多任务学习,也就是MTL(Multi-task Learning),现在已经被用在很多领域了,比如处理自然语言、搞计算机视觉,还有语音识别这些领域。MTL在大规模的推荐系统里也玩得挺溜,尤其是那些做视频推荐的大家伙。
MTL的玩法就是,用一套模型结构和底层的数据表示来同时处理好几个任务。这样做的好处是,理论上能提升相关任务的准确度,因为不同任务之间可以相互学习、相互帮助。这样一来,不仅省了计算资源,还能造出更通用的模型来。而且,因为参数是共享的,所以还能让机器学习系统反应更快,处理大规模数据也更给力。
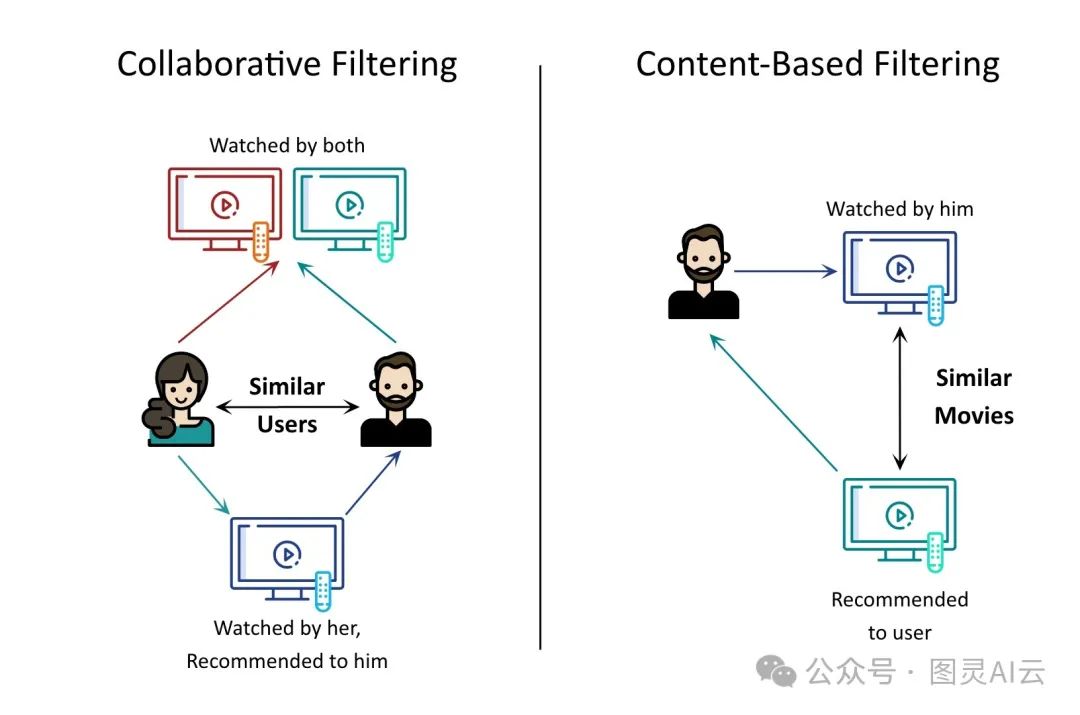
推荐系统的工作,就是预测用户将来会怎么反馈,以此来猜测用户的喜好和满意度。目标就是给用户推荐那些他们可能会喜欢的、会多看两眼的视频。但是,要真正搞清楚用户到底满不满意,其实是挺难的,也是个复杂问题。有时候,用户的真实感受并不会直接在他们的活动记录里体现出来。所以,我们在做推荐系统的时候,会找个替代方案,比如预测用户给视频打分的准确性,希望这样能间接提升电影推荐的效率。简单来说,我们就是通过观察用户的行为或者反馈,比如他们看视频看得多认真,来判断他们可能喜欢什么。比如,如果一个视频的播放完成率很高,或者平均观看时间很长,那我们就可以认为用户对这视频挺满意的。
对于那些视频应用,比如Instagram Reels、抖音、快手或者YouTube Shorts,用户的反馈可以有很多种形式,比如点赞、评论、分享、看完整、跳过、收藏等等。比如,一个电影推荐系统可能就会预测用户会不会点击某个视频,或者会不会看完。MTL就能一块儿预测这些行为,然后通过一个融合的过程,根据模型输出的各种结果来综合判断用户的满意度。
搞大规模的视频推荐,确实得面对一些特别的挑战。Covington等人(https://dl.acm.org/doi/10.1145/2959100.2959190)提到了几个难点,这些难点让推荐YouTube视频变得挺棘手的。
首先,是规模问题:那些在小规模情况下表现不错的复杂算法,一旦放到有几十亿用户和视频的场景下,可能就行不通了。效率很关键,因为它直接关系到成本和用户的体验。研究显示,哪怕只是100毫秒的延迟,都可能对收入有明显影响。
再来,是新鲜感的问题:像抖音、快手这样的平台,每天都会有数不清的新视频上传。推荐系统得够灵敏,得能及时处理这些新内容和用户互动的数据。同时,怎么把新内容推荐给用户,也得有个不错的探索和利用的策略。
最后,是噪声的问题:因为数据量太大,用户互动的数据通常都很稀疏。而且,模型还得处理那些嘈杂的隐式反馈信号,比如不小心点到的,因为我们很少能直接观察到用户真正的满意度。
在工业界,推荐系统一般会分两个阶段来处理:先是候选生成,也就是找出可能感兴趣的视频,然后是排名,也就是给这些候选视频打分,排个名。在找候选的阶段,会用各种检索策略,比如根据用户喜好、视频之间的相似性或者主题来匹配,从海量视频里找出几百几千个可能感兴趣的。这个阶段的个性化做得比较广,主要是通过协同过滤来实现。然后,到了排名阶段,就会对每个候选视频进行更细致的评分,最终生成推荐列表。
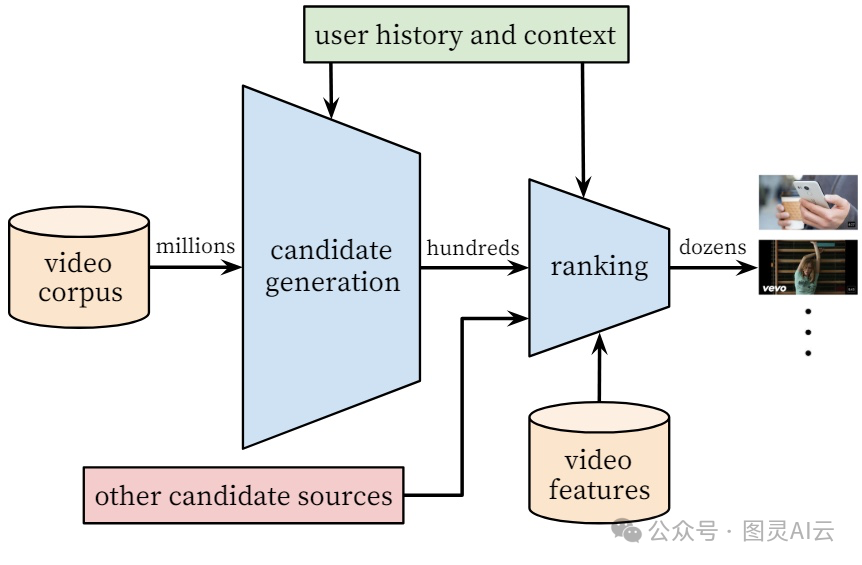
YouTube推荐系统架构
