一、版本描述
apache-hive-2.3.9-bin.tar.gz
hadoop-2.7.0.tar.gz
下载链接:
https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz
https://dlcdn.apache.org/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz
https://archive.apache.org/dist/hadoop/zookeeper/zookeeper-3.3.2/zookeeper-3.3.2.tar.gz
二、创建安装用户
各个节点都需要执行
useradd hhs
passwd hhs
Apache_20240416
三、配置域名映射
各个节点都需要执行
vi /etc/hosts
ip1 hostname1
ip2 hostname2
......
ipn hostnamen
四、配置无密钥登录
每个节点切换到 hhs 用户生成密钥
su - hhs
ssh-keygen -t rsa
输入命令后全部回车
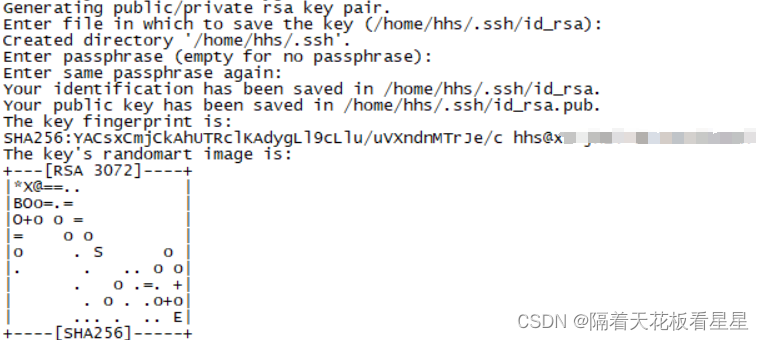
执行命令后会在~目录下生成.ssh文件夹,里面包含id_rsa和id_rsa.pub两个文件
cd .ssh
cp id_rsa.pub authorized_keys
依次将authorized_keys 复制到其他节点并把该节点的id_rsa.pub 添加到 authorized_keys
再将包含所有节点的 authorized_keys 放到每个节点的 /home/hhs/.ssh 下
scp authorized_keys hhs@目标hostname:/home/hhs/.ssh
五、关闭防火墙
各个节点使用root用户执行
systemctl status firewalld
systemctl stop firewalld
六、关闭selinux
各个节点使用root用户执行
cat /etc/selinux/config
vi /etc/selinux/config
SELINUX=enforcing 改为 SELINUX=disabled
七、调整操作系统最大数限制
各个节点使用root用户执行(重启生效)
vi /etc/security/limits.conf
* soft nofile 65535
* hard nofile 1024999
* soft nproc 65535
* hard noroc 65535
* soft memlock unlimited
* hard memlock unlimited
如果不修改,计算数据量增大时会报 打开的文件数过多 错误 ,因为linux处处皆文件,所以也会限制socket打开的数量,当各个节点数据传输增大时就会导致整个错暴漏出来
测试
ulimit -a
八、操作系统内核调优-网络部分
各个节点使用root用户执行
vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 1000 65534
net.ipv4.tcp_fin_timeout=30
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_recycle=1
如果 小文件特别多,错误文件特别多(主要时受损的压缩文件) 这个时候就会报如下错:
23/11/28 17:11:58 WARN hdfs.DFSClient: Failed to connect to /10.183.243.230:9866 for block BP-1901849752-10.183.243.230-1672973682151:blk_1074692119_951295, add to deadNodes and continue.
