赛题连接
https://challenge.xfyun.cn/topic/info?type=role-element-extraction&option=phb
Datawhale_Al__2">Datawhale Al夏令营 零基础入门大模型技术竞赛

数据集预处理
由于赛题官方限定使用了星火大模型,所以只能调用星火大模型的API或者使用零代码微调
首先训练数据很少是有129条,其中只有chat_text和infos两个属性,chat_text是聊天文本,infos就是提取的信息也是训练集标签,他的平均长度有6000左右对于星火对于信息提取任务已经很长了,而且最长的将近30000,如果使用星火大模型进行询问肯定是要被截断的,而且微调上传的数据也是有最大长度的,我门需要对数据进行处理。
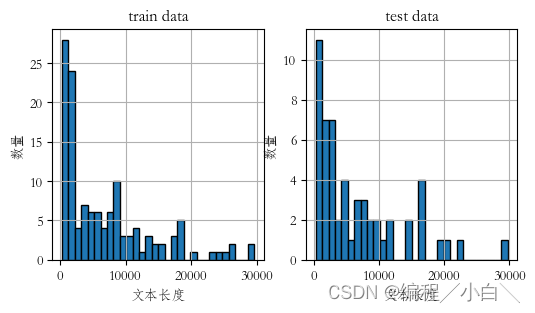
数据简单清洗
简单的导包
python">from dataclasses import dataclass
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
import pandas as pd
import os
import json
import re
import matplotlib.pyplot as plt
from tqdm import tqdm
from math import ceil
import numpy as np
from copy import deepcopy
import randomtqdm.pandas()
plt.rcParams['font.family'] = ['STFangsong']
plt.rcParams['axes.unicode_minus'] = False
加载数据
python">data_dir = "./data"
train_file = "train.json"
test_file = "test_data.json"train_data = pd.read_json(os.path.join(data_dir, train_file))
test_data = pd.read_json(os.path.join(data_dir, test_file))
首先我们发现数据集中有许多[图片]和超链接,这些对数据提取作用不大,我们可以将其去掉,
python"># 删除表情图片、超链接
train_data['chat_text'] = train_data['chat_text'].str.replace(r"\[[^\[\]]{2,10}\]", "", regex=True)
train_data['chat_text'] = train_data['chat_text'].str.replace("https?://\S+", "", regex=True)
test_data['chat_text'] = test_data['chat_text'].str.replace(r"\[[^\[\]]{2,10}\]", "", regex=True)
test_data['chat_text'] = test_data['chat_text'].str.replace("https?://\S+", "", regex=True)
对于一个人连续的对话我们可以哦将其合并成一个对话
python">def get_names_phones_and_emails(example):names = re.findall(r"(?:\n)?([\u4e00-\u9fa5]+\d+):", example["chat_text"])names += re.findall(r"@([\u4e00-\u9fa5]+)\s", example["chat_text"])emails = re.findall(r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}", example["chat_text"])# phones = re.findall(r"1[356789]\d{9}", example["chat_text"]) # 文本中的手机号并不是标准手机号phones = re.findall(r"\d{3}\s*\d{4}\s*\d{4}", example["chat_text"]) return pd.Series([set(names), set(phones), set(emails)], index=['names', 'phones', 'emails'])def merge_chat(example):for name in