一、日志管理

mybatis主要使用logback来管理日志,具体内容之前的java进阶有说,链接如下
java基础进阶——log日志、类加载器、XML、单元测试、注解、枚举类_java logs是什么意思-CSDN博客
二、动态SQL
动态SQL指的是根据参数数据动态组织SQL的技术。

三、MyBatis二级缓存
我们使用mybatis查询一条数据两次,第一次查询从硬盘读取,第二次查询还从硬盘读取是比较慢的,如果把第一次查询的结果存到内存一块空间中,在内存中读取会快至少几十倍。
1.二级缓存和缓存范围

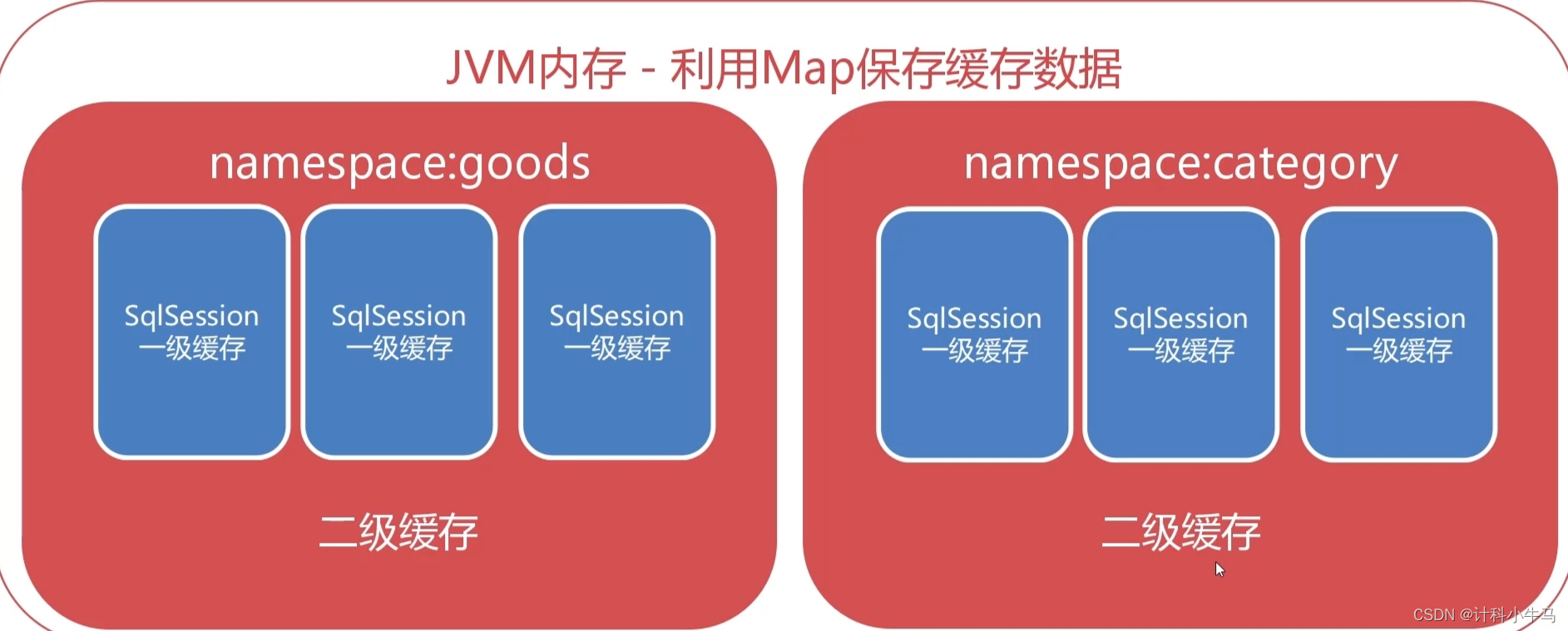
一级缓存的存在时间比较短,SqlSession会话结束后缓存就会清空,所以需要mapper命名空间这个二级缓存。不同的命名空间对应不同的二级缓存区域,只有在使用相同命名空间执行相同的查询语句并且没有对查询结果进行修改等操作时,才会从二级缓存中获取数据。
2.二级缓存运行规则和开启

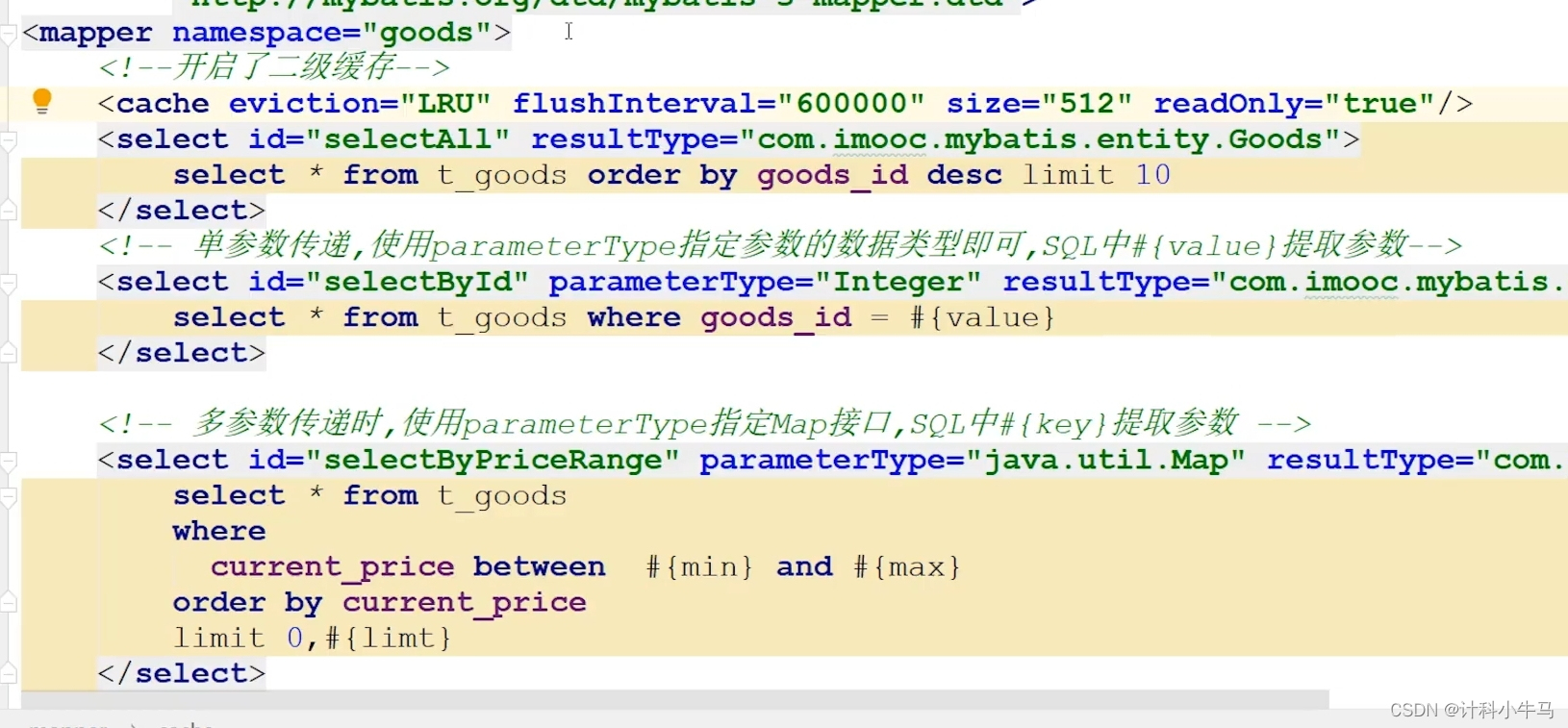
mapper文件中在mapper标签的第一行添加cache标签
3.cache标签属性的解读
(1)eviction
eviction是缓存的清除策略,当缓存对象数量达到上限后,自动触发对应算法对缓存对象清除
1.LRU 最近最久未使用:移除最长时间不被使用的对象。
2.FIFO 先进先出:按对象进入缓存的顺序来移除它们。
3.SOFT 软引用:移除基于垃圾收集器状态和软引用规则的对象。
4.WEAK 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
(2)flushInterval
代表间隔多长时间自动清空缓存,单位亳秒,600000毫秒=10分钟
(3)size
缓存存储上限,用于保存对象或集合(1个集合算1个对象)的数量上限
(4)readOnly
设置为true,代表返回只读缓存,每次从缓存取出的是缓存对象本身,这种执行效率较高
设置为false代表每次取出的是缓存对象的"副本”,每一次取出的对象都是不同的,这种安全性较高
4.useCache和flushCache
(1)useCache
可以在<insert>等四大sql标签使用useCache属性设置值为false表示不开启缓存。
(2)flushCache
可以在四大sql标签添加该属性,设置值为true表示一句sql执行完,立马刷新缓存空间。
四、分页查询
1.PageHelper分页
(1)PageHelper使用流程
直接浏览器搜pageHelper到官网有详细用法

(2)引入PageHelper和jsqlparser依赖
<dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>5.1.10</version></dependency><dependency><groupId>com.github.jsqlparser</groupId><artifactId>jsqlparser</artifactId><version>2.0</version></dependency>(3)增加Plugin配置
<plugins><plugin interceptor="com.github.pagehelper.PageInterceptor"><property name="helperDialect" value="mysql"/><property name="reasonable" value="true"/></plugin></plugins>说明:
(1)plugins插件是mybatis的一个特色,通过插件可以扩展mybatis的能力;
(2)interceptor属性:代表拦截器,需要配置PageHelper的核心类;
(3)helperDialect配置项,设置为mysql代表使用limit分页,不同数据库的分页操作不同,所以这个配置项必须设置。
(4)reasonable配置项,代表分页合理化。
(4)测试方法
@Testpublic void testPageHelper(){SqlSession sqlSession = null;try {sqlSession = MybatisUtils.getSqlSession();PageHelper.startPage(10,10);Page page = (Page)sqlSession.selectList("goods.selectAll");System.out.println("总页数:"+page.getPages());System.out.println("总记录数:"+page.getTotal());System.out.println("开始行号:"+page.getStartRow());System.out.println("结束行号:"+page.getEndRow());List<Goods> list = page.getResult();for(Goods goods : list){System.out.println(goods.getTitle());}} catch (Exception e) {throw new RuntimeException(e);} finally {MybatisUtils.closeSqlSession(sqlSession);}}2.不同数据库分页
(1)Mysql

从第10行开始读取20行
(2)Oracle

读取12行到20行数据
(3)SQL Server
2000年

读取第16 17 18行数据
2012年至今

读取到5 6 7 8 9行数据
五、mybatis整合C3P0连接池

mybatis自己生成的连接池并没有许多现有的连接池技术好,现在介绍一款。
1.引入maven依赖

2.建一个datasource包下创建一个工厂类
/*** C3PO与MyBatis兼容使用的数据源工厂类*/
public class C3P0DataSourceFactory extends UnpooledDataSourceFactory {public C3P0DataSourceFactory() {this.dataSource = new ComboPooledDataSource();}
}3.配置文件mybatis-config.xml
不同连接池的数据连接配置的属性名称不同(驱动、数据连接、用户名、密码)
还可以设置默认连接数量和最大最小连接数量