java.net.BindException: Cannot assign requested address
“Cannot assign requested address.”是由于linux分配的客户端连接端口用尽,无法建立socket连接所致,虽然socket正常关闭,但是端口不是立即释放,而是处于TIME_WAIT状态,默认等待60s后才释放,端口才可以继续使用。在http查询中,需要发送大量的短连接,这样的高并发的场景下,就会出现端口不足,从而抛出Cannot assign requested address的异常。
查看当前linux系统的可分配端口
cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999
当前系统的端口数范围为32768~60999, 所以能分配的端口数为28231。如果我的连接数达到了28231个,就会报如上错误。
1、修改端口范围
vi /etc/sysctl.conf
#1000到65534可供用户程序使用,1000以下为系统保留端口
net.ipv4.ip_local_port_range = 1000 65534
2、配置tcp端口的重用配置,提高端口的回收效率
vi /etc/sysctl.conf
#调低端口释放后的等待时间,默认为60s,修改为15~30s 表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_fin_timeout=30
#修改tcp/ip协议配置, 通过配置/proc/sys/net/ipv4/tcp_tw_resue, 默认为0,修改为1,释放TIME_WAIT端口给新连接使用
net.ipv4.tcp_timestamps=1
#修改tcp/ip协议配置,快速回收socket资源,默认为0,修改为1 需要开启net.ipv4.tcp_timestamps该参数才有效果
#更不为提到却很重要的一个信息是:当tcp_tw_recycle开启时(tcp_timestamps同时开启,快速回收socket的效果达到),对于位于NAT设备后面的Client来说,是一场灾难——会导到NAT设备后面的Client连接Server不稳定(有的Client能连接server,有的Client不能连接server)。也就是说,tcp_tw_recycle这个功能,是为“内部网络”(网络环境自己可控——不存在NAT的情况)设计的,对于公网,不宜使用。
net.ipv4.tcp_tw_recycle=1
九、安装 JDK 和 Scala
解压
tar -xzvf jdk-8u181-linux-x64.tar.gz
tar -xvzf scala-2.11.12.tgz
配置
vi ~/.bash_profile
#-------------java setting ----------------
export JAVA_HOME=/mnt/software/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#-------------scala setting ----------------
export SCALA_HOME=/mnt/software/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
刷新配置
source ~/.bash_profile
验证
java -version
scala -version
十、安装ntp
各个节点使用root用户执行
cd /mnt/software/ntp
rpm -Uvh *.rpm --nodeps --force
配置
vi /etc/ntp.conf
master:
注释掉其他server
填写
server 127.127.1.0 fudge
127.127.1.0 stratum 8
限制从节点ip段信息,可以不配置
restrict 10.243.71.0 mask 255.255.255.0 nomodify notrap
slaver:
server server的hostname或ip prefer
启动、查看状态命令
systemctl status ntpd
systemctl restart ntpd
报错:
/lib64/libcrypto.so.10: version `OPENSSL_1.0.2' not found (required by /usr/sbin/ntpd)
解决
备份原有libcrypto.so.10
mv /usr/lib64/libcrypto.so.10 /usr/lib64/libcrypto.so.10_bak
从其他服务器找到对应的so文件复制到/usr/lib64目录下
cp libcrypto.so.10 /usr/lib64/libcrypto.so.10
手动同步
ntpdate -u ip
查看同步状态
ntpdc -np
ntpstat
十一、安装mysql
解压
tar -xzvf mysql-5.7.11-linux-glibc2.5-x86_64.tar.gz
重命名
mv mysql-5.7.11-linux-glibc2.5-x86_64 /usr/local/mysql
编写配置文件
vi /etc/my.cnf
[mysqld]
bind-address=0.0.0.0
port=3306
user=root
basedir=/usr/local/mysql