example['names']:example["chat_text"] = example["chat_text"].replace(f"\n{name}:", f"<|sep|>{name}:")chats = example["chat_text"].split("<|sep|>")last_name = "UNKNOWN"new_chats = []for chat in chats:if chat.startswith(last_name):chat = chat.strip("\n")chat = "".join(chat.split(":")[1:])new_chats[-1] += " " + chatelse:new_chats.append(chat)last_name = chat.split(":")[0]return pd.Series(["\n".join(new_chats), new_chats], index=["chats", "chat_list"])# 使用正则表达式获得'names', 'phones', 'emails'
train_data[['names', 'phones', 'emails']] = train_data.apply(get_names_phones_and_emails, axis=1)
test_data[['names', 'phones', 'emails']] = test_data.apply(get_names_phones_and_emails, axis=1)
# 分割聊天记录, 合并连续相同人的聊天
train_data[["chats", "chat_list"]] = train_data.apply(merge_chat, axis=1)
test_data[["chats", "chat_list"]] = test_data.apply(merge_chat, axis=1)
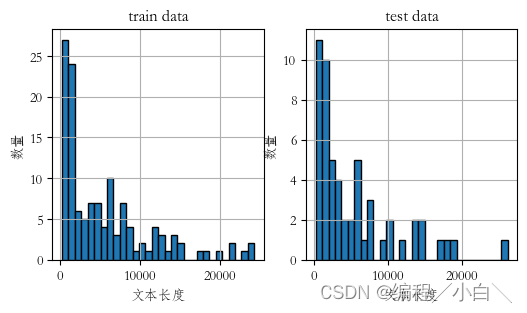
补充
补充:后面我们发现数据中chat_text中有许多是重复多编的,我们需要把重复的也给去除掉,这样处理后的数据就会大大减小,使用暴力匹配去除
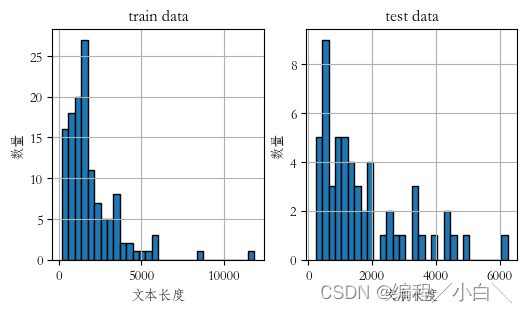
def process(excemple):chat_list = excemple["chat_text"].split("\n")res = []s = 0while s < len(chat_list):i, j = s, s+1start_j = jwhile i < len(chat_list) and j < len(chat_list):if chat_list[i] == chat_list[j]:i += 1else:if i != s:if j - start_j >10:res += list(range(start_j, j))i = sstart_j = jj += 1s += 1texts = []for i in range(len(chat_list)):if i not in res:texts.append(chat_list[i])return "\n".join(texts)train_data["chat_text"] = train_data.apply(process, axis = 1)
test_data["chat_text"] = test_data.apply(process, axis = 1)
构造训练集
处理之后其实有些还是很长,我们可以有两种简单粗暴的方法
- 截断
- 分块
对于构造训练数据,我们使用了第一种截断的方法,但这两种方法都有一定的缺点
我们需要查看讯飞官方微调需要的训练集格式,这里我选择使用JSONL格式,并且其每一行是一个JSON字符串,格式为
{"input":"", "target":""}
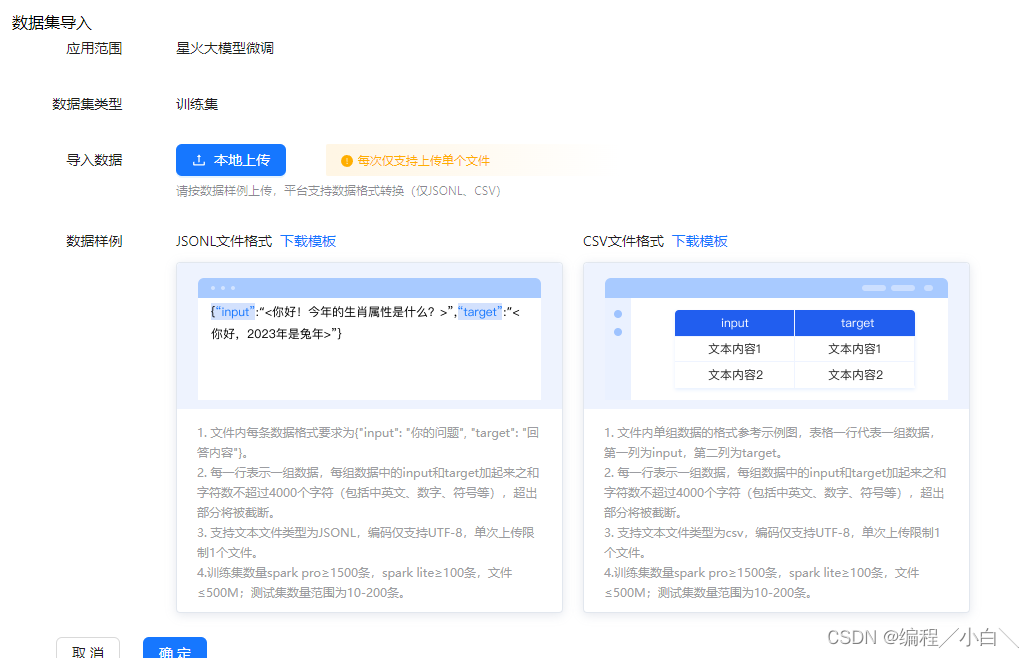
训练时我选用了讯飞的spark pro进行训练,其要求训练数据不少于1500条,每一个input+target长度不能大于8000
python">def process(x):# 提示词,我们交代清楚大模型的角色、目标、注意事项,然后提供背景信息,输出格式就可以了prompt = f"""Instruction:
你是一个信息要素提取工作人员,你需要从给定的`ChatText`中提取出**客户**的`Infos`中相关信息,将提取的信息填到`Infos`中,
注意事项:
1. 没有的信息无需填写
2. 保持`Infos`的JSON格式不变,没有的信息项也要保留!!!
