提示:DDU,供自己复习使用。欢迎大家前来讨论~
第七章 回溯算法part03
开始补一下
一、题目
题目一: 39. 组合总和
39. 组合总和
解题思路:
本题是可以重复被选取,不会出现0,然后看到下面提示:1 <= candidates[i] <= 200,我就放心了。
直接的想法就是两层for循环,依次输出两个元素。
本题搜索的过程抽象成树形结构如下:
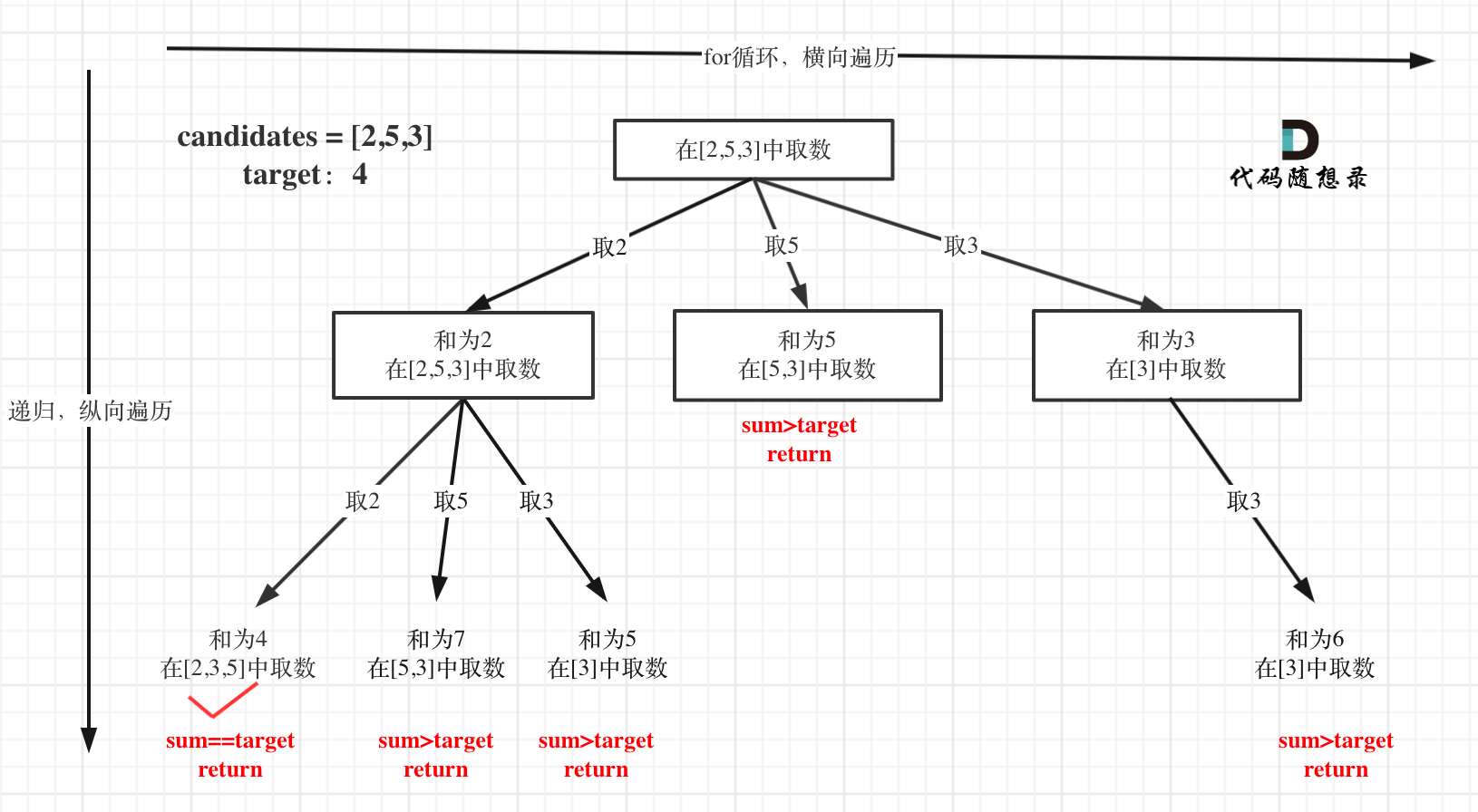
注意图中叶子节点的返回条件,因为本题没有组合数量要求,仅仅是总和的限制,所以递归没有层数的限制,只要选取的元素总和超过target,就返回!
回溯三部曲
排列和组合是不一样的。
本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?
