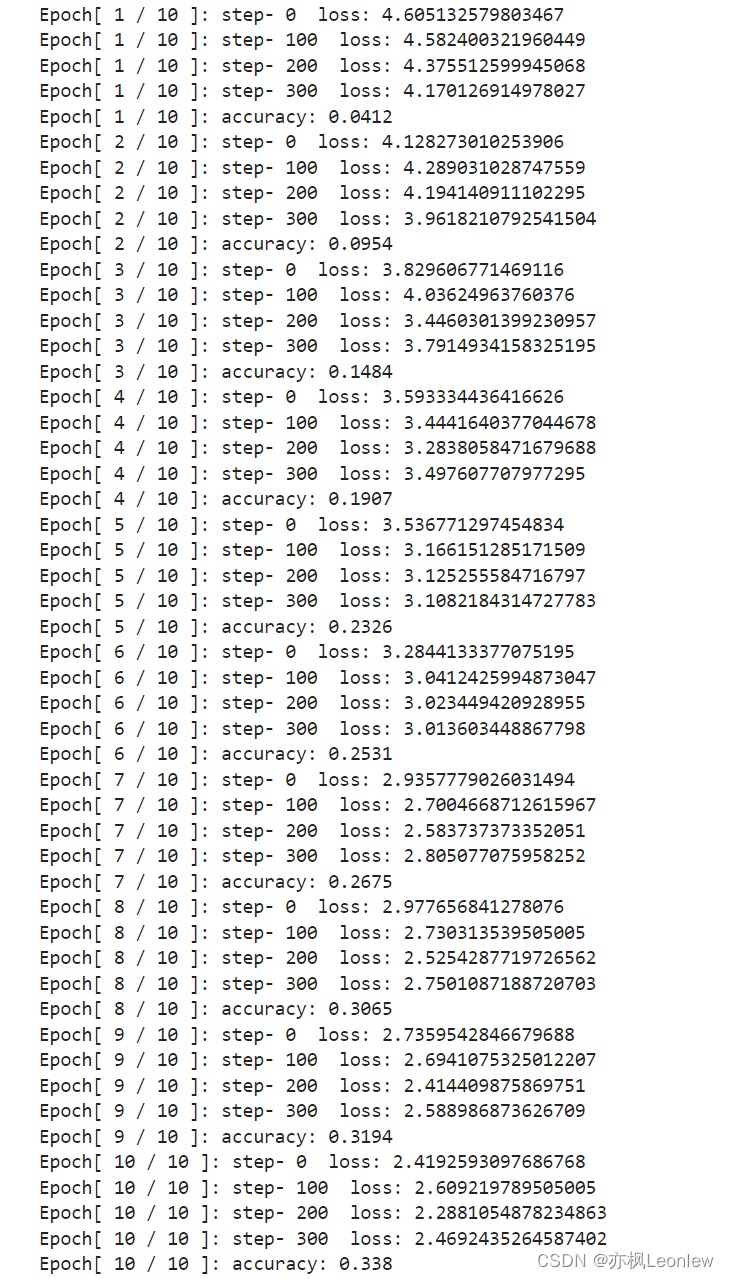
本笔记记录CNN做CIFAR100数据集的训练相关内容,代码中使用了类似VGG13的网络结构,做了两个Sequetial(CNN和全连接层),没有用Flatten层而是用reshape操作做CNN和全连接层的中转操作。由于网络层次较深,参数量相比之前的网络多了不少,因此只做了10次epoch(RTX4090),没有继续跑了,最终准确率大概在33.8%左右。
import os
import time
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics, Inputos.environ['TF_CPP_MIN_LOG_LEVEL']='2'
#tf.random.set_seed(12345)
tf.__version__#如果下载很慢,可以使用迅雷下载到本地,迅雷的链接也可以直接用官网URL:
# https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
#下载好后,将cifar-100.python.tar.gz放到 .keras\datasets 目录下(我的环境是C:\Users\Administrator\.keras\datasets)
# 参考:https://blog.csdn.net/zy_like_study/article/details/104219259
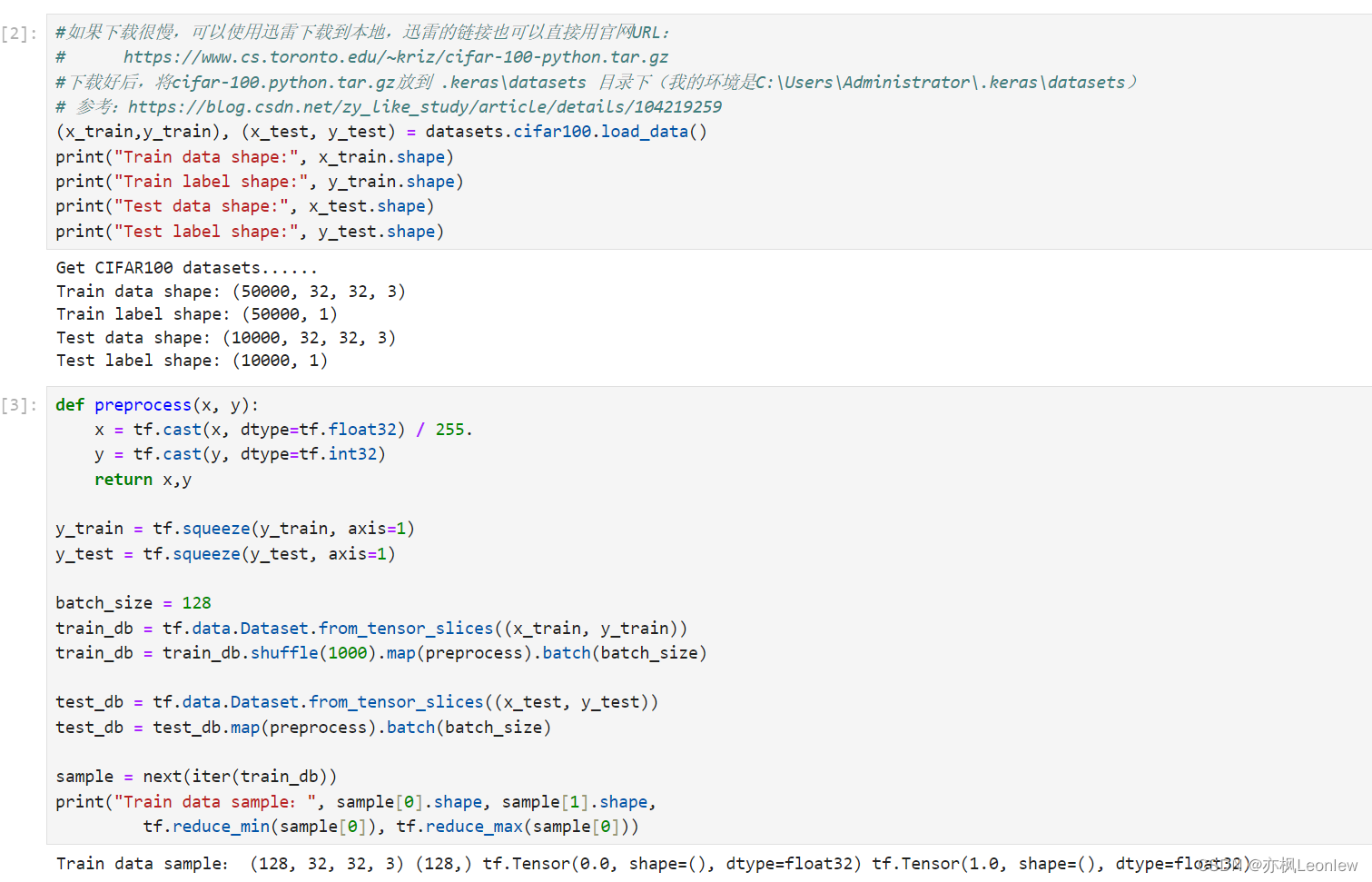
(x_train,y_train), (x_test, y_test) = datasets.cifar100.load_data()
print("Train data shape:", x_train.shape)
print("Train label shape:", y_train.shape)
print("Test data shape:", x_test.shape)
print("Test label shape:", y_test.shape)def preprocess(x, y):x = tf.cast(x, dtype=tf.float32) / 255.y = tf.cast(y, dtype=tf.int32)return x,yy_train = tf.squeeze(y_train, axis=1)
y_test = tf.squeeze(y_test, axis=1)batch_size = 128
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_db = train_db.shuffle(1000).map(preprocess).batch(batch_size)test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocess).batch(batch_size)sample = next(iter(train_db))
print("Train data sample:", sample[0].shape, sample[1].shape, tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))#创建CNN网络,总共4个unit,每个unit主要是两个卷积层和Max Pooling池化层