4. 姓名可以是聊天昵称
5. 注意是客户的信息,不是客服的信息
6. 可以有多个客户信息
ChatText:
{x["chat_text"]}
"""# 要求的输出格式infos = """"
Infos:
infos": [{"基本信息-姓名": "","基本信息-手机号码": "","基本信息-邮箱": "","基本信息-地区": "","基本信息-详细地址": "","基本信息-性别": "","基本信息-年龄": "","基本信息-生日": "","咨询类型": [],"意向产品": [],"购买异议点": [],"客户预算-预算是否充足": "","客户预算-总体预算金额": "","客户预算-预算明细": "","竞品信息": "","客户是否有意向": "","客户是否有卡点": "","客户购买阶段": "","下一步跟进计划-参与人": [],"下一步跟进计划-时间点": "","下一步跟进计划-具体事项": ""
}]
"""# prompt+infos是文件中的input,answer是文件中的targetanswer = f"""{x["infos"]}""" #targettotal= len(prompt + infos + answer)if total > 8000:prompt = prompt[:8000-len(infos + answer)]return pd.Series([prompt, answer], index=["input", "target"])data = train_data.apply(process, axis=1)
# 测试集中的target并没有用可以忽略
data = test_data.apply(process, axis=1)#保存数据
with open(os.path.join(data_dir, "my_train.jsonl"), "w", encoding="utf-8") as f:f.write("\n".join([json.dumps(i, ensure_ascii=False) for i in list(data.transpose().to_dict().values())]))
f.close()
with open(os.path.join(data_dir, "my_test.jsonl"), "w", encoding="utf-8") as f:f.write("\n".join([json.dumps(i, ensure_ascii=False) for i in list(data.transpose().to_dict().values())]))
f.close()
对于训练数据不少于1500条的要求,我直接将训练集进行了多次复制,只要不少于1500条就可以训练。训练我只训练了两轮。
使用官方零代码微调
测试
模型训练好后我们需要到官网将训练好的模型发布,这样才能够调用
在我的服务中获取 接口地址、APPID 、APIKey、APISecret,不同版本会有不同
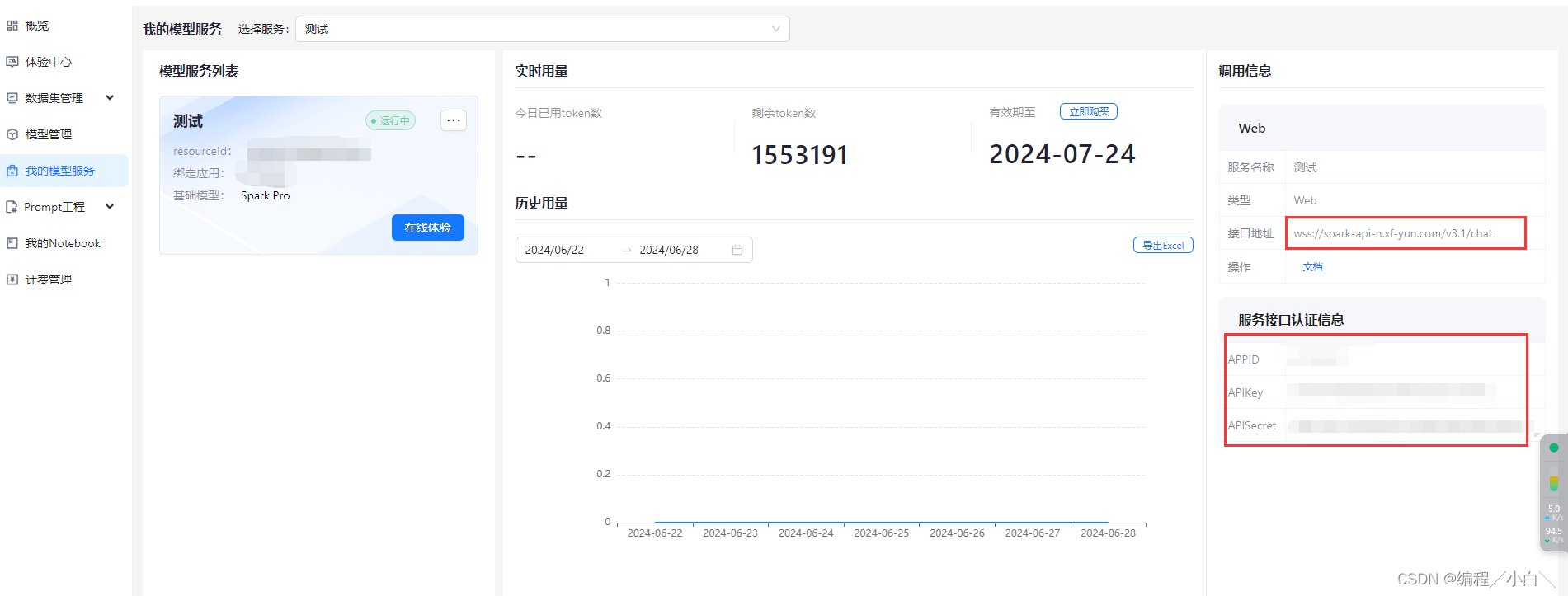
后续就可以写代码测试了,我们可以询问多轮然后进行投票,减少一次不确定性带来的误差,一轮其实已经可以达到26以上的分数了
python">from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
import pandas as pd
import os
from tqdm import tqdm
import jsonspark = ChatSparkLLM(spark_api_url="wss://spark-api-n.xf-yun.com/v3.1/chat",#spark pro微调的urlspark_app_id="",spark_api_key="",spark_api_secret="",spark_llm_domain="patchv3", #spark pro微调的版本streaming=False,
)
def save_result(data):with open("./data/result1.json", "w") as f:file = data.to_json(orient='records', index=False, force_ascii=False)f.write(file)f.close()
