Title
题目
Adversarial EM for variational deep learning: Application to semi-supervised image quality enhancement in low-dose PET and low-dose CT
对抗性EM用于变分深度学习:在低剂量PET和低剂量CT中的半监督图像质量增强应用
01
文献速递介绍
医学影像领域是当今医学诊断、筛查和治疗方案的重要组成部分。由于非侵入性成像技术可以更好地帮助诊断、治疗规划、治疗监测和外科干预,人们对其益处的依赖日益增加。两种广泛使用的成像技术是X射线计算机断层扫描(CT)和正电子发射断层扫描(PET)。
CT利用旋转的X射线管将X射线束穿过被检对象,然后由探测器测量射线能量。通过从不同角度进行多次测量,可以重建显示内部器官和组织结构细节的二维图像切片。这些二维切片叠加形成一个三维体积。与之相比,PET是一种功能性成像技术。在PET扫描前,放射性示踪剂被注入受检者的血流中。当放射性物质在受检者体内发生正电子衰变时,会释放出伽马光子,这些光子被扫描仪检测到。利用这些数据,PET成像可以显示体内的生理过程,例如血流、局部化学成分以及代谢过程的变化(Townsend等,2004)。
Abatract
摘要
In positron emission tomography (PET) and X-ray computed tomography (CT), reducing radiation dose cancause significant degradation in image quality. For image quality enhancement in low-dose PET and CT,we propose a novel theoretical adversarial and variational deep neural network (DNN) framework relying onexpectation maximization(EM) based learning, termed adversarial EM (AdvEM). AdvEM proposes an encoder–decoder architecture with a multiscale latent space, and generalized-Gaussian models enabling datum-specificrobust statistical modeling in latent space and image space. The model robustness is further enhancedby including adversarial learning in the training protocol. Unlike typical variational-DNN learning, AdvEMproposes latent-space sampling from the posterior distribution, and uses a Metropolis–Hastings scheme. Unlikeexisting schemes for PET or CT image enhancement which train using pairs of low-dose images with theircorresponding normal-dose versions, we propose a semi-supervised AdvEM (ssAdvEM) framework that enableslearning using a small number of normal-dose images. AdvEM and ssAdvEM enable per-pixel uncertaintyestimates for their outputs. Empirical analyses on real-world PET and CT data involving many baselines,out-of-distribution data, and ablation studies show the benefits of the proposed framework.
在正电子发射断层扫描(PET)和X射线计算机断层扫描(CT)中,降低辐射剂量可能会导致图像质量显著下降。为了解决低剂量PET和CT的图像质量增强问题,我们提出了一种基于期望最大化(EM)学习的全新对抗性和变分深度神经网络(DNN)框架,称为对抗性EM(AdvEM)。AdvEM采用编码器-解码器架构,具有多尺度潜在空间,并使用广义高斯模型,实现了在潜在空间和图像空间中的数据特异性稳健统计建模。模型的稳健性通过在训练过程中加入对抗学习进一步增强。
与典型的变分-DNN学习不同,AdvEM提出从后验分布中进行潜在空间采样,并使用Metropolis–Hastings方法。与现有的PET或CT图像增强方法不同,这些方法需要使用低剂量图像及其对应的正常剂量图像进行成对训练,我们提出了一种半监督AdvEM(ssAdvEM)框架,使得只需使用少量的正常剂量图像即可进行学习。AdvEM和ssAdvEM能够为其输出提供每像素不确定性估计。在涉及多个基线、分布外数据以及消融研究的实际PET和CT数据上的实证分析显示了所提框架的优势。
Method
方法
We propose a novel semi-supervised, adversarial and variationalDNN framework for image quality enhancement of low-dose PET andCT relying on EM based training and inference. This framework (Fig. 1)uses an encoder–decoder network architecture and leads to two variants: (i) AdvEM that is fully supervised, i.e., it employs paired trainingdata involving low-dose and normal-dose images, and (ii) its semisupervised counterpart ssAdvEM that trains without needing a normaldose image corresponding to every the low-dose image.
