代码。
我们首先从 tardis 下载数据,然后进行一些预处理,以使用 dataframe 在算法部分构建相应的 RL 环境。
算法
算法部分请参考EarnHFT_Algorithm/README.md
我们首先训练低级代理,该代理在具有不同偏好参数的第二级上运行beta。
然后,我们用有效数据评估低级别代理,将其分为不同类别,并挑选在市场的每个特定类别中表现出色的代理来构建策略池。
我们利用该池来训练在分钟级别上运行的高级代理。
我们在有效和测试数据集中评估高级代理。
AAAI 2024 EarnHFT:高频交易的高效分层强化学习正式实施。
数据
数据预处理部分请参考data_preprocess/README.md。
我们从tardis下载数据。您可能需要购买 API 密钥才能充分利用我们的代码。
我们首先从 tardis 下载数据,然后进行一些预处理,以使用 dataframe 在算法部分构建相应的 RL 环境。
算法
算法部分请参考EarnHFT_Algorithm/README.md
我们首先训练低级代理,该代理在具有不同偏好参数的第二级上运行beta。
然后,我们用有效数据评估低级别代理,将其分为不同类别,并挑选在市场的每个特定类别中表现出色的代理来构建策略池。
我们利用该池来训练在分钟级别上运行的高级代理。
我们在有效和测试数据集中评估高级代理。
代码:
EarnHFT/EarnHFT_Algorithm/script/BTCUSDT/low_level/train.py
CUDA_VISIBLE_DEVICES=0 nohup python RL/agent/low_level/ddqn_pes_risk_aware.py \--beta 100 --train_data_path data/BTCUSDT/train --dataset_name BTCUSDT \>log/train/BTCUSDT/low_level/beta_100.log 2>&1 &CUDA_VISIBLE_DEVICES=1 nohup python RL/agent/low_level/ddqn_pes_risk_aware.py \--beta -10 --train_data_path data/BTCUSDT/train --dataset_name BTCUSDT \>log/train/BTCUSDT/low_level/beta_-10.log 2>&1 &CUDA_VISIBLE_DEVICES=2 nohup python RL/agent/low_level/ddqn_pes_risk_aware.py \--beta -90 --train_data_path data/BTCUSDT/train --dataset_name BTCUSDT \>log/train/BTCUSDT/low_level/beta_-90.log 2>&1 &CUDA_VISIBLE_DEVICES=3 nohup python RL/agent/low_level/ddqn_pes_risk_aware.py \--beta 30 --train_data_path data/BTCUSDT/train --dataset_name BTCUSDT \>log/train/BTCUSDT/low_level/beta_30.log 2>&1 &# TODO add a random tree to see what features that matter
class DQN(object):def __init__(self, args):self.seed = args.seedseed_torch(self.seed)if torch.cuda.is_available():self.device = "cuda"else:self.device = "cpu"# PES selectorself.beta = args.betaself.type = args.typeassert self.type in ["even", "sigmoid", "boltzmann"]if self.type == "even":self.priority_transformation = get_transformation_even_riskelif self.type == "sigmoid":self.priority_transformation = get_transformation_even_based_sigmoid_riskelif self.type == "boltzmann":self.priority_transformation = get_transformation_even_based_boltzmann_riskself.risk_bond = args.risk_bond# log pathself.model_path = os.path.join(args.result_path,args.dataset_name,"beta_{}_risk_bond_{}".format(args.beta, args.risk_bond),"seed_{}".format(self.seed),)self.log_path = os.path.join(self.model_path, "log")if not os.path.exists(self.log_path):os.makedirs(self.log_path)self.writer = SummaryWriter(self.log_path)# trading settingself.max_holding_number = args.max_holding_numberself.action_dim = args.action_dimself.transcation_cost = args.transcation_costself.back_time_length = args.back_time_lengthself.reward_scale = args.reward_scale# RL settingself.update_counter = 0self.grad_clip = 0.01self.tau = args.tauself.batch_size = args.batch_sizeself.update_times = args.update_timesself.gamma = args.gammaself.epsilon_init = args.epsilon_initself.epsilon_min = args.epsilon_minself.epsilon_step = args.epsilon_stepself.epsilon_decay = (self.epsilon_init - self.epsilon_min) / self.epsilon_stepself.epsilon = self.epsilon_initself.target_freq = args.target_freq# replay buffer settingself.n_step = args.n_stepself.buffer_size = args.buffer_size# supervisor settingself.ada_init = args.ada_initself.ada_min = args.ada_minself.ada_step = args.ada_stepself.ada_decay = (self.ada_init - self.ada_min) / self.ada_stepself.ada = self.ada_init# general learning settingself.lr_init = args.lr_initself.lr_min = args.lr_minself.lr_step = args.lr_stepself.lr_decay = (self.lr_init - self.lr_min) / self.lr_stepself.lr = self.lr_initself.num_sample = args.num_sample# data# self.test_df = pd.read_feather(args.valid_data_path)# self.test_df_list = [# self.test_df,# pd.read_feather(args.test_data_path),# ]self.train_data_path = args.train_data_pathself.chunk_num = 14400self.tech_indicator_list = np.load("data/feature/second_feature.npy").tolist()self.n_state = len(self.tech_indicator_list)# network & loss functionself.hidden_nodes = args.hidden_nodesself.eval_net = Qnet(self.n_state, self.action_dim, self.hidden_nodes).to(self.device) # 利用Net创建两个神经网络: 评估网络和目标网络self.target_net = copy.deepcopy(self.eval_net)self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=self.lr)self.loss_func = nn.MSELoss()def update(self,states: torch.tensor,info: dict,actions: torch.tensor,rewards: torch.tensor,next_states: torch.tensor,info_: dict,dones: torch.tensor,):# TD errorb = states.shape[0]q_eval = self.eval_net(states.reshape(b, -1),info["previous_action"].float().unsqueeze(1),info["avaliable_action"],).gather(1, actions)q_next = self.target_net(next_states.reshape(b, -1),info_["previous_action"].float().unsqueeze(1),info_["avaliable_action"],).detach()# since investigating is a open end problem, we do not use the done here to updateq_target = rewards + torch.max(q_next, 1)[0].view(self.batch_size, 1) * (1 - dones)td_error = self.loss_func(q_eval, q_target)# KL divergencedemonstration = info["q_value"]predict_action_distrbution = self.eval_net(states.reshape(b, -1),info["previous_action"].float().unsqueeze(1),info["avaliable_action"],)KL_div = F.kl_div((predict_action_distrbution.softmax(dim=-1) + 1e-8).log(),(demonstration.softmax(dim=-1) + 1e-8),reduction="batchmean",)# final loss functionloss = td_error + (KL_div) * self.adaself.optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(self.eval_net.parameters(), self.grad_clip)self.optimizer.step()for param, target_param in zip(self.eval_net.parameters(), self.target_net.parameters()):target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)self.update_counter += 1return (KL_div.cpu(),td_error.cpu(),torch.mean(q_eval.cpu()),torch.mean(q_target.cpu()),torch.mean(rewards.cpu()),torch.std(rewards.cpu()),)def act(self, state, info, epsilon):x = torch.unsqueeze(torch.FloatTensor(state).reshape(-1), 0).to(self.device)previous_action = torch.unsqueeze(torch.tensor([info["previous_action"]]).float().to(self.device), 0).to(self.device)avaliable_action = torch.unsqueeze(torch.tensor(info["avaliable_action"]).to(self.device), 0).to(self.device)if np.random.uniform() > epsilon:actions_value = self.eval_net.forward(x, previous_action, avaliable_action)action = torch.max(actions_value, 1)[1].data.cpu().numpy()action = action[0]else:action_choice = []for i in range(len(info["avaliable_action"])):if info["avaliable_action"][i] == 1:action_choice.append(i)action = random.choice(action_choice)return actiondef act_perfect(self, info):action = np.argmax(info["q_value"])return action以下是对给定代码逐行解释的详细分析,该代码实现了一个名为 DQN (Deep Q-Network) 的强化学习模型,用于金融>量化金融交易环境中的决策过程:
python
# TODO add a random tree to see what features that matter
class DQN(object):
- 这里定义了一个名为
DQN的类,用于实现深度Q网络。TODO注释意味着在未来希望添加随机树来识别哪些特征更重要。
python
复制
def __init__(self, args):
- 这是类的初始化函数,
args是传入的参数集,通常包含模型配置和超参数。
self.seed = args.seedseed_torch(self.seed)
- 设置随机种子以确保模型训练的可复现性。
seed_torch是一个假设的函数,用于设置 PyTorch 的随机种子。
python
复制
if torch.cuda.is_available():self.device = "cuda"else:self.device = "cpu"
- 判断是否有可用的 CUDA 设备,以决定模型是在 GPU 还是 CPU 上运行。
python
复制
self.beta = args.betaself.type = args.typeassert self.type in ["even", "sigmoid", "boltzmann"]
- 初始化 beta 参数和 type 参数。断言确保 type 参数是预定义选项之一。
