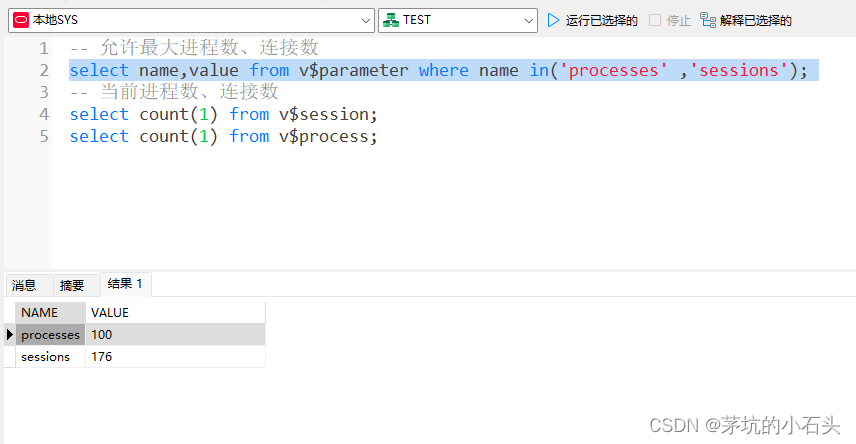
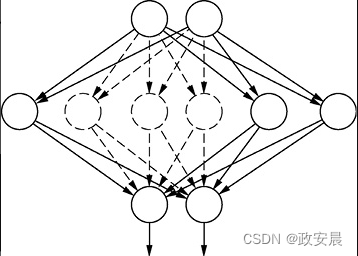
一、分区与高可用
在Kafka中,事件(events 事件即消息)是以topic的形式进行组织的;同时topic是分区(partitioned)的,这意味着一个topic分布在Kafka broker上的多个“存储桶”(buckets)上。这种数据的分布式放置对于可伸缩性非常重要,因为它允许客户端应用程序同时从多个broker读取和写入数据。当新事件发布到主题时,它实际上会附加到主题的分区之一。具有相同事件键的事件(例如,客户或车辆 ID)被写入同一分区,Kafka确保了在分区维度上读写的顺序性,即与写入完全相同的顺序读取该分区的消息。相关架构如下:
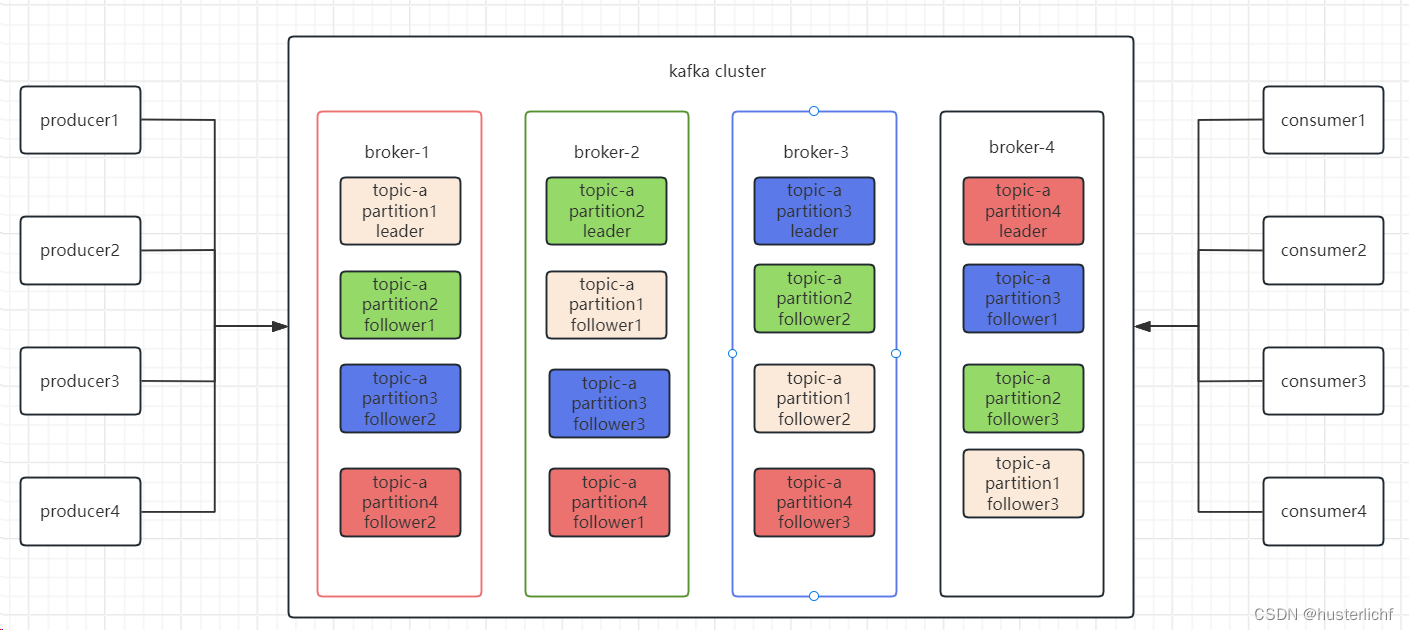
二、数据组织架构
Message是按照topic来组织,每个topic可以分成多个的partition,partition在服务器上的表现形式就是一个一个的文件夹(命名规则:topic名称+分区序号);并且为了防止log文件过大,又将partition切割成一个一个log segment,一个log segment对应三个文件,即index、log、timeindex、snapshot。log文件就实际是存储 message 的地方,而 index 和 timeindex 文件为索引文件,用于检索消息,snapshot是快照文件。这三个文件文件名一致,只是后缀不一致;
