DolphinDB 高性能分布式数据库>时序数据库,具有分布式计算、事务支持、多模存储、以及流批一体等能力,非常适合作为一款理想的轻量级大数据平台,轻松搭建一站式的高性能实时数据仓库。
本教程将以案例与脚本的方式,介绍如何通过 DolphinDB 快速搭建实时数仓,助力各个行业(如能源电力、航空航天、车联网、石油化工、矿业、智能制造、贸易政务、金融等)在复杂业务场景下快速实现海量数据的低延时复杂指标计算和分析。
本教程包括原理介绍和实践操作,配套示例代码,用户可以根据教程,结合自身业务特点,动手搭建一个轻量级高性能的实时数据仓库。
1. 引言
1.1 案例背景与需求
随着大数据时代的来临,各行各业对数据处理的实时性和准确性要求越来越高。传统的离线数仓,虽然能够在一定程度上满足企业的数据存储和离线分析需求,但在处理大规模实时数据时,往往显得力不从心。尤其是在对数据实时性要求非常高的物联网和金融的头部企业,离线数仓的局限性更加明显。
以电力行业的发电厂为例,每个发电厂都拥有大量的测点,这些测点实时采集着电站的运行数据。如何结合海量的电站运行数据,对实时数据进行精准复杂的计算和分析,成为了发电厂面临的一大挑战。传统的实时数据库欠缺对海量数据的聚合分析与计算能力,而传统大数据系统搭建的离线数仓由于处理速度慢、时延高、架构复杂,难以满足更深层次的业务需求。
DolphinDB 作为一款轻量级一站式实时数仓解决方案,凭借其高性能分布式计算框架、实时流数据处理能力、分布式多模态存储引擎以及内存计算技术,成为了解决这一问题的理想选择。
本文将通过 DolphinDB 实现一个典型的发电侧需求场景。在发电侧 4万个测点秒采样的情况下,实时获取每个测点在1分钟、5分钟、30分钟、小时、天、月、直至最近1年的各项测点指标(最大值、最小值、平均值、中位数、95%分位数、5%分位数、变化量、变化率、开始值、结束值等),并且实现毫秒级查询响应。这些指标对于电站的运行监控、故障预警、能效分析,大数据展示等方面至关重要。
1.2 数据仓库的基本概念
数据仓库(Data Warehouse,简称 DW 或 DWH)是一种用于存储、处理和分析大量数据的系统,旨在支持特定业务场景下的决策制定过程。数据仓库也是一种技术架构,能够汇集并融合来自多个数据源(如MySQL、Oracle、MongoDB、HBase 等)的异构数据(如数据表、Json、CSV、Protobuf 等),通过数据清洗、集成和转换,将数据整合至统一的存储体系(如 DolphinDB,Hadoop)中,从而支持业务的多维分析、数据挖掘以及精准决策。

1.1 传统数据仓库典型架构图
数据仓库的重要性在于它能够帮助企业实现数据的集中管理和高效利用,根据用途和实时性区分,可以分为离线数仓和实时数仓两种类型。
离线数据仓库通常采用 T -1 的方式实现,即每天定时(如凌晨)通过作业任务将前一天的历史数据导入数据仓库,再通过 OLAP(Online Analytical Processing) 对海量历史数据(批数据)进行分析查询。
对于大部分企业来说,业务上迫切需要 T +0 实现实时风控、实时效果分析、实时过程管控等功能。传统离线数仓无法满足实时性要求,因此出现了兼顾实时性和分析性的新型数据仓库架构,即实时数仓。
实时数仓在技术要求和实现难度上,要远远超过传统的数据仓库。相比传统数仓来说,实时数仓可以更高效的数据处理能力和实时(准实时)的数据更新频率。在低延时的性能要求下,需要解决数据源异构性、数据质量控制、事务和强一致性、多模存储、高性能聚合分析等技术难题。并且,如何让普通开发人员具备实时数仓的开发和运维能力,并持续稳定的进行产品迭代,也是非常大的考验。
1.3 传统的实时数仓典型架构
传统的实时数仓,通常以 Hadoop 大数据框架为基础,使用 Lambda 架构或 Kappa 架构。技术复杂,开发周期长,无论在开发人员成本、时间成本还是硬件投入成本等方面来看,对企业都是极大的负担。
传统实时数仓典型的技术栈如下所示:
- 采集(Sqoop、Flume、Flink CDC、DataX、Kafka)
- 存储(HBase、HDFS、Hive、MySQL、MongoDB)
- 数据加工和计算(Hive、Spark、Flink、Storm、Presto)
- OLAP 分析及查询(TSDB/HTAP、ES、Kylin、DorisDB)
企业要落地应用传统的实时数仓,将会面临学习成本高、资源消耗大、扩展性和实时性不足等诸多问题。
1.4 DolphinDB 实时数仓架构与性能
与复杂的传统实时数仓不同,DolphinDB 可通过自身产品能力,快速实现轻量级实时数仓。既可独立进行采集、存储、流计算、ETL、决策分析与计算、可视化展示。亦可以作为企业已部署的各类第三方应用(如大数据平台、AI 中台、驾驶舱)的有效补充,为企业级应用系统、集团级数据中台提供实时数仓的技术支撑,以实现更复杂的应用场景。

DolphinDB 实时数仓业务架构图
DolphinDB 在物联网和金融等各行各业均拥有丰富且成熟的数据仓库实践案例,充分展现了其广泛的应用价值。
以某省海关电子口岸公司的实时数仓项目为例,DolphinDB 构建的实时数仓充分发挥了 All In One 轻量级一站式的产品优势。支持多源异构数据的接入,兼容标准 SQL ,支持复杂的多表关联,强大的 ETL 数据清洗能力,极大缩短了数据处理链条,减少运维和开发成本。其业务架构及技术特点如下图所示:

某省电子口岸实时数仓项目业务架构图
以下是在三机高可用集群部署的情况下,DolphinDB 可支持的实时数仓性能指标参考:
- 测点数量支持:>1亿测点
- 写入吞吐量:>1亿测点/秒
- ODS 支持存储的记录数:> 1万亿条
- 客户端最大连接数:>5000
- 并发查询(QPS):> 5000
- 多维度聚合查询:毫秒级
- 实时流计算特征值提取:>50万/秒
- 单条记录、单进程的删改(软删除、upsert)同步耗时:≈ 10ms
- 高可用集群:多副本(数据高可用),多控制节点(元数据高可用),客户端断线重连和故障切换(客户端高可用)
- 弹性扩展:不停机水平扩展(加节点)、不停机垂直扩展(加磁盘卷),支持灰度升级
2. DolphinDB 实时数仓实践
接下来,我们将以水电站发电机组设备实时监控的真实需求为案例,通过 DolphinDB 搭建轻量级实时数仓。该案例可应用于能源电力、工业物联网、车联网等行业中。
欢迎大家动手尝试,一起来验证一下!
2.1 DolphinDB 安装部署
1. 下载官网社区最新版,建议2.00.11及以上版本。
传送门:https://cdn.dolphindb.cn/downloads/DolphinDB_Win64_V2.00.11.3.zip
