目录
- 前言
- 一、简介
- 二、下载与安装
- 2.1 下载
- 2.2 安装
- 2.3 配置环境变量
- 三、基本使用
- 四、Java 整合
- 4.1 导入依赖
- 4.2 添加语言库
- 4.3 代码示例
- 五、训练字库
- 5.1 为什么要训练字库
- 5.2 jTessBoxEditor
前言
如果想要通过代码的方式去识别图片中的文字,通常有以下几种方法:
- 第一种:使用开源的 OCR
- 第二种:使用第三方 OCR(比如阿里、百度的 OCR)
本文章是对开源 Tesseract OCR 的一个简单介绍,以及 Java 如何整合 Tesseract OCR
一、简介
什么是 OCR
OCR,即 Optical Character Recognition,是光学字符识别的简称。它是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。简言之,OCR 技术可以将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工。
OCR 技术基于图像处理和模型识别技术,其应用场景非常广泛,包括文档数字化、数据提取、自动翻译、安全监控、智能客服等,还可以应用于医疗、金融、教育等领域。衡量一个 OCR 系统性能好坏的主要指标包括拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
技术路线:
Tesseract OCR
官网:https://tesseract.patagames.com/
Tesseract OCR 是一款开源的文本识别(OCR)引擎。它主要用于识别图片中的文字,并将其转换为可编辑的文本。Tesseract OCR 是目前公认最优秀、最精确的开源 OCR 系统之一。
Tesseract OCR 支持多种语言,包括英文、中文、德文、法文等,并可以通过训练来扩展识别其他语言。它能够处理各种图像文件格式,如JPEG、PNG、TIFF 等。此外,Tesseract OCR 的准确性在同类产品中处于领先地位,对于印刷体文本的识别率高达 95% 以上。
Tesseract OCR 采用了一系列图像处理、特征提取和机器学习技术来实现文字识别的过程。它的主要功能是识别图像中的文字,并将其转换成机器可读的文本内容。它使用训练好的模型来识别字符,并通过上下文和语言模型来提高识别准确性。
值得一提的是,Tesseract OCR 提供了灵活的 API 接口,可以轻松集成到各种应用中。这款软件已经有 30 年的历史,最初是惠普实验室的一款专利软件,然后在2005年开源,自 2006 年后由 Google 赞助进行后续的开发和维护。
GitHub:https://github.com/tesseract-ocr/tesseract
二、下载与安装
2.1 下载
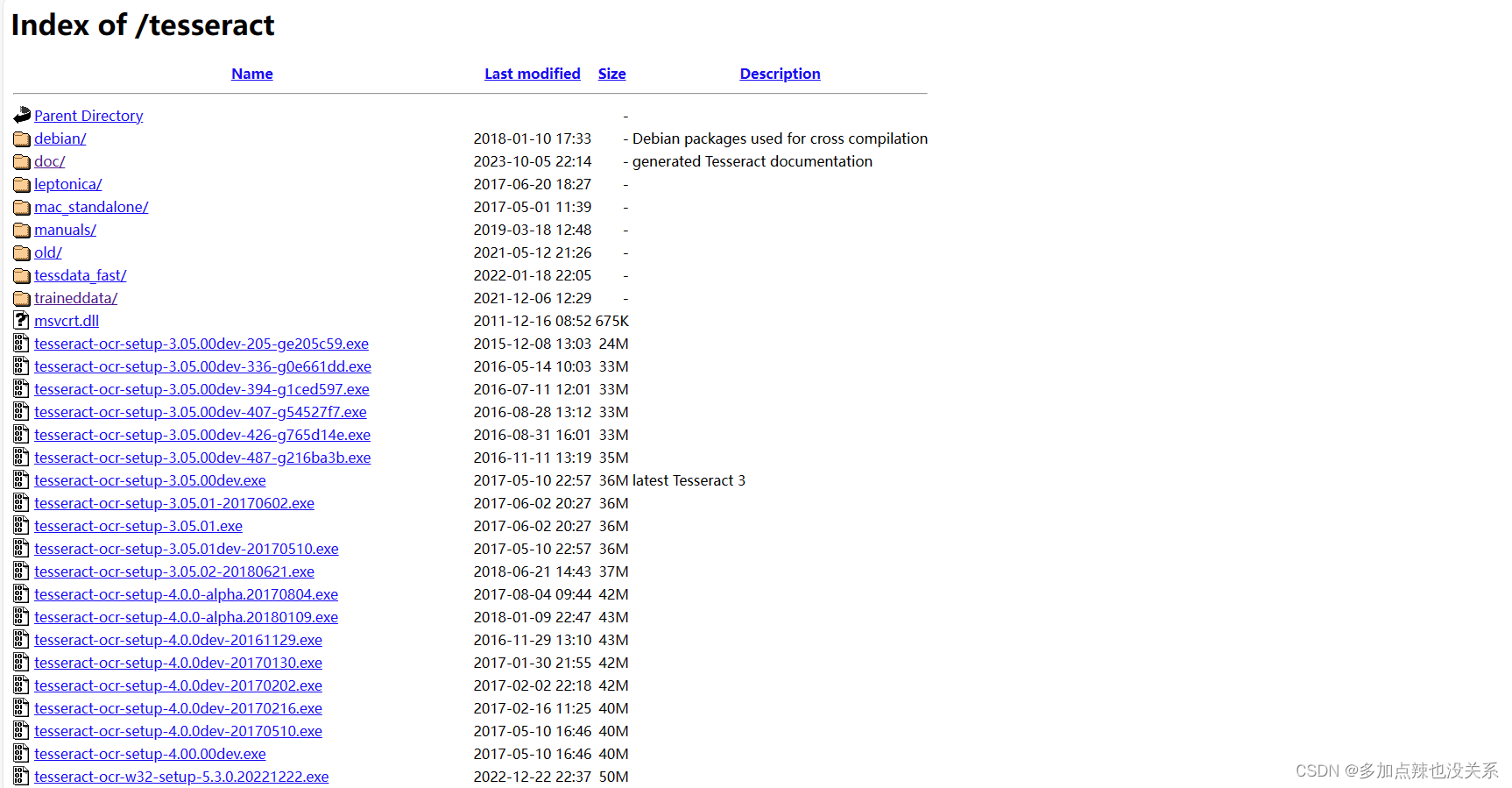
下载页面:https://tesseract-ocr.github.io/tessdoc/Downloads.html

