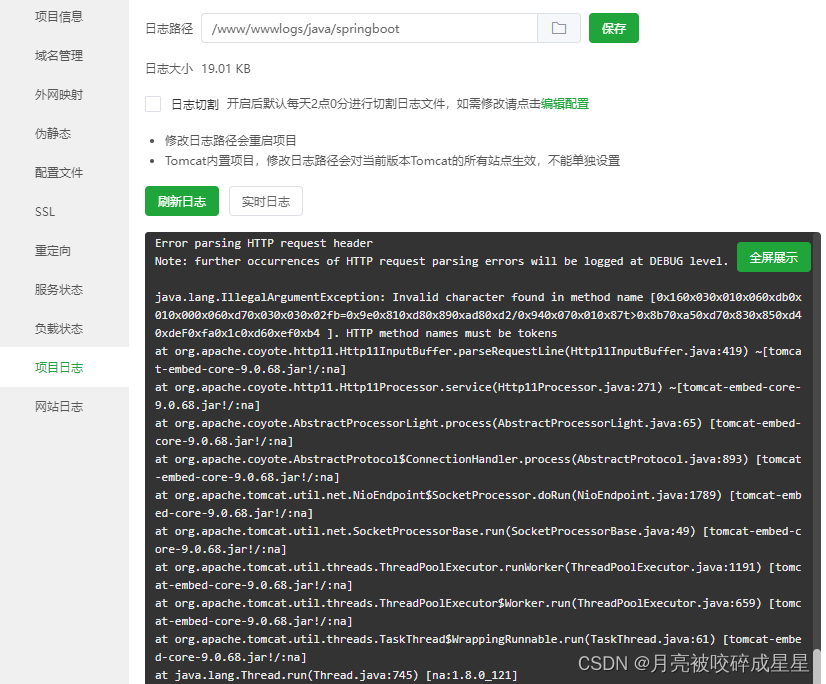
丢包的另一个思路,内核里有些counter的计数,记录的不准确。这个时候怎么办?就需要使用另外一个方式:/sys/kernel/debug/tracing/event/skb/kfree_skb 的跟踪功能。这个算是对counter的一个补充,可以拿来做统计分析使用。
然后收集trace文件里的内容。再根据里面的内容,来统计丢失的原因,然后根据代码去看为什么。
比如下面一个就可以看到主要的丢包原因是qdisc丢了。
#cat /root/mark.trace | awk -F’:’ ‘{print $4}’ | sort | uniq -c | more
18509 NOT_SPECIFIED
904 NO_SOCKET
123714 QDISC_DROP
632 TCP_INVALID_SEQUENCE
63 TCP_OLD_DATA
然后再根据tc qdisc的命令,查看具体的丢包原因,是因为:overlimit,超过了limit的限制。这个时候就可以尝试通过修改limit来解决问题。这里主要的问题是一个网络burst的问题。
#tc -s -d qdisc show
qdisc noqueue 0: dev lo root refcnt 2
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc fq_codel 0: dev int0 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
Sent 12347100936 bytes 18084492 pkt (dropped 127799, overlimits 0 requeues 3)
backlog 0b 0p requeues 3
maxpacket 30107 drop_overlimit 123714 new_flow_count 348529 ecn_mark 0
new_flows_len 0 old_flows_len 0