目录
一、grep
(1)用文件查找
二、正则表达式
三、sed命令
四、awk命令
grep、sed、awk可以称作linux里的三驾马车
一、grep
grep:一种强大的文本搜索工具,它能使用正则表达式匹配模式搜 索文本,并把匹配的行打印出来
格式:grep [options] pattern file
常见参数:
-w:word 精确查找某个关键词 pattern


-c:统计匹配成功的行的数量

-v:反向选择,即输出没有匹配的行
-n:显示匹配成功的行所在的行号
-r:从目录中查找pattern
-e:指定多个匹配模式
 【使用-i 忽略大小写,所以UTR也能被检测出来】
【使用-i 忽略大小写,所以UTR也能被检测出来】
-f:从指定文件中读取要匹配的 pattern
-i:忽略大小写
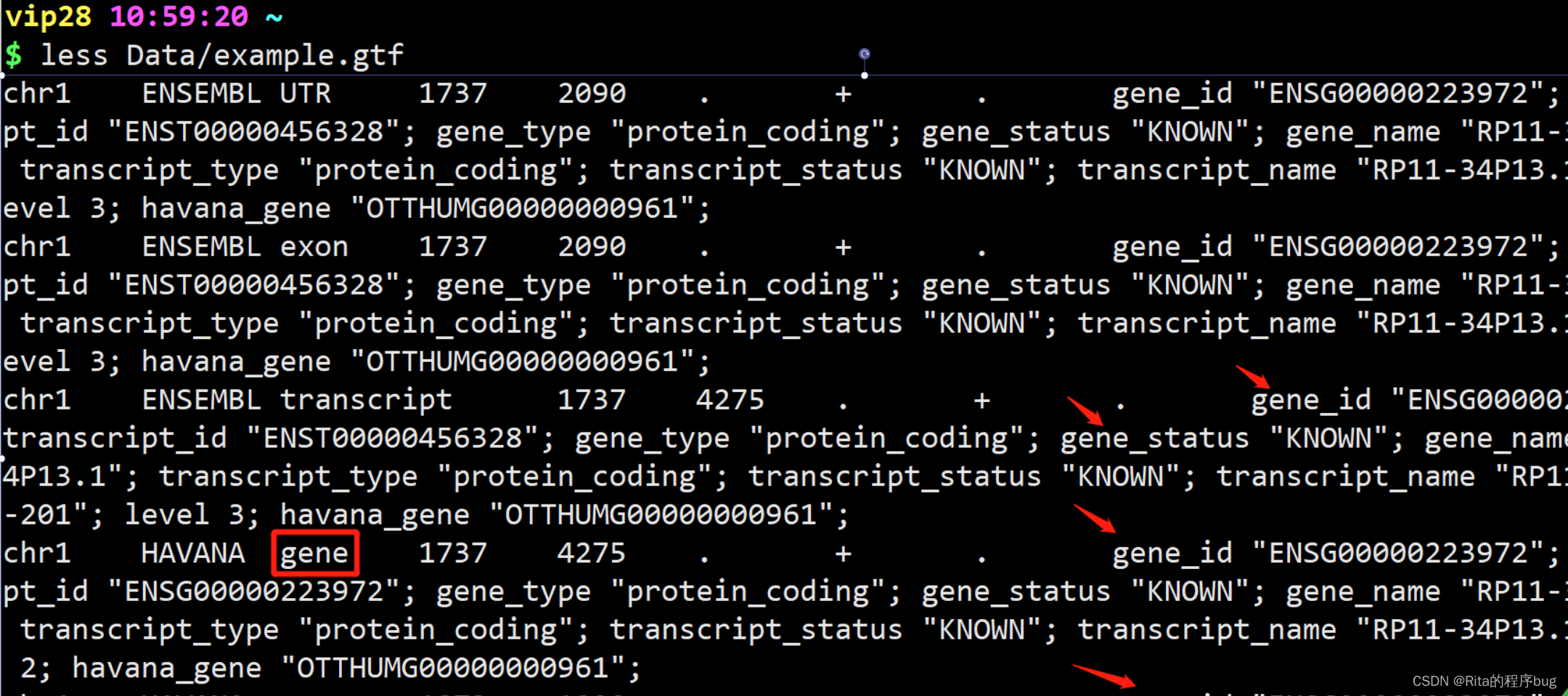
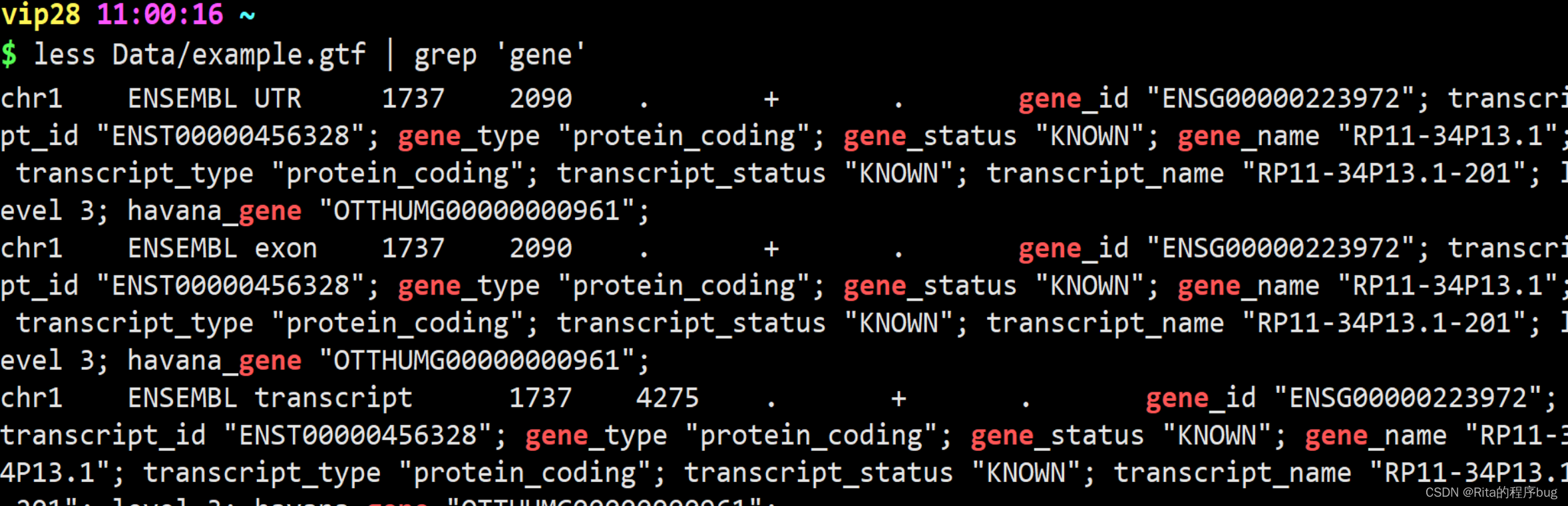
(1)用文件查找
【首先创建一个文件,编辑文件】

