PyTorch:1-基础知识
注:所有资料来源且归属于thorough-pytorch(https://datawhalechina.github.io/thorough-pytorch/),下文仅为学习记录
1.1:张量
神经网络核心包:autograd(自动微分)
张量的核心:数据容器
| 张量维度 | 几何含义 |
|---|---|
| 0 | 标量 |
| 1 | 向量 |
| 2 | 矩阵 |
| 3 | 时间序列 |
| 4 | 图像 |
| 5 | 视频 |
1个图像
(width, height, channel) = 3D
1个图像数据集
(batch_size, width, height, channel) = 4D
torch.Tensor
存储和变换数据
创建tensor
【1】随机矩阵
python">import torch
# row行数, col列数
x = torch.rand(row, col)
【2】全0矩阵
python">import torch
# row行数, col列数
x = torch.zeros(row, col, dtype=torch.long)
【3】张量构建
python">import torch
# x1为元素1,x2为元素2,默认转float
x = torch.tensor([x1, x2])
【4】输出张量维度
python">print(x.size())
# or
print(x.shape)
常见构造
| 函数 | 功能 |
|---|---|
| Tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
张量的操作
【1】加法
python">x = torch.rand(row, col)
y = torch.rand(row, col)# m1
x + y
# m2
torch.add(x,y)
# m3
y.add_(x)
【2】索引
取某一行/列
python">x = torch.rand(row, col)
print(x[: 1]) # 取第2列
ps:索引出来的结果与原数据共享内存。修改一个,另一个会跟着修改。如果不想修改,可以使用copy()
【3】维度变换
torch.view() 共享内存
python">import torch
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1是指这一维的维数由其他维度决定
print(x.size(), y.size(), z.size())# torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
torch.reshape()不共享内存
python">import torch
x = torch.randn(4, 4)
y = x.reshape(16)
z = x.reshape(-1, 8) # -1是指这一维的维数由其他维度决定
print(x.size(), y.size(), z.size())# output is the same
推荐的方法:先用
clone()创造一个张量副本,然后再使用torch.view()进行函数维度变换
【4】取值
python">import torch
x = torch.randn(1)
print(type(x))
print(type(x.item()))# <class 'torch.Tensor'> 表示x是张量
# <class 'float'> 表示x的元素是浮点数
广播机制
背景:对两个形状不同的 Tensor 按元素运算
python">import torch
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
print(y)
print(x + y)
# 很明显此处讲x的row扩展为了3,y的col扩展为了2,然后再进行加法操作"""
tensor([[1, 2]])
tensor([[1],[2],[3]])
tensor([[2, 3],[3, 4],[4, 5]])
"""
1.2:自动求导
Autograd
记录张量操作
属性 .requires_grad 为 True,则会追踪对于 Tensor 的所有操作。
完成计算后可以调用 .backward(),自动计算所有的梯度。
张量的所有梯度将会自动累加到.grad属性。
防止操作追踪
防止跟踪历史记录,可以将代码块包装在 with torch.no_grad(): 中,也就是evaluate模型时所用。
每个张量都有一个.grad_fn属性,该属性引用了创建 Tensor 自身的Function。
若张量为用户手动创建,则.grad_fn = None。
计算导数
在 y.backward() 时,如果 y 是标量,则不需要为 backward() 传入任何参数;否则,需要传入一个与 y 同形的Tensor
Example
python">import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)y = x**2
print(y)
print(y.grad_fn)"""
tensor([[1., 1.],[1., 1.]], requires_grad=True)
tensor([[1., 1.],[1., 1.]], grad_fn=<PowBackward0>)
<PowBackward0 object at 0x741131d598a0>
"""
梯度
因为 out 是一个标量,因此out.backward()和 out.backward(torch.tensor(1.)) 等价,求解的导数是 d(out)/dx。
grad在反向传播过程中是累加的,所以一般在反向传播之前需把梯度清零 x.grad.data.zero_()。
雅可比向量积的例子
python">import torch
x = torch.randn(3, requires_grad=True)
print(x)y = x * 2
i = 0
while y.data.norm() < 1000:y = y * 2i = i + 1
print(y)
print(i)# y不再是标量!
# torch.autograd无法直接计算完整的雅可比矩阵
# 想要雅可比向量积,需将这个向量作为参数传给 backward
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v)print(x.grad)"""
tensor([ 0.3718, 0.4511, -0.5233], requires_grad=True)tensor([ 761.5394, 923.9069, -1071.7576], grad_fn=<MulBackward0>)10tensor([2.0480e+02, 2.0480e+03, 2.0480e-01])
"""
修改张量数值,但不被autograd记录/反向传播
可对 tensor.data 进行操作
python">import torch
x = torch.ones(1,requires_grad=True)print(x.data) # 还是一个tensor
print(x.data.requires_grad) # 但是已经是独立于计算图之外y = 2 * x
x.data *= 100 # 只改变了值,不会记录在计算图,所以不会影响梯度传播y.backward()
print(x) # 更改data的值也会影响tensor的值
print(x.grad)"""
tensor([1.])Falsetensor([100.], requires_grad=True)tensor([2.])
"""
并行计算
查看GPU情况
nvidia-smi
# windows下的cmd也可以用!
CUDA
CUDA是NVIDIA提供的一种GPU并行计算框架。
在PyTorch使用 CUDA,表示开始要求模型或者数据使用GPU。
当使用 .cuda() 时,其功能是让模型或者数据从CPU迁移到GPU上(默认是0号GPU)
设置训练所用的GPU
方法1:运行train.py时设置可用cuda
CUDA_VISBLE_DEVICE=0,1 python train.py
# 使用0,1两块GPU
方法2:在train.py开头设置可用cuda
python">import os
os.environ["CUDA_VISIBLE_DEVICE"] = "2"
常见并行方法
【1】Network partitioning
网络结构分布到不同的设备中
【2】Layer-wise partitioning
同一层的任务分布到不同数据中
【3】Data parallelism
不同的数据分布到不同的设备中,执行相同的任务
cuda加速训练
【1】单卡
显式的将数据和模型通过.cuda()方法转移到GPU上
python">model = Net()
model.cuda() # 模型显示转移到CUDA上for image,label in dataloader:# 图像和标签显示转移到CUDA上image = image.cuda() label = label.cuda()
【2】多卡
DataParallel 和 DistributedDataParallel
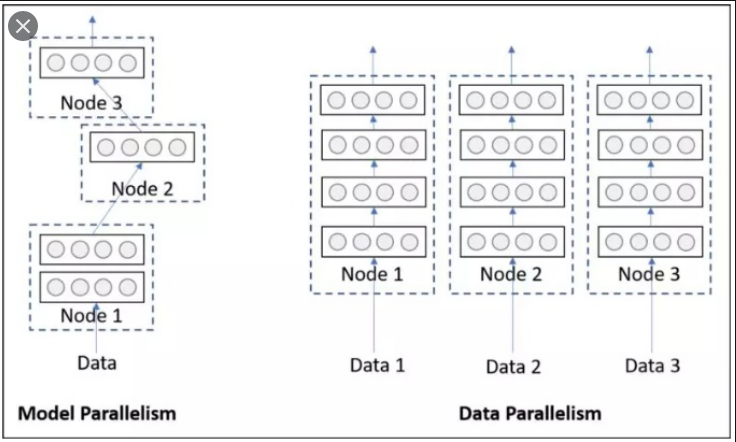
DP数据并行
python">model = Net()
model.cuda() # 模型显示转移到CUDA上if torch.cuda.device_count() > 1: # 含有多张GPU的卡model = nn.DataParallel(model) # 单机多卡DP训练
指定GPU进行并行训练
python">model = nn.DataParallel(model, device_ids=[0,1]) # 使用第0和第1张卡进行并行训练
DDP多机多卡
AI硬件加速设备
TPU
Tensor Processing Unit,张量处理器。
NPU
存中…(img-6EdY2G6i-1713698392008)]
DP数据并行
python">model = Net()
model.cuda() # 模型显示转移到CUDA上if torch.cuda.device_count() > 1: # 含有多张GPU的卡model = nn.DataParallel(model) # 单机多卡DP训练
指定GPU进行并行训练
python">model = nn.DataParallel(model, device_ids=[0,1]) # 使用第0和第1张卡进行并行训练
DDP多机多卡
AI硬件加速设备
TPU
Tensor Processing Unit,张量处理器。
NPU
Neural-network Processing Unit,神经网络处理器。