如果是一个集合来求组合的话,就需要startIndex,例如77.组合,216.组合总和III 。
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:17.电话号码的字母组合
- 递归函数参数
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& candidates, int target, int sum, int startIndex)
- 递归终止条件
在如下树形结构中:
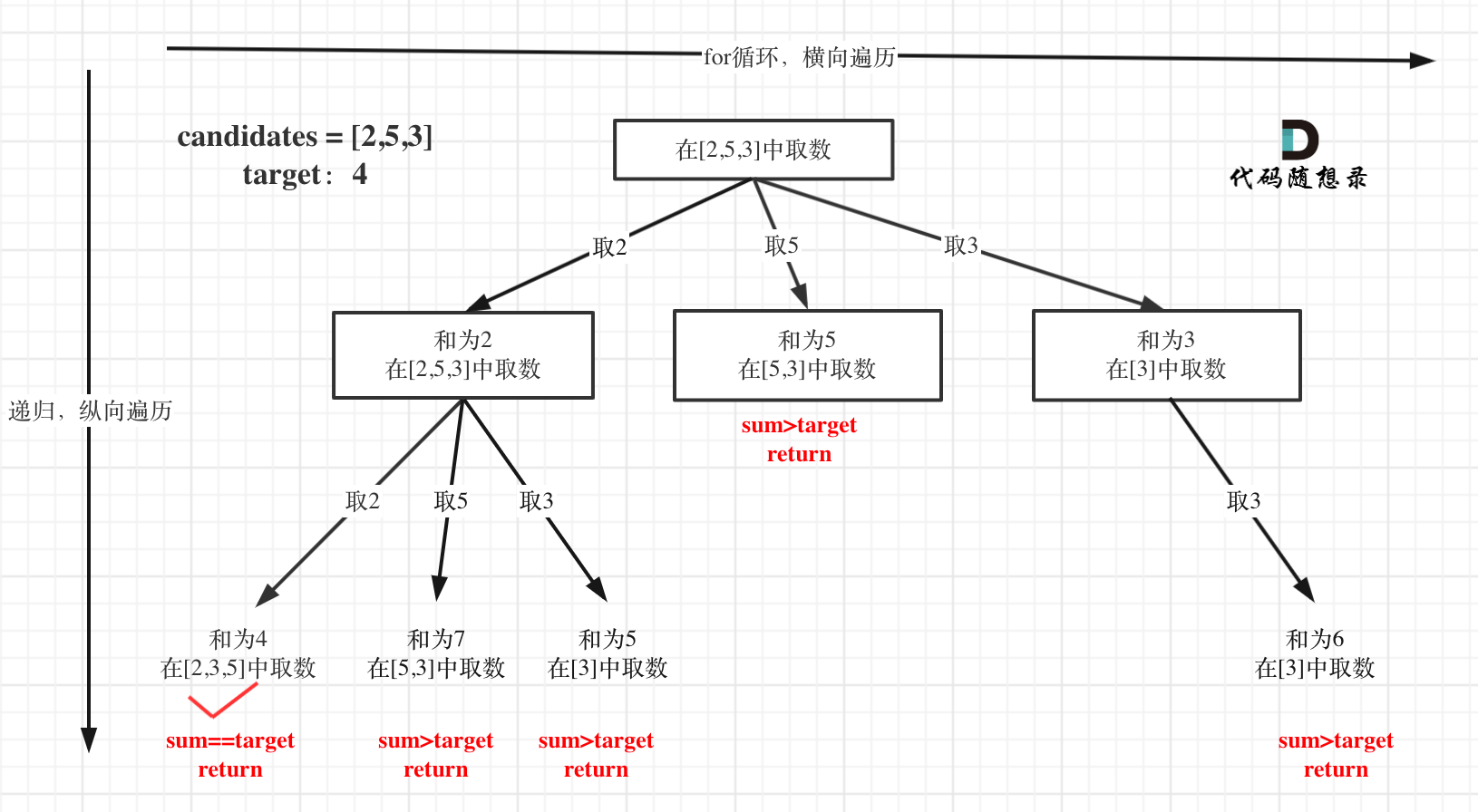
从叶子节点可以清晰看到,终止只有两种情况,sum大于target和sum等于target。
if (sum > target) {return;
}
if (sum == target) {result.push_back(path);return;
}
- 单层搜索的逻辑
单层for循环依然是从startIndex开始,搜索candidates集合。
for (int i = startIndex; i < candidates.size(); i++) {sum += candidates[i];path.push_back(candidates[i]);backtracking(candidates, target, sum, i); // 关键点:不用i+1了,表示可以重复读取当前的数sum -= candidates[i]; // 回溯path.pop_back(); // 回溯
}
完整代码:
// 版本一
class Solution {
private:vector<vector<int>> result;vector<int> path;void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {if (sum > target) {return;}if (sum == target) {result.push_back(path);return;}for (int i = startIndex; i < candidates.size(); i++) {sum += candidates[i];path.push_back(candidates[i]);backtracking(candidates, target, sum, i); // 不用i+1了,表示可以重复读取当前的数sum -= candidates[i];path.pop_back();}}