到了排名阶段,因为候选数量已经减少了很多,我们就可以上一些更复杂、更强大的神经网络模型了,也能用到更多描述用户、视频和它们之间关系的特征。这个阶段也有助于整合不同来源的候选结果,因为这些结果的分数可能直接比较不了。多任务学习的技术,通常在排名阶段用得上,因为排名的目标可能对应着不同类型的用户反馈。
至于训练数据,我们通常会从用户行为日志里抽取最近几天的数据。一般会用7到10天的数据来训练,然后用接下来的1到3天的数据来做测试。虽然我们可以直接用用户的显式反馈,比如产品内的调查什么的,但这样的信号太少,成本也高,所以不太能大规模使用。因此,我们更多依赖于隐式反馈,比如点击、评论、看完视频这些作为正面样本,而像跳过或隐藏视频这样的反馈作为负面样本。有些系统还会把用户反馈分成不同的类别。比如YouTube就定义了两类:参与行为,比如点击和观看,以及满意度行为,比如点赞和驳回。
要注意的是,训练数据里肯定会有一些噪声和稀疏性。稀疏的特性往往遵循幂律分布,用户反馈的方差会很大。比如,用户可能在稍微不同的情境下(比如不同的地方、不同的时间、不同的缩略图,或者我们系统捕捉不到的一些外部因素)就不会点击推荐的视频。用隐式反馈的话,我们就能为那些长尾的视频提供推荐,这些视频在印象日志里的显式参与可能非常少。
咱们在准备训练数据的时候,得用一些聪明的办法来筛掉那些不太有用的信息。比如说,咱们可能会这么干:
-
把那些互动次数少于五次的用户给筛掉。
-
把那些视频时长太短,不到五秒,或者太长,超过三小时的视频给筛掉。
-
把那些被看过次数少于五次的视频给筛掉。
-
把那些观看时间异常长的视频观看记录给筛掉。
每个样本,不管是好的还是坏的,都得标上一个目标值。比如,要是任务是关于观看时间的,那正面的样本就用用户实际观看视频的时间来标记。类似地,对于点击任务,每个视频就得看它在被推荐时有没有被点过。
排名模型一般都是用点式方法来实现的。虽然可以用对式或列表式方法来增加推荐的多样性,但是从实际操作的角度来看,点式方法更容易扩展。对于每个候选视频,我们的排名系统会用用户的查询、候选视频和上下文(比如一天中的时间、设备类型)的特征作为输入,然后学习预测多种用户行为。用户查询通常就是通过用户过去看的视频历史来表示的。
推荐系统用到的特征,可以根据它们是描述视频(“印象”)的属性还是用户/上下文(“查询”)的属性来分类。用户端的特征每次用户请求时计算一次,而视频端的特征每个视频计算一次。
用户的观看历史就是一堆长短不一(稀疏)的视频ID序列,这些ID会通过嵌入转换成密集向量表示。如果用户有搜索历史,那也会用类似的方法处理,把以前的搜索词标记化,然后嵌入。这些密集的观看和搜索历史可以通过连接或者取平均值(或者求和、取最大值等)来整合。这些ID序列通常会被截断到一个固定的长度,必要时会填充默认值。嵌入的维度大概和唯一值的数量的对数成正比。注意,同一个ID空间里的分类特征也会共用嵌入,这有助于提升模型的泛化能力,加快训练速度,还能减少内存的使用。
提供用户的一些基本信息,比如地理位置、性别和年龄,可以帮助我们更好地处理新用户。稀疏的分类特征会通过嵌入转换成密集表示。二进制特征(比如用户有没有登录)和连续特征会被归一化到0到1之间。一些连续特征,比如用户在这个频道上看了多少次视频,用户上次看这个话题的视频是什么时候,这些通常描述得挺好的。
至于视频方面,我们有标题、标签、时长、封面、内容、类别等特征。视频的元数据和内容信号用来生成视频的表示。可以从预训练的编码器模型中提取分类特征的嵌入。和视频封面相关的特征可能更有助于预测点击率,而内容嵌入可能更有助于预测观看时间。实际上,视频的元数据结构可能不太好,也没有一个明确定义的本体论,因为咱们也不能强迫视频制作者提供他们发布的视频的所有详细信息。计算多模态特征在时间和资源上也挺费钱的。因为这些获取上的挑战,有些团队可能就只用交互数据。
用户对推荐的视频可能会有不同的反应。多任务排名模型会预测和用户满意度相关的这些行为。比如点击和观看时间可以衡量用户的参与度,而点赞和评分可以衡量满意度。对于二元分类任务(比如点击、看了80%的视频),我们会计算交叉熵损失,而对于回归任务(比如视频观看时间),通常用的是平方损失。
咱们来看看正在使用的视频推荐系统中,人们都怎么用标签来提升推荐质量。
-
腾讯的WeSee:刘等人(https://arxiv.org/abs/2110.13365)的研究里,腾讯讲了他们怎么同时预测正面的反馈,比如点赞、关注、评论、分享、看评论和主页,还有三个跟视频观看时间有关的“播放”任务(两个积极的,一个消极的)。
-
播放完成率:这是个回归任务,就是拿观看时间除以视频长度,来预测视频的完成率。因为可能有人会反复看同一个视频,所以观看时间可能会超过视频本身的长度,这种情况下,值的范围[0,∞]通常会被限制在一个最大阈值内。
-
播放完成:这是个二元分类任务,用来预测用户会不会看完整个视频(也就是观看时间达到或超过视频长度)。
-
跳过:这也是个二元分类任务,用来预测用户会不会很快就跳过视频(也就是观看时间少于某个特定的秒数c)。
-
-
腾讯新闻:类似地,唐等人(https://dl.acm.org/doi/abs/10.1145/3383313.3412236)研究中,腾讯用观看完成率来模拟观看次数,用观看通过率来模拟观看时间。他们还用了分享和评论来模拟更传统的用户反馈行为。
-
百度好看视频:李等人(https://dl.acm.org/doi/10.1145/3397271.3401238)研究中,百度用了点击率(CTR)、连续CTR、连续播放长度等等。
对于每个视频候选,所有任务的预测结果会通过一个组合函数(比如加权乘法)结合起来,生成一个最终的得分。这些权重可以通过学习得到,或者根据业务需要手动调整,以达到最佳效果。刘他们提出了一个基于强化学习的方法来学习一个代理函数,这个函数会计算最终的融合得分。辛等人(https://www.semanticscholar.org/paper/Prototype-Feature-Extraction-for-Multi-task-Xin-Jiao/1f820eb19afec15911bf92d6db0f3009478e1376)还建议提高那些更少见任务的损失权重。候选视频集合会根据这个组合得分来排序,从而生成排名推荐列表。
至于离线实验,二元分类任务会用交叉熵损失来训练,用AUC来评估,而回归任务会用MSE损失来训练,用MSE来评估。评估时用的真值数据是从用户行为日志中提取的,损失就是实际用户行为和预测行为之间的差异。还会用到其他一些指标,比如精确度、召回率和NDCG,来指导整个推荐流程的迭代开发。模型的有效性最终会通过生产系统中的A/B测试来评估。这种现场测试可以让我们测量多种参与度和满意度指标,比如点击率、观看时间、驳回率、用户调查反馈等等。对于大规模系统来说,像每秒查询数这样的服务成本指标也非常重要。A/B测试结果和离线实验不一致也是常有的事。