datadir=/mnt/data/mysql
socket=/tmp/mysql.sock
#character config
character_set_server=utf8mb4
symbolic-links=0
explicit_defaults_for_timestamp=true
初始化
cd /usr/local/mysql/bin/
./mysqld --defaults-file=/etc/my.cnf --basedir=/usr/local/mysql/ --datadir=/mnt/data/mysql/ --user=root --initialize
![]()
记录下临时密码:a9Mhhie*kKo3
移动mysql服务到启动目录
cd /usr/local/mysql/support-files
cp mysql.server /etc/init.d/mysql
chmod +x /etc/init.d/mysql
启动mysql
service mysql start
登录mysql修改密码
/usr/local/mysql/bin/mysql -uroot -p
报错
/usr/local/mysql/bin/mysql: error while loading shared libraries: libncurses.so.5: cannot open shared object file: No such file or directory
/usr/local/mysql/bin/mysql: error while loading shared libraries: libtinfo.so.5: cannot open shared object file: No such file or directory
复制其他节点上的这两个包到指定目录
cd /mnt/software
cp libtinfo.so.5 /usr/lib64
cp libncurses.so.5 /usr/lib64
登录成功,开始修改密码并建立hive库
alter user root@localhost identified by 'hhs#_20240416';
grant all privileges on *.* to 'root'@'%' identified by 'hhs#_20240416' ;
flush privileges;create database hive default character set utf8;
grant all privileges on hive.* to 'hive'@'%' identified by 'hhs#_20240416';
flush privileges;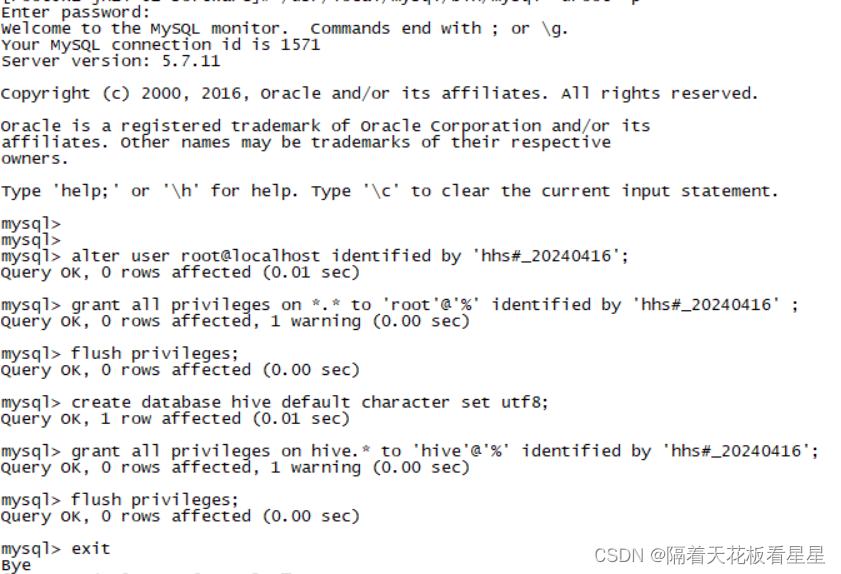
十二、安装Hadoop
以下操作均使用hhs用户
解压
tar -xzvf hadoop-2.7.0.tar.gz
各个节点创建数据目录
mkdir -p /mnt/data/hadoop/dfs
mkdir -p /mnt/data/hadoop/dfs/name
mkdir -p /mnt/data/hadoop/dfs/data
mkdir -p /mnt/data/hadoop/tmp
1、配置Hadoop守护程序的环境
vi ~/.bash_profile
#------------hadoop setting-----------------
export HADOOP_HOME=/mnt/software/hadoop-2.7.0
export HADOOP_PREFIX=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
刷新配置
source ~/.bash_profile
测试(等配置完拷贝到其他节点一起测试)
hadoop version
配置 hadoop-env.sh
vi /mnt/software/hadoop-2.7.0/etc/hadoop/hadoop-env.sh
配置JAVA_HOME
export JAVA_HOME=/mnt/software/jdk1.8.0_181
2、配置Hadoop相关配置文件
配置 core-site.xml
vi /mnt/software/hadoop-2.7.0/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://hdfs的namenode节点域名:8020</value></property><property><name>hadoop.tmp.dir</name><value>/mnt/data/hadoop/tmp</value></property>
</configuration>配置 hdfs-site.xml
vi /mnt/software/hadoop-2.7.0/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>/mnt/data/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>/mnt/data/hadoop/dfs/data</value></property>
</configuration>配置 yarn-site.xml