for j in range(0, 10):res = []for i in tqdm(range(len(data)), desc=f"正在询问第{j}轮"):messages = [ChatMessage(role="user",content=data.iloc[i]["input"])]while True:try:handler = ChunkPrintHandler()a = spark.generate([messages], callbacks=[handler])a = json.loads(a.generations[0][0].text.replace("'", "\""))except:print("出错了")continueres.append(a)breakmulti_res.append(res)test_data[f"infos_{j}"] = ressave_result(test_data)
多轮投票
python">from typing import Counter, defaultdicttemplate_infos = {"基本信息-姓名": "","基本信息-手机号码": "","基本信息-邮箱": "","基本信息-地区": "","基本信息-详细地址": "","基本信息-性别": "","基本信息-年龄": "","基本信息-生日": "","咨询类型": [],"意向产品": [],"购买异议点": [],"客户预算-预算是否充足": "","客户预算-总体预算金额": "","客户预算-预算明细": "","竞品信息": "","客户是否有意向": "","客户是否有卡点": "","客户购买阶段": "","下一步跟进计划-参与人": [],"下一步跟进计划-时间点": "","下一步跟进计划-具体事项": ""
}
result_Infos = []
## 这里的代码已经不是我最初始的代码了,可能会影响到效果,最初我是不管有结果个用户,只投出一个用户,其他信息也是直接全部投票,没有使用根据'基本信息-姓名'进行分开投票,可以自行尝试,投票还是可以提升一点分数的
for multi_infos in zip(*multi_res):names_info_dict = defaultdict(list)for infos in multi_infos:for info in infos:names_info_dict[info['基本信息-姓名']].append(info)res_infos = []for name in names_info_dict:l = len(names_info_dict[name])print(l)if l < 5:continueinfos = template_infos.copy()for attr in template_infos:if isinstance(template_infos[attr], str):val_freq = Counter([multi_info.get(attr, "") for multi_info in names_info_dict[name]])top_2 = val_freq.most_common(2)if len(top_2) == 1:val = top_2[0][0]else:if top_2[0][0] == "" and top_2[1][1] < l/2:val = ""elif top_2[0][0] == "":val = top_2[1][0]else:val = top_2[0][0] else:val_freq = []for multi_info in names_info_dict[name]:val_freq.extend((multi_info.get(attr, [])))val_freq = Counter(val_freq)val =[val for val, freq in val_freq.most_common(10) if freq > l/2]infos[attr] = valres_infos.append(infos)# if len(res_infos) >= 2:# print(len(names_info_dict[name]),res_infos)result_Infos.append(res_infos)
test_data["infos"] = result_Infos
save_result(test_data[["chat_text", "infos"]])
总结
以上只是一个简洁的思路,如果有其他想法欢迎在评论区留言。