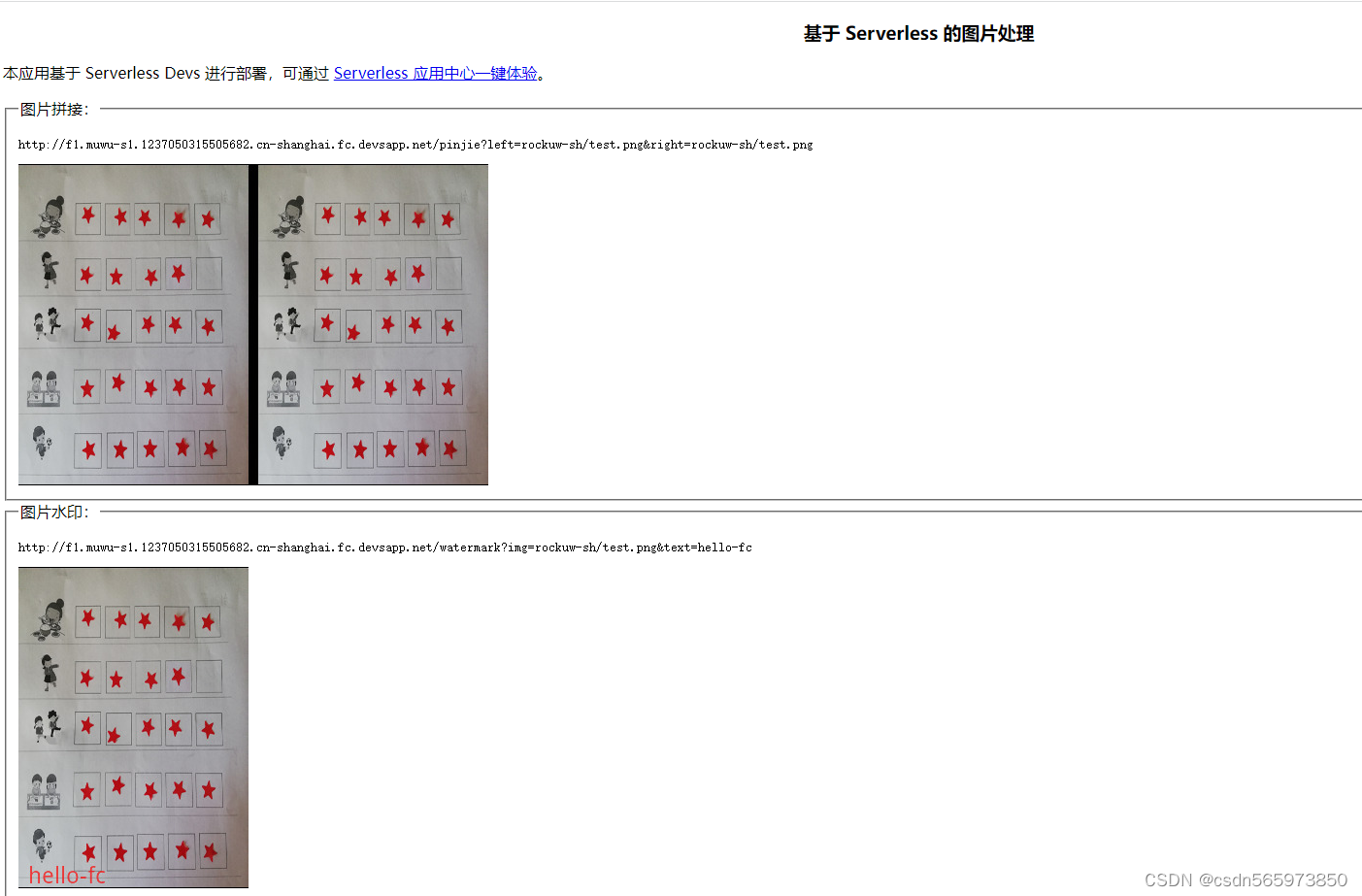
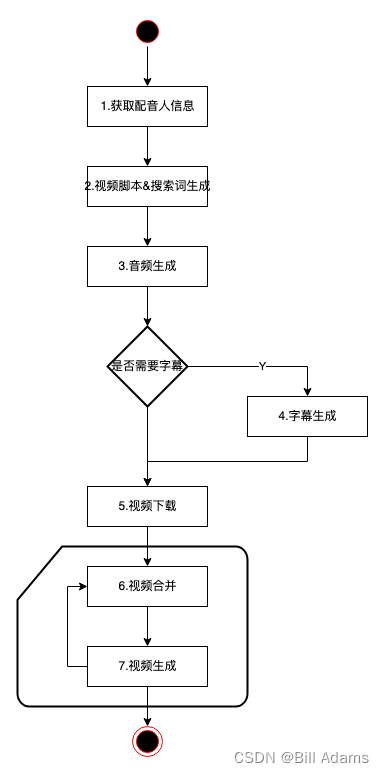
1. 整体流程
第一步,加载视频/图片和音频/tts。用melspectrogram将wav文件拆分成mel_chunks。
第二步,调用face_detect模型,给出人脸检测结果(可以改造成从文件中读取),包装成4个数组batch:img_batch(人脸),mel_batch(语音),frame_batch(原图),coords_batch(坐标)
第三步,加载模型,进行计算。这个模型目前看下来就是简单的resnet,没有transfomer。另外mask也不是用分割模型,而是直接将图片下半部分全部作为mask😄,然后将mask图片拼接到原图片的色彩通道上作为输入。
第四步:预测出来的人脸拼接到原图上,输出位视频。
2. 优缺点
优点:极其简单,一个人脸检测模型+一个基于CNN的lipsync模型,速度很快。
缺点:嘴唇经常是歪的,而且有变形;牙齿不断在闪烁。经过图像增强后,我们取出截图如下: