根据课程GitHub - datawhalechina/hugging-llm: HuggingLLM, Hugging Future.
摘写自己不懂得一些地方,具体可以再到以上项目地址
LM:这是ChatGPT的基石的基石。
Transformer:这是ChatGPT的基石,准确来说它的一部分是基石。
GPT:本体,从GPT-1,一直到现在的GPT-4,按OpenAI自己的说法,模型还是那个模型,只是它长大了,变胖了,不过更好看了。关于这点,大家基本都没想到。现在好了,攀不上了。
RLHF:ChatGPT神兵利器,有此利刃,ChatGPT才是那个ChatGPT,不然就只能是GPT-3
1 LM 语言模型
LM,Language Model,语言模型,简单来说就是利用自然语言构建的模型。这个自然语言就是人常说的话,或者记录的文字等等,只要是人生产出来的文字,都可以看做语言。你现在看到的文字也是。模型就是根据特定输入,通过一定计算输出相应结果的一个东西,可以把它当做人的大脑,输入就是你的耳、眼听或看到的文字,输出就是嘴巴说出来或手写出来的文字。总结一下,语言模型就是利用自然语言文本构建的,根据输入的文字,输出相应文字的模型。
在深度学习的初期,最著名的语言模型是RNN,Recurrent Neural Network,中文叫循环神经网络。RNN 模型与其他神经网络不同的地方在于,它的节点之间存在循环连接,这使得它能够记住之前的信息,并将它们应用于当前的输入。这种记忆能力使得 RNN 在处理时间序列数据时特别有用,例如预测未来的时间序列数据、自然语言处理等。通俗地说,RNN 就像一个具有记忆功能的人,可以根据之前的经验和知识对当前的情况做出反应,并预测未来的发展趋势。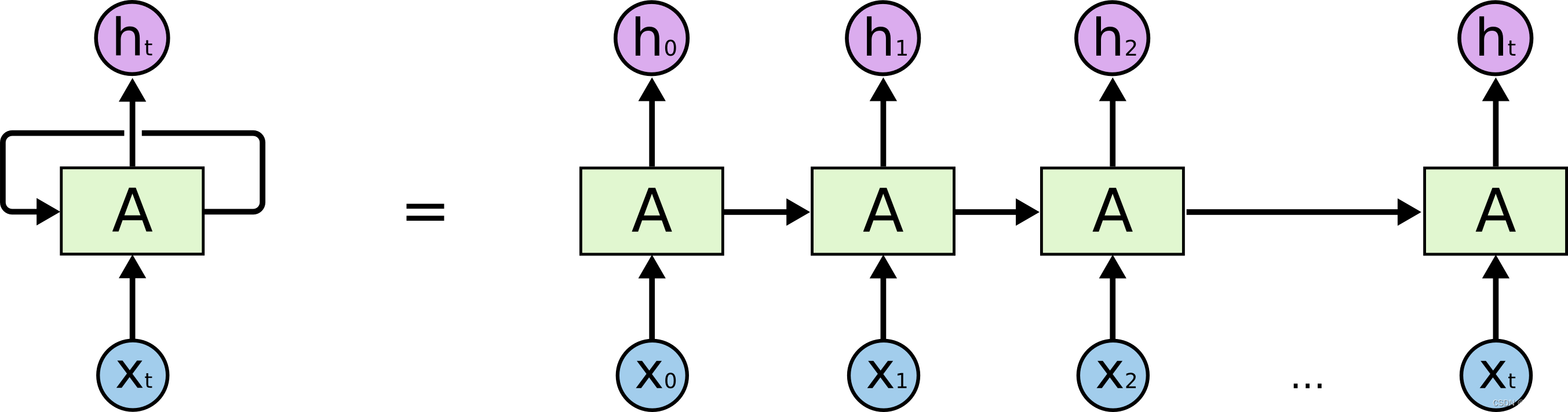
右边是左边的展开,A就是参数,X是输入,h就是输出,由于自然语言是Token by Token的,所以就组成了一个序列。那这个参数怎么学习呢?
右边的图就是左边图像的展开,真的非常形象,每次输入一个新的值,再经过中间体就会产生一个新的值。之前只看左边的图确实不太理解什么意思。如果对于逐步输入且有记忆还是不太明白的话请看下图。

