Diffusers
StableDdiffusion
参考: Stable Diffusion原理详解(附代码实现)

Latent Diffusion
自编码器(Variational Autoencoder, VAE):
- 自编码器是一种无监督学习的神经网络,用于学习数据的有效表示或编码。
- 在稳定扩散模型中,VAE用于将高维的图像数据编码到一个低维的潜在空间中,这个空间的维度远小于原始图像空间。
- VAE由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器将输入图像压缩成一个潜在空间的向量,解码器则将这个向量重构回图像空间。
- 在潜在扩散训练过程中,编码器用于获取图像的潜在表示(latent),用于向前扩散过程中逐步增加噪音。在推断过程中,通过反向扩散过程生成的去噪潜在表示将使用VAE解码器转换回图像。在推断过程中,我们只需要VAE解码器。

U-Net:
https://blog.csdn.net/hwjokcq/article/details/140413174
- U-Net是一种流行的卷积神经网络架构,最初用于医学图像分割任务。
- 它具有对称的U形结构,包括一个收缩(编码)路径和一个对称的扩展(解码)路径。,两者都由ResNet块组成。编码器将图像表示压缩为低分辨率图像表示,解码器将低分辨率图像表示解码回原始更高分辨率图像表示
- 为防止U-Net在降采样过程中丢失重要信息,通常在编码器的降采样ResNet和解码器的升采样ResNet之间添加快捷连接(short-cut connections)。
- 稳定扩散U-Net能够通过交叉注意力层将输出条件化为文本嵌入。交叉注意力层通常添加在U-Net的编码器和解码器部分之间,通常在ResNet块之间。
- SD中Unet多用于预测噪声


文本编码器(Text-encoder):
- 文本编码器是用于处理文本数据的组件,它可以将自然语言描述转换成模型可以理解的向量形式。
- 在稳定扩散模型中,文本编码器通常使用预训练的语言模型,如BERT或GPT,来捕捉文本的语义信息。现在多用CLIP模型
- 这些编码的文本向量随后可以与潜在空间中的图像表示相结合,以生成与文本描述相匹配的图像。

STEPS
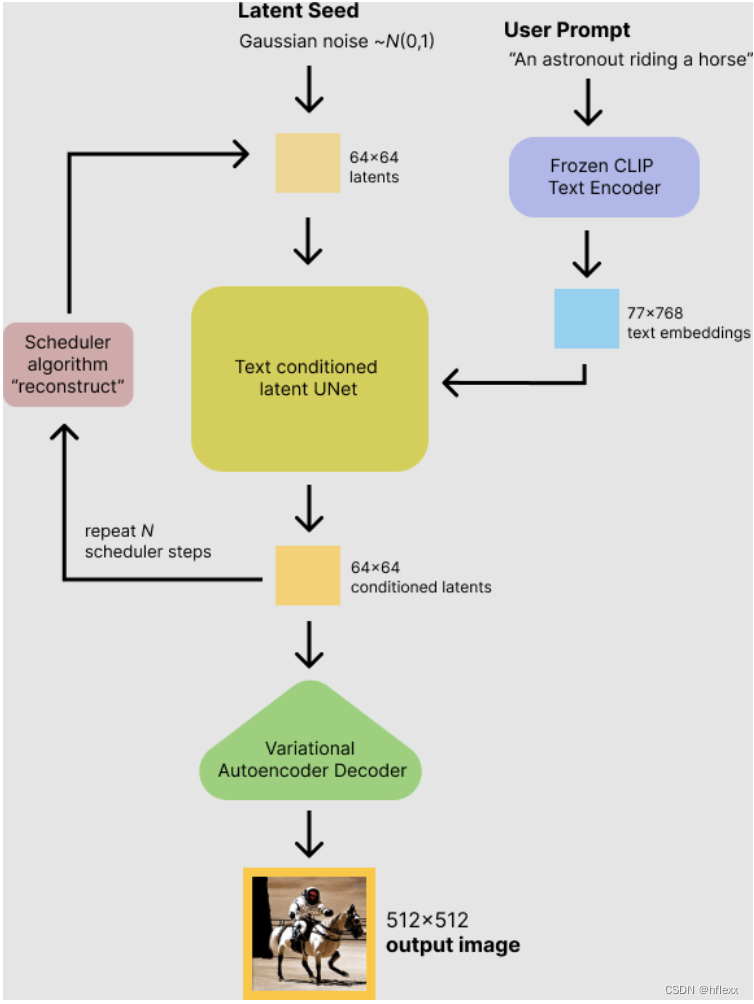

-
step1:输入:稳定扩散模型接受两个输入
- 一个是潜在种子(latent seed),用来生成64×64大小的随机潜在图像表示。
- 另一个是文本提示(text prompt),文本提示通过CLIP的文本编码器转换为77×768大小的文本嵌入,用于指导图像的生成。
-
step2:去噪denoise:U-Net在被条件化于文本嵌入的情况下逐步去噪随机潜在图像表示,U-Net的输出是噪声残差,用于通过调度算法计算去噪随机潜在图像表示。
- 调度scheduler算法:去噪后的输出(噪声残差)用于通过调度算法计算去噪后的潜在图像表示。有多种调度算法可供选择,每种算法都有其优缺点。对于Stable Diffusion,推荐使用以下之一:
- PNDM调度器(默认使用)
- K-LMS调度器
- Heun离散调度器
- DPM Solver多步调度器,这种调度器能够在较少的步骤中实现高质量,可以尝试使用25步代替默认的50步。
- 去噪过程:去噪过程大约重复50次,逐步检索更好的潜在图像表示。
- 调度scheduler算法:去噪后的输出(噪声残差)用于通过调度算法计算去噪后的潜在图像表示。有多种调度算法可供选择,每种算法都有其优缺点。对于Stable Diffusion,推荐使用以下之一:
-
step3:解码:完成去噪后,潜在图像表示由变分自编码器的解码器部分解码,生成最终的图像。
Code
Stable Diffusion原理详解(附代码实现)
Stable Diffusion原理+代码
HuggingFace&DiffusionPipeline
官网教程
https://huggingface.co/docs/diffusers/main/zh/quicktour
https://huggingface.co/docs/diffusers/main/zh/api/pipelines/overview#diffusers-summary
https://blog.bot-flow.com/diffusers-quicktour/

#先使用from_pretrained()方法加载模型:from diffusers import DiffusionPipeline
# 这里会下载模型,由于模型一般比较大,默认下载目录为~/.cache/huggingface,可通过export HF_HOME=指定目录,最好写入~/.bashrc持久化
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)#DiffusionPipeline下载并缓存所有model、tokenization、scheduling组件。
'''pipeline
# StableDiffusionPipeline {
# "_class_name": "StableDiffusionPipeline",
# "_diffusers_version": "0.21.4",
# ...,
# "scheduler": [
# "diffusers",
# "PNDMScheduler"
# ],
# ...,
# "unet": [
# "diffusers",
# "UNet2DConditionModel"
# ],
# "vae": [
# "diffusers",
# "AutoencoderKL"
# ]
# }'''
现在,可以在pipeline中输入文本提示生成图像
image = pipeline("An image of a squirrel in Picasso style").images[0]
image.save("image_of_squirrel_painting.png")#保存图像
自定义shceduler()
from diffusers import EulerDiscreteSchedulerpipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
MODEL
大多数模型采用噪声样本,并在每个时间步预测噪声残差。您可以混合搭配模型来创建其他扩散系统。模型是使用from_pretrained()方法启动的,该方法还会在本地缓存模型权重,因此下次加载模型时速度会更快。
#加载 UNet2DModel,这是一个基本的无条件图像生成模型:
from diffusers import UNet2DModelrepo_id = "google/ddpm-cat-256"
model = UNet2DModel.from_pretrained(repo_id, use_safetensors=True)model.config#访问模型参数
模型配置(cinfig)是一个冻结字典,这意味着这些参数在模型创建后无法更改。这是有意为之,并确保一开始用于定义模型架构的参数保持不变,而其他参数仍然可以在推理过程中进行调整
- sample_size:输入样本的高度和宽度尺寸。
- in_channels:输入样本的输入通道数。
- down_block_types和up_block_types:用于创建 UNet 架构的下采样和上采样模块的类型。
- block_out_channels:下采样块的输出通道数;也以相反的顺序用于上采样块的输入通道的数量。
- layers_per_block:每个 UNet 块中存在的 ResNet 块的数量。
如需使用推理(inferrence),首先需要使用随机高斯噪声创建图像(在计算机视觉领域,图像往往通过一个复杂的多维张量表示,不同的维度代表不同的含义),具体来说,这里张量的shape是batch * channel * width * height。
- batch:一个批次想生成的图片张数
- channel:一般为3,RGB色彩空间
- width: 图像宽
- height: 图像高
import torchtorch.manual_seed(0)
noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
#randn函数生成服从标准正态分布(均值为0,方差为1)的随机数noisy_sample.shape#输出形状
对于推理,将噪声图像(noisy_sample)和时间步长(timestep)传递给模型。时间步长表示输入图像的噪声程度,开始时噪声多,结束时噪声少。这有助于模型确定其在扩散过程中的位置,是更接近起点还是更接近终点。使用样例方法得到模型输出:
with torch.no_grad():noisy_residual = model(sample=noisy_sample, timestep=2).sample#noisy_residual 对应调度,给定模型输出,调度程序管理从噪声样本到噪声较小的样本
调度程序:与model不同,调度程序没有可训练的权重并且是无参数的
#使用其DDPMScheduler的from_config()
from diffusers import DDPMSchedulerscheduler = DDPMScheduler.from_pretrained(repo_id)
scheduler
- num_train_timesteps:去噪过程的长度,或者换句话说,将随机高斯噪声处理为数据样本所需的时间步数。
- beta_schedule:用于推理和训练的噪声计划类型。
- beta_start和beta_end:噪声表的开始和结束噪声值。
要预测噪声稍低的图像,需要传入:模型输出(noisy residual)、步长(timestep) 和 当前样本(noisy sample)。
less_noisy_sample = scheduler.step(model_output=noisy_residual, timestep=2, sample=noisy_sample).prev_sample
less_noisy_sample.shape
import PIL.Image
import numpy as np#首先,创建一个函数,对去噪图像进行后处理并将其显示为PIL.Image:def display_sample(sample, i):image_processed = sample.cpu().permute(0, 2, 3, 1)#匹配PIL的格式image_processed = (image_processed + 1.0) * 127.5image_processed = image_processed.numpy().astype(np.uint8)image_pil = PIL.Image.fromarray(image_processed[0])display(f"Image at step {i}")display(image_pil)#为了加速去噪过程,请将输入和模型移至 GPU:model.to("cuda")
noisy_sample = noisy_sample.to("cuda")现在创建一个去噪循环来预测噪声较小的样本的残差,并使用调度程序计算噪声较小的样本:
# 导入必要的库
import torch
import tqdm# 假设noisy_sample是之前定义的噪声样本张量
sample = noisy_sample# 使用tqdm库来显示进度条,遍历调度器scheduler中的所有时间步
for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):# 1. 预测噪声残差# 使用torch.no_grad()上下文管理器来禁用梯度计算,这通常在推理或评估阶段使用with torch.no_grad():# 调用模型的sample方法来获取噪声残差# 这里model(sample, t)可能代表模型根据当前样本和时间步预测噪声residual = model(sample, t).sample# 2. 计算更少噪声的图像,并更新样本为上一个时间步的值# scheduler.step方法根据残差、时间步和当前样本来更新样本# prev_sample属性保存了更新后的样本sample = scheduler.step(residual, t, sample).prev_sample# 3. 可选地查看图像# 每隔50步检查一次图像,以可视化生成过程# 这里display_sample是一个假设的函数,用于显示或保存图像if (i + 1) % 50 == 0:display_sample(sample, i + 1)论文:https://arxiv.org/abs/1505.04597
Unet code (only complete unet)
代码: https://github.com/yassouali/pytorch-segmentation/blob/master/models/unet.py
# 导入基础模块和PyTorch相关模块
from base import BaseModel
import torch
import torch.nn as nn
import torch.nn.functional as F
from itertools import chain
from base import BaseModel # 这里重复导入了BaseModel,可能是一个错误
from utils.helpers import initialize_weights, set_trainable # 导入初始化权重和设置参数可训练性的函数
from itertools import chain # 再次导入chain,这里也是多余的
from models import resnet # 导入resnet模型,用于UNetResnet变体# 定义一个函数x2conv,用于创建一个卷积块,包含两个卷积层和BN层
def x2conv(in_channels, out_channels, inner_channels=None):# 如果没有指定inner_channels,则将其设置为out_channels的一半inner_channels = out_channels // 2 if inner_channels is None else inner_channels# 创建一个包含两个卷积层和BN层的序列模块down_conv = nn.Sequential(nn.Conv2d(in_channels, inner_channels, kernel_size=3, padding=1, bias=False), # 第一个卷积层,通道数不变,面积收缩nn.BatchNorm2d(inner_channels), # 第一个BN层nn.ReLU(inplace=True), # ReLU激活函数nn.Conv2d(inner_channels, out_channels, kernel_size=3, padding=1, bias=False), # 第二个卷积层,对通道数进行扩张nn.BatchNorm2d(out_channels), # 第二个BN层nn.ReLU(inplace=True) # ReLU激活函数)return down_conv# 定义编码器模块,用于下采样
class encoder(nn.Module):def __init__(self, in_channels, out_channels):super(encoder, self).__init__() # 调用父类的构造函数self.down_conv = x2conv(in_channels, out_channels) # 使用x2conv函数创建卷积块self.pool = nn.MaxPool2d(kernel_size=2, ceil_mode=True) # 创建最大池化层,ceil_mode=True确保输出尺寸为整数def forward(self, x):x = self.down_conv(x) # 通过卷积块x = self.pool(x) # 通过池化层return x # 返回结果# 定义解码器模块,用于上采样
class decoder(nn.Module):def __init__(self, in_channels, out_channels):super(decoder, self).__init__() # 调用父类的构造函数self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) # 创建上采样卷积层self.up_conv = x2conv(in_channels, out_channels) # 使用x2conv函数创建卷积块def forward(self, x_copy, x, interpolate=True):x = self.up(x) # 通过上采样卷积层# 检查尺寸是否一致,如果不一致则进行插值或填充if (x.size(2) != x_copy.size(2)) or (x.size(3) != x_copy.size(3)):if interpolate:x = F.interpolate(x, size=(x_copy.size(2), x_copy.size(3)), mode="bilinear", align_corners=True)else:# 计算需要填充的尺寸diffY = x_copy.size()[2] - x.size()[2]diffX = x_copy.size()[3] - x.size()[3]# 进行填充x = F.pad(x, (diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2))# 将上采样的特征图与编码器的特征图进行拼接x = torch.cat([x_copy, x], dim=1)x = self.up_conv(x) # 通过卷积块return x # 返回结果# 定义UNet模型