在这里可以下载最新的二进制安装包
如果想要下载旧版本可在该地址中下载:https://digi.bib.uni-mannheim.de/tesseract/
2.2 安装
下载完成之后,双击进行安装
选择语言,点击 OK

点击 Next

点击 I Agree

点击 Next

这里有一个 Additional language data (download)添加语言库的选项,可以添加所需要识别的语言

比如你需要它识别中文和英文,则可以选择
- Chinese (Simplified):简体中文
- Chinese (Simplified Vertical):简体中文(竖排)
- English:英文
再点击,Next

选择安装路径,再点击 Next

点击 Install 开始安装


点击 Next

点击 Finish 安装结束

2.3 配置环境变量
安装完成之后需要修改一个环境变量
鼠标右键 我的电脑(此电脑) - 属性 - 高级系统设置 再选择 环境变量

找到 Path

将安装地址配置在末端,例如:;D:\tesseract-cor,记得加上 ;

再添加一个系统变量:
- 变量名:
TESSDATA_PREFIX - 变量值:
安装地址\tessdata

然后 确认 保存即可
配置好之后就可以 win + R,输入 cmd 调出命令命令窗口
输入:tesseract.exe -v,能看到对应的版本信息就表明环境变量配置成功了

通过 tesseract.exe --list-langs 命令可以查看 tesseract 所支持的语言包

三、基本使用
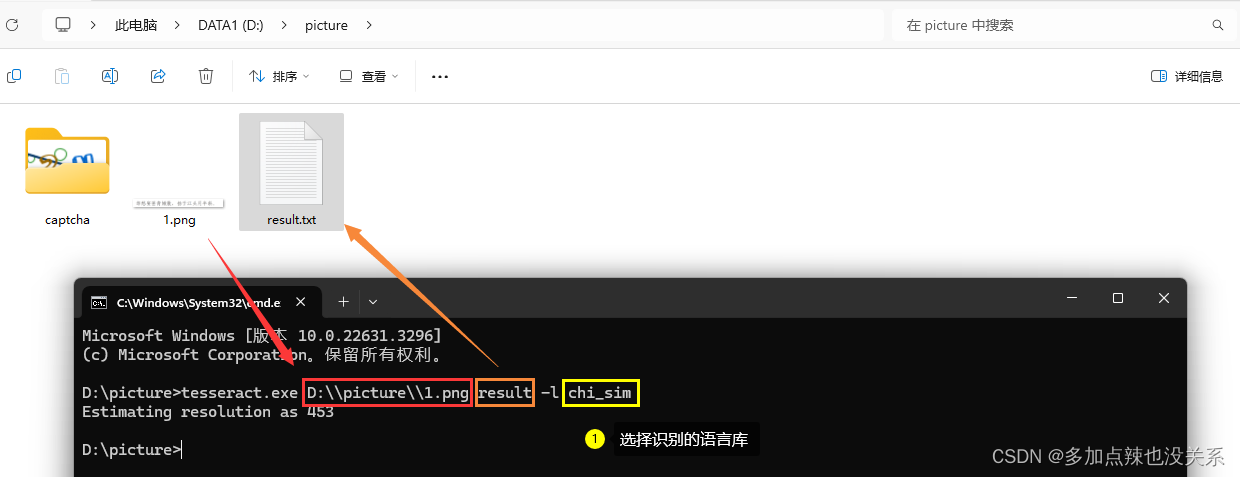
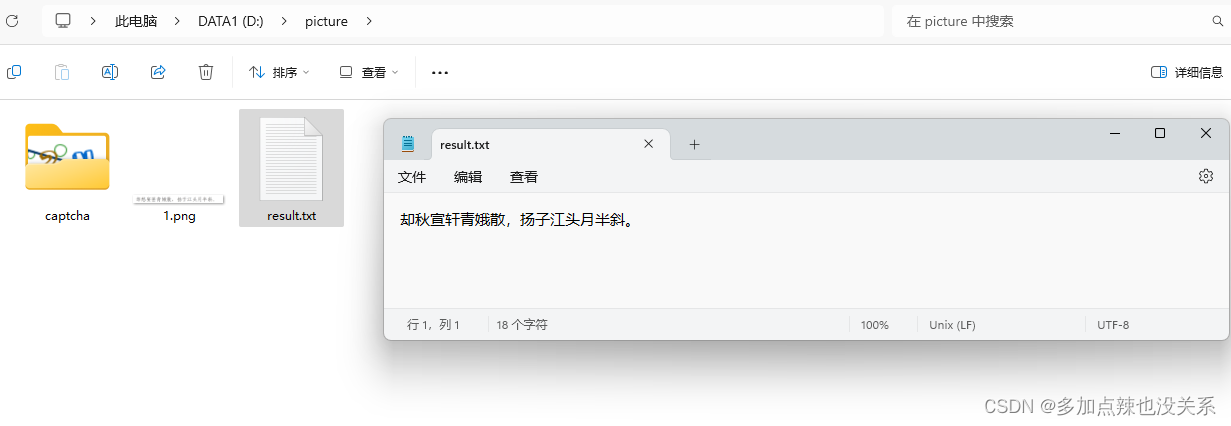
这里我准备了一张图片,用 tesseract-ocr 识别该图片中的文字