【编辑好内容后,按Esc,退出编辑模式,然后按:wq退出并保存】


【在面板上输入命令】


【就可以按照文件里的内容查找啦~】
二、正则表达式
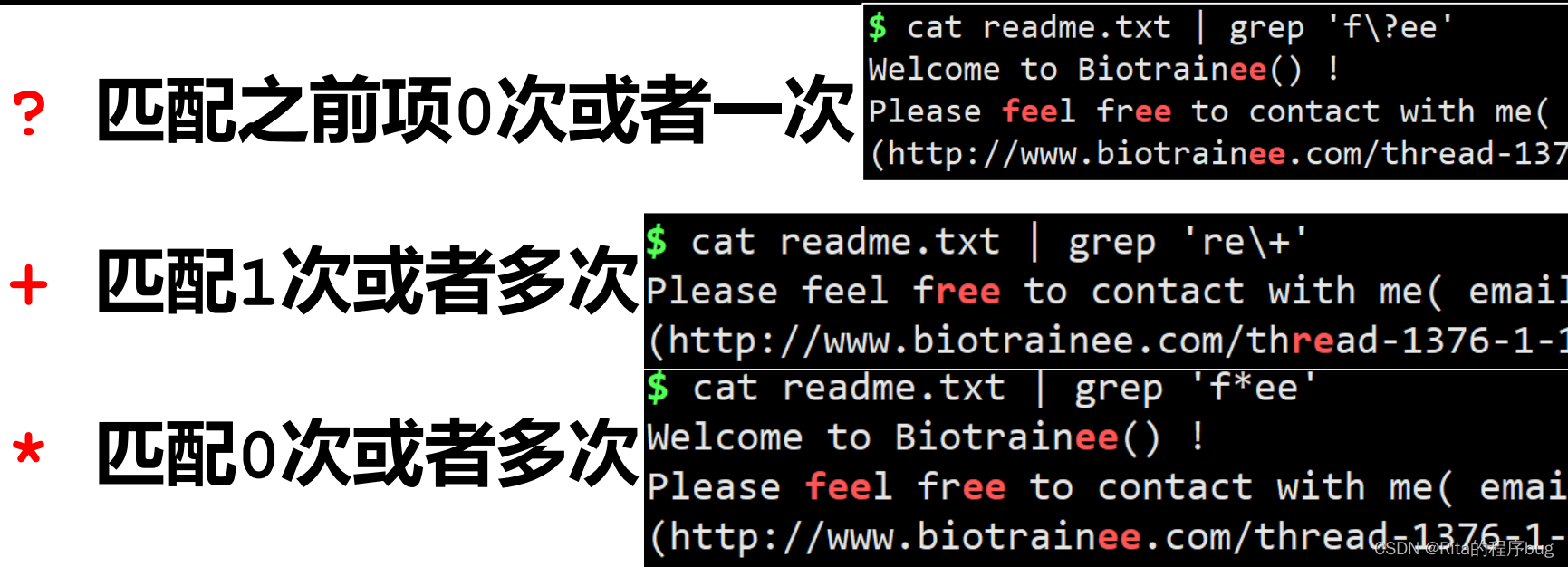
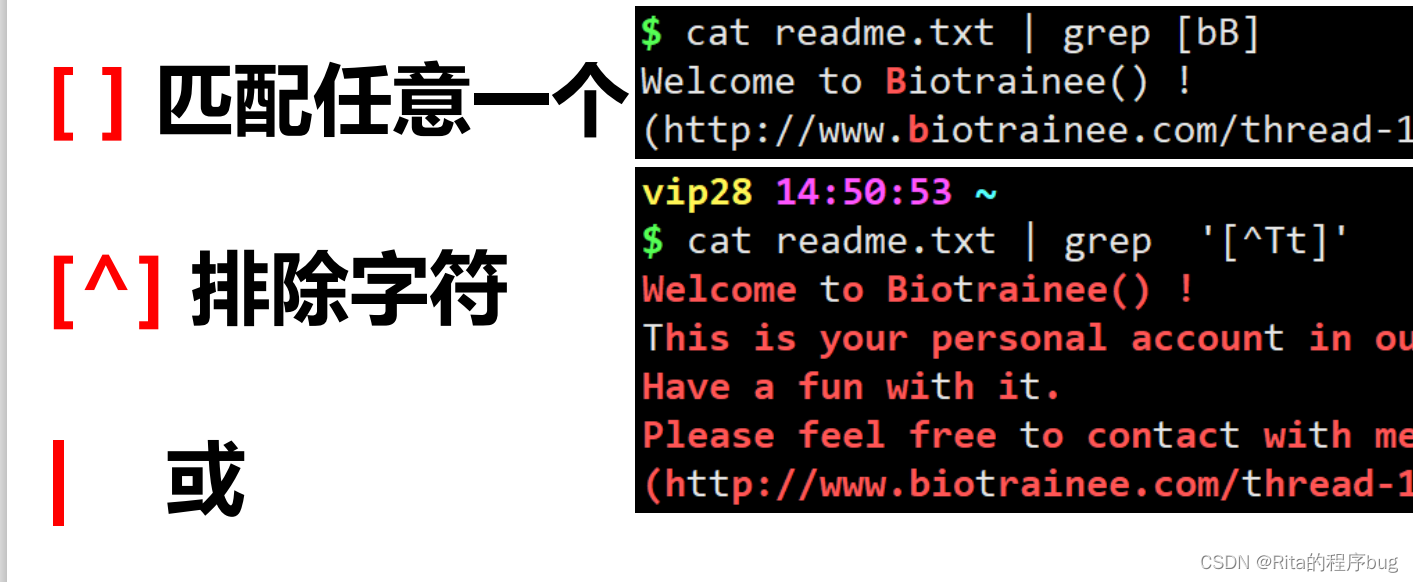
正则表达式:是对字符串操作的一种逻辑公式,就是用事先 定义好的一些特定字符、及这些特定字符的组合,组成一个 “规则字符串” ,这个“规则字符串”用来表达对字符串的 一种过滤逻辑。