六、mybatis批次处理
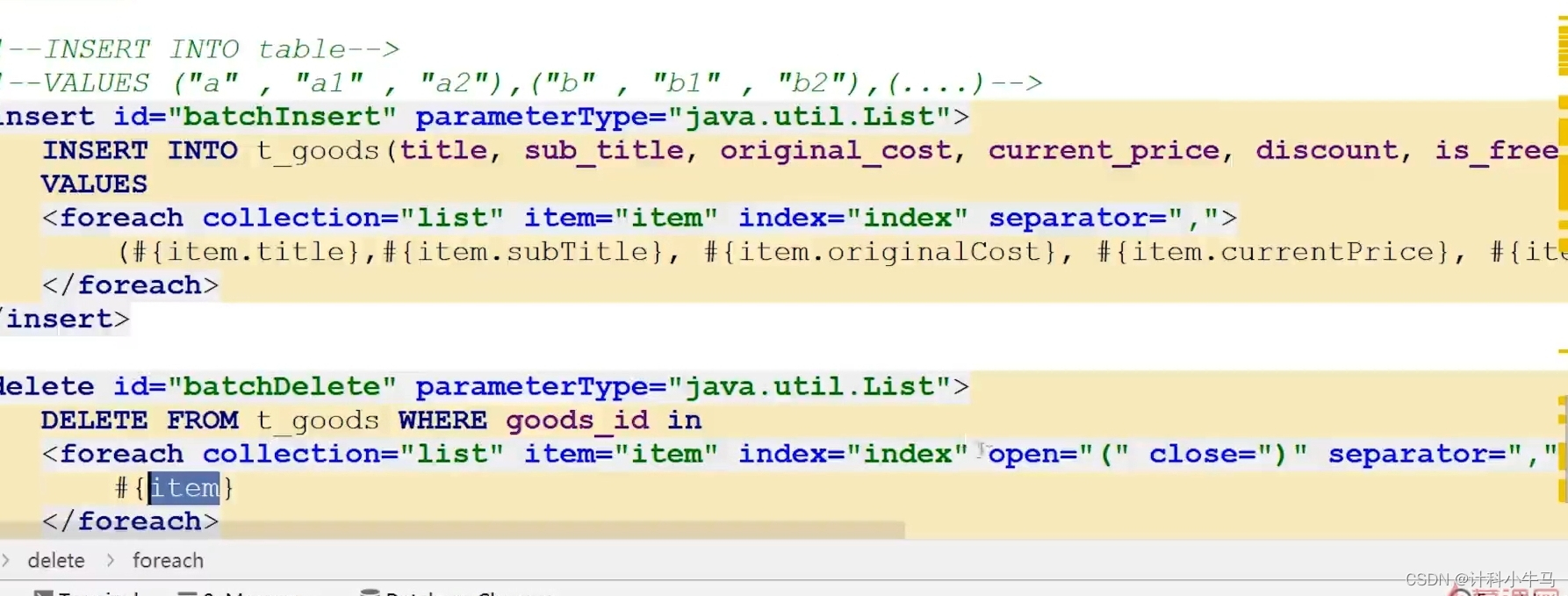
使用foreach标签
1.批次插入,批次删除
2.批次处理优缺点
优点: 比一条一条sql处理快
缺点:无法获得插入数据生成的id
批量生成的SQL太长,可能会被服务器拒绝
七、mybatis注解开发
1.常用注解
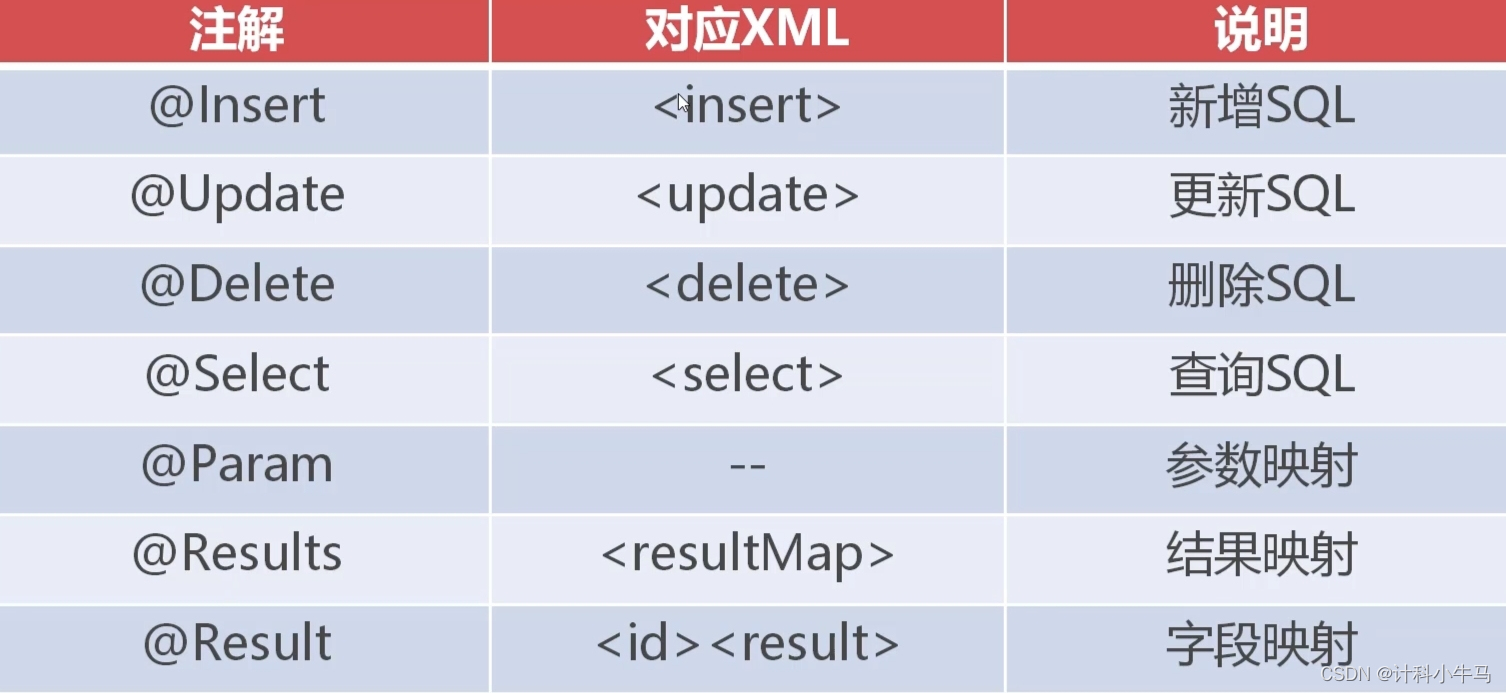
2.注解开发流程
注解开发不需要使用mapper xml文件,需要建立一个dao包,里面存放操作sql的接口,在接口的抽象方法上面添加常用注解。
3.注解方式查询流程
(1)创建接口和查询方法
在dao包下创建接口和方法,并在方法上使用@Select注解,SQL传参使用@Param注解

(2)在mybatis配置文件配置坐标

(3)测试方法

4.注解方式插入返回自动生成的主键
要添加@SelectKey注解,里面要配置statement属性(mysql查询主键id的SQL语句),
keyProperty属性(实体对象的主键属性名goodsId),returnType属性(主键的数据类型Integer.class)