public:vector<vector<int>> combinationSum(vector<int>& candidates, int target) {result.clear();path.clear();backtracking(candidates, target, 0, 0);return result;}
};
剪枝优化
对总集合排序之后,如果下一层的sum(就是本层的 sum + candidates[i])已经大于target,就可以结束本轮for循环的遍历。
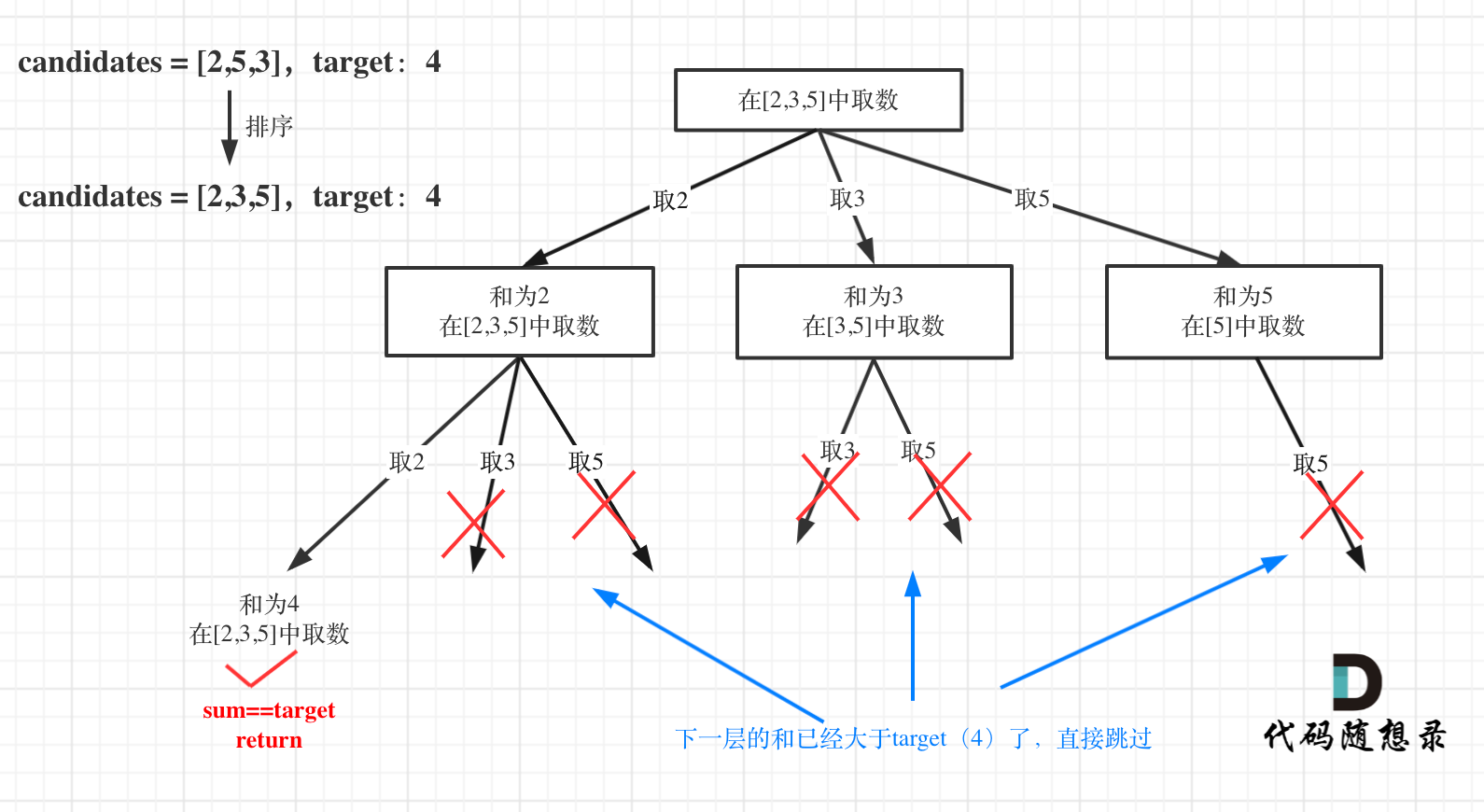
for循环剪枝代码如下:
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
整体代码如下:(注意注释的部分)
class Solution {
private:vector<vector<int>> result;vector<int> path;void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {if (sum == target) {result.push_back(path);return;}// 如果 sum + candidates[i] > target 就终止遍历for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {sum += candidates[i];path.push_back(candidates[i]);backtracking(candidates, target, sum, i);sum -= candidates[i];path.pop_back();}}
public:vector<vector<int>> combinationSum(vector<int>& candidates, int target) {result.clear();path.clear();sort(candidates.begin(), candidates.end()); // 需要排序backtracking(candidates, target, 0, 0);return result;}
};
- 时间复杂度: O(n * 2^n),注意这只是复杂度的上界,因为剪枝的存在,真实的时间复杂度远小于此
- 空间复杂度: O(target)
小结:
- 组合没有数量要求
- 元素可以无限重复取
在求和问题中,排序之后加剪枝是常见的套路!
题目二:40.组合总和Ⅱ
40. 组合总和 II
解题思路:
所以我们要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。
强调一下,树层去重的话,需要对数组排序!