【只输出查找的那一行,以W开头的那一行】
 【找以‘)’结尾的行】
【找以‘)’结尾的行】
三、sed命令
sed:流编辑器,一般用来对文本进行增删改查
用法:sed [-options] 'script' file(s)
常见参数:
-n :禁止显示所有输入内容,只显示经过sed处理的行(常用)
-e :直接在命令模式上进行 sed 的动作编辑,接要执行的一个或 者多个命令
-f :执行含有 sed 动作的文件
-r :sed 的动作支持的扩展正则(默认基础正则)
-i :直接修改读取的文件内容,不输出。

常见 'script' address :
2 ∶第 2 行
2,4 ∶第 2 行到第 4 行
2,$ ∶第 2 行到最后一行,$ 表示最后
2~3 ∶从第 2 行开始,每隔 3 行取一行2、5、8
2,+4 ∶从第 2 行到 2+4 行
/pattern/ :匹配上 pattern 的行
[!] :表示否定,取反: '2 !' 表示除了第二行

常见 'script' command :增删改查
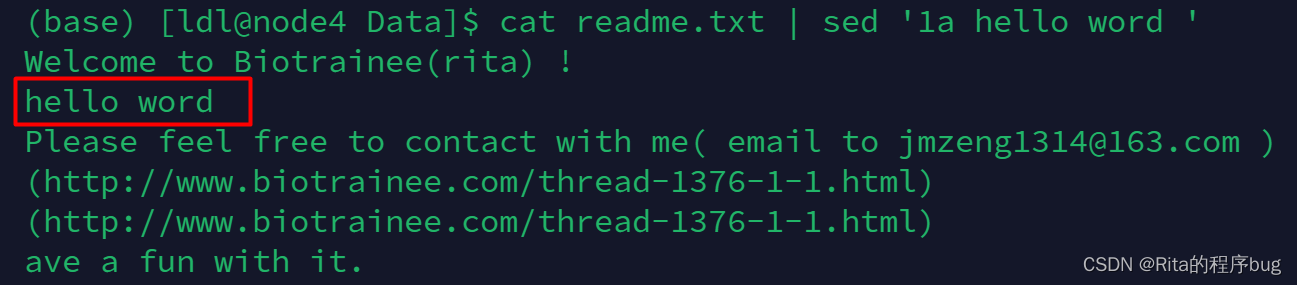
a∶append,在指定行的后增加一行,内容为 a 的后面接的字串
【原文件】

【在第一行后添加‘hello word’】
i∶insert,在指定行的前增加一行,内容为 i 的后面接的字串

d∶delete,删除某一行或者某几行,也可以指定删除匹配上的行

c∶change,改变指定行的内容
s∶更改或替换字符串,使用格式为 's/pattern/new/[flags]' ,

把pattern替换成new,默认只替换一个,可以指定flags
y∶转换,实现字符一对一转换,格式 ‘y/abc/ABC/'