vi /mnt/software/hadoop-2.7.0/etc/hadoop/yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.resourcemanager.hostname</name><value>resourcemanager节点域名</value></property><property><name>yarn.resourcemanager.address</name><value>${yarn.resourcemanager.hostname}:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>${yarn.resourcemanager.hostname}:8030</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>${yarn.resourcemanager.hostname}:8088</value></property><property><name>yarn.resourcemanager.webapp.https.address</name><value>${yarn.resourcemanager.hostname}:8090</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>${yarn.resourcemanager.hostname}:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>${yarn.resourcemanager.hostname}:8033</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>30720</value></property></configuration>配置 mapred-site.xml
cd /mnt/software/hadoop-2.7.0/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>配置 slaves
vi slaves (写上所有节点的hostname)
3、分发的其他节点
cd /mnt/software
scp -r hadoop-2.7.0 hhs@其他节点域名:/mnt/software
4、格式化NameNode
cd /mnt/software/hadoop-2.7.0/bin
hdfs namenode -format

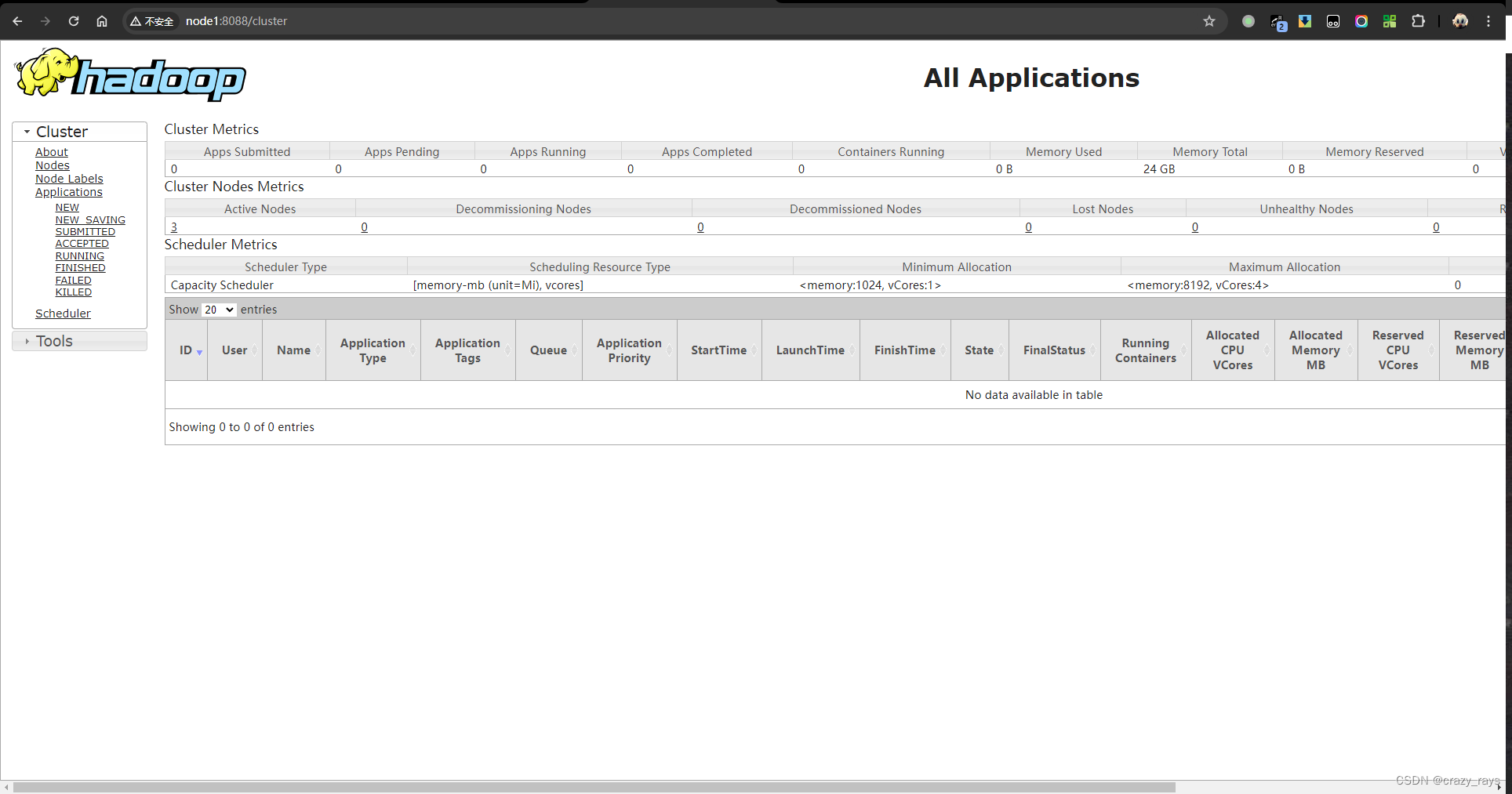
5、启动Hadoop集群
cd /mnt/software/hadoop-2.7.0/sbin
./start-all.sh
用jps在各个节点查看启动的进程,如果发现没有启动的角色也可以单独启动,如:
/mnt/software/hadoop-2.7.0/sbin/yarn-daemon.sh start resourcemanager
/mnt/software/hadoop-2.7.0/sbin/yarn-daemon.sh start nodemanager
/mnt/software/hadoop-2.7.0/sbin/hadoop-daemon.sh stop datanode
6、测试
1、输入数据制作并上传
vi file01.txt
Hello World Bye World
vi file02.txt
Hello Hadoop Goodbye Hadoop
hadoop fs -mkdir -p /user/hhs/input
hadoop fs -put file*.txt /user/hhs/input/
2、运行作业
cd /mnt/software/hadoop-2.7.0/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.0.jar wordcount /user/hhs/input /user/hhs/output
3、结果查看
hadoop fs -cat /user/hhs/output/*

十三、安装Hive
解压
tar -xzvf apache-hive-2.3.9-bin.tar.gz
1、配置环境变量
hhs用户在各个节点操作
vi ~/.bash_profile
#------------hive setting-----------------
export HIVE_HOME=/mnt/software/apache-hive-2.3.9-bin
export PATH=$PATH:$HIVE_HOME/bin
2、创建所需目录
mkdir -p /mnt/data/hive/tmp
3、配置Hive
cd /mnt/software/apache-hive-2.3.9-bin/conf
cp hive-env.sh.template hive-env.sh
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
cp hive-default.xml.template hive-site.xml
配置 hive-env.sh
vi hive-env.sh
HADOOP_HOME=/mnt/software/hadoop-2.7.0
export HIVE_CONF_DIR=/mnt/software/apache-hive-2.3.9-bin/conf
export HIVE_AUX_JARS_PATH=/mnt/software/apache-hive-2.3.9-bin/lib
配置 hive-site.xml
vi hive-site.xml
修改下面name对应的属性值
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://mysql所在节点域名:3306/hive?useSSL=false</value>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hhs#_20240416</value>
<name>hive.metastore.schema.verification</name>
<value>false</value>
将hive-site.xml 中的 添加 system:java.io.tmpdir 和 system:user.name
<property>
<name>system:java.io.tmpdir</name>
<value>/mnt/data/hive/tmp</value>
</property>
<property>
<name>system:user.name</name>
<value>hhs</value>
</property>
将MySQL的数据库连接工具包添加到Hive的“lib”目录下
cd /mnt/software
cp mysql-connector-java-5.1.47.jar /mnt/software/apache-hive-2.3.9-bin/lib
备份 hive中$HIVE_HOME/lib下面的log4j-slf4j-impl-*.jar包 到上级目录
cd /mnt/software/apache-hive-2.3.9-bin/lib
mv log4j-slf4j-impl-2.6.2.jar ..
4、分发
cd /mnt/software
scp -r apache-hive-2.3.9-bin hhs@其他节点域名:/mnt/software
5、Hive初始化
cd /mnt/software/apache-hive-2.3.9-bin/bin
./schematool -initSchema -dbType mysql

mysql中的hive库也有了对应的表和数据
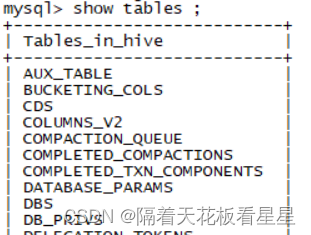
6、测试登录
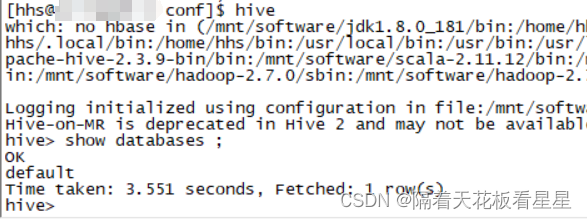
如果有报错或者卡住的现象,可以使用下面的命令打出日志查看错误
将配置好的整个hive目录分发到其他节点 (即:/mnt/software/apache-hive-2.3.9-bin)
scp -r apache-hive-2.3.9-bin hhs@节点2域名:/mnt/software
scp -r apache-hive-2.3.9-bin hhs@节点3域名:/mnt/software
......
十四、安装Spark
解压
cd /mnt/software
tar -xzvf spark-2.4.0-bin-hadoop2.7.tgz
1、配置环境变量
vi ~/.bash_profile
#------------spark setting-----------------
export SPARK_HOME=/mnt/software/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
刷新
source ~/.bash_profile
验证
echo $SPARK_HOME
2、配置Spark
cd /mnt/software/spark-2.4.0-bin-hadoop2.7/conf
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
配置slaves
将所有的节点域名都写进去(Spark 会将在列出的每台机器上启动Spark Worker)
配置spark-env.sh
export JAVA_HOME=/mnt/software/jdk1.8.0_181
export HADOOP_HOME=/mnt/software/hadoop-2.7.0
export HADOOP_CONF_DIR=/mnt/software/hadoop-2.7.0/etc/hadoop
export HIVE_HOME=/mnt/software/apache-hive-2.3.9-bin
export HIVE_CONF_DIR=/mnt/software/apache-hive-2.3.9-bin/conf
export SCALA_HOME=/mnt/software/scala-2.11.12
export SPARK_MASTER_IP=你所选择的master域名或者ip
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8081
3、分发
cd /mnt/software
scp -r spark-2.4.0-bin-hadoop2.7 hhs@其他节点域名:/mnt/software
4、启动
cd /mnt/software/spark-2.4.0-bin-hadoop2.7/sbin
./start-all.sh
哪个节点执行的./start-all.sh 哪个节点就是master
5、测试
spark-shell