我们提出了一种新颖的半监督、对抗性和变分深度神经网络(DNN)框架,用于基于EM训练和推理的低剂量PET和CT图像质量增强。该框架(图1)采用编码器-解码器网络结构,形成了两种变体:(i) 完全监督的AdvEM,即使用包含低剂量和正常剂量图像的配对训练数据;(ii) 其半监督对应方法ssAdvEM,在训练时无需每张低剂量图像对应的正常剂量图像。
Conclusion
结论
We propose a brand-new adversarial and variational deep-learningframework, i.e., ssAdvEM, for semi-supervised image quality enhancement of low-dose PET and CT, where the variational modeling and learning relies on MCEM. Our MCEM framework is unlike typical variational deep-learning schemes, e.g., the VAE and its extensions, thatrely on the evidence lower bound (ELBO). During MCEM, our frame work models the posterior distribution of the latent-space variable andsamples from that posterior using the MH sampler. Unlike the sampling in typical variational deep-learning schemes, our posterior sampling leverages not only the encoder but also the decoder and the referenceimage. Furthermore, it combines a novel multiscale latent space with datum-specific robust GG modeling to yield a framework that can workwell for both (i) in-distribution images and (ii) OOD images that result from very low doses. ssAdvEM introduce adversarial learning into our own novel method termed ss-NonAdv-EM whose preliminary versionappeared in Sharma et al. (2022). The addition of adversarial learning can further improve the robustness of the proposed framework, showing significant performance improvement for OOD images, as seen inSections 4.3 and 4.4. Our proposed adaptation of the MCEM frameworkto semi-supervised learning enables training using a very small amountof high-quality images, thereby providing a powerful tool in overcom ing practical challenges of dataset availability. Both our frameworks of ssAdvEM and ss-NonAdv-EM are able to outperform other unsupervisedand semi-supervised frameworks such as N2N, DIP, and N2N+UNet (a baseline framework we proposed for fair comparison). Additionally, they also outperform prior-model-based methods like TV denoising andBM3D/BM4D. Another important aspect of the proposed framework is its ability to enable uncertainty estimation that the other methods ignore. The ablation studies in Section 4.6 demonstrate the benefits of (i) adversarial learning, (ii) variational modeling, (iii) GG loss, and (iv) multiscale latent space, towards building an effective and robust framework for low-dose PET and CT enhancement.
我们提出了一种全新的对抗性和变分深度学习框架,即ssAdvEM,用于低剂量PET和CT的半监督图像质量增强,其中变分建模和学习依赖于MCEM(蒙特卡洛期望最大化)。与典型的变分深度学习方案(如VAE及其扩展)依赖于证据下界(ELBO)不同,我们的MCEM框架在过程中过对潜在空间变量的后验分布进行建模,并使用MH采样器从该后验分布中采样。与典型变分深度学习方案中的采样不同,我们的后验采样不仅利用编码器,还利用解码器和参考图像。此外,该框架结合了一种新颖的多尺度潜在空间和数据特异性的稳健广义高斯(GG)建模,使其在(i)分布内图像和(ii)因超低剂量产生的分布外(OOD)图像上均表现良好。
ssAdvEM将对抗学习引入我们自己提出的新方法ss-NonAdv-EM,该方法的初步版本已在Sharma等人(2022年)中出现。通过增加对抗学习,可以进一步提高所提出框架的稳健性,对OOD图像的性能有显著改善,如第4.3节和4.4节所示。我们将MCEM框架适配于半监督学习,允许使用非常少量的高质量图像进行训练,从而为解决数据集可用性方面的实际挑战提供了有力工具。我们的ssAdvEM和ss-NonAdv-EM框架均能够超越其他无监督和半监督框架,如N2N、DIP和N2N+UNet(我们为公平比较而提出的基线框架)。此外,它们也优于之前的模型基方法,如TV去噪和BM3D/BM4D。
该框架的另一个重要方面是能够实现其他方法忽略的不确定性估计。第4.6节中的消融研究展示了(i)对抗学习、(ii)变分建模、(iii)GG损失和(iv)多尺度潜在空间在构建一个有效和稳健的低剂量PET和CT增强框架中的益处。
Results
结果
This section describes the dataset, the baselines, the results including ssAdvEM and the baseline methods, the results of all methods onOOD images, the ablation studies for ssAdvEM, and the computationaltime analysis for ssAdvEM and the baselines..We define the level of supervision 𝛾 as the proportion of the numberof paired low-dose and normal-dose images (||) in the entire trainingset ( ∪ ), i.e., 𝛾 ∶= ||∕(| ∪ |).
本节介绍数据集、基线方法、包括ssAdvEM和基线方法在内的结果、所有方法在分布外(OOD)图像上的结果、ssAdvEM的消融研究,以及ssAdvEM与基线方法的计算时间分析。
我们定义监督水平 𝛾 为整个训练集中成对的低剂量和正常剂量图像的数量(||)所占的比例,即 𝛾 := || / (| ∪ |)。
Figure
图

Fig. 1. Semi-Supervised Adversarial Expectation Maximization (ssAdvEM) framework. (a) In the fully-supervised AdvEM framework, the input to the DNN is a low-doseimage 𝑋, and the reference image at the output end 𝑌 is the corresponding normal-dose image 𝑍. In ssAdvEM, for some input images 𝑋, the reference image 𝑌 is another imageat a low dose, instead of the normal-dose image 𝑍. (b) Each encoder block outputs a generalized-Gaussian (GG) distribution at one scale ofthe multiscale latent space 𝐻.
图 1. 半监督对抗性期望最大化 (ssAdvEM) 框架。
(a) 在完全监督的AdvEM框架中,输入到深度神经网络(DNN)的图像是低剂量图像 𝑋,输出端的参考图像 𝑌 是相应的正常剂量图像 𝑍。在ssAdvEM框架中,对于某些输入图像 𝑋,参考图像 𝑌 是另一张低剂量图像,而不是正常剂量图像 𝑍。(b) 每个编码器模块在多尺度潜在空间 𝐻 的一个尺度上输出广义高斯(GG)分布。
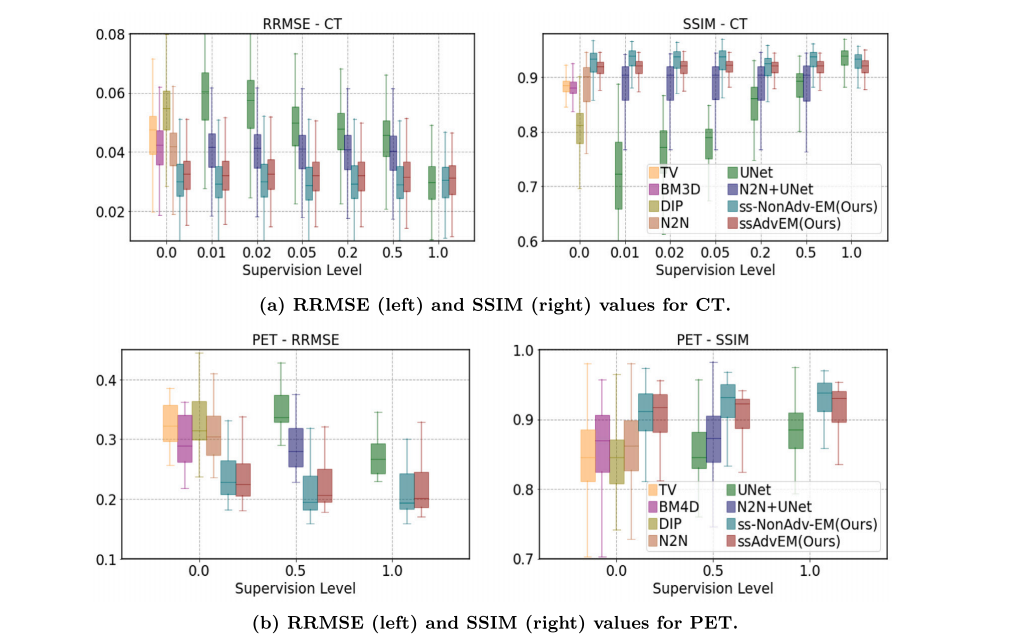
Fig. 2. Results: Quantitative. Results of quality enhancement of low-dose (a) CT and (b) PET images at varying levels of supervision 𝛾, for all methods, showing boxplots of RRMSE and SSIM values across the test set.
图 2. 结果:定量分析。低剂量(a) CT和(b) PET图像在不同监督水平 𝛾 下的质量增强结果,展示了所有方法在测试集上的相对均方根误差(RRMSE)和结构相似性(SSIM)值的箱线图。
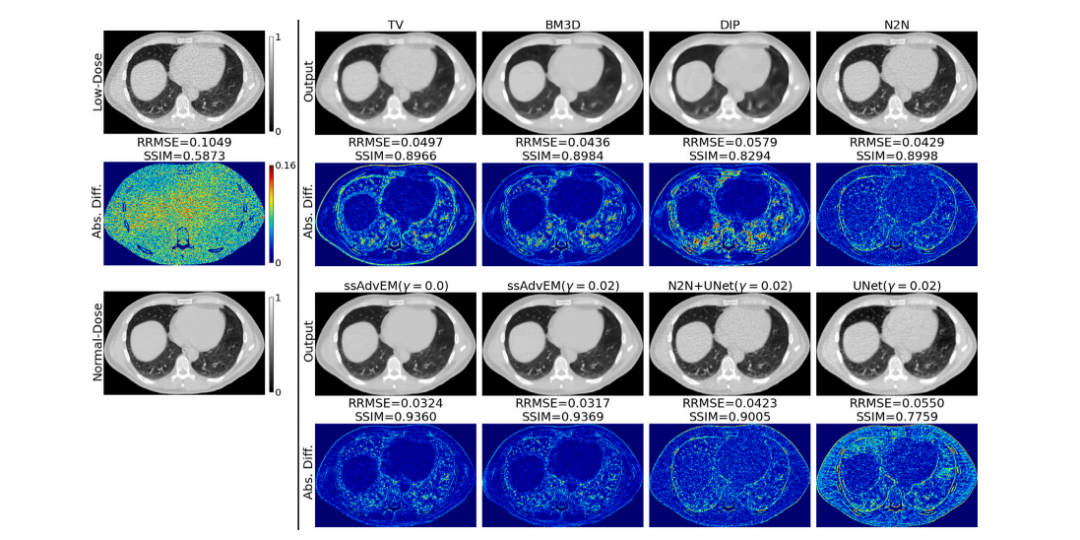
Fig. 3. Results: Qualitative - CT. Quality enhancement of low-dose images, showing image outputs and their corresponding images showing per-pixel difference magnitudesbetween the output and the ground truth.
图 3. 结果:定性分析 - CT。低剂量图像的质量增强结果,显示了图像输出及其对应的每像素差异幅度图像,展示输出与真实图像之间的差异。
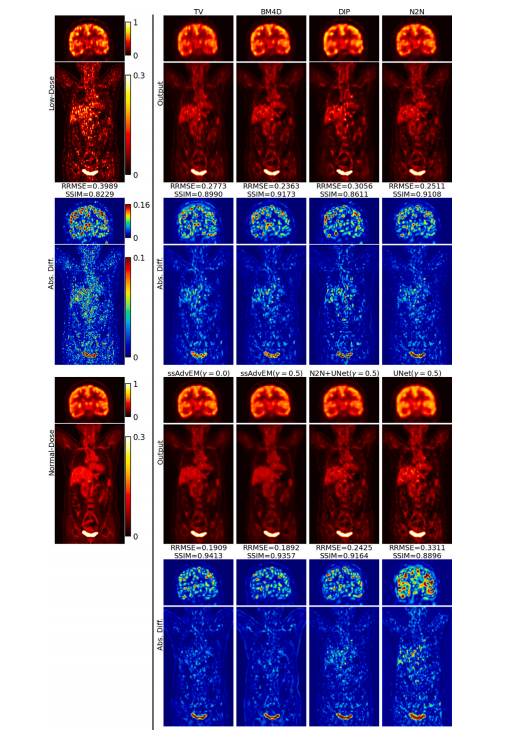
Fig. 4. Results: Qualitative - PET. Quality enhancement of low-dose images, showing image outputs and their corresponding images showing per-pixel difference magnitudesbetween the output and the ground truth. For better visualization, the head and the torso regions use different colormaps to maintain contrast and avoid saturation..
图 4. 结果:定性分析 - PET。低剂量图像的质量增强结果,显示了图像输出及其对应的每像素差异幅度图像,展示输出与真实图像之间的差异。为了更好的可视化效果,头部和躯干区域使用不同的颜色映射来保持对比度并避免饱和。
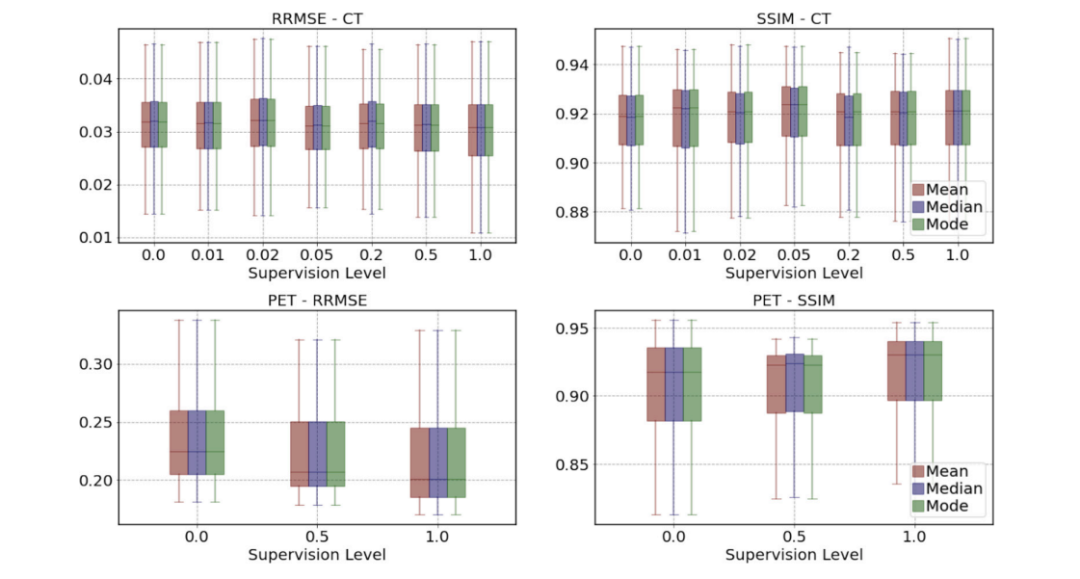
Fig. 5. Results: Analysis of Bayesian inference schemes. At varying levels of supervision 𝛾, quantitative results corresponding to the mean, median, and mode of the output set .