下面有used数组的使用:
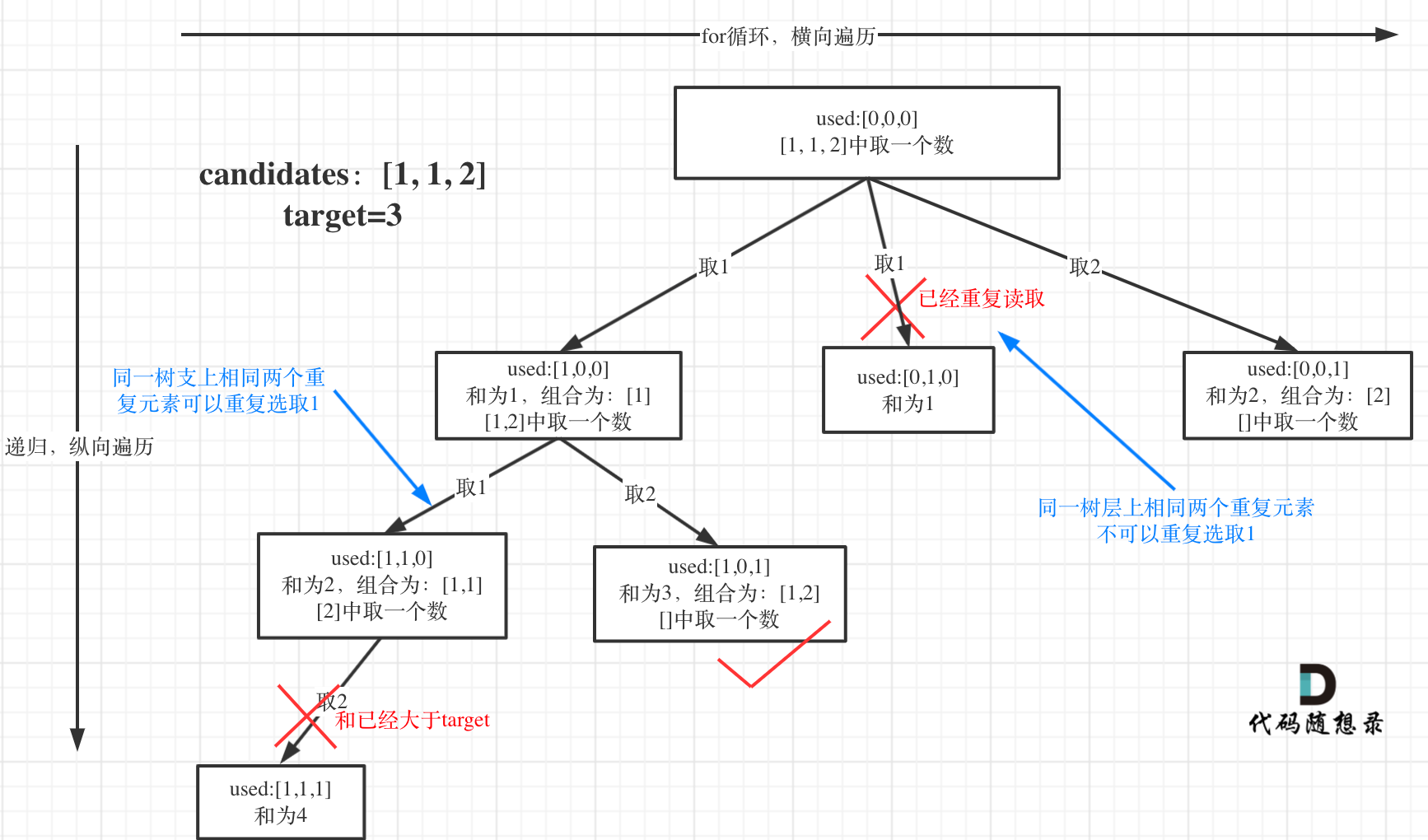
回溯三部曲
- 确定递归函数参数
依然需要一维数组path来存放符合条件的结果,二维数组result来存放结果集。
此题还需要加一个bool型数组used,用来记录同一树枝上的元素是否使用过。这个集合去重的重任就是used来完成的。
vector<vector<int>> result; // 存放组合集合
vector<int> path; // 符合条件的组合
void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {
- 确定终止条件
if (sum > target) { // 这个条件其实可以省略return;
}
if (sum == target) {result.push_back(path);return;
}
- 单层搜索过程
如果candidates[i] == candidates[i - 1] 并且 used[i - 1] == false,就说明:前一个树枝,使用了candidates[i - 1],也就是说同一树层使用过candidates[i - 1]。
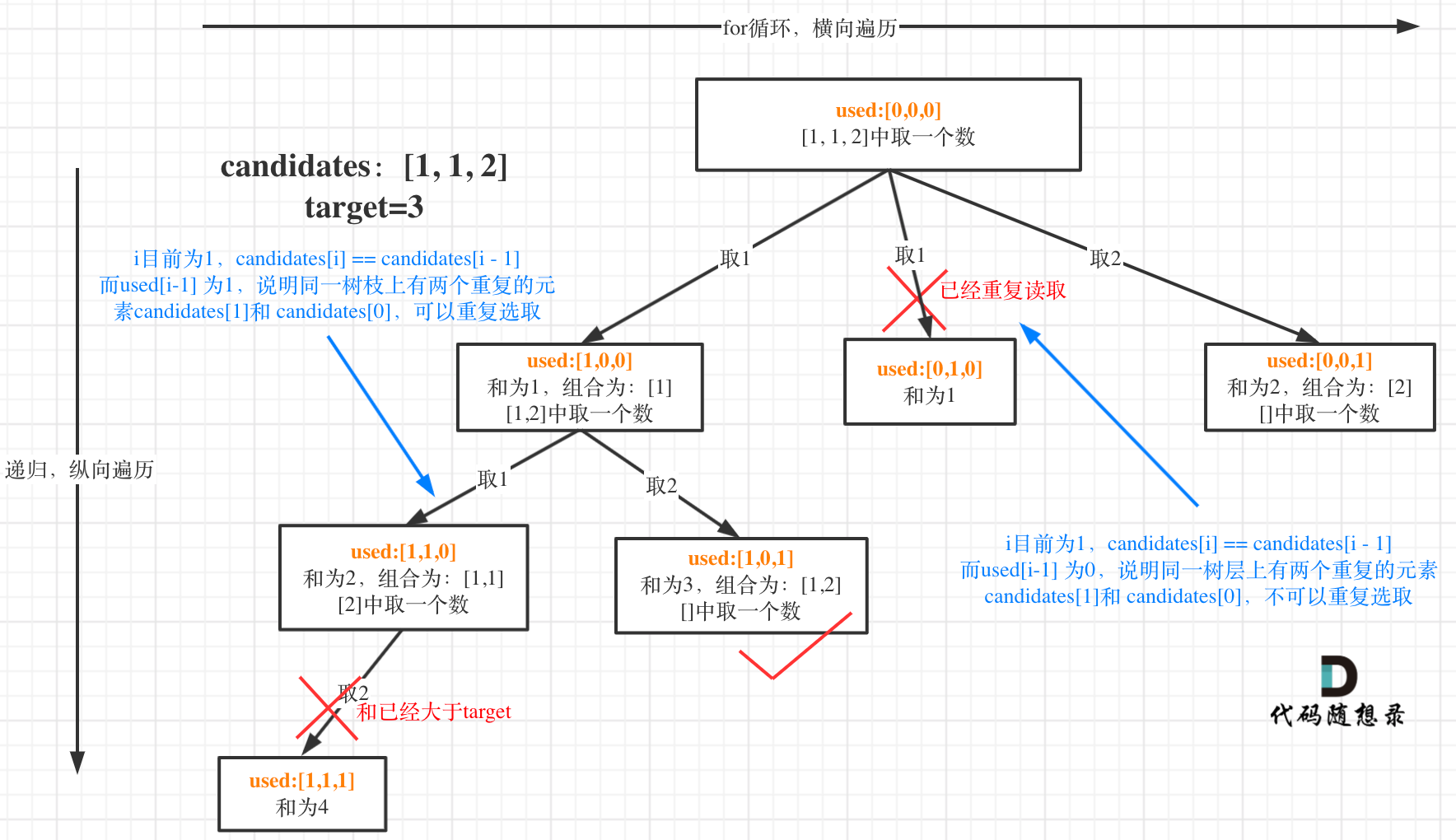
在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