2. windows 解压路径,不能有空格,避免安装到 Program Files 路径下。
官网教程:https://docs.dolphindb.cn/zh/tutorials/deploy_dolphindb_on_new_server.html
3. 本次测试使用企业版,license 可申请免费试用。如使用免费社区版,建议降低测试的数据量级。
获取方式:https://dolphindb.cn/product#downloads
4. 安装及测试过程中,有任何问题,可后台私信咨询。
2.2 实时数仓指标需求
- 数据基本情况
测点个数:40000
采样频率:秒级
- 计算指标(聚合值)

2.3 实践方案规划
以 DolphinDB 流计算框架为基础,搭建边缘端轻量级实时数仓。所有计算结果在数据写入的同时高效完成,时延控制在毫秒级。

- 对于1分钟计算周期、5分钟计算周期的指标,以原始实时数据为基表;
- 对于30分钟计算周期、1小时计算周期的指标,以1分钟计算结果为基表;
- 对于24小时计算周期指标,以5分钟计算结果作为基表;
- 对于1年计算周期指标,以24小时计算结果作为基表。
每类指标的计算窗口及滑动步长如下表所示:
| 计算周期 | 窗口长度 | 滑动步长 | 备注 |
|---|---|---|---|
| 1分钟 | 1分钟 | 1分钟 | 每间隔1分钟,对过去1分钟窗口内的值进行计算 |
| 5分钟 | 5分钟 | 5分钟 | 每间隔5分钟,对过去5分钟窗口内的值进行计算 |
| 30分钟 | 30分钟 | 30分钟 | 每间隔30分钟,对过去30分钟窗口内的值进行计算 |
| 1小时 | 1小时 | 1小时 | 每间隔1小时,对过去1小时窗口内的值进行计算 |
| 24小时 | 24小时 | 24小时 | 每间隔24小时,对过去24小时窗口内的值进行计算 |
| 1年 | 1年 | 24小时 | 每间隔1天,对过去1年窗口内的值进行计算 |
3. 性能测试及结果
3.1 测试环境
为了方便测试和验证,采用单机单节点的部署方式实现轻量级实时数仓,服务器配置如下:
- CPU:12核
- 内存:32GB
- 磁盘:1.1T HDD 150MB/s
通过脚本模拟全量测点(40000)24小时内的实时数据(2023.01.01T00:00:00—2023.01.02T00:00:01.000),进行 1分钟、5分钟、30分钟、1小时、24小时的窗口聚合计算,并将计算结果写入分布式数据库。(在某个窗口内,数据条数有可能比窗口长度要小)
对于1年窗口的计算,另模拟24小时窗口计算结果实时数据,对该模拟的结果进行实时聚合计算。
详细的测试脚本,包含在文末的附件中。
3.2 测试结果
性能测试结果见下表:
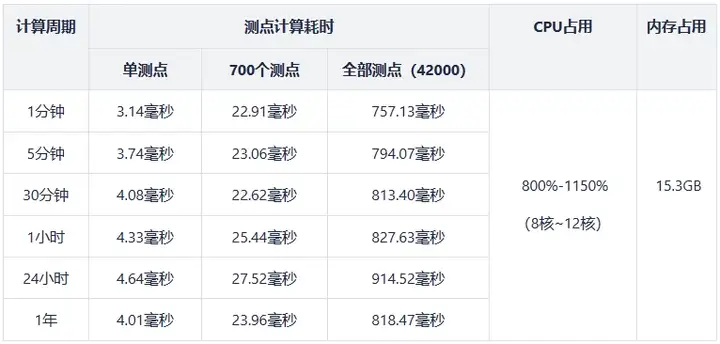
注:上表中,全部测点计算耗时为时间窗口内所有测点指标计算的耗时;单测点/多测点计算耗时为时间窗口内所选测点指标计算的耗时。
4. 总结
通过本教程的学习和实践,我们深入了解了 DolphinDB 在构建轻量级实时数仓方面的强大能力。DolphinDB 以其高性能、分布式、实时计算的特点,为各个行业提供了快速实现海量数据低延时复杂指标计算和分析的有力工具。
通过实践操作,我们可以体验到了 DolphinDB 的易用性和高效性。无论是数据导入、数据查询还是复杂的流式计算,DolphinDB 都提供了简洁明了的语法和强大的功能。附件中所提供的脚本不仅包括 DolphinDB 的基本使用和操作方法,更能够深入了解实时数仓的构建原理和应用场景。这使得我们可以快速构建出符合业务需求的实时数仓,并实时响应各种复杂的分析需求。
最后,希望读者能够结合本教程的示例代码和自身业务特点,动手搭建一个轻量级高性能的实时数据仓库。在实际应用中,不断挖掘 DolphinDB 的潜力,无论是能源电力、石油化工、智能制造、航空航天还是车联网、金融等行业,DolphinDB 均可为实时数仓的广泛应用提供有力支持。
5. 附件
测试结果可通过以下脚本,在 DolphinDB 服务器上进行复现:
def clearEnv(){//取消订阅unsubscribeTable(tableName=`inputStream, actionName="dispatch1")unsubscribeTable(tableName=`inputStream, actionName="dispatch2")unsubscribeTable(tableName=`oneMinuteResult, actionName="calcHalfHour")unsubscribeTable(tableName=`oneMinuteResult, actionName="calcOneHour")unsubscribeTable(tableName=`fiveMinuteResult, actionName="calcOneDay")unsubscribeTable(tableName = `oneDayResultSimulate,actionName=`calcOneYear)unsubscribeTable(tableName = `oneMinuteResult,actionName=`appendInToDFS)unsubscribeTable(tableName = `fiveMinuteResult,actionName=`appendInToDFS)unsubscribeTable(tableName = `halfHourResult,actionName=`appendInToDFS)unsubscribeTable(tableName = `oneHourResult,actionName=`appendInToDFS)unsubscribeTable(tableName = `oneDayResult,actionName=`appendInToDFS)unsubscribeTable(tableName = `oneYearResult,actionName=`appendInToDFS)//删除流计算引擎for(i in 1..2){try{dropStreamEngine(`dispatchDemo+string(i))}catch(ex){print(ex)}}for(i in 