图 5. 结果:贝叶斯推断方案分析。在不同监督水平 𝛾 下,输出集 对应的平均值、中位数和众数的定量分析结果。
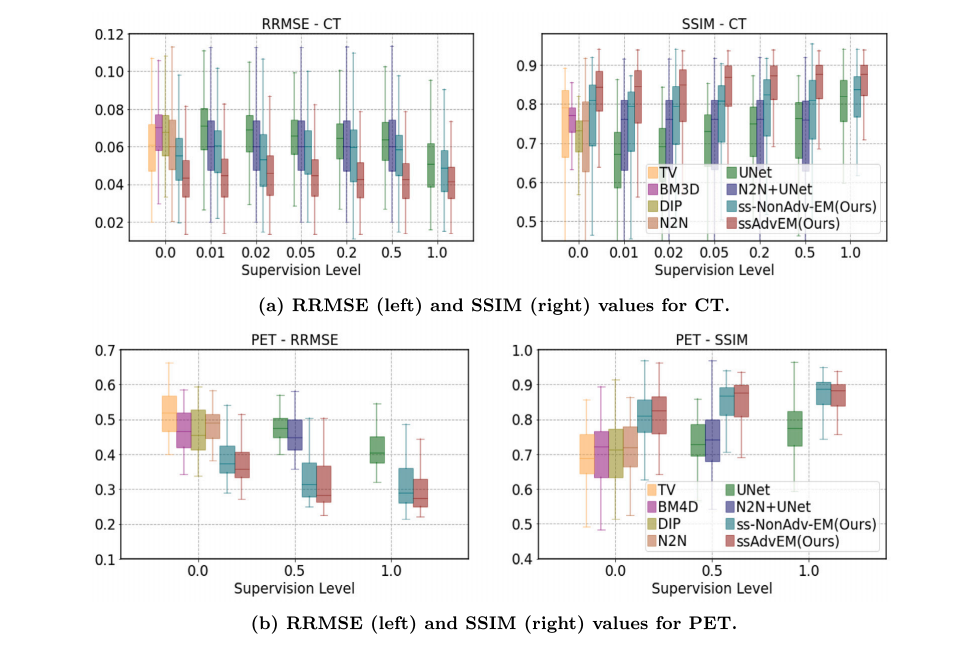
Fig. 6. Results on OOD images: Quantitative. Results of image quality enhancement of very-low-dose (a) CT and (b) PET images at varying levels of supervision 𝛾, for allmethods, showing boxplots of RRMSE and SSIM values across the test set.
图 6. 分布外(OOD)图像结果:定量分析。在不同监督水平 𝛾 下,各种方法对超低剂量 (a) CT和 (b) PET图像的质量增强结果,展示了测试集中相对均方根误差(RRMSE)和结构相似性(SSIM)值的箱线图。

Fig. 7. Results on OOD Images: Qualitative - CT. Results of image quality enhancement of very-low-dose images, showing image outputs and their corresponding versionsshowing per-pixel difference magnitudes between the output and the ground truth.
图 7. 分布外(OOD)图像结果:定性分析 - CT。超低剂量图像的质量增强结果,展示了图像输出及其对应的每像素差异幅度图像,显示输出与真实图像之间的差异。
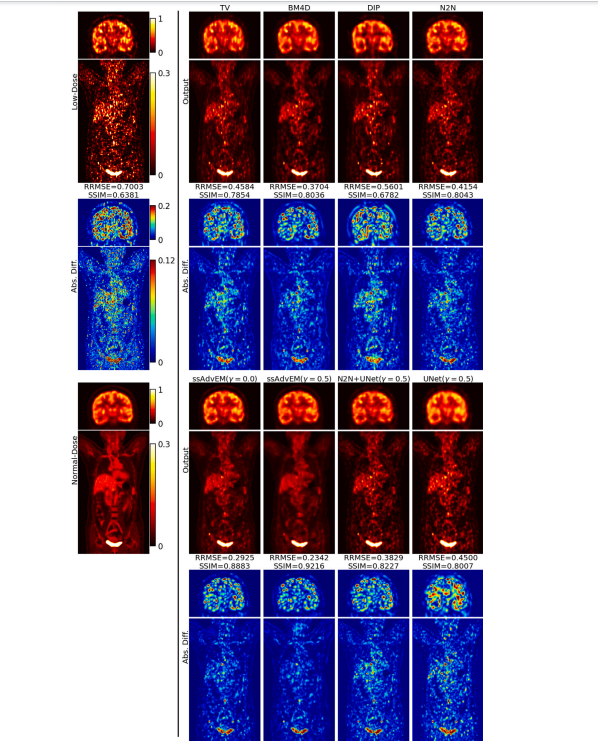
Fig. 8. Results on OOD Images: Qualitative - PET. Results of image quality enhancement of very-low-dose images, showing image outputs and their corresponding versionsshowing per-pixel difference magnitudes between the output and the ground truth. For better visualization, the head and the torso regions use different colormaps..