==文件命名规则:==其中每个 LogSegment 都有一个 Offset 来作为基准偏移量(baseOffset),用来表示当前 LogSegment 中第一条消息的Offset。偏移量是一个64位的 Long 长整型数,最大长度为20位数字,日志文件和这几个索引文件都是根据基准偏移量(baseOffset)命名的,名称固定为20位数字,没有达到的位数前面用0填充。比如第一个 LogSegment 的基准偏移量为0,对应的日志文件为00000000000000000000.log。相关架构如下:
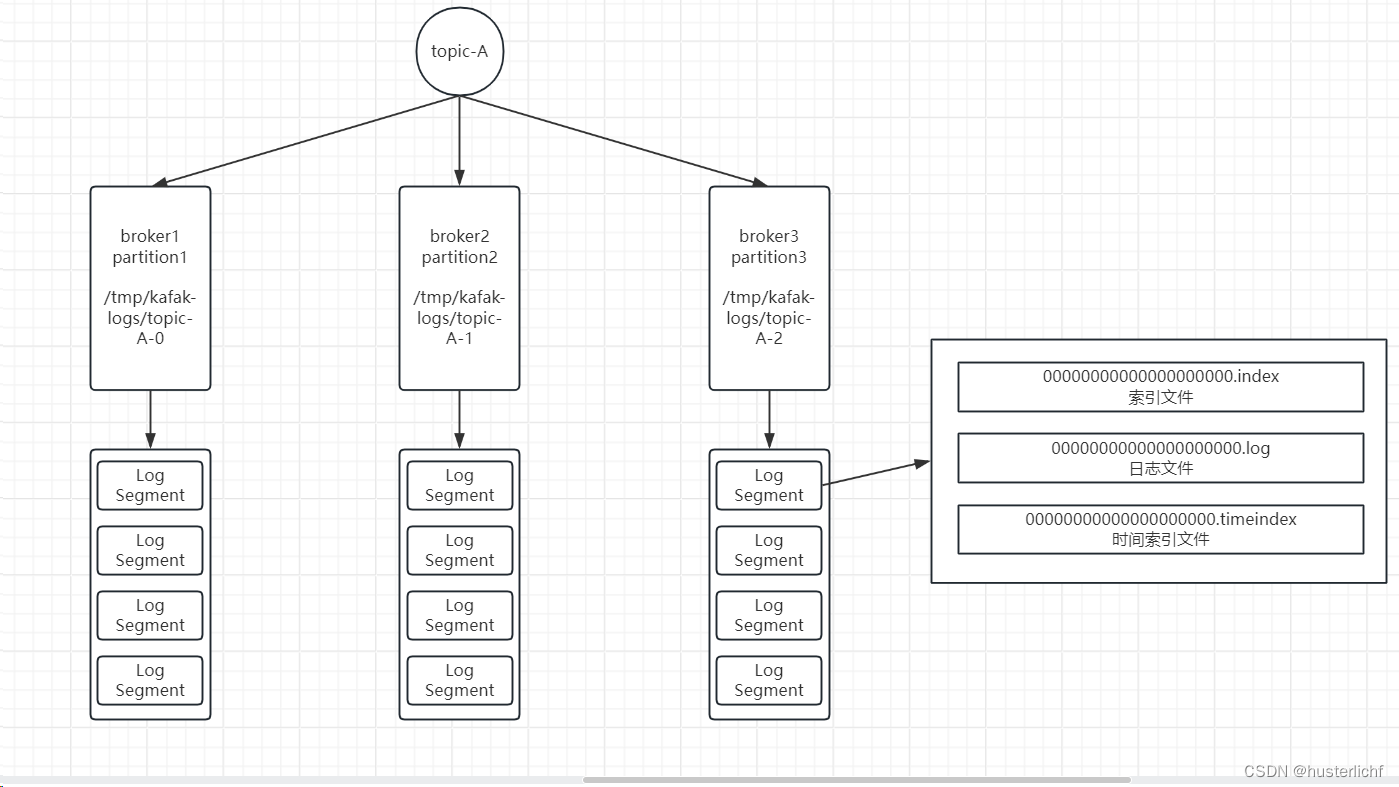
相关目录如下:
[zhjl@yyzc-zhjlpi01 bin]$ ls -lR /tmp/kafka-logs/
/tmp/kafka-logs/:
total 16
-rw-r--r-- 1 zhjl zhjl 0 Apr 14 13:51 cleaner-offset-checkpoint
-rw-r--r-- 1 zhjl zhjl 4 Apr 16 20:00 log-start-offset-checkpoint
-rw-r--r-- 1 zhjl zhjl 88 Apr 15 21:18 meta.properties
-rw-r--r-- 1 zhjl zhjl 44 Apr 16 20:00 recovery-point-offset-checkpoint
-rw-r--r-- 1 zhjl zhjl 44 Apr 16 20:00 replication-offset-checkpoint
drwxr-xr-x 2 zhjl zhjl 167 Apr 16 09:35 topic-A-0
drwxr-xr-x 2 zhjl zhjl 167 Apr 16 09:35 topic-A-1
drwxr-xr-x