文章目录
- 延时应答
- 捎带应答
- 面向字节流
- 粘包问题
- 方案一:指定分隔符
- 方案二:指定数据的长度
- TCP 报头
- 首部长度
- 保留(6 位)
- 选项
- 序号
- 确认序号
延时应答
尽可能降低可靠传输带来的性能影响
提升性能==>让滑动窗口变大
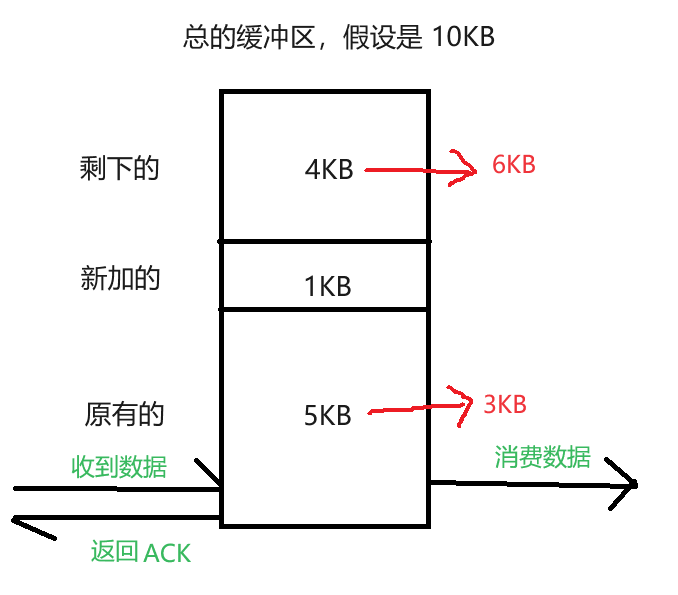
- 如果我们立即返回
ACK,此时窗口大小就是4KB - 其实在收到数据的时候,应用程序也在源源不断的消费接收缓冲区中的数据
- 所以我们返回的时间可以晚一些,这样应用程序就有机会读取缓冲区中更多的数据
- 假设让
ACK不是立即返回,而是100ms之后再进行返回,这就意味着,此时在100ms之内,应用程序可能又消费掉2KB的数据了,此时返回的ACK携带的窗口大小就是6KB
延时返回的ACK窗口大小,大概率要比立即返回ACK的窗口大小更大,因为在这个时间里,会有一个消费数据的过程
- 不是一定,只是有“大概率”,关键取决于程序是不是在不停地读取数据、延时时间内发送方是否会新发数据过来(发多了窗口还变得更小了)
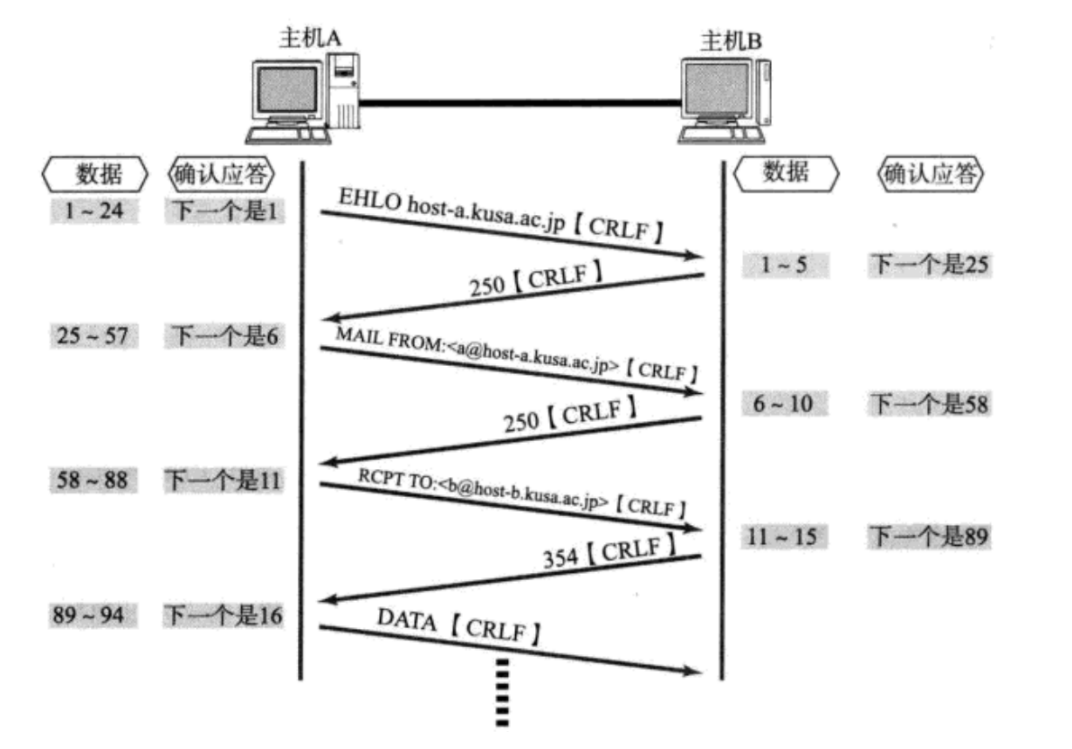
捎带应答
在延时应答的基础上,引入的提升效率的机制,把返回的业务数据和 ACK 两者合二为一了
实际网络通信中,大部分情况都是“一问一答”的形式
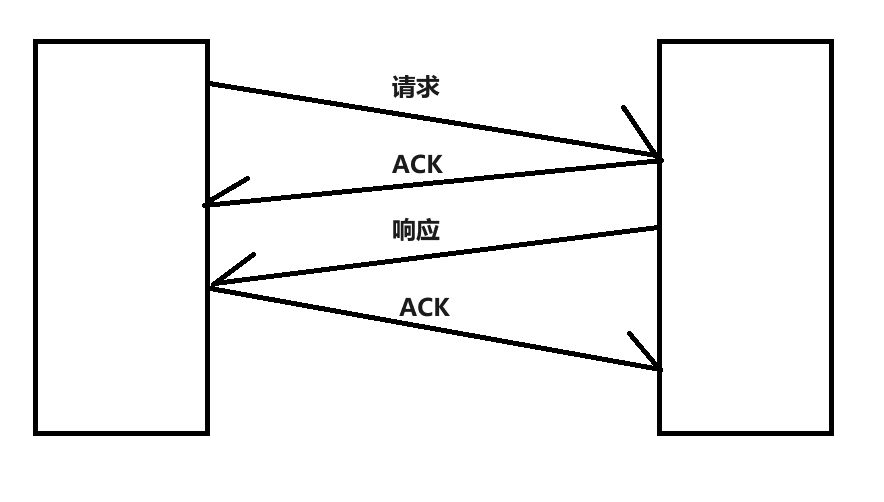
ACK是内核返回的,是收到请求之后,立即就返回ACK- 响应,则是应用程序返回的,代码中根据请求,计算得到响应,再把响应写回到客户端
正常情况下,ACK和响应是不同的时机,无法合并。但是,ACK涉及到“延时应答”, - 延时应答就会使
ACK的返回时间被往后拖,这样一延时,就可能赶上接下来发送响应数据的操作了 - 也是就可以在发送响应的时候,把刚才
ACK的信息也带上- 本身
ACK报文,不需要载荷,包头中,设置ACK这一位为1,设置窗口大小的值,设置确认序号 - 响应数据主要是设置载荷,和
ACK不冲突,可以共存
- 本身
- 在四次挥手中也说到过这样的情况,ACK 和 FIN 是不同的时机,不能合并在一起
- 但是,在延时应答之下,ACK 可能返回的时间更晚,此时,就可能可以和 FIN 合并,使四次挥手变成三次挥手
比如说,你在床上口渴了,但是你不想起来,就等到要上厕所的时候再起来,顺带把水喝了
延时应答,捎带应答都是 TCP 提升性能的机制。TCP 之所以复杂,不仅仅在考虑可靠传输,还要在可靠传输的基础上尽可能提高效率
面向字节流
读写 100 个字节的数据
- 可以一次读写一个字节,分 100 次
- 一次读写 10 个字节,分 10 次
- 一次读写 50 个字节,分 2 次
- 一次读写 100 个字节,一次搞定
- …
粘包问题
通过面向字节流的方式传输数据,都是会涉及到“粘包问题”
-
粘的是 TCP 携带的载荷(应用层数据包)
-
aaa、bbb、ccc 分别是三个不同的应用层数据包
-
接收方那边就有一个接收缓冲区,三个数据就进去了
-
应用程序需要读取接收缓冲区中的数据,由于 TCP 是面向字节流的,所以怎么读都可以
- 可以读成:a,aa,b,bb,ccc
- 也可以:aaa,b,b,bc,cc
- 存在很多种读法
-
但只有一是正确的读法,才是完整的“应用层数据包”
应用层在 TCP 的接收缓冲区中连成一片,就称为“粘包问题”
要想解决粘包问题,关键就是要明确“包之间的边界”
方案一:指定分隔符
前面在写
TCP Echo Server的时候,我们约定:请求和响应都以\n结尾。
- 发送请求响应的时候,专门使用
println进行写数据- 接受请求响应的时候,专门使用
scanner.next按照\n进行解析
需要确认数据内容的正文中,不能包含分隔符。如果传输的数据,是纯文本数据的话,此时使用 \n 或者 ; 之类的可能都不合适,但是可以使用 ASCII 码表中的一些不常见的字符