p∶print,把匹配或修改过的行打印出来,通常与–n参数合用

四、awk命令
awk:也称 gawk,编程语言,可对文本和数据进行处理
常见参数:-F,fields,设置字段分隔符;
用法:awk [options] '{script}'→ file
基础结构: ' {script} '
匹配结构: ' /pattern/{script} '
扩展结构: 'BEGIN{script} {script} END{script}
awk 在读取一行文本时,会用预定义的字段分隔符划分每个数据字段,并分配给一个变量。
● $0 代表整个文本行;
● $1 代表文本行中的第1个数据字段;
●……
● $NF 代表文本行中的最后一个数据字段
awk 默认的字段分隔符是任意空白字符(如:空格 or 制表 符),也可以用 -F 参数自定义分隔符
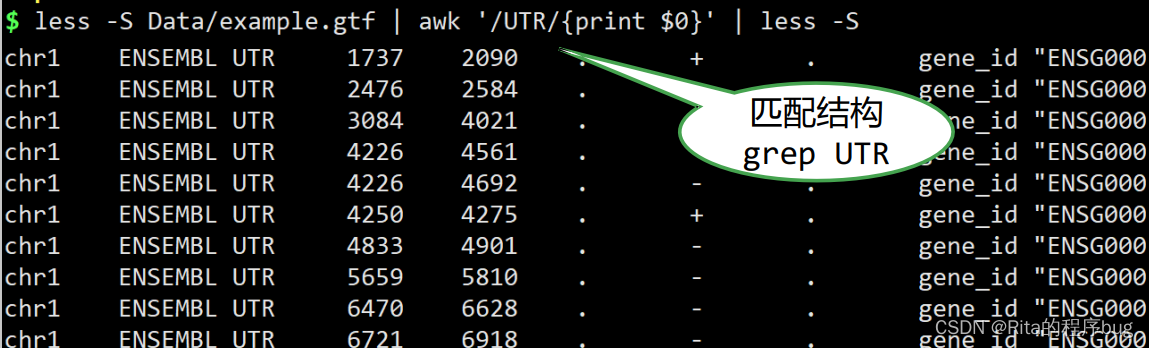
【这个是输出含有UTR的每一行】


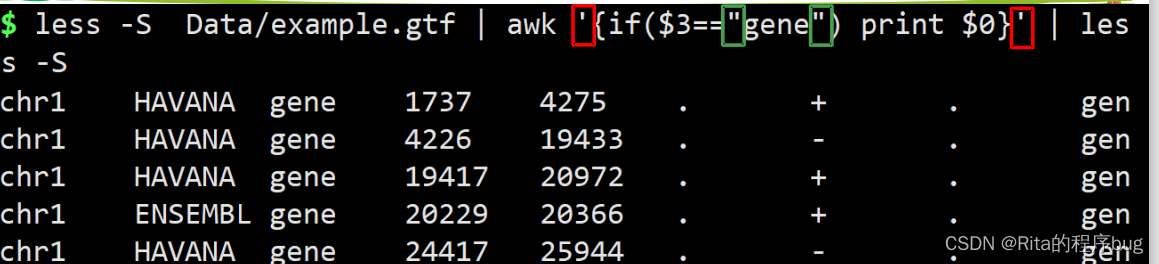
【要注意是单引号还是双引号】
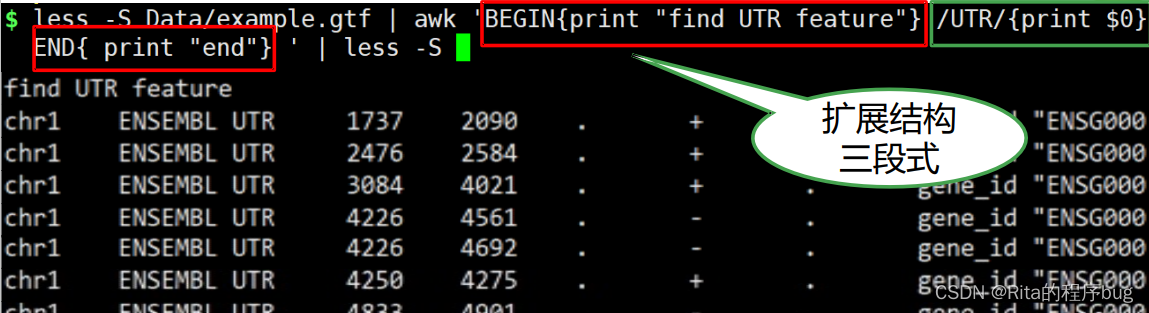




![[C语言][数据结构][链表] 双链表的从零实现!](https://img-blog.csdnimg.cn/direct/fc062952df6a4624bf8bba98a2ad2ed5.png)