- used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
- used[i - 1] == false,说明同一树层candidates[i - 1]使用过
为什么 used[i - 1] == false 就是同一树层呢,因为同一树层,used[i - 1] == false 才能表示,当前取的 candidates[i] 是从 candidates[i - 1] 回溯而来的。
而 used[i - 1] == true,说明是进入下一层递归,去下一个数,所以是树枝上,如图所示:
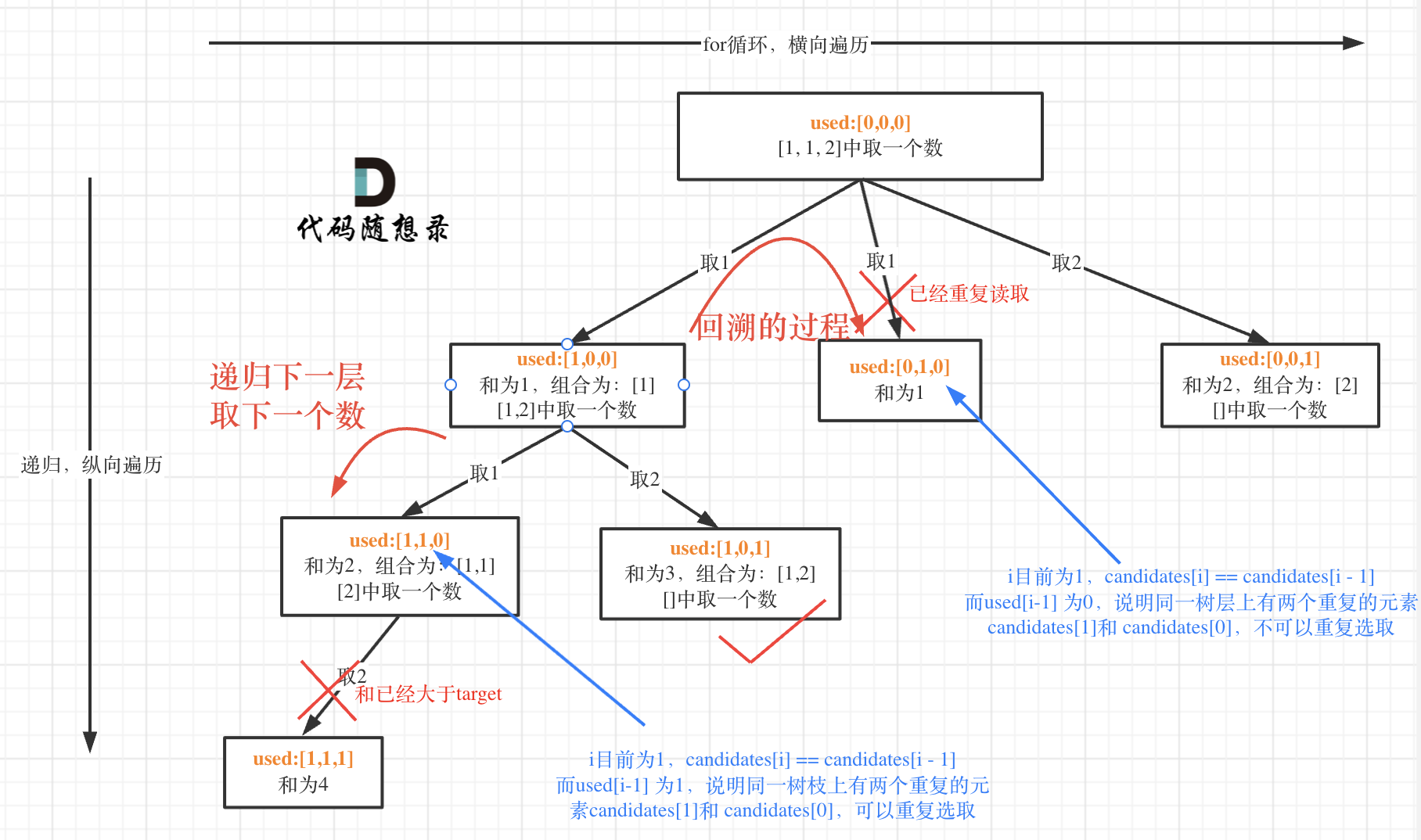
注意sum + candidates[i] <= target为剪枝操作
回溯三部曲分析完了,整体C++代码如下:
class Solution {
private:vector<vector<int>> result;vector<int> path;void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {if (sum == target) {result.push_back(path);return;}for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过// used[i - 1] == false,说明同一树层candidates[i - 1]使用过// 要对同一树层使用过的元素进行跳过if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {continue;}sum += candidates[i];path.push_back(candidates[i]);used[i] = true;backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次used[i] = false;sum -= candidates[i];path.pop_back();}}public:vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {vector<bool> used(candidates.size(), false);path.clear();result.clear();// 首先把给candidates排序,让其相同的元素都挨在一起。sort(candidates.begin(), candidates.end());backtracking(candidates, target, 0, 0, used);return result;}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
小结:
去重逻辑很关键,涉及到回溯。
题目三: 131.分割回文串
131. 分割回文串
解题思路
本题这涉及到两个关键问题:
- 切割问题,有不同的切割方式
- 判断回文
例如对于字符串abcdef:
- 组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个…。
- 切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段…。
所以切割问题,也可以抽象为一棵树形结构,如图:
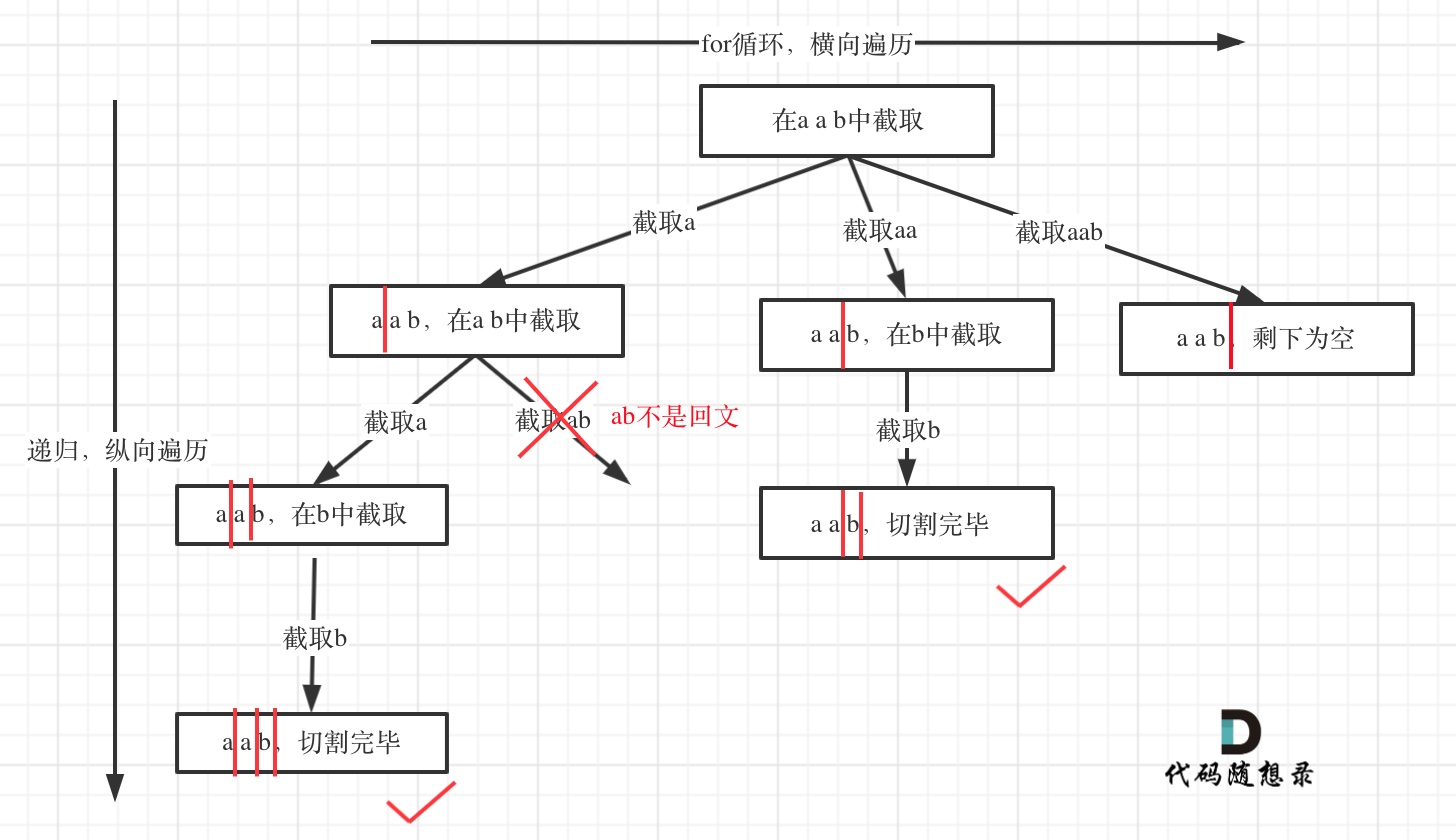
递归用来纵向遍历,for循环用来横向遍历,切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。
回溯三部曲
- 确定回溯函数参数
本题递归函数参数还需要startIndex,因为切割过的地方,不能重复切割,和组合问题也是保持一致的。
vector<vector<string>> result;
vector<string> path; // 放已经回文的子串
void backtracking (const string& s, int startIndex) {
- 确定终止条件
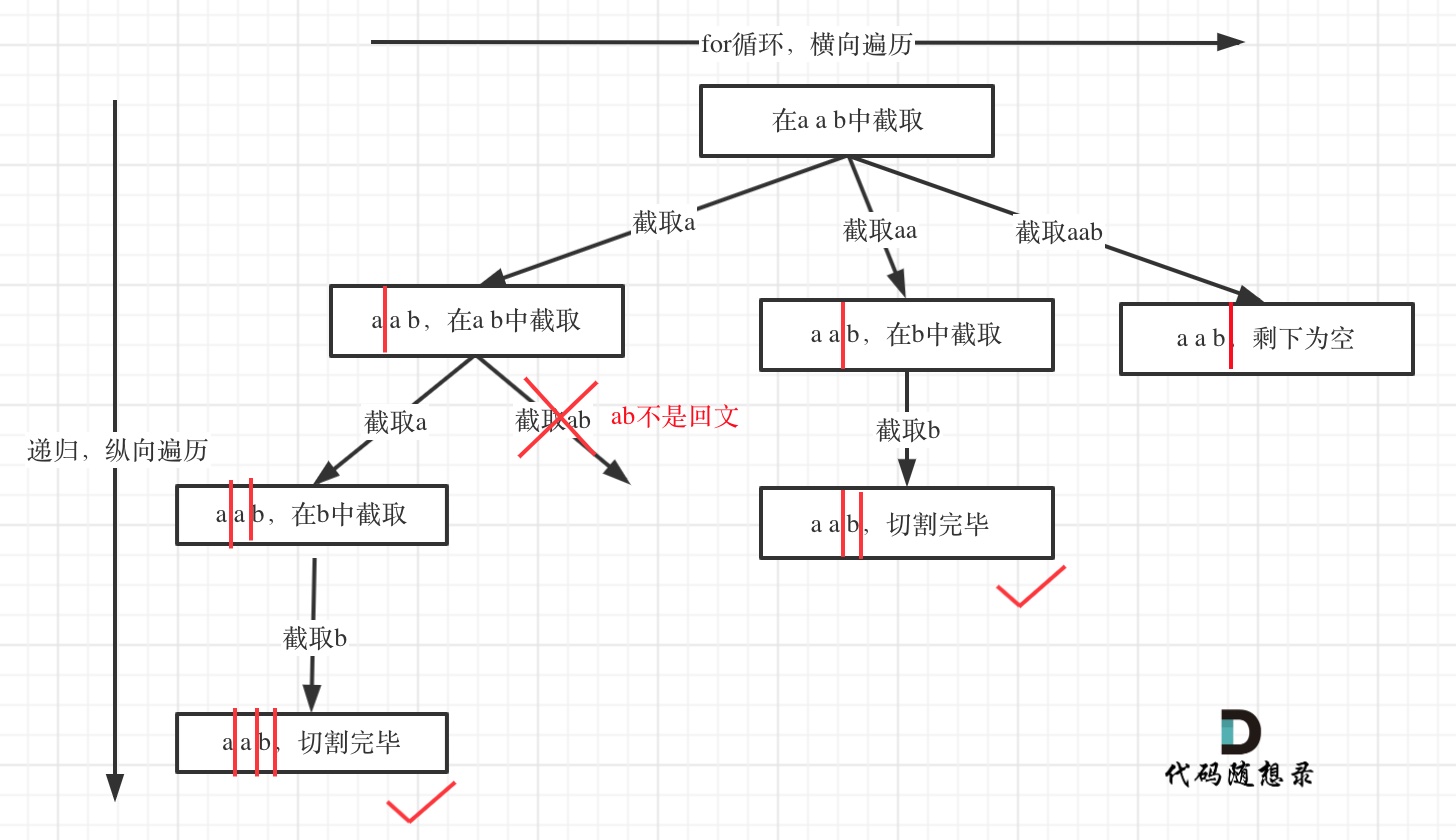
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本层递归的终止条件。
那么在代码里什么是切割线呢?