之前有配置过环境变量,通过命令的方式来读取图片中的文字
例如:tesseract.exe D:\\picture\\1.png result -l chi_sim
四、Java 整合
4.1 导入依赖
Tess4j 是 Tesseract OCR 在 Java 上的应用,在英文和数字识别中性能还是不错的,但是在中午识别中,无论速度还是识别率还是较弱,建议有条件的话,针对场景进行训练,会获得较好的结果。
依赖下载:https://mvnrepository.com/search?q=tess4j
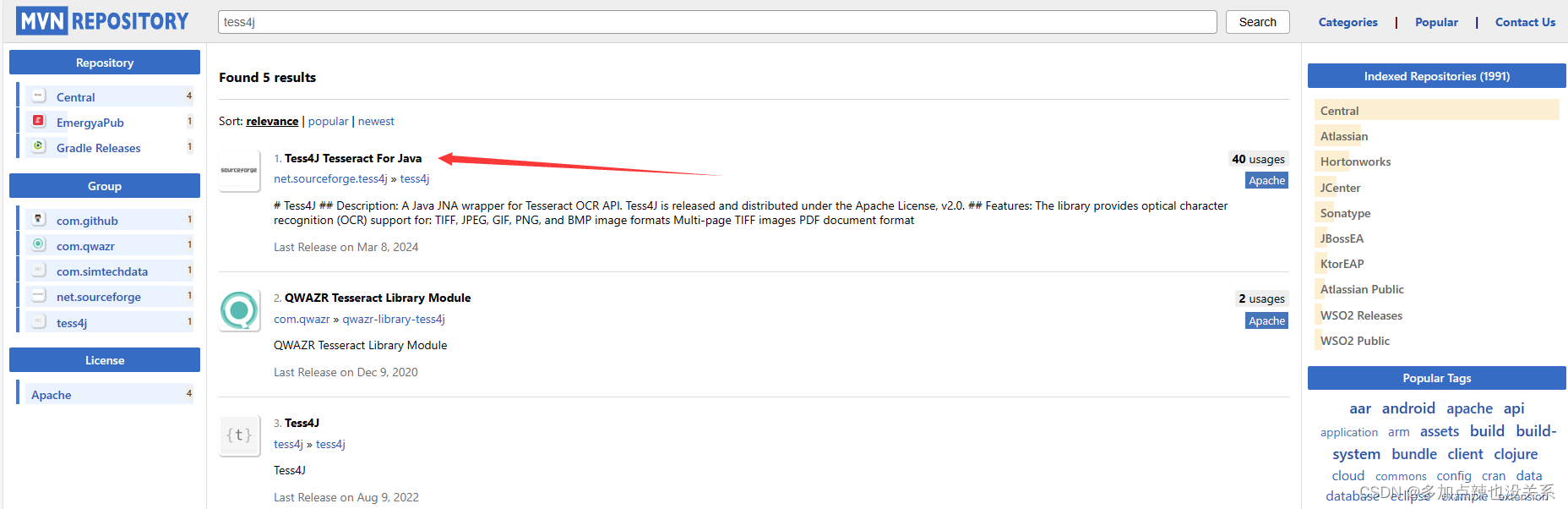

<!-- https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j -->
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>5.7.0</version>
</dependency>
4.2 添加语言库
下载语言库:https://github.com/tesseract-ocr/tessdata
或者去 Gitee 中下载:https://gitee.com/superaskar/tessdata
- 中文语言库:
chi_sim.traineddata - 英文语言库:
eng.traineddata
目前我将该语言库存放在 D:\tessdata 文件夹下

4.3 代码示例
比如我在 D:\picture 文件夹下放了一张图片 1.png
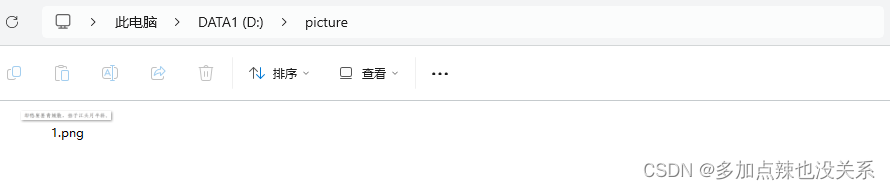
代码示例:
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;public class Demo {public static void main(String[] args) {// 图片地址String imgPath = "D:\\picture\\1.png";File imgFile = new File(imgPath);// 语言库位置String languageDataPath = "D:\\tessdata";Tesseract tesseract = new Tesseract();// 设置训练库位置tesseract.setDatapath(languageDataPath);// 中文:chi_sim// 英文:eng// 中英文:chi_sim+engtesseract.setLanguage("chi_sim");String result = null;try {result = tesseract.doOCR(imgFile);} catch (TesseractException e) {e.printStackTrace();}System.out.println(result);}
}
输出结果:

可以看到是有成功识别出图片上的文字的
五、训练字库
5.1 为什么要训练字库
虽然在上述案例中是有正确的识别出图片中的文字,这主要得益于被识别图片清晰且容易被识别,在很多情况下其实是无法满足提取图片中的文字这项要求的,比如这张图片:

最后输出的结果为:

就会发现正确率下降了很多
或者说我这里有几张验证码
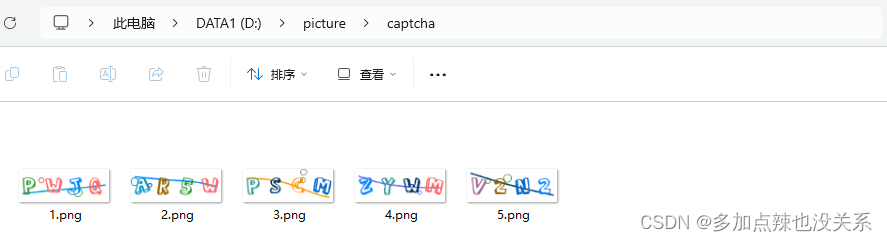
识别也是有问题的
面对一些比较复杂的图片,可以看到识别的正确率不是很高,因此需要针对特定情况用自己的样本进行训练,提高识别率,通过训练,也可以形成自己的语言库。
5.2 jTessBoxEditor
jTessBoxEditor 是一个光学字符识别(OCR)程序,主要用于编辑 Tesseract OCR 引擎生成的盒子文件。盒子文件包含单词或字符在图像中的位置和大小信息,这些信息有助于 OCR 引擎正确识别图像中的文本。
jTessBoxEditor 基于 Java 开发,支持跨平台使用,能够在 Windows、Linux 和 Mac OS 等操作系统上运行。它提供了一个用户友好的界面,允许用户手动创建和修改 Tesseract 训练数据中的字符框和标签。使用 jTessBoxEditor,用户可以通过鼠标在图像上拖动来创建字符框,并可以通过单击字符框并拖动其边缘来调整其大小和位置。此外,用户还可以选中字符框后,使用文本框添加或编辑字符框的标签,这些标签通常是字符或字符序列,用于训练 Tesseract 识别这些字符。
除了基本的编辑功能,如复制、粘贴、删除、查找和替换等,jTessBoxEditor 还提供了一些高级功能,如自动排版、自动校对和文字统计等,这些功能可以大大提高编辑效率并提升文档质量。
总的来说,jTessBoxEditor 是一个功能强大且易于使用的工具,对于需要进行 OCR 处理或 Tesseract 训练数据编辑的用户来说,是一个很好的选择。
下载与安装
下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/

注意:jTessBoxEditor 有两个版本,带 FX 的版本才支持中文符编辑,因此下载带 FX 版本的
这里我下载的是:jTessBoxEditorFX-2.5.0.zip
在官网上下载会比较慢,可以直接从我的网盘上下载
-----------------------------百度网盘----------------------------------
链接:百度网盘
提取码:k7kg
----------------------------------------------------------------------
下载完成之后直接解压即可:

启动程序
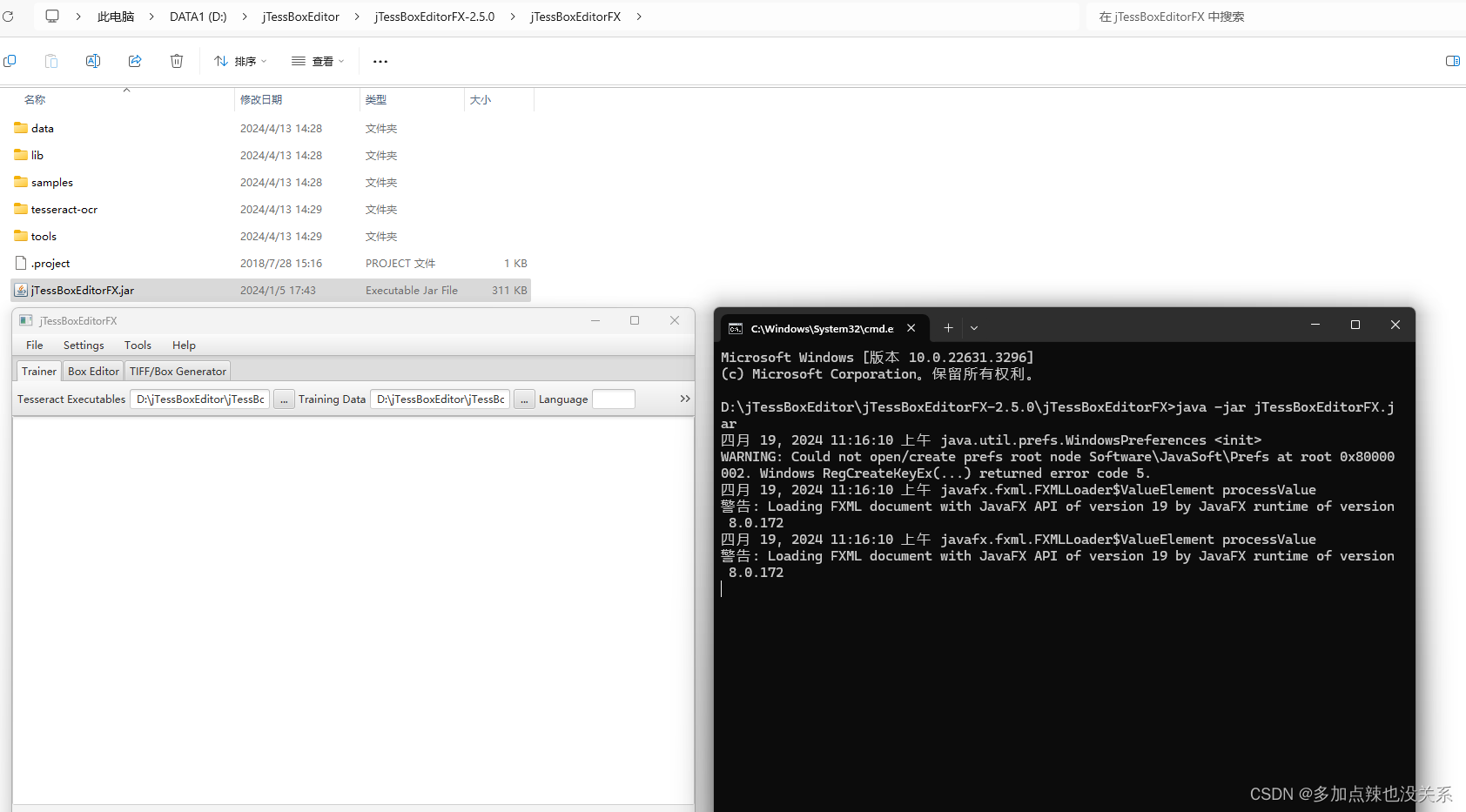
可以看到这里有个 jTessBoxEditorFX.jar,所以如果想要运行该程序,需要先配置 java 环境
既然是一个 jar 包,就可以直接用 java -jar 去启动
java -jar jTessBoxEditorFX.jar
训练字库
以上述几张验证码为例,通过这些验证码形成自己的语言库
首先需要先整合图片,点击 Tools