1..5){try{dropStreamEngine(`oneMinuteCalc+string(i))}catch(ex){print(ex)}try{dropStreamEngine(`fiveMinuteCalc+string(i))}catch(ex){print(ex)}}try{dropStreamEngine(`halfHourCalc)}catch(ex){print(ex)}try{dropStreamEngine(`oneHourCalc)}catch(ex){print(ex)}try{dropStreamEngine(`oneDayCalc)}catch(ex){print(ex)}try{dropStreamEngine(`oneYearCalc)}catch(ex){print(ex)}//删除流数据表try{dropStreamTable(`inputStream)}catch(ex){print(ex)}try{dropStreamTable(`oneMinuteResult)}catch(ex){print(ex)}try{dropStreamTable(`fiveMinuteResult)}catch(ex){print(ex)}try{dropStreamTable(`halfHourResult)}catch(ex){print(ex)}try{dropStreamTable(`oneHourResult)}catch(ex){print(ex)}try{dropStreamTable(`oneDayResult)}catch(ex){print(ex)}try{dropStreamTable(`oneDayResultSimulate)}catch(ex){print(ex)}try{dropStreamTable(`oneYearResult)}catch(ex){print(ex)}}def createStreamTable(){//定义输入流表enableTableShareAndPersistence(table = streamTable(1000:0,`Time`deviceId`value,`TIMESTAMP`SYMBOL`DOUBLE),tableName = `inputStream,cacheSize = 1000000,precache=1000000)colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTimecolType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP//定义1分钟窗口计算结果流表 enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),tableName = `oneMinuteResult,cacheSize = 1000000,precache=1000000)//定义5分钟窗口计算结果流表 enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),tableName = `fiveMinuteResult,cacheSize = 1000000,precache=1000000)//定义30分钟窗口计算结果流表 enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),tableName = `halfHourResult,cacheSize = 1000000,precache=1000000)//定义1小时窗口计算结果流表 enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),tableName = `oneHourResult,cacheSize = 1000000,precache=1000000)//定义24小时窗口计算结果流表 enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),tableName = `oneDayResult,cacheSize = 1000000,precache=1000000)//定义模拟24小时窗口计算结果流表colName = `TIME`deviceId`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`lastcolType = `DATE`SYMBOL join take(`DOUBLE,10) enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),tableName = `oneDayResultSimulate,cacheSize = 1000000,precache=1000000)//定义1年窗口计算结果流表colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTimecolType = `DATE`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),tableName = `oneYearResult,cacheSize = 1000000,precache=1000000)
}def createDFS(){//创建存储计算1分钟窗口计算结果表if(existsDatabase("dfs://oneMinuteCalc")){dropDatabase("dfs://oneMinuteCalc")}db1 = database(, VALUE,2023.01.01..2023.01.03)db2 = database(, HASH,[SYMBOL,20])db = database(directory="dfs://oneMinuteCalc", partitionType=COMPO, partitionScheme=[db1,db2],engine="TSDB")colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTimecolType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMPt = table(1:0,colName,colType)pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time","deviceId"],sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})//创建存储计算5分钟窗口计算结果表 if(existsDatabase("dfs://fiveMinuteCalc")){dropDatabase("dfs://fiveMinuteCalc")}db = database(directory="dfs://fiveMinuteCalc", partitionType=VALUE,partitionScheme=2023.01.01..2023.01.03,engine="TSDB")t = table(1:0,colName,colType)pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],sortColumns =["deviceId","Time"],compressMethods={Time:"delta"},sortKeyMappingFunction=[hashBucket{,100}]) //创建存储计算30分钟窗口计算结果表if(existsDatabase("dfs://halfHourCalc")){dropDatabase("dfs://halfHourCalc")}db = database(directory="dfs://halfHourCalc", partitionType=VALUE, partitionScheme=2023.01.01..2023.01.03,engine="TSDB")t = table(1:0,colName,colType)pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],sortColumns =["deviceId","Time"],compressMethods={Time:"delta"}) //创建存储计算1小时窗口计算结果表if(existsDatabase("dfs://oneHourCalc")){dropDatabase("dfs://oneHourCalc")}db = database(directory="dfs://oneHourCalc", partitionType=VALUE,partitionScheme=2023.01.01..2023.01.03,engine="TSDB")t = table(1:0,colName,colType)pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})//创建存储计算24小时窗口计算结果表if(existsDatabase("dfs://oneDayCalc")){dropDatabase("dfs://oneDayCalc")}db = database(directory="dfs://oneDayCalc", partitionType=VALUE, partitionScheme=2023.01.01..2023.01.03,engine="TSDB")t = table(1:0,colName,colType)pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})//创建存储计算1年窗口计算结果表if(existsDatabase("dfs://oneYearCalc")){dropDatabase("dfs://oneYearCalc")}db = database(directory="dfs://oneYearCalc", partitionType=VALUE, partitionScheme=2023.01.01..2023.01.03,engine="TSDB")t = table(1:0,colName,colType)pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
}//1分钟窗口计算过滤函数
def filter1(msg){t = select *,now(true) as filterTime from msg getStreamEngine(`dispatchDemo1).append!(t)
}//5分钟窗口计算过滤函数
def filter2(msg){t = select *,now(true) as filterTime from msg getStreamEngine(`dispatchDemo2).append!(t)
}//30分钟窗口计算过滤函数
def filter3(msg){t = select *,now(true) as filterTime2 from msg getStreamEngine(`halfHourCalc).append!(t)
}//1小时窗口计算
def filter4(msg){t = select *,now(true) as filterTime2 from msg getStreamEngine(`oneHourCalc).append!(t)
}//24小时窗口计算
def filter5(msg){t = select *,now(true) as filterTime2 from msg getStreamEngine(`oneDayCalc).append!(t)
}clearEnv();
createStreamTable();
createDFS();schemas1 = table(1:0,`Time`deviceId`value`filterTime,`TIMESTAMP`SYMBOL`DOUBLE`NANOTIMESTAMP)
metrics1 = <[first(filterTime),max(value),min(value),mean(value),med(value),percentile(value,95),percentile(value,5),last(value)-first(value),(last(value)-first(value))/first(value),first(value),last(value),now(true)]>
//创建1分钟窗口聚合计算引擎
for(i in 1..5){engine1 = createTimeSeriesEngine(name="oneMinuteCalc"+string(i), windowSize=60000, step=60000,metrics=metrics1 , dummyTable=schemas1 , outputTable=objByName(`oneMinuteResult),timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
}//创建5分钟窗口聚合计算引擎