广泛使用的多任务排名架构遵循以下图所示的共享底部结构。
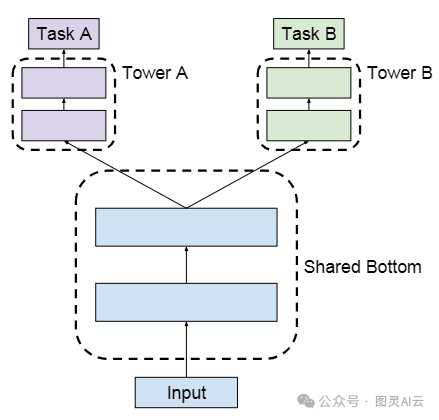
共享底部多任务模型架构
该架构由所有任务共享的低级层组成,顶部有一些特定于任务的高级层。共享组件有助于学习许多相关任务的联合表示,避免过拟合,并且由于参数共享,还节省了计算成本。这种隐藏层的共享也称为硬参数共享。
理论上,硬参数共享能让模型从不同任务中学到共通的东西,提高模型的泛化能力。但研究发现,多任务学习(MTL)对任务之间的关系特别敏感,如果任务之间关系不强或者太复杂,模型的性能可能会下降。这就像是让一个模型同时解决数学和语文问题,但用了同一套思维模式,结果两边都不讨好,这种现象就叫做负迁移。还有研究发现,复杂的任务关系中存在跷跷板效应,就是一个任务表现好了,另一个任务的表现就可能变差。
在现实世界的推荐系统中,任务之间通常关系不大,有时候甚至是相互冲突的。比如,点击率和观看完成率这两个任务,它们模拟的是用户不同的行为,所以它们之间的关系比较简单。但我们通常有很多不同的目标,有时候这些目标之间是有冲突的。比如,我们可能既想减少视频被跳过的次数,又想增加用户的观看时长。或者,我们可能想让模型推荐更短的视频来提高播放完成率,但同时又想推荐更长的视频来增加平均观看时间。
解决这种任务冲突的一个简单办法是,对于有关系的任务用多任务模型,对于没啥关系的任务就用单任务模型。但问题是,我们很难判断哪些任务是相关的。另一种方法是调整网络结构,让参数共享更灵活。有些人尝试通过学习不同任务表示的线性组合的权重来解决任务冲突,但这种方法学的是静态权重,而且会引入很多额外的参数,所以在大规模应用中效果有限。
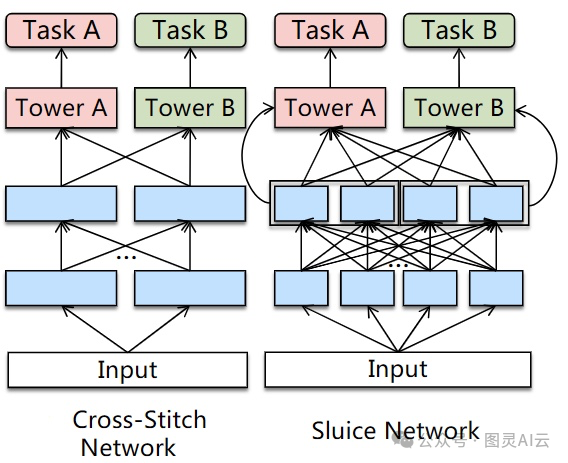
替代路由架构:蓝色矩形代表共享层,粉色和绿色矩形代表特定于任务的层。
一种流行且可扩展的解决冲突问题的方法是设计门控结构和注意力机制,它们基于输入融合知识。专家混合(MoE)最初提出在底部共享一些专家,并通过门控网络组合专家。多门控混合专家(MMoE)扩展了这一概念,以获得不同的融合权重。
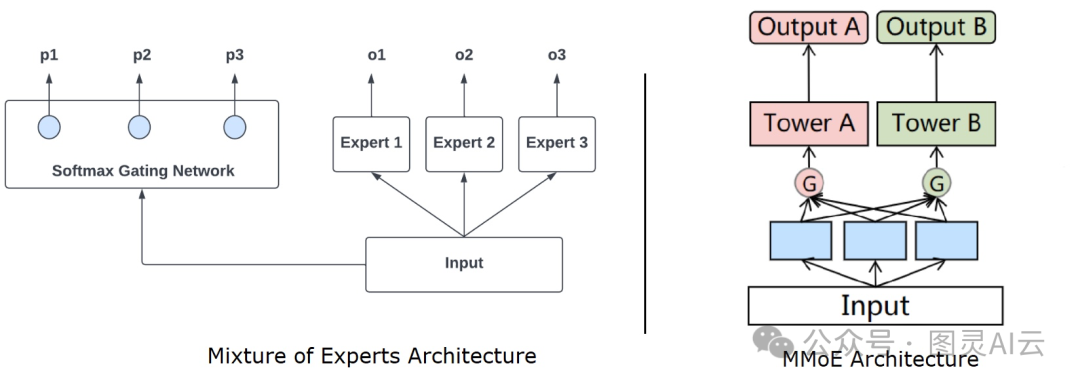
MoE 和 MMoE 架构
多门控混合专家(MMoE)将共享的低级层分割成子网络,称为专家,并使用特定于任务的门控网络来利用不同的子网络。MMoE明确地从数据中学习建模任务差异和关系。
在《推荐下一个观看的视频:一个多任务排名系统》(https://daiwk.github.io/assets/youtube-multitask.pdf)中,谷歌描述了通过多门控混合专家(MMoE)使用软参数共享,为YouTube的推荐系统排名组件带来了显著的改进。专家有助于改进从多种模态生成的复杂特征空间中学到的表示,而与共享底部模型相比,不需要显著增加更多的参数。由于特定于任务的门控,每个任务现在都有定制的融合,即它可以选择共享或不共享专家。
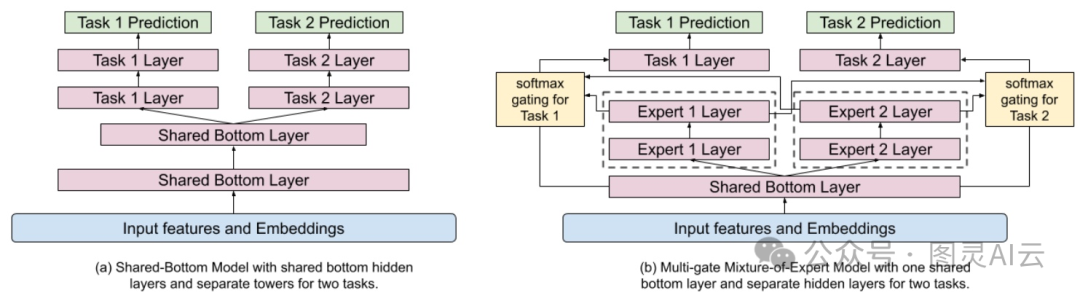
YouTube用多门控混合专家(MMoE)模型替换了他们的共享底部模型
如上图,YouTube搞了个MMoE模型,就是在共享的隐藏层上再加了些专家。理论上,如果直接从输入层开始学,可能会学得更好,但这样会多花不少银子和时间。所以YouTube为了省事儿,就给MMoE层送去了不那么复杂的输入。
谷歌这边也没闲着,他们想出了个用神经架构搜索(NAS)的方法,来自动学出一个更灵活的参数共享方式。Ma他们搞了个叫子网络路由(SNR)的框架,用一些能学的隐藏变量来控制不同子网络之间的连接,这样既保持了计算上的优势,又能让模型更灵活。
他们的方法就是一边学模型的结构,一边学模型的参数。这个结构是由一些潜在的二进制变量决定的,这些变量是从一些分布里来的。目标就是同时把这些变量和模型的参数都学好。虽然这样做让MMoE方法更灵活了,但也有一些过于简化的假设,学起来成本高,也不好扩展。
在多门控混合专家(MMoE)模型里,所有的任务都用同样的专家和注意力模块,这就意味着它没考虑到专家之间可能需要不同的处理。唐他们就发现这个问题,于是腾讯就提出了个新的多任务学习(MTL)模型,叫定制门控控制(CGC),把任务通用的专家和任务特定的专家分开,这样就能更好地处理任务之间的冲突。他们还把CGC扩展了一下,搞出了个渐进分层提取(PLE)的新方法,让信息传递更灵活。
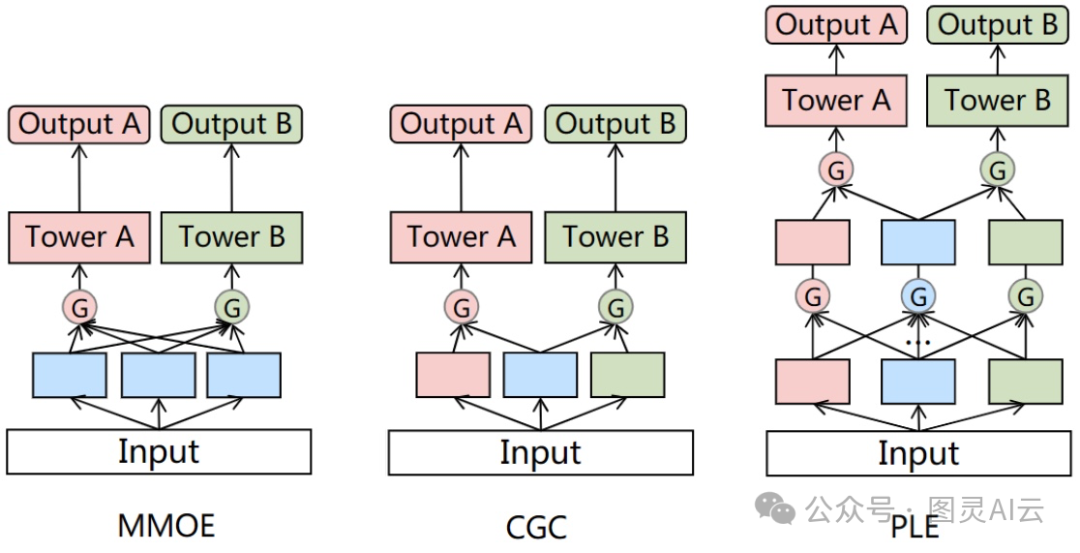
MMoE、CGC和PLE的比较。蓝色矩形代表共享层,粉色和绿色矩形代表特定于任务的层,粉色和绿色圆形代表不同任务的特定于任务的门控网络
CGC,也就是定制门控控制,它把每个任务的塔式网络和其他任务的专家网络之间的连接给切断了。这样,每个任务的专家就能专心学自己的东西,不会被其他任务的参数干扰。这些专家通过门控网络来接收自己网络和共享网络的信息,然后动态地混合这些信息。CGC把任务特有的部分和共享的部分分得很清楚。
但是,研究者们觉得,学习应该是一步步深入,逐渐学出更深层次的意思来。有时候,我们不太清楚中间学出的东西应该是大家都能用的,还是只对某个任务有用。所以,他们就把CGC升级成了PLE,也就是渐进分层提取,这个模型有多层门控网络,上层还有每个任务自己独立的参数。PLE把CGC的专家网络堆在一起,又加了一层提取网络。这层网络接收从下面网络传来的信息,然后逐渐学出更深入的意思,提取出更高级的共享信息。

刘等人研究的时候发现,多任务学习(MTL)模型处理的任务一多,效果就没那么好了,尤其是超过2到6个任务的时候。这导致在实际的排名服务中,大家会用两个甚至三个MTL模型来解决问题。为了改善这个状况,腾讯提出了一个叫多面层次多任务学习模型(MFH)的新框架,这个框架能够利用许多相关任务之间的内在联系,通过一个嵌套的层次结构来提高MTL的效率和扩展能力。
他们的核心想法是,在推荐系统中,不同的用户属性或特征(比如新用户、不活跃的用户和新内容)和预测结果之间的关系可能差异很大。如果直接用这些数据去训练模型,可能会导致模型在某些特征区域学得过于具体,也就是过拟合。特别是在数据样本不平衡或者不够多的区域,这个问题会更明显。为了在这些区域提高模型的准确性,一个直接的办法就是为每个区域设置一个单独的任务,比如区分新旧用户和内容。但这样做会导致任务数量急剧增加,变得难以处理。
为了解决这个问题,MFH在设计上用到了“开关器”这个概念。开关器就像一个神经网络的建筑块,它接受一个输入,然后分叉成两个或更多的潜在输出。这些输入可以是各种特征、嵌入向量或者中间的表示,输出则是一些潜在的表示,通常会被送到更高层的网络中去。这个开关器可以用在MTL结构中,比如共享底部、MMoE或者PLE模型里。
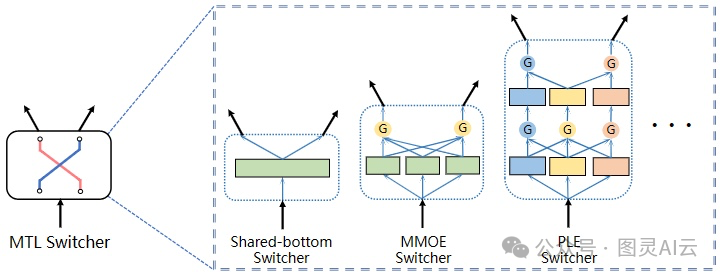
MTL开关器
咱们假设手头有三个任务:播放完成率(Cmpl)、播放完成率(Finish)和播放跳过率(Skip)。这些任务之前在“训练标签”那部分已经讲过了。要是咱们把每个任务再细分一下,分成新用户(New)、低活跃用户(Low)和高活跃用户(High)这三类,那任务数量一下子就变成9个了。研究者们还提出了一个“方面”的概念,用来把任务分到不同的组里。方面就像是每个任务都有的、互相垂直的维度。比如在这个9任务的设置里,每个任务都同时属于两个方面,一个是用户行为方面,比如 {Cmpl, Finish, Skip},另一个是用户群组方面,比如 {New, Low, High},每个方面都分成了3个小块。
下面这张图展示了一个两级层次的树状结构,这种结构叫做层次多任务学习(H-MTL),用来模拟这些任务之间的关系。在最底层,有一个开关器,它根据输入的特征来学习用户行为方面里各个任务之间的关系,然后连到上一层的三个多层感知器(MLP)。每个MLP都会输出一些隐藏的信息,这些信息再送到另一个开关器,这个开关器就负责学习基于用户行为的用户群组方面里各个任务之间的关系。
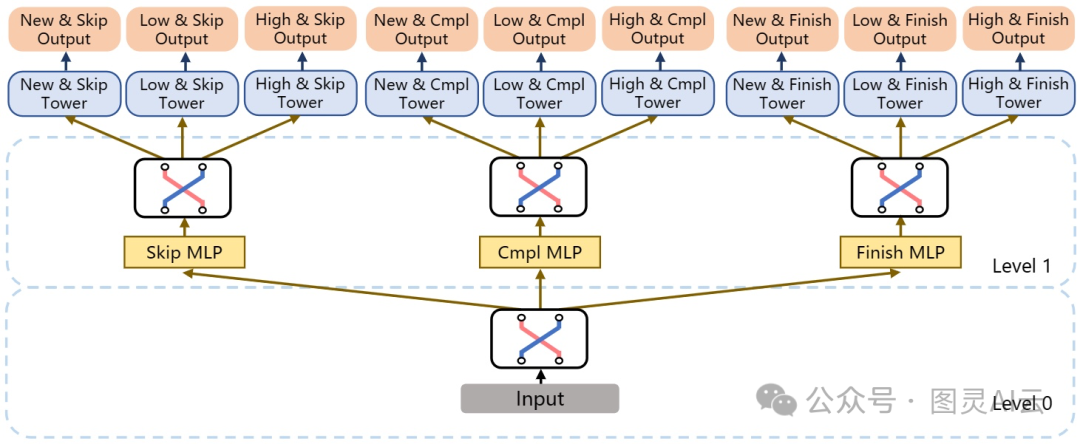
H-MTL模型架构
为了提升效率,MFH把好几棵H-MTL的树给嵌套起来用了。就像下图那样,在最底层,开关器学的是两个不同方面之间的关系,然后分叉到上一层的两个多层感知器(MLP)。更高层的结构,就是这两种H-MTL模型变体的混合体。
这种嵌套式的H-MTL结构,让模型能够在不同的层级上捕捉任务间的复杂联系,同时还能让计算保持在可处理的范围内。通过在较低的层级处理和特定方面有关的关系,在较高的层级处理跨方面的联系,MFH能更高效地处理那些有很多相关任务的大型推荐系统。这种结构不仅增强了模型的泛化能力,还有助于在保持模型易于理解的同时,处理好那些复杂多变的用户行为数据。
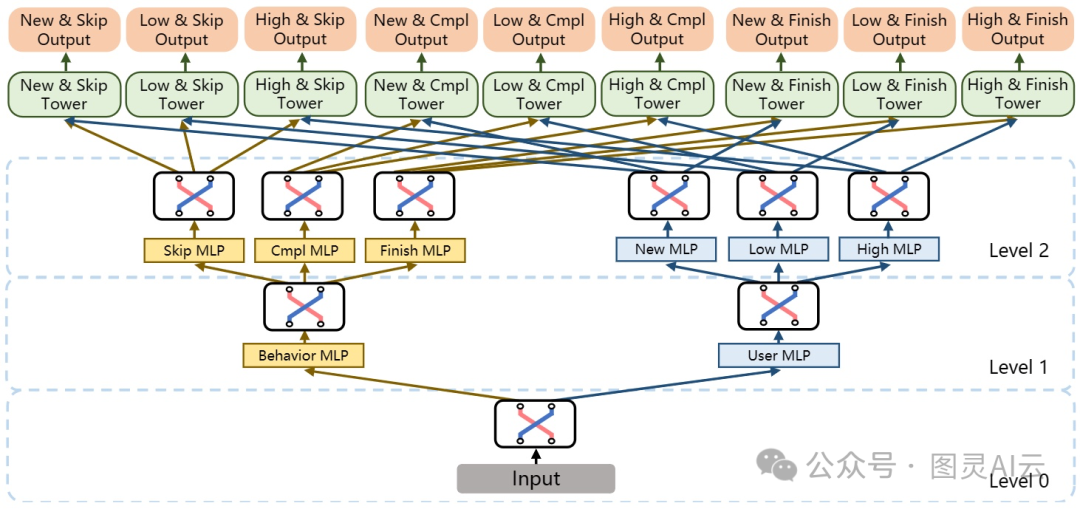
MFH模型架构
这篇文章深入地讨论了多任务学习(MTL)在大规模工业视频推荐系统中的应用。MTL这种方式特别适合视频推荐系统,因为它得同时预测好多不同的目标。通过共享模型参数,MTL还能节省计算资源。但是,传统的参数共享方式在任务之间关系不紧密的时候,可能会遇到一些问题,比如负迁移和跷跷板效应。还好,更灵活的软参数共享方式在一定程度上帮我们解决了这些问题。
文章里还重点介绍了一些实际的解决方案,这些方案来自不同公司部署的顶尖推荐系统。这些解决方案帮助我们更好地理解和应用MTL,让推荐系统能够更有效地为用户推荐他们可能喜欢的视频。

参考:
1. Covington, P., Adams, J.K., & Sargin, E. (2016). Deep Neural Networks for YouTube Recommendations. Proceedings of the 10th ACM Conference on Recommender Systems. [DOI link](https://dl.acm.org/doi/10.1145/2959100.2959190)
2. Zhuo, W., Liu, K., Xue, T., Jin, B., Li, B., Dong, X., Chen, H., Pan, W., Zhang, X., & Zhou, S. (2021). A Behavior-aware Graph Convolution Network Model for Video Recommendation. ArXiv. [arXiv link](https://arxiv.org/abs/2106.15402)
3. Kohavi, Ron & Deng, Alex & Frasca, Brian & Walker, Toby & Xu, Ya & Pohlman, Nils. (2013). Online Controlled Experiments at Large Scale. 10.1145/2487575.2488217. [DOI link](https://dl.acm.org/doi/10.1145/2487575.2488217)
4. Liu, J., Xia, Z., Lei, Y., Li, X., & Wang, X. (2021). Multi-Faceted Hierarchical Multi-Task Learning for a Large Number of Tasks with Multi-dimensional Relations. ArXiv, abs/2110.13365. [arXiv link](https://arxiv.org/abs/2110.13365)
5. Tang, H., Liu, J., Zhao, M., & Gong, X. (2020). Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. Proceedings of the 14th ACM Conference on Recommender Systems. [DOI link](https://dl.acm.org/doi/10.1145/3383313.3412236)
6. Li, D., Li, X., Wang, J., & Li, P. (2020). Video Recommendation with Multi-gate Mixture of Experts Soft Actor Critic. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. [DOI link](https://dl.acm.org/doi/10.1145/3397271.3401238)
7. Xin, S., Jiao, Y., Long, C., Wang, Y., Wang, X., Yang, S., Liu, J., & Zhang, J. (2022). Prototype Feature Extraction for Multi-task Learning. Proceedings of the ACM Web Conference 2022. [DOI link](https://dl.acm.org/doi/10.1145/3485447.3512090)