选择 Merge TIFF...

默认情况下是查询 TIFF 格式的图片,如果训练的图片不是 TIFF 格式的,则选择 All Image Files ... 这个选项,就能看到所有的图片了

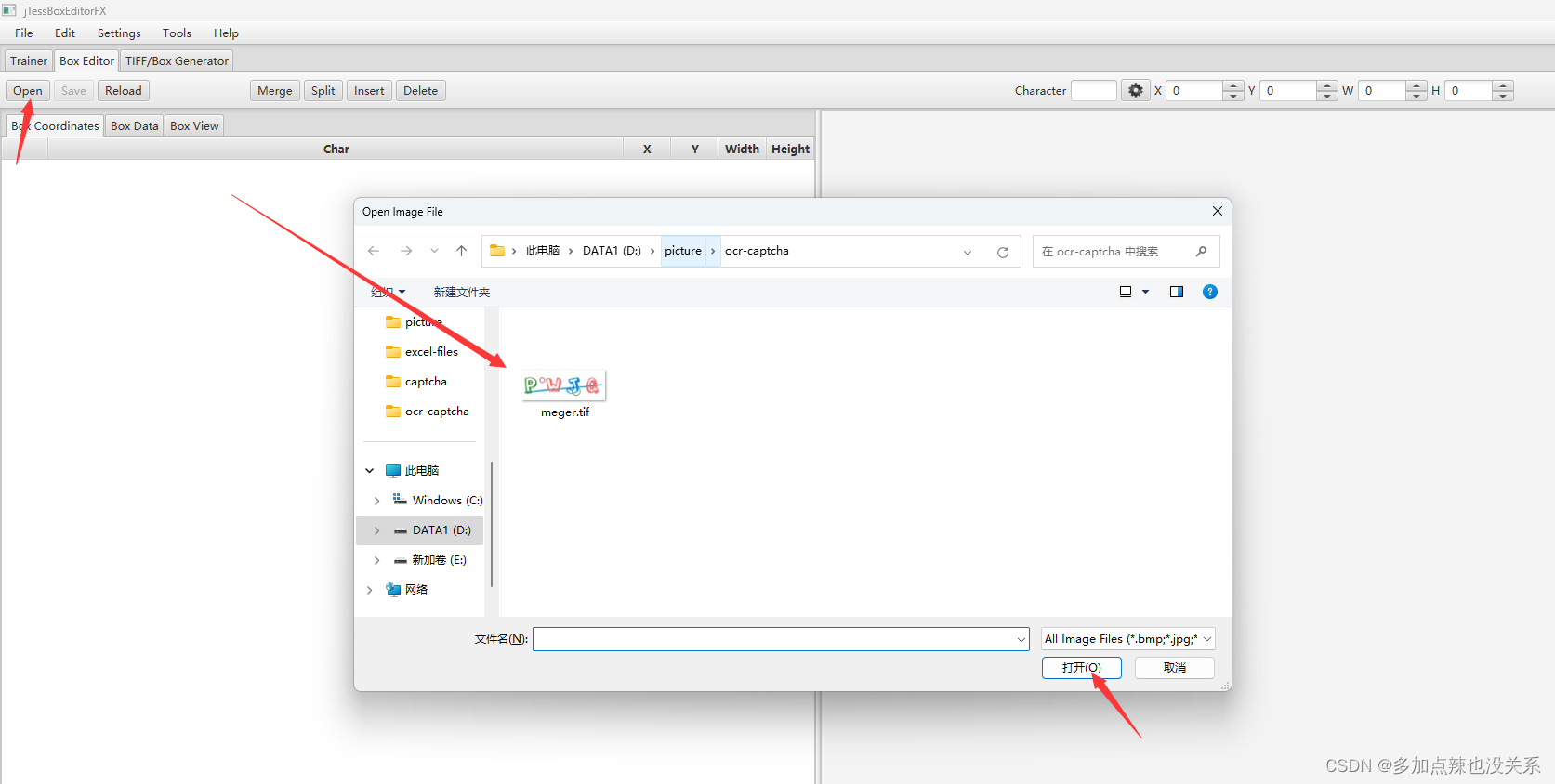
选择需要整合的图片,点击 打开

指定整合后图片的地址和名称后,点击 保存
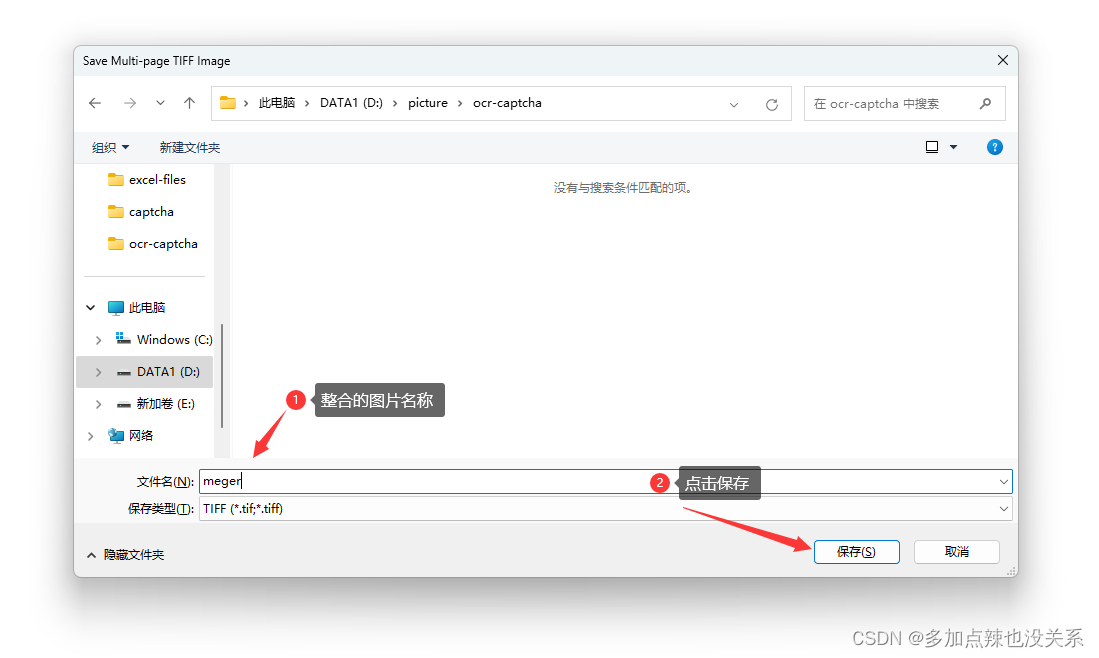

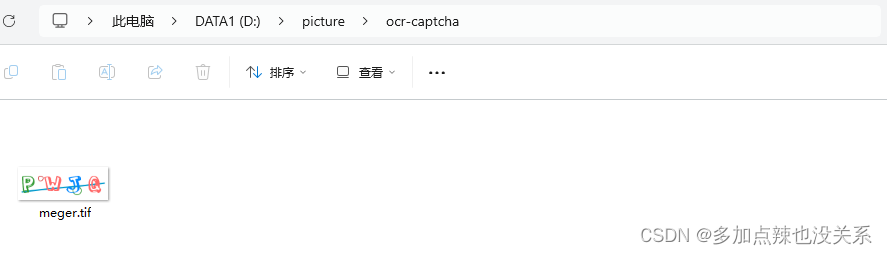
在对应的文件夹下就会出现一个 tif 格式的图片文件
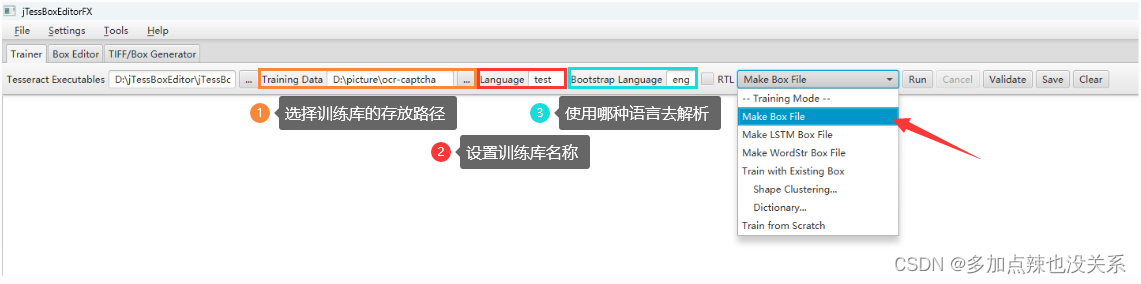
接着在 Trainer 中配置以下内容
点击 Run