python
复制
if self.type == "even":self.priority_transformation = get_transformation_even_riskelif self.type == "sigmoid":self.priority_transformation = get_transformation_even_based_sigmoid_riskelif self.type == "boltzmann":self.priority_transformation = get_transformation_even_based_boltzmann_risk
- 根据 type 参数选择优先级转换函数,这些函数可能用于调整训练过程中样本的抽样策略。
python
复制
self.risk_bond = args.risk_bond
- 初始化风险约束参数。
python
复制
self.model_path = os.path.join(args.result_path,args.dataset_name,"beta_{}_risk_bond_{}".format(args.beta, args.risk_bond),"seed_{}".format(self.seed),)self.log_path = os.path.join(self.model_path, "log")if not os.path.exists(self.log_path):os.makedirs(self.log_path)self.writer = SummaryWriter(self.log_path)
- 设置模型和日志的存储路径,并创建这些路径。
SummaryWriter用于记录训练过程中的数据,方便后续分析。
python
复制
self.max_holding_number = args.max_holding_numberself.action_dim = args.action_dimself.transcation_cost = args.transcation_costself.back_time_length = args.back_time_lengthself.reward_scale = args.reward_scale
- 初始化交易设置参数,如最大持仓数、动作维度、交易成本、回看时间长度和奖励缩放。
python
复制
self.update_counter = 0self.grad_clip = 0.01self.tau = args.tauself.batch_size = args.batch_sizeself.update_times = args.update_timesself.gamma = args.gammaself.epsilon_init = args.epsilon_initself.epsilon_min = args.epsilon_minself.epsilon_step = args.epsilon_stepself.epsilon_decay = (self.epsilon_init - self.epsilon_min) / self.epsilon_stepself.epsilon = self.epsilon_initself.target_freq = args.target_freq
- 初始化强化学习相关参数,包括梯度剪裁、软更新系数、批大小、更新次数、折扣因子、探索率参数等。
python
复制
self.n_step = args.n_stepself.buffer_size = args.buffer_size
- 初始化经验重放缓冲区的设置,如 n-step 学习和缓冲区大小。
。
python
复制
self.ada_init = args.ada_init
self.ada_min = args.ada_min
self.ada_step = args.ada_step
self.ada_decay = (self.ada_init - self.ada_min) / self.ada_step
初始化自适应学习率衰减参数。ada_init 是初始值,ada_min 是最小值,ada_step 是衰减步长。这些参数可能用于动态调整学习率以适应训练过程中的不同阶段。
python
复制
self.network = self.create_network()
self.target_network = copy.deepcopy(self.network)
self.optimizer = optim.Adam(self.network.parameters(), lr=self.ada_init)
创建神经网络模型并复制一份作为目标网络,以实现稳定的训练。使用 Adam 优化器,并设置初始学习率为 ada_init。
python
复制
self.memory = ReplayBuffer(self.buffer_size)
初始化经验重放缓冲区,其大小由 buffer_size 参数控制。缓冲区用于存储训练过程中的经历,以便后续进行批量学习。
python
复制
self.loss_fn = nn.MSELoss()
设置损失函数为均方误差(MSE),这是许多回归任务中常用的损失函数,适用于 Q-learning 的值函数近似。
python
复制
self.steps_done = 0
self.total_rewards = []
初始化一些监控训练过程的变量。steps_done 记录了总的行动步数,total_rewards 用于存储每一个完整回合的总奖励。
python
复制
def create_network(self):
return Net(args.input_dim, self.action_dim)
定义一个创建神经网络的方法。这里假设 Net 是一个神经网络类,接受输入维度和动作维度作为参数。
python
复制
def select_action(self, state):
sample = random.random()
eps_threshold = self.epsilon_min + (self.epsilon - self.epsilon_min) * \
math.exp(-1. * self.steps_done / self.epsilon_decay)
self.steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
return self.network(state.to(self.device)).max(1)[1].view(1, -1)
else:
return torch.tensor([[random.randrange(self.action_dim)]], device=self.device, dtype=torch.long)
定义一个基于当前状态选择动作的方法。使用 ε-greedy 策略,其中 ε 通过指数衰减函数逐渐减少,增加模型在训练后期的利用(exploitation)能力。
python
复制
def update_model(self):
if len(self.memory) < self.batch_size:
return
transitions = self.memory.sample(self.batch_size)
batch = Transition(*zip(*transitions))
更新模型的方法。首先检查缓冲区中是否有足够的数据进行一次批量更新。之后从缓冲区中随机抽取一批数据进行学习。
python
复制
# 以下代码涉及到从批数据中提取状态、动作等,并进行必要的处理和计算以更新网络参数。
# 代码继续进行损失计算和优化器步骤,最后可能还会涉及目标网络的更新等。
这部分注释说明了接下来的代码将处理批数据,进行损失计算和模型优化,以及可能的目标网络更新。这是模型训练中的关键部分,负责实现算法的核心逻辑,如 Bellman 方程的近似实现等。
以上解释了代码的每一部分如何协同工作以实现 DQN 模型,这是一种强化学习方法,用于训练代理在给定环境中做出决策。代码涵盖了参数初始化、网络构建、动作选择、模型更新等关键步骤。