在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是==切割线==。
void backtracking (const string& s, int startIndex) {// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了if (startIndex >= s.size()) {result.push_back(path);return;}
}
- 确定单层遍历逻辑
来看看在递归循环中如何截取子串呢?
[startIndex, i] 就是要截取的子串。
首先判断这个子串是不是回文,如果是回文,就加入在vector<string> path中,path用来记录切割过的回文子串。
for (int i = startIndex; i < s.size(); i++) {if (isPalindrome(s, startIndex, i)) { // 是回文子串// 获取[startIndex,i]在s中的子串string str = s.substr(startIndex, i - startIndex + 1);path.push_back(str);} else { // 如果不是则直接跳过continue;}backtracking(s, i + 1); // 寻找i+1为起始位置的子串path.pop_back(); // 回溯过程,弹出本次已经添加的子串
}
注意切割过的位置,不能重复切割,所以,backtracking(s, i + 1); 传入下一层的起始位置为i + 1。
判断回文子串
可以使用==双指针法==,一个指针从前向后,一个指针从后向前,如果前后指针所指向的元素是相等的,就是回文字符串了。
bool isPalindrome(const string& s, int start, int end) {for (int i = start, j = end; i < j; i++, j--) {if (s[i] != s[j]) {return false;}}return true;}
回溯算法模板:
void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}
}
完整C++代码:
class Solution {
private:vector<vector<string>> result;vector<string> path; // 放已经回文的子串void backtracking (const string& s, int startIndex) {// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了if (startIndex >= s.size()) {result.push_back(path);return;}for (int i = startIndex; i < s.size(); i++) {if (isPalindrome(s, startIndex, i)) { // 是回文子串// 获取[startIndex,i]在s中的子串string str = s.substr(startIndex, i - startIndex + 1);path.push_back(str);} else { // 不是回文,跳过continue;}backtracking(s, i + 1); // 寻找i+1为起始位置的子串path.pop_back(); // 回溯过程,弹出本次已经添加的子串}}bool isPalindrome(const string& s, int start, int end) {for (int i = start, j = end; i < j; i++, j--) {if (s[i] != s[j]) {return false;}}return true;}
public:vector<vector<string>> partition(string s) {result.clear();path.clear();backtracking(s, 0);return result;}
};
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n^2)
优化
- 动态规划:动态规划是一种解决子问题重叠问题的有效方法。在判断回文子串的问题中,可以预先计算出一个字符串的所有子串是否为回文,并存储这些结果。这样,在后续的判断中,可以直接查询这些预先计算的结果,而不需要重新计算。
- 动态规划的具体实现:可以创建一个二维布尔数组
dp[i][j],其中i和j分别表示子串的起始和终止索引。如果s[i] == s[j]并且dp[i + 1][j - 1]为真(即s[i + 1]到s[j - 1]的子串是回文),则dp[i][j]也为真。这样,对于任意子串,只需要检查一次,并将结果存储在dp数组中。
class Solution {
private:vector<vector<string>> result;vector<string> path; // 放已经回文的子串vector<vector<bool>> isPalindrome; // 放事先计算好的是否回文子串的结果void backtracking (const string& s, int startIndex) {// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了if (startIndex >= s.size()) {result.push_back(path);return;}for (int i = startIndex; i < s.size(); i++) {if (isPalindrome[startIndex][i]) { // 是回文子串// 获取[startIndex,i]在s中的子串string str = s.substr(startIndex, i - startIndex + 1);path.push_back(str);} else { // 不是回文,跳过continue;}backtracking(s, i + 1); // 寻找i+1为起始位置的子串path.pop_back(); // 回溯过程,弹出本次已经添加的子串}}void computePalindrome(const string& s) {// isPalindrome[i][j] 代表 s[i:j](双边包括)是否是回文字串 isPalindrome.resize(s.size(), vector<bool>(s.size(), false)); // 根据字符串s, 刷新布尔矩阵的大小for (int i = s.size() - 1; i >= 0; i--) { // 需要倒序计算, 保证在i行时, i+1行已经计算好了for (int j = i; j < s.size(); j++) {if (j == i) {isPalindrome[i][j] = true;}else if (j - i == 1) {isPalindrome[i][j] = (s[i] == s[j]);}else {isPalindrome[i][j] = (s[i] == s[j] && isPalindrome[i+1][j-1]);}}}}
public:vector<vector<string>> partition(string s) {result.clear();path.clear();computePalindrome(s);backtracking(s, 0);return result;}
};
小结:
列出如下几个难点:
- 切割问题可以抽象为组合问题
- 如何模拟那些切割线
- 切割问题中递归如何终止
- 在递归循环中如何截取子串
- 如何判断回文
总结出来难究竟难在哪里也是一种需要锻炼的能力
总结
- 回溯问题的进阶
- 判断回文串,可以重复选取元素,使用used数组