图 8. 分布外(OOD)图像结果:定性分析 - PET。超低剂量图像的质量增强结果,展示了图像输出及其对应的每像素差异幅度图像,显示输出与真实图像之间的差异。为了更好的可视化效果,头部和躯干区域使用了不同的颜色映射。
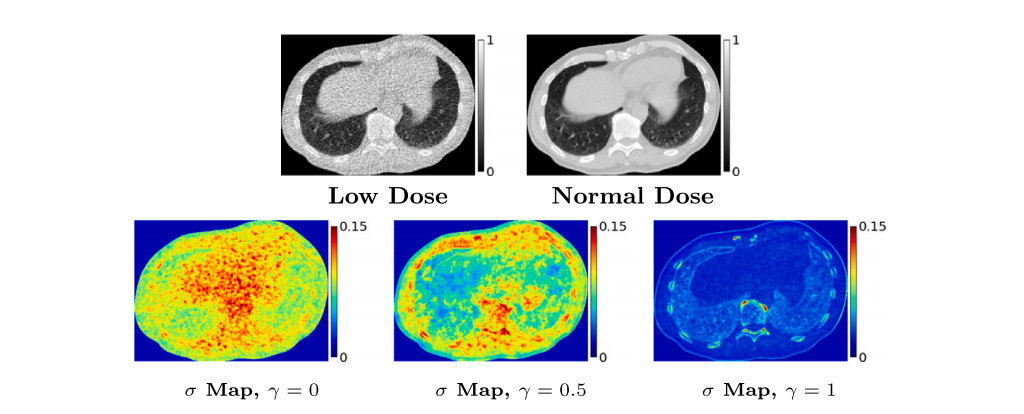
Fig. 9. Results: Visualizing per-pixel uncertainty in the output for CT. At varying levels of supervision 𝛾, the per-pixel standard-deviation (𝜎) maps of the output set foran example CT image. Overall, the 𝜎 magnitudes reduce as the supervision 𝛾 increases.
图 9. 结果:CT输出中每像素不确定性的可视化。在不同监督水平 𝛾 下,展示一个示例CT图像的输出集 的每像素标准差 (𝜎) 图。总体来看,随着监督水平 𝛾 的增加,𝜎 的幅度逐渐减小。
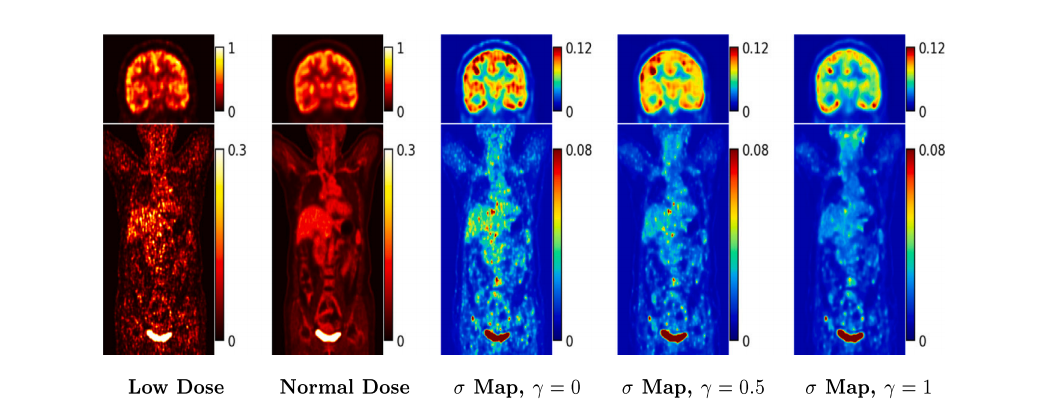
Fig. 10. Results: Visualizing per-pixel uncertainty in the output for PET. At varying levels of supervision 𝛾, the per-pixel standard-deviation (𝜎) maps of the output set for an example PET image. Overall, the 𝜎 magnitudes reduce as the supervision 𝛾 increases.