方案二:指定数据的长度
比如,约定在每个应用层数据包开头的几个字节,表示数据包的长度
- 如果是传输二进制数据,这个方案就很有用
如果希望在文件中存储结构化数据,也是存在这样的问题的。所以存文件,也经常会使用 XML/JSON 这样的格式来存储(也就是解决粘包问题)
UDP 这种面向数据报的传输方式,不涉及到上述问题,因为 send/receive 得到的就是一个完整的 DatagramPacket,这里携带的二进制的字节数组,就是一个完整的应用层数据包
TCP 报头
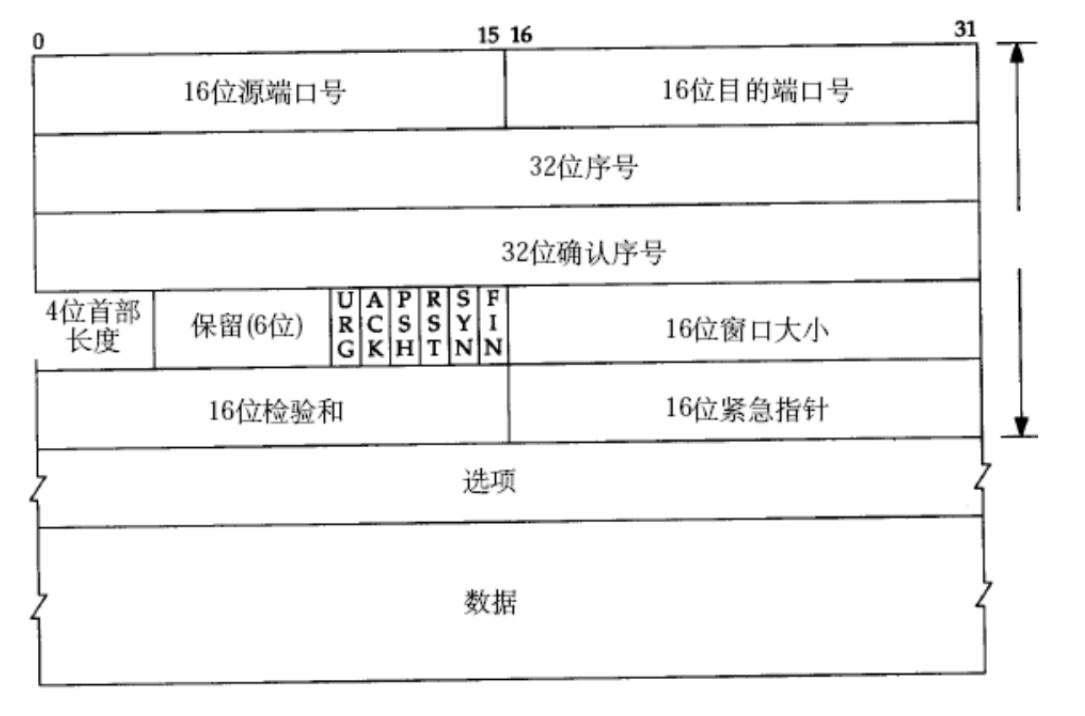
首部长度
TCP 报头的长度
UDP协议报头固定就是8个字节- 对于
TCP来说,报头长度是可变的
4 个比特位可表示的范围: 0000~1111——>0x0~0xF——>0~15- 此处的长度单位是 4 字节,不是字节(所以范围是
0~60字节)
保留(6 位)
虽然现在不用,但是先把这个东西申请下来,以备不时之需。用于考虑未来的可扩展性
- 充分吸取了
UDP的教训,UDP的报文长度字段,是没法扩展的 - 如果未来某一天,
TCP需要新增属性或者谋和属性的长度不够用,就可以把保留位拿出来,进行使用 TCP的结构不需要发生太大的改变,这样的升级就会容易很多
关于“可扩展性”也是属于编程的时候需要考虑到的一点,毕竟写的代码不可能写一份就能持续地使用。对代码做出调整,做出修改,是非常普遍、常见的情况
但是,
选项
TCP 报头边长的主要原因。四个字节为一个单位
- 可以有, 也可以没有
- 可有一个,也可有多个
通过“首部长度”确定报头有多长,如果是两个四个字节长度就是两个选项,三个四个字节长度就是三个选项,以此类推
序号
由于会出现“后发先至”的情况,所以需要通过编号,区分出数据的先后顺序
序号:表示的就是 TCP 数据报载荷中的第一个字节的序号,由于序号是连续递增,知道了第一个字节的序号,后续每个字节的序号也就知道了
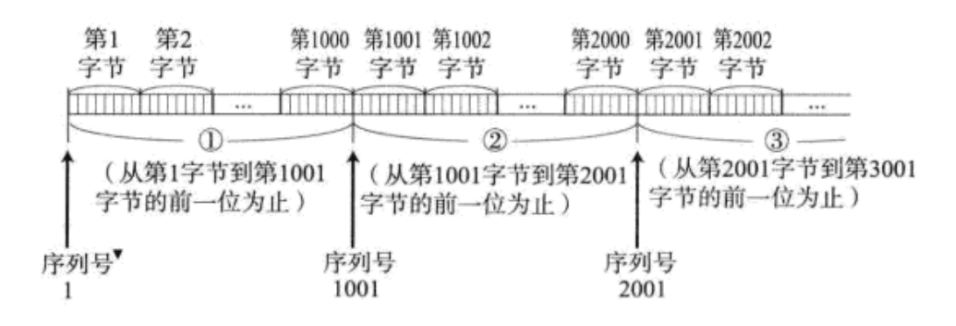
- 32 位/四字节,表示的范围是
0~42亿9千万(0~4G) - 因为
TCP是面向字节流的,所以一个TCP数据报和下一个TCP数据报携带的数据,是可以直接进行拼装的 - 比如要传输一个特别大的数据,传输过程中,本身就会通过多个
TCP数据报来进行携带,这些TCP数据报彼此之间携带的载荷都是可以在接受方自动拼起来的- 这样就不像
UDP存在传输的上限,使用UDP传输大数据,就需要考虑调用这一次send操作,参数是否超过了64KB,超过了就不行 - 使用
TCP的话就没关系,可以调用一次write,也可以调用多次write。无论怎么进行write,在网络传输和对端接收的角度来看是没有任何差别的 - 如果多次
write,传输的总数据量超过上述的4G也没关系,这里的数据序号是可以再从 0 开始重新设置的
- 这样就不像
确认序号
确认序号的设定方式,和后发先至中发短信的例子,略有差别
- TCP 序号不是按照“一条两条”来编排的,而是按照“字节”来编排的
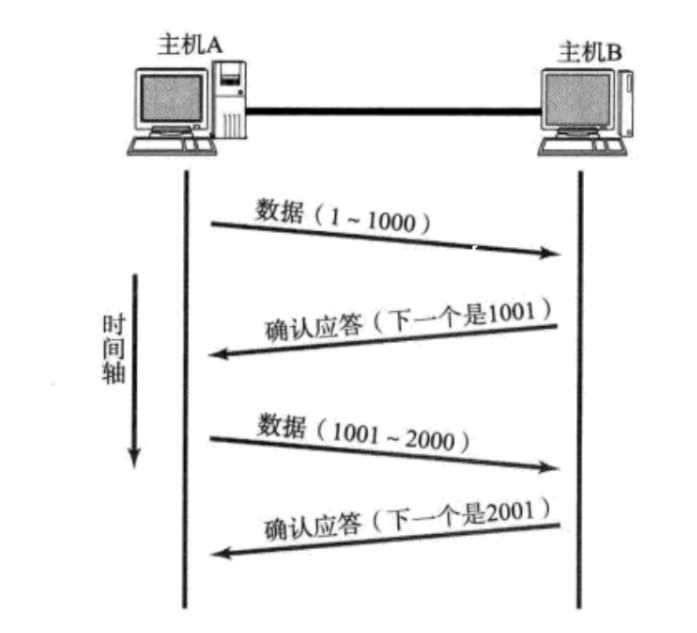
TCP 的确认序号这里,填写的是 1001,接收方收到的数据的最后一个字节序号的下一个序号
- 表示的含义是
<1001的序号的数据都收到了(TCP序号是连续增长的) - 对于应答报文来说,“确认序号”就会按照收到的数据的最后一个字节序号
+1的方式来填写 - 并且六个标志位中,第二个标志位(
ACK)会设为1- 普通报文的
ACK为0,应答报文的ACK为1 - 如果是普通报文,序号是有效的,确认序号是无效的;如果是应答报文,序号和确认序号都是有效的
- 应答报文的序号是另一套编号体系,和传输数据的序号是不一样的
- 应答报文默认情况下是不携带数据的
- 普通报文的