cnn_layers = [#unit 1layers.Conv2D(64, kernel_size=[3,3], padding='same', activation='relu'),layers.Conv2D(64, kernel_size=[3,3], padding='same', activation='relu'),#layers.MaxPool2D(pool_size=[2,2], strides=2, padding='same'),layers.MaxPool2D(pool_size=[2,2], strides=2),#unit 2layers.Conv2D(128, kernel_size=[3,3], padding='same', activation='relu'),layers.Conv2D(128, kernel_size=[3,3], padding='same', activation='relu'),#layers.MaxPool2D(pool_size=[2,2], strides=2, padding='same'),layers.MaxPool2D(pool_size=[2,2], strides=2),#unit 3layers.Conv2D(256, kernel_size=[3,3], padding='same', activation='relu'),layers.Conv2D(256, kernel_size=[3,3], padding='same', activation='relu'),#layers.MaxPool2D(pool_size=[2,2], strides=2, padding='same'),layers.MaxPool2D(pool_size=[2,2], strides=2),#unit 4layers.Conv2D(512, kernel_size=[3,3], padding='same', activation='relu'),layers.Conv2D(512, kernel_size=[3,3], padding='same', activation='relu'),#layers.MaxPool2D(pool_size=[2,2], strides=2, padding='same'),layers.MaxPool2D(pool_size=[2,2], strides=2),#unit 5layers.Conv2D(512, kernel_size=[3,3], padding='same', activation='relu'),layers.Conv2D(512, kernel_size=[3,3], padding='same', activation='relu'),#layers.MaxPool2D(pool_size=[2,2], strides=2, padding='same'),layers.MaxPool2D(pool_size=[2,2], strides=2),