for(i in 1..5){engine2 = createTimeSeriesEngine(name="fiveMinuteCalc"+string(i), windowSize=300000, step=300000, metrics=metrics1 , dummyTable=schemas1 , outputTable=objByName(`fiveMinuteResult),timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
}//1分钟、5分钟窗口聚合计算分发引擎
dispatchEngine1=createStreamDispatchEngine(name="dispatchDemo1", dummyTable=schemas1, keyColumn=`deviceId, outputTable=[getStreamEngine("oneMinuteCalc1"),getStreamEngine("oneMinuteCalc2"),getStreamEngine("oneMinuteCalc3"),getStreamEngine("oneMinuteCalc4"),getStreamEngine("oneMinuteCalc5")])
dispatchEngine2=createStreamDispatchEngine(name="dispatchDemo2", dummyTable=schemas1, keyColumn=`deviceId, outputTable=[getStreamEngine("fiveMinuteCalc1"),getStreamEngine("fiveMinuteCalc2"),getStreamEngine("fiveMinuteCalc3"),getStreamEngine("fiveMinuteCalc4"),getStreamEngine("fiveMinuteCalc5")])colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime`filterTime2
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP`NANOTIMESTAMP
schemas2 = table(1:0,colName,colType)
metrics2 = <[first(filterTime2),max(MAX),min(MIN),mean(MEAN),med(MED),avg(P95),avg(P5),last(last)-first(first),(last(last)-first(first))/first(first),first(first),last(last),now(true)]>
//创建30分钟窗口聚合计算引擎
engine3 = createTimeSeriesEngine(name="halfHourCalc", windowSize=1800000, step=1800000, metrics=metrics2 , dummyTable=schemas2 , outputTable=objByName(`halfHourResult),timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)//创建1小时窗口聚合计算引擎
engine4 = createTimeSeriesEngine(name="oneHourCalc", windowSize=3600000, step=3600000, metrics=metrics2 , dummyTable=schemas2 , outputTable=objByName(`oneHourResult),timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)//创建24小时窗口聚合计算引擎
engine5 = createTimeSeriesEngine(name="oneDayCalc", windowSize=86400000, step=86400000, metrics=metrics2 , dummyTable=schemas2 , outputTable=objByName(`oneDayResult),timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)//订阅
subscribeTable(tableName=`inputStream, actionName="dispatch1", handler=filter1, msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`inputStream, actionName="dispatch2", handler=filter2, msgAsTable = true,batchSize = 10240)subscribeTable(tableName=`oneMinuteResult, actionName="calcHalfHour", handler=filter3,msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`oneMinuteResult, actionName="calcOneHour", handler=filter4, msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`fiveMinuteResult, actionName="calcOneDay", handler=filter5, msgAsTable = true,batchSize = 10240)subscribeTable(tableName = `oneMinuteResult,actionName=`appendInToDFS,offset=0,handler=loadTable("dfs://oneMinuteCalc","test"),msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `fiveMinuteResult,actionName=`appendInToDFS,offset=0,handler=loadTable("dfs://fiveMinuteCalc","test"),msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `halfHourResult,actionName=`appendInToDFS,offset=0,handler=loadTable("dfs://halfHourCalc","test"),msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `oneHourResult,actionName=`appendInToDFS,offset=0,handler=loadTable("dfs://oneHourCalc","test"),msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `oneDayResult,actionName=`appendInToDFS,offset=0,handler=loadTable("dfs://oneDayCalc","test"),msgAsTable=true,batchSize=10240)def filter6(msg){tmp = select * ,now(true) as filterTime from msg getStreamEngine(`oneYearCalc).append!(tmp)
} colName = `Time`deviceId`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`filterTime
colType = `DATE`SYMBOL join take(`DOUBLE,10) join `NANOTIMESTAMP
schemas3 = table(1:0,colName,colType)
metrics3 = <[last(filterTime),max(MAX),min(MIN),mean(MEAN),med(MED),avg(P95),avg(P5),last(last)-first(first),(last(last)-first(first))/first(first),first(first),last(last),now(true)]>
engine6 = createTimeSeriesEngine(name="oneYearCalc", windowSize=365, step=1, metrics=metrics3 , dummyTable=schemas3 , outputTable=objByName(`oneYearResult),timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)subscribeTable(tableName = `oneDayResultSimulate,actionName=`calcOneYear, handler=filter6, msgAsTable = true,batchSize = 10240)
subscribeTable(tableName = `oneYearResult,actionName=`appendInToDFS,offset=0,handler=loadTable("dfs://oneYearCalc","test"),msgAsTable=true)deviceIdList = lapd(string(rand(10000,700)),6,"0") //测点id//模拟数据的函数,一共模拟1小时的数据
def simulateData(deviceIdList){num = deviceIdList.size()startTime = timestamp(2023.01.01)do{Time = take(startTime,num)deviceId = deviceIdListvalue = rand(100.0,num)objByName(`inputStream).append!(table(Time,deviceId,value))startTime = startTime+1000sleep(100)}while(startTime<=2023.01.02T00:00:10.000)
}def simulateOneDay(deviceIdList){num = deviceIdList.size()startTime =2022.01.01do{Time = take(startTime,num)deviceId = deviceIdListMAX = rand(100.0,num)MIN = rand(100.0,num)MEAN = rand(100.0,num)MED = rand(100.0,num)P95 = rand(100.0,num)P5 = rand(100.0,num)CHANGE = rand(100.0,num)CHANGE_RATE = rand(100.0,num)first = rand(100.0,num)last = rand(100.0,num)tmp = table(Time,deviceId,MAX,MIN,MEAN,MED,P95,P5,CHANGE,CHANGE_RATE,first,last)objByName(`oneDayResultSimulate).append!(tmp)startTime = startTime+1sleep(500)}while(startTime<=2023.12.31)
}submitJob("simulateData","write",simulateData,deviceIdList)
submitJob("simulateOneDay","write",simulateOneDay,deviceIdList)//耗时统计
tmp1 = select Time,deviceId,filterTime,endTime from loadTable("dfs://oneYearCalc","test") order by Time,deviceId
tmp2 = select Time,deviceId,next(filterTime) as startTime,endTime from tmp1 context by deviceId
select avg(endTime-startTime)\1000\1000 as timeUsed from tmp2 group by deviceId //统计单个测点的计算耗时
tmp3 = select min(startTime) as st,max(endTime) as dt from tmp2 group by Time
select (dt-st)\1000\1000 as used from tmp3 //统计整个时间窗口的计算耗时