第一行就是X,第二行就是Y,SOS表示Start of Sentence,EOS就不多解释了。注意,上面的h并不是那个输出的概率,而是hidden state,如果需要概率,可以将h再做一个张量运算,归一化到整个词表即可。这里每次输入一个值,然后再输出一个值,每次都会基于前边的记忆进行输入再输出。最后综合前边所有的输入,输出最后的语句。
import torch.nn as nnrnn = nn.RNN(32, 64)
input = torch.randn(4, 32)
h0 = torch.randn(1, 64)
output, hn = rnn(input, h0)
output.shape, hn.shape
# (torch.Size([4, 64]), torch.Size([1, 64]))意思已经大致明白了,虽然代码确实有些地方还不太懂,对于深度学习相对还不是那么熟悉。
2 Transformer
一个刚开始在NLP领域,后来横跨到语音和图像领域,并最终统一几乎所有模态的架构。这是Google2017年发的一篇论文,标题叫《Attention Is All You Need》,其最重要的核心就是提出来的Self-Attention机制,中文也叫自注意力。简单来说,就是在语言模型建模过程中,把注意力放在那些重要的Token上。
Transformer是一种Encoder-Decoder架构,简单来说就是先把输入映射到Encoder,这里大家可以把Encoder先想象成上面介绍的RNN,Decoder也可以想象成RNN。这样,左边负责编码,右边则负责解码。这里面不同的是,左边因为我们是知道数据的,所以建模时可以同时利用当前Token的历史Token和未来(前面的)Token;但解码时,因为是一个Token一个Token输出来的,所以只能根据历史Token以及Encoder的Token表示进行建模,而不能利用未来的Token。
Transformer的这种架构从更普遍的角度来看,其实是Seq2Seq架构,大家别慌,这简单来说就是序列到序列模型,也就是输入是一个文本序列,输出是另一个文本序列。翻译就是个很好的例子,我们看下面这个来自Google的GNMT(Google Neutral Machine Translation)的经典图片:

这个图是动态的,具体可以到原文链接直接看。Encoder和Decoder可以采用RNN,最终就是Encoder所有Token最终输出一个向量,作为整句话的表示。说到这里,整句话又怎么表示呢?刚刚上面我们也提到过,如果RNN这种结构,可以把最后一个Token的输出作为整个句子的表示。当然了,很符合直觉地,你也可以取每个Token向量的平均值,或第一个和最后一个的平均值,或后面N个的平均值。这些都可以,问题不大,不过一般取平均的情况比较多,效果要好一些。除了平均值,也可以求和、取最大值等,我们就不多深入讨论了。现在重点来了,看Decoder的过程,仔细看,其实它在生成每一个Token时都用到了Encoder每一个Token的信息,以及它已经生成的Token的信息。前面这种关注Encoder中Token的信息的机制就是Attention(注意力机制)。直观点解释,当生成Knowledge时,「知识」两个字会被赋予更多权重。

根据上面的这个文字看以上Transformer的示意图可能更清楚一些。
3 GPT
GPT,Generative Pre-trained Transformer,没错了,就是ChatGPT的那个GPT,中文叫「生成式预训练Transformer」。生成式的意思就是类似语言模型那样,Token by Token生成文本,也就是上面提到的Decoder。预训练刚刚也提过了,就是在大量语料上训练的语言模型。GPT模型从1到4,一共经历了5个版本,中间有个ChatGPT是3.5版,接下来我们分别介绍它们的基本思想。看到了这么多,现在终于可以理解之前的GPT的具体含义到底是什么了。GPT-1和BERT一样,走的是下游任务微调套路,也就是固定住预训练模型不动,然后在不同下游任务上微调一个模型。