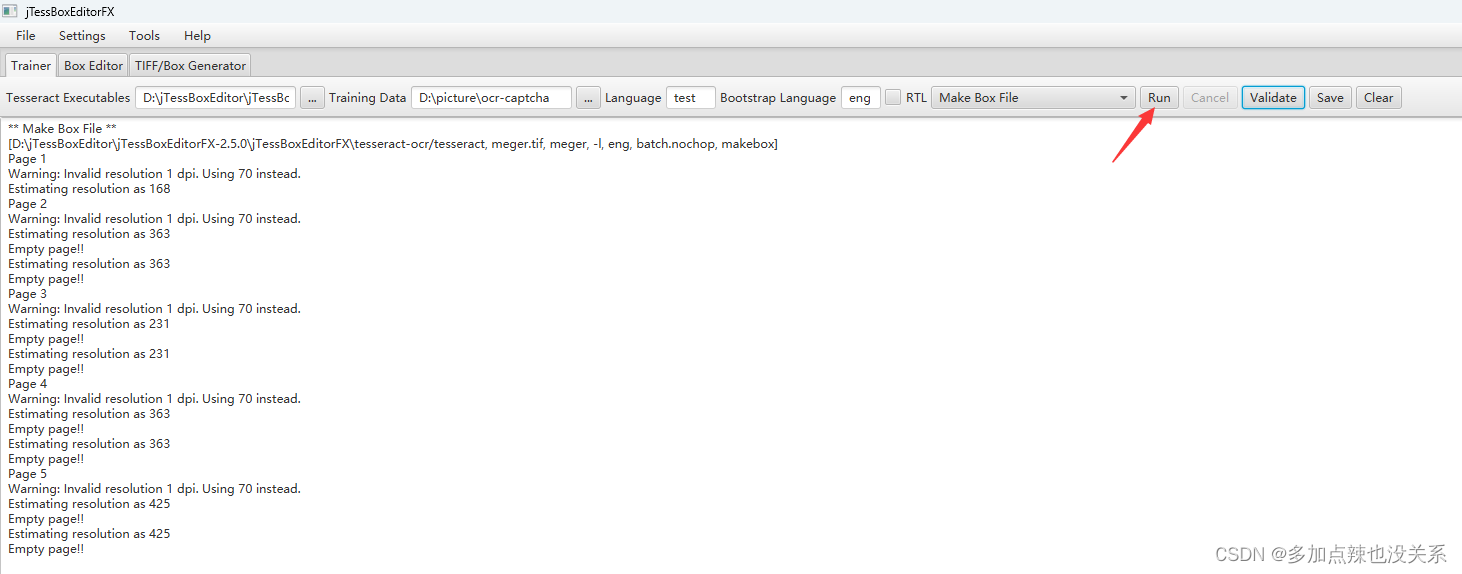
就会生成一个 .box 文件
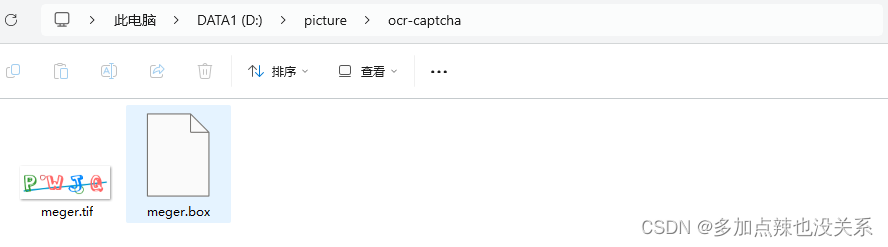
在 Box Editor 中 Open 该 .tif 文件
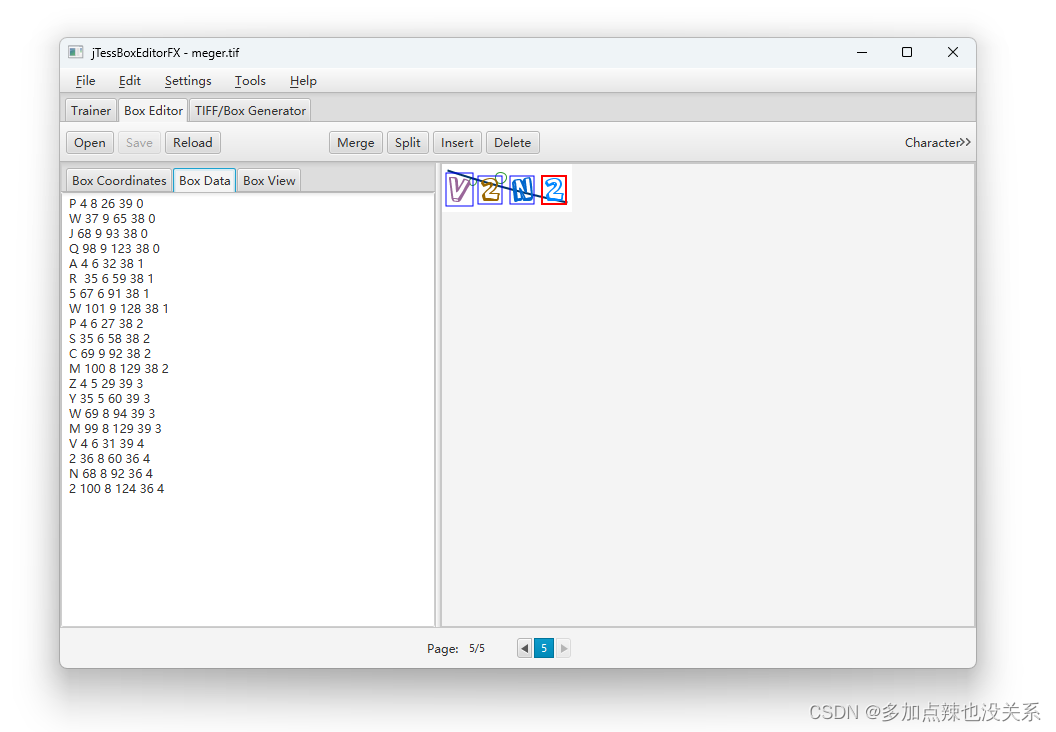
校验图片中每个字符是否正确,如果不正确则进行调整

调整完成后点击 Save 进行保存

保存之后的结果会同步到 Box Data 中
在底部可以进行图片的切换
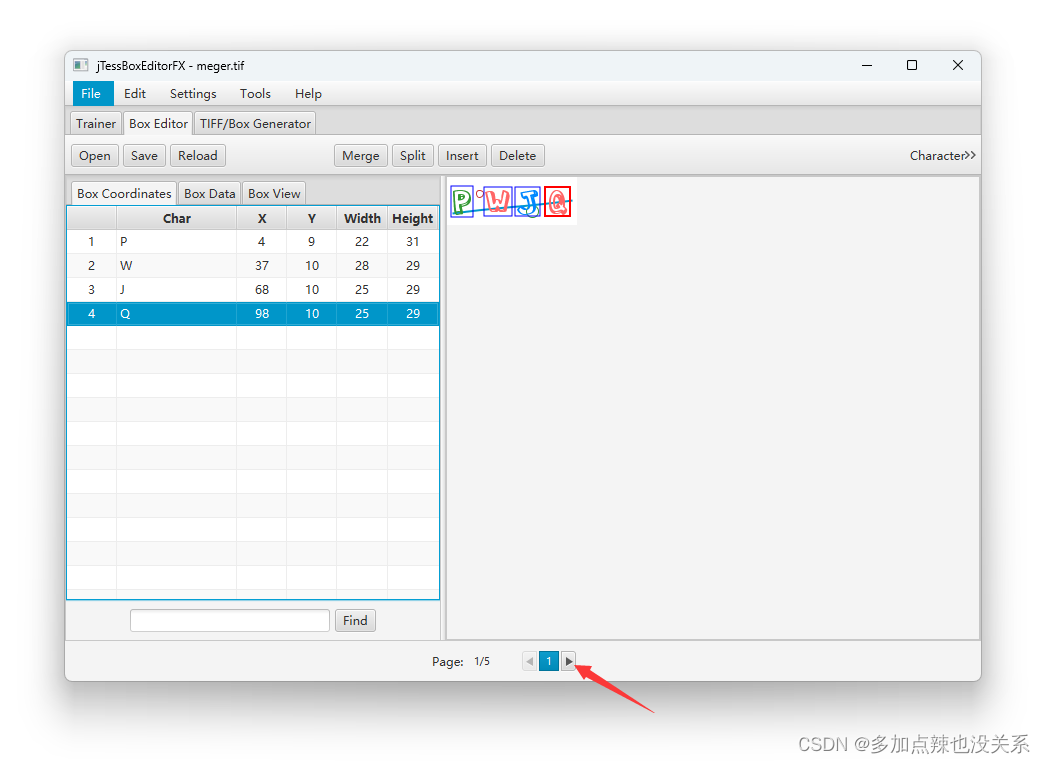
全部调整完之后就可以生成训练库
回到 Trainer 中,选择 Train with Existing Box,再点击 Run
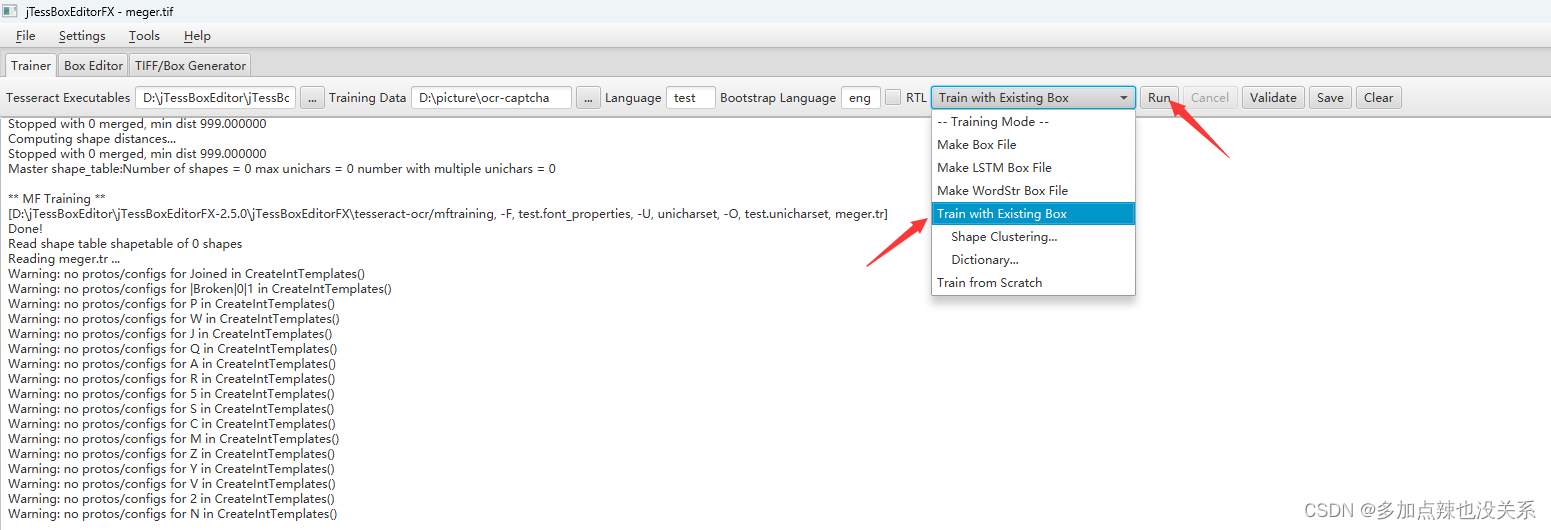
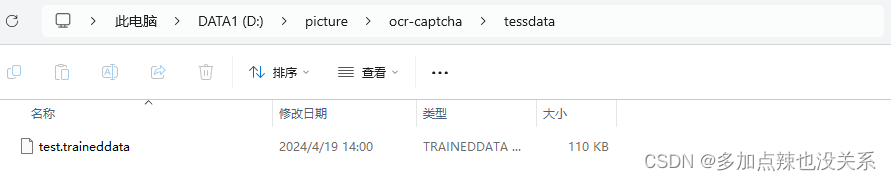
在指定的位置下就会生成训练库,训练的图片越多,识别文字的准确性就越高
参考文章:
Win11平台下OCR开源项目实践之Tesseract OCR:https://blog.csdn.net/hao_alien/article/details/134785971
Windows下Tesseract4.0识别与中文手写字体训练:https://blog.csdn.net/tly599167/article/details/116042755
Tesseract4.0训练字库 OCR 提高识别率必备(超详情):https://www.cnblogs.com/wpcnblog/p/12850590.html
使用jTessBoxEditorFX-2.2.0制作自己的字库:https://blog.csdn.net/qq_37781464/article/details/90292350
9款文字识别(OCR)工具推荐!涵盖移动端、网页端、PC端,满足您的所有需求!:https://zhuanlan.zhihu.com/p/663176898