8. Ma, J., Zhao, Z., Chen, J., Li, A., Hong, L., & Chi, E.H. (2019). SNR: Sub-Network Routing for Flexible Parameter Sharing in Multi-Task Learning. AAAI Conference on Artificial Intelligence. [DOI link](https://aaai.org/ojs/index.php/AAAI/article/view/5384)
9. Pan, Y., Li, N., Gao, C., Chang, J., Niu, Y., Song, Y., Jin, D., & Li, Y. (2023). Learning and Optimization of Implicit Negative Feedback for Industrial Short-video Recommender System. ArXiv. [DOI link](https://doi.org/10.1145/3583780.3615482)
10. Song, J., Jin, B., Yu, Y., Li, B., Dong, X., Zhuo, W., & Zhou, S. (2022). MARS: A Multi-task Ranking Model for Recommending Micro-videos. APWeb/WAIM. [DOI link](https://link.springer.com/chapter/10.1007/978-3-031-22687-6_2)
11. Lubos, S., Felfernig, A., & Tautschnig, M. (2023). An overview of video recommender systems: state-of-the-art and research issues. Frontiers in Big Data, 6. [DOI link](https://www.frontiersin.org/articles/10.3389/fdata.2023/905793/full)
12. Zhao, Z., Hong, L., Wei, L., Chen, J., Nath, A., Andrews, S., Kumthekar, A., Sathiamoorthy, M., Yi, X., & Chi, E.H. (2019). Recommending what video to watch next: a multitask ranking system. Proceedings of the 13th ACM Conference on Recommender Systems. [DOI link](https://dl.acm.org/doi/10.1145/3343031.3350942)
13. https://blog.reachsumit.com/posts/2024/06/multi-task-video-recsys-p1/