class UNet(BaseModel):def __init__(self, num_classes, in_channels=3, freeze_bn=False, **_):super(UNet, self).__init__() # 调用父类的构造函数# 定义模型的各个部分#4个下采样模块self.start_conv = x2conv(in_channels, 64) # 初始卷积层self.down1 = encoder(64, 128) # 第一层编码器self.down2 = encoder(128, 256) # 第二层编码器self.down3 = encoder(256, 512) # 第三层编码器self.down4 = encoder(512, 1024) # 第四层编码器#中间卷积self.middle_conv = x2conv(1024, 1024) # 中间卷积层#上采样self.up1 = decoder(1024, 512) # 第一层解码器self.up2 = decoder(512, 256) # 第二层解码器self.up3 = decoder(256, 128) # 第三层解码器self.up4 = decoder(128, 64) # 第四层解码器#分类self.final_conv = nn.Conv2d(64, num_classes, kernel_size=1) # 最终的分类卷积层self._initialize_weights() # 初始化权重if freeze_bn:self.freeze_bn() # 如果需要,冻结BN层def _initialize_weights(self):# 权重初始化函数for module in self.modules():if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):nn.init.kaiming_normal_(module.weight)if module.bias is not None:module.bias.data.zero_()elif isinstance(module, nn.BatchNorm2d):module.weight.data.fill_(1)module.bias.data.zero_()def forward(self, x):# 前向传播函数x1 = self.start_conv(x)x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x = self.middle_conv(self.down4(x4))x = self.up1(x4, x)x = self.up2(x3, x)x = self.up3(x2, x)x = self.up4(x1, x)x = self.final_conv(x)return xdef get_backbone_params(self):# 返回模型参数,对于UNet,没有预训练的骨干网络,所以返回空列表return []def get_decoder_params(self):# 返回解码器的参数return self.parameters()def freeze_bn(self):# 冻结BN层for module in self.modules():if isinstance(module, nn.BatchNorm2d):module.eval()# 定义一个带有ResNet骨干网络的UNet变体
class UNetResnet(BaseModel):def __init__(self, num_classes, in_channels=3, backbone='resnet50', pretrained=True, freeze_bn=False, freeze_backbone=False, **_):super(UNetResnet, self).__init__() # 调用父类的构造函数# 根据指定的backbone创建ResNet模型,如果pretrained为True,则加载预训练权重model = getattr(resnet, backbone)(pretrained, norm_layer=nn.BatchNorm2d)# 提取ResNet模型的前四个部分作为初始层self.initial = list(model.children())[:4]# 如果输入通道数不是3,则替换第一个卷积层以匹配输入通道数if in_channels != 3:self.initial[0] = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3, bias=False)# 将初始层转换为Sequential模块self.initial = nn.Sequential(*self.initial)# 将ResNet模型的层1到层4作为编码器的一部分self.layer1 = model.layer1self.layer2 = model.layer2self.layer3 = model.layer3self.layer4 = model.layer4# 定义解码器的卷积层和上采样卷积层self.conv1 = nn.Conv2d(2048, 192, kernel_size=3, stride=1, padding=1)self.upconv1 = nn.ConvTranspose2d(192, 128, 4, 2, 1, bias=False)self.conv2 = nn.Conv2d(1152, 128, kernel_size=3, stride=1, padding=1)self.upconv2 = nn.ConvTranspose2d(128, 96, 4, 2, 1, bias=False)self.conv3 = nn.Conv2d(608, 96, kernel_size=3, stride=1, padding=1)self.upconv3 = nn.ConvTranspose2d(96, 64, 4, 2, 1, bias=False)self.conv4 = nn.Conv2d(320, 64, kernel_size=3, stride=1, padding=1)self.upconv4 = nn.ConvTranspose2d(64, 48, 4, 2, 1, bias=False)self.conv5 = nn.Conv2d(48, 48, kernel_size=3, stride=1, padding=1)self.upconv5 = nn.ConvTranspose2d(48, 32, 4, 2, 1, bias=False)self.conv6 = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1)self.conv7 = nn.Conv2d(32, num_classes, kernel_size=1, bias=False)# 初始化权重initialize_weights(self)# 如果需要,冻结BN层if freeze_bn:self.freeze_bn()# 如果需要,冻结ResNet骨干网络的参数if freeze_backbone: set_trainable([self.initial, self.layer1, self.layer2, self.layer3, self.layer4], False)def forward(self, x):# 前向传播函数H, W = x.size(2), x.size(3) # 保存输入的高度和宽度# 通过ResNet的初始层和层1到层4获取编码器的特征图x1 = self.layer1(self.initial(x))x2 = self.layer2(x1)x3 = self.layer3(x2)x4 = self.layer4(x3)# 通过解码器的卷积层和上采样卷积层逐步上采样并合并特征图x = self.upconv1(self.conv1(x4))x = F.interpolate(x, size=(x3.size(2), x3.size(3)), mode="bilinear", align_corners=True)x = torch.cat([x, x3], dim=1)x = self.upconv2(self.conv2(x))x = F.interpolate(x, size=(x2.size(2), x2.size(3)), mode="bilinear", align_corners=True)x = torch.cat([x, x2], dim=1)x = self.upconv3(self.conv3(x))x = F.interpolate(x, size=(x1.size(2), x1.size(3)), mode="bilinear", align_corners=True)x = torch.cat([x, x1], dim=1)x = self.upconv4(self.conv4(x))x = self.upconv5(self.conv5(x))# 如果上采样后的特征图尺寸与输入不一致,则进行插值以匹配输入尺寸if x.size(2) != H or x.size(3) != W:x = F.interpolate(x, size=(H, W), mode="bilinear", align_corners=True)# 通过最后的卷积层得到最终的输出x = self.conv7(self.conv6(x))return xdef get_backbone_params(self):# 返回ResNet骨干网络的参数return chain(self.initial.parameters(), self.layer1.parameters(), self.layer2.parameters(), self.layer3.parameters(), self.layer4.parameters())def get_decoder_params(self):# 返回解码器的参数return chain(self.conv1.parameters(), self.upconv1.parameters(), self.conv2.parameters(), self.upconv2.parameters(),self.conv3.parameters(), self.upconv3.parameters(), self.conv4.parameters(), self.upconv4.parameters(),self.conv5.parameters(), self.upconv5.parameters(), self.conv6.parameters(), self.conv7.parameters())def freeze_bn(self):# 冻结BN层for module in self.modules():if isinstance(module, nn.BatchNorm2d):module.eval()