图 10. 结果:PET输出中每像素不确定性的可视化。在不同监督水平 𝛾 下,展示一个示例PET图像的输出集 的每像素标准差 (𝜎) 图。总体来看,随着监督水平 𝛾 的增加,𝜎 的幅度逐渐减小。
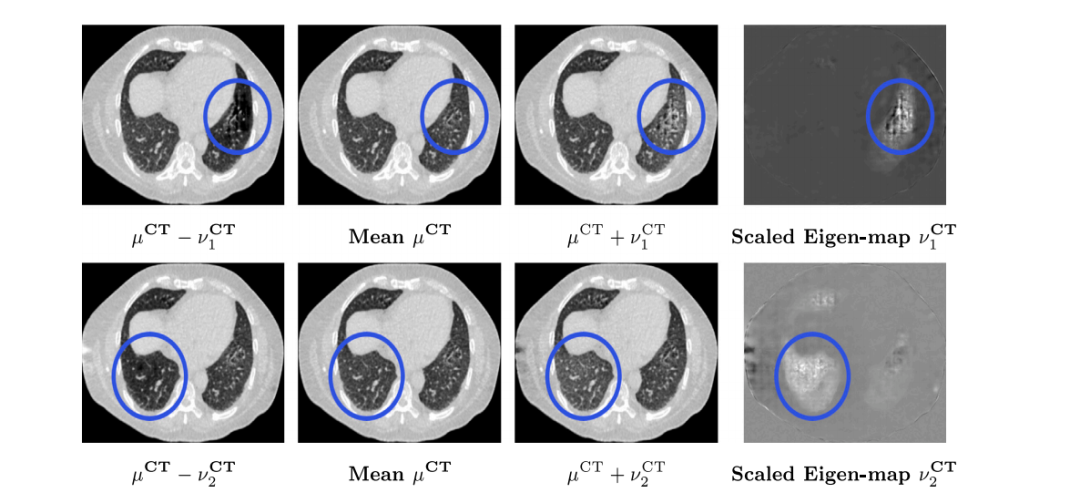
Fig. 11. Results: Visualizing variability in the output distribution through its principal modes of variation. First two principal modes of variation for CT.
图 11. 结果:通过主变化模式可视化输出分布的变异性。CT的前两个主变化模式。
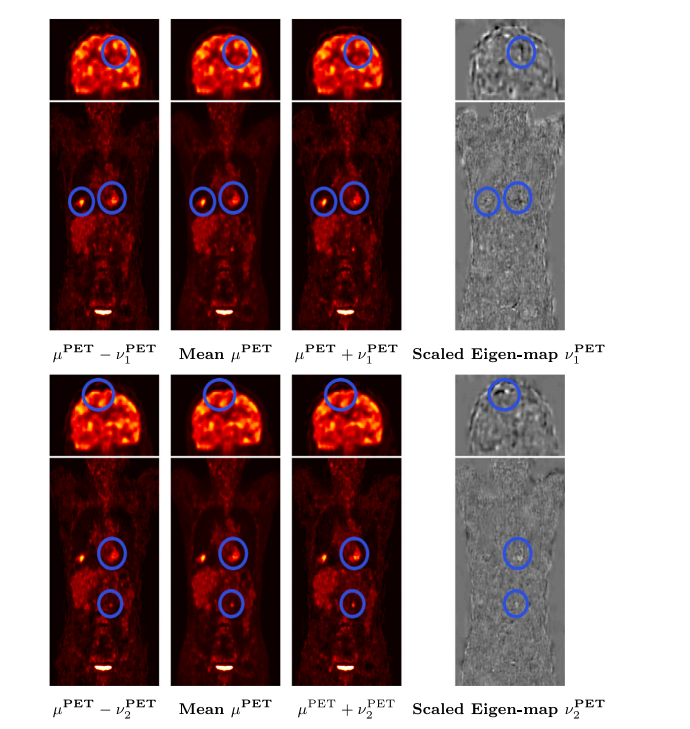
Fig. 12. Results: Visualizing variability in the output distribution through its principal modes of variation. First two principal modes of variation for PET
图 12. 结果:通过主变化模式可视化输出分布的变异性。PET的前两个主变化模式。
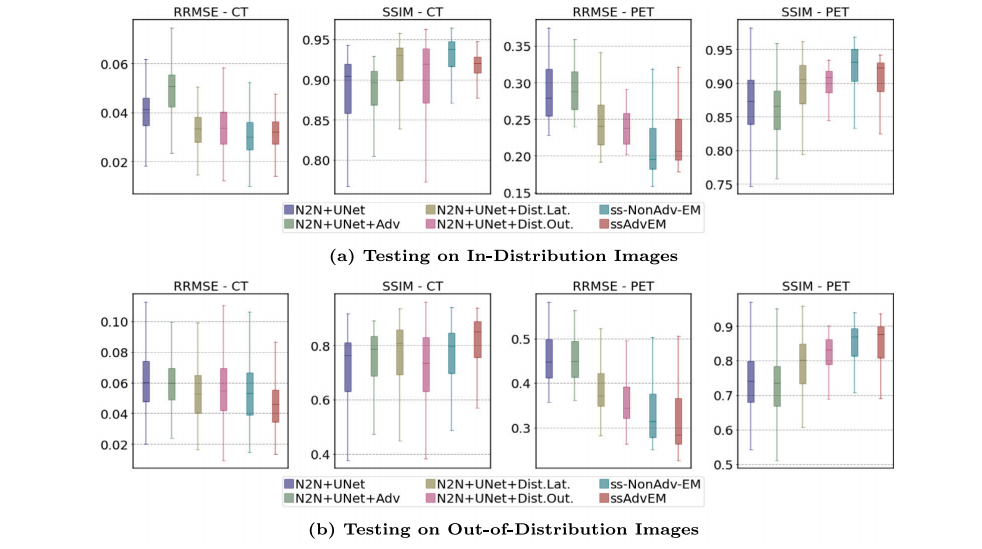
Fig. 13. Ablation studies: Modeling and training. Performance of six semi-supervised methods (at 𝛾 = 0.02 for CT; at 𝛾 = 0.5 for PET): (i) N2N+UNet, (ii) N2N+UNet+Adv thatadds adversarial learning to N2N+UNet, (iii) N2N+UNet+DistLat that adds EM-based distribution modeling to the latent space for N2N+UNet, (iv) N2N+UNet+DistOut that addsGG distribution modeling at N2N+UNet’s decoder output, (v) ss-NonAdv-EM that adds both DistLat and DistOut to N2N+UNet, and (vi) ssAdvEM that adds adversarial learning toss-NonAdv-EM. Results for tests on (a) in-distribution images and (b) OOD images.
图 13. 消融研究:建模和训练。六种半监督方法的性能比较(在CT中 𝛾 = 0.02;在PET中 𝛾 = 0.5):(i) N2N+UNet,(ii) N2N+UNet+Adv,在N2N+UNet中加入对抗学习,(iii) N2N+UNet+DistLat,在N2N+UNet的潜在空间中加入基于EM的分布建模,(iv) N2N+UNet+DistOut,在N2N+UNet的解码器输出处加入GG分布建模,(v) ss-NonAdv-EM,将DistLat和DistOut都加入N2N+UNet,(vi) ssAdvEM,在ss-NonAdv-EM中加入对抗学习。结果包括对(a) 分布内图像和 (b) 分布外(OOD)图像的测试结果
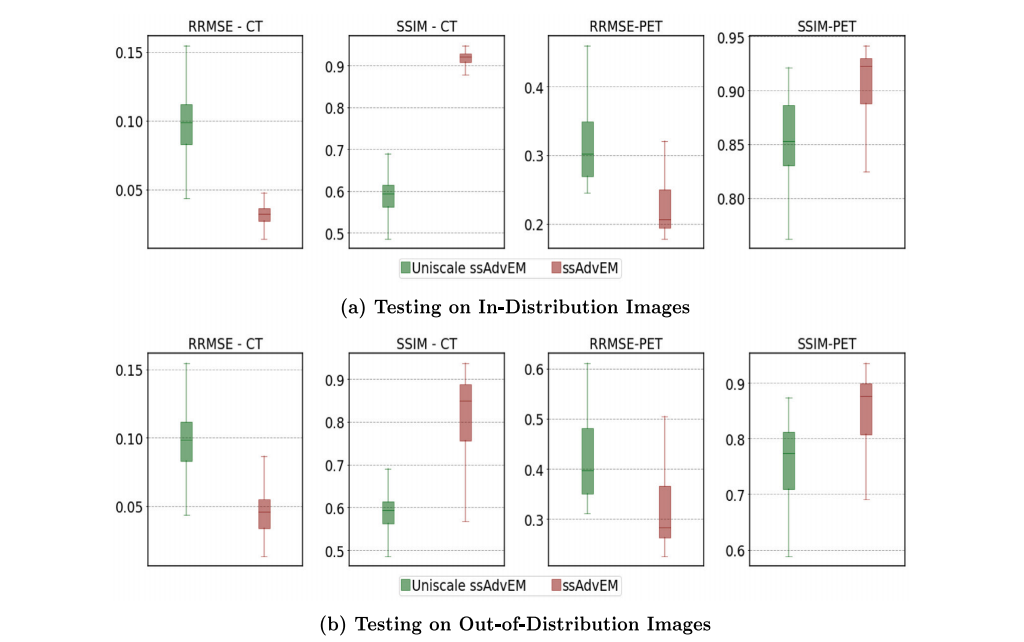
Fig. 14. Ablation studies: Effect of multiscale latent space. Performance of two semi-supervised methods (at 𝛾 = 0.02 for CT; at 𝛾 = 0.5 for PET): (i) standard ssAdvEM frameworkwith multiscale latent space. (ii) ablated ssAdvEM framework with a uniscale latent space similar to that used in VAE-based methods. Results for tests on (a) in-distribution imagesand (b) OOD images.
图 14. 消融研究:多尺度潜在空间的效果。两种半监督方法的性能比较(在CT中 𝛾 = 0.02;在PET中 𝛾 = 0.5):(i) 使用多尺度潜在空间的标准ssAdvEM框架,(ii) 使用与基于VAE方法相似的单尺度潜在空间的简化ssAdvEM框架。结果包括对(a) 分布内图像和 (b) 分布外(OOD)图像的测试结果。