]def main():#[b, 32, 32, 3] => [b, 1, 1, 512]cnn_net = Sequential(cnn_layers)cnn_net.build(input_shape=[None, 32, 32, 3])#测试一下卷积层的输出#x = tf.random.normal([4, 32, 32, 3])#out = cnn_net(x)#print(out.shape)#创建全连接层, 输出为100分类fc_net = Sequential([layers.Dense(256, activation='relu'),layers.Dense(128, activation='relu'),layers.Dense(100, activation=None),])fc_net.build(input_shape=[None, 512])#设置优化器optimizer = optimizers.Adam(learning_rate=1e-4)#记录cnn层和全连接层所有可训练参数, 实现的效果类似list拼接,比如# [1, 2] + [3, 4] => [1, 2, 3, 4]variables = cnn_net.trainable_variables + fc_net.trainable_variables#进行训练num_epoches = 10for epoch in range(num_epoches):for step, (x,y) in enumerate(train_db):with tf.GradientTape() as tape:#[b, 32, 32, 3] => [b, 1, 1, 512]out = cnn_net(x)#flatten打平 => [b, 512]out = tf.reshape(out, [-1, 512])#使用全连接层做100分类logits输出#[b, 512] => [b, 100]logits = fc_net(out)#标签做one_hot encodingy_onehot = tf.one_hot(y, depth=100)#计算损失loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)loss = tf.reduce_mean(loss)#计算梯度grads = tape.gradient(loss, variables)#更新参数optimizer.apply_gradients(zip(grads, variables))if (step % 100 == 0):print("Epoch[", epoch + 1, "/", num_epoches, "]: step-", step, " loss:", float(loss))#进行验证total_samples = 0total_correct = 0for x,y in test_db:out = cnn_net(x)out = tf.reshape(out, [-1, 512])logits = fc_net(out)prob = tf.nn.softmax(logits, axis=1)pred = tf.argmax(prob, axis=1)pred = tf.cast(pred, dtype=tf.int32)correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)correct = tf.reduce_sum(correct)total_samples += x.shape[0]total_correct += int(correct)#统计准确率acc = total_correct / total_samplesprint("Epoch[", epoch + 1, "/", num_epoches, "]: accuracy:", acc)
if __name__ == '__main__':main()运行结果: