系列文章目录
- 1- Spark词频统计案例加强-hdfs读写(掌握)
- 2- Spark on Yarn 环境—验证案例(操作)
- 3- spark-submit命令(了解)
- 4- PySpark程序与Spark交互流程(掌握)
- 5- 常见面试题(掌握)
文章目录
- 系列文章目录
- 前言
- 一、1- Spark词频统计案例加强-hdfs读写(掌握)
- 1、读写HDFS
- 代码详解:
- 2、链式编程实现
- 代码详解:
- 3、对结果排序
- 代码详细实现:
- 4、案例相关算子小结
- 5、PySpark的异常排查流程
- 6、代码模板设置
- 二、Spark On Yarn环境配置(操作)
- 1、Spark On Yarn的本质
- 2、环境启动相关指令
- 2.1启动sparkonyarn
- 3、提交应用验证环境(掌握)
- 4、如何查看日志
- 5、Spark On Yarn两种部署方式(掌握)
- 三、spark-submit命令(了解)
- 四、PySpark程序与Spark交互流程(掌握)
- 1、client_Spark集群
- 2、cluster_Spark集群
- 3、client on Yarn集群
- 4、cluster on Yarn集群
- 五、常见面试题
前言
本文主要介绍了,
一:
1.spark读写hdfs案例
2.spark链式编程
3.spark排序案例
二:环境验证
验证spark on yarn 环境
三:pyspark程序与spark交互流程
四:整理面试题
1.请列举常见的RDD算子,以及对应功能
2.请列举常见的spark_submit参数,以及对应功能
3.请表述下spark中核心概念
4.请表述下cluster on yarn集群的执行流程
一、1- Spark词频统计案例加强-hdfs读写(掌握)
1、读写HDFS
1- 启动Hadoop集群
start-all.sh2- 验证Hadoop集群是否运行正常
jps访问
http://node1:9870
http://node1:80883- 上传文件到HDFS
准备一个content.txt文件,内容如下
hello hello spark
hello heima spark接着将content.txt文件上传到hdfs
hdfs dfs -mkdir /input
hdfs dfs -put content.txt /input/4- 基于原生入门案例,修改文件路径为 hdfs://node1:8020/...
代码详解:
# 导包
import os
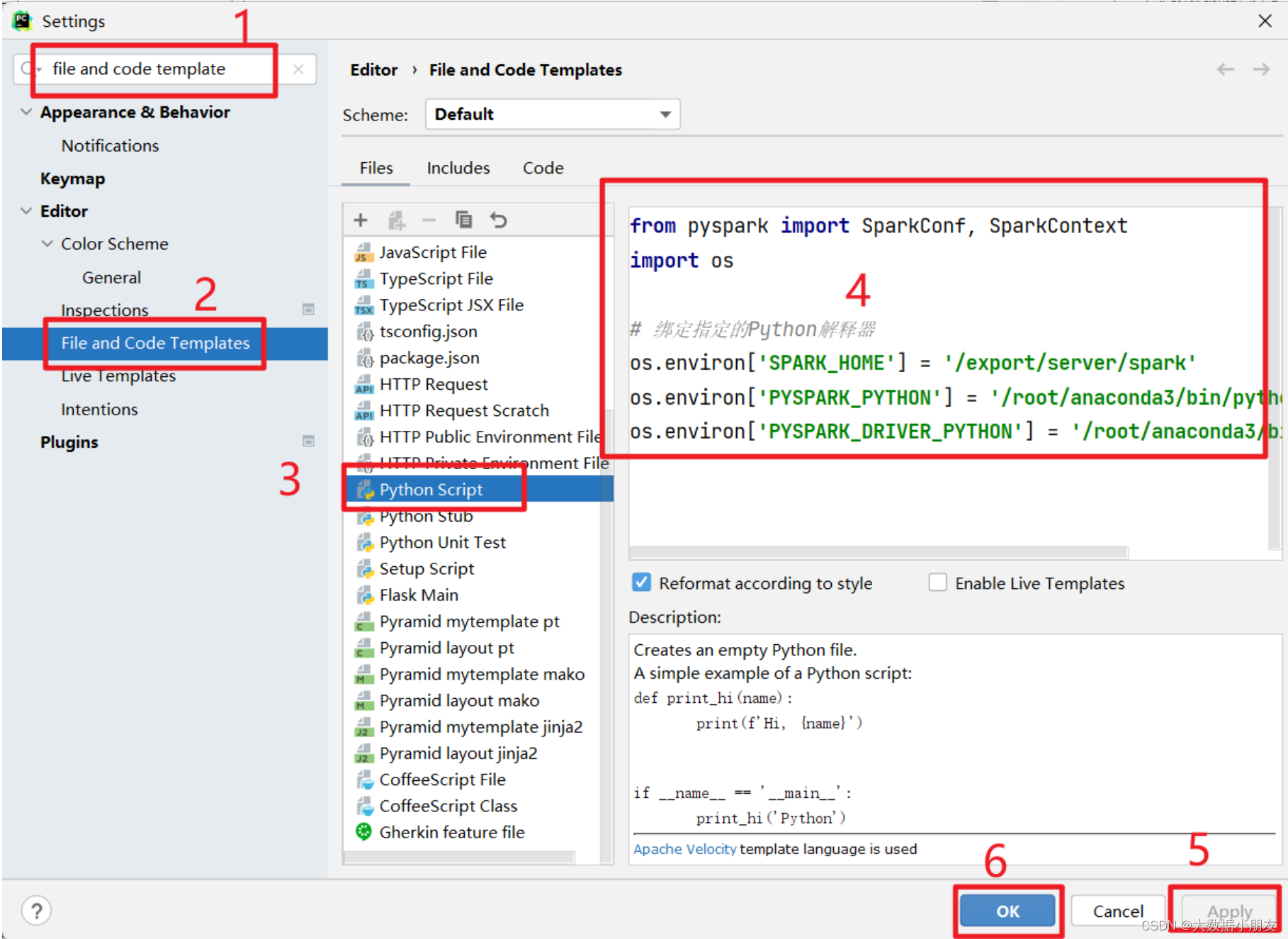
import timefrom pyspark import SparkConf, SparkContext# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':print("Spark加强案例: 从hdfs中读取文件进行WordCount词频统计开始~")# - 1.创建SparkContext对象conf = SparkConf().setAppName('my_pyspark_demo').setMaster('local[*]')sc = SparkContext(conf=conf)print(sc) # 默认<SparkContext master=local[*] appName=pyspark-shell># - 2.数据输入# 注意: 默认是linux本地路径省略了file:/// 如果是hdfs路径必须加hdfs://node1:8020/# 注意: 需要修改为hdfs路径init_rdd = sc.textFile('hdfs://node1:8020/input/content.txt')# - 3.数据处理# - 3.1文本内容切分flatmap_rdd = init_rdd.flatMap(lambda line: line.split(' '))# - 3.2数据格式转换map_rdd = flatmap_rdd.map(lambda word: (word, 1))# - 3.3分组和聚合reduce_rdd = map_rdd.reduceByKey(lambda agg, curr: agg + curr)# - 4.数据输出# 注意: 此时结果也需要利用算子存储到hdfs中reduce_rdd.saveAsTextFile('hdfs://node1:8020/day02_output')# - 5.释放资源time.sleep(100)sc.stop()print("Spark加强案例: WordCount词频统计结果已经保存到hdfs,程序结束~")
可能报的错误:

原因: 输出路径已经存在
解决: 直接删除已经存在的路径即可该错误需要查看Hadoop的源代码(131行):https://gitee.com/highmoutain/hadoop/blob/trunk/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-core/src/main/java/org/apache/hadoop/mapred/FileOutputFormat.java
2、链式编程实现
链式编程: 就是一种代码简洁的写法。省略中间变量的声明,调用完一个算子后,继续调用其他算子
使用场景:当功能需求比较简单(代码比较少)的时候,推荐使用链式编程,可以让你的代码看起来更加简洁。
另外,算子返回值类型都是相同的时候才能够使用
代码详解:
# 导包
import osfrom pyspark import SparkConf, SparkContext# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':print("Spark加强案例: 从hdfs中读取文件进行WordCount词频统计开始~")# - 1.创建SparkContext对象conf = SparkConf().setAppName('my_pyspark_demo').setMaster('local[*]')sc = SparkContext(conf=conf)print(sc) # 默认<SparkContext master=local[*] appName=pyspark-shell># - 2.数据输入_处理_输出result = sc.textFile('hdfs://node1:8020/input/content.txt') \.flatMap(lambda line: line.split(' ')) \.map(lambda word: (word, 1)) \.reduceByKey(lambda agg, curr: agg + curr)print(result.collect())# - 3.释放资源sc.stop()print("Spark加强案例:程序结束~")
3、对结果排序
sortBy(参数1,参数2):参数1: 自定义函数,通过函数指定按照谁来进行排序操作参数2: (可选)boolean类型,表示是否为升序。默认为True,表示升序sortByKey(参数1):参数1: 可选的,boolean类型,表示是否为升序。默认为True 表示升序top(N,函数):参数N: 取RDD的前N个元素参数函数:(可选)如果kv(键值对)类型,默认是根据key进行排序操作,如果想根据其他排序,可以定义函数指定
代码详细实现:
# 导包
from pyspark import SparkContext
import os# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# - 1.创建SparkContext对象sc = SparkContext() # 默认master=local[*],默认appname=pyspark-shellprint(sc)# - 2.数据输入# - 3.数据处理reduceRDD = sc.textFile('file:///export/data/spark_project/spark_base/content.txt') \.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.reduceByKey(lambda agg, curr: agg + curr)# - 4.数据输出# 排序操作# ①sortBy 默认升序s1 = reduceRDD.sortBy(lambda tup: tup[1], False)print(s1.collect())# ②sortByKey 默认升序 (key,value)s2 = reduceRDD.sortByKey(False) print(s2.collect())# 思考: sortByKey 能不能根据value值降序排序s2 = reduceRDD.map(lambda tup:(tup[1],tup[0])).sortByKey(False).map(lambda tup:(tup[1],tup[0]))print(s2.collect())# ③top 默认降序s3 = reduceRDD.top(4, lambda tup: tup[1])print(s3)# 思考: top能不能拿最小n个value值# 排序规则可以利用负数概念,-1>-2>-3,注意:不能修改数据本身s4 = reduceRDD.top(4, lambda tup: -tup[1])print(s4)# - 5.释放资源sc.stop()
4、案例相关算子小结
读取文件: textFile(path): 读取外部数据源,支持本地文件系统和HDFS文件系统将结果数据输出文件上: saveAsTextFile(path): 将数据输出到外部存储系统,支持本地文件系统和HDFS文件系统文件路径协议: 本地: file:///路径hdfs: hdfs://node1:8020/路径排序相关的API: sortBy(参数1,参数2):参数1: 自定义函数,通过函数指定按照谁来进行排序操作参数2: 可选的,boolean类型,表示是否为升序。默认为True,表示升序sortByKey(参数1):参数1: 可选的,boolean类型,表示是否为升序。默认为True 表示升序top(N,函数):参数N: 取RDD的前N个元素参数函数: 可选的。如果kv(键值对)类型,默认是根据key进行排序操作,如果想根据其他排序,可以定义函数指定相关其他API/算子: flatMap(函数): 根据指定的函数对元素进行转换操作,支持将一个元素转换为多个元素map(函数): 根据指定的函数对元素进行转换操作,支持一对一的转换操作,传入一个返回一个reduceByKey(函数): 根据key进行分组操作,将同一分组内的value数据合并为一个列表,然后执行传入的函数。函数传入的参数有两个,参数1表示的是局部聚合结果,默认值是列表中的第一个元素;参数2表示遍历的每一个列表中value值,默认从第二开始collect(): 收集,将程序中全部的结果数据收集回来,形成一个列表返回
百度统计中实际应用:
https://tongji.baidu.com/main/overview/demo/source/all?siteId=16847648
5、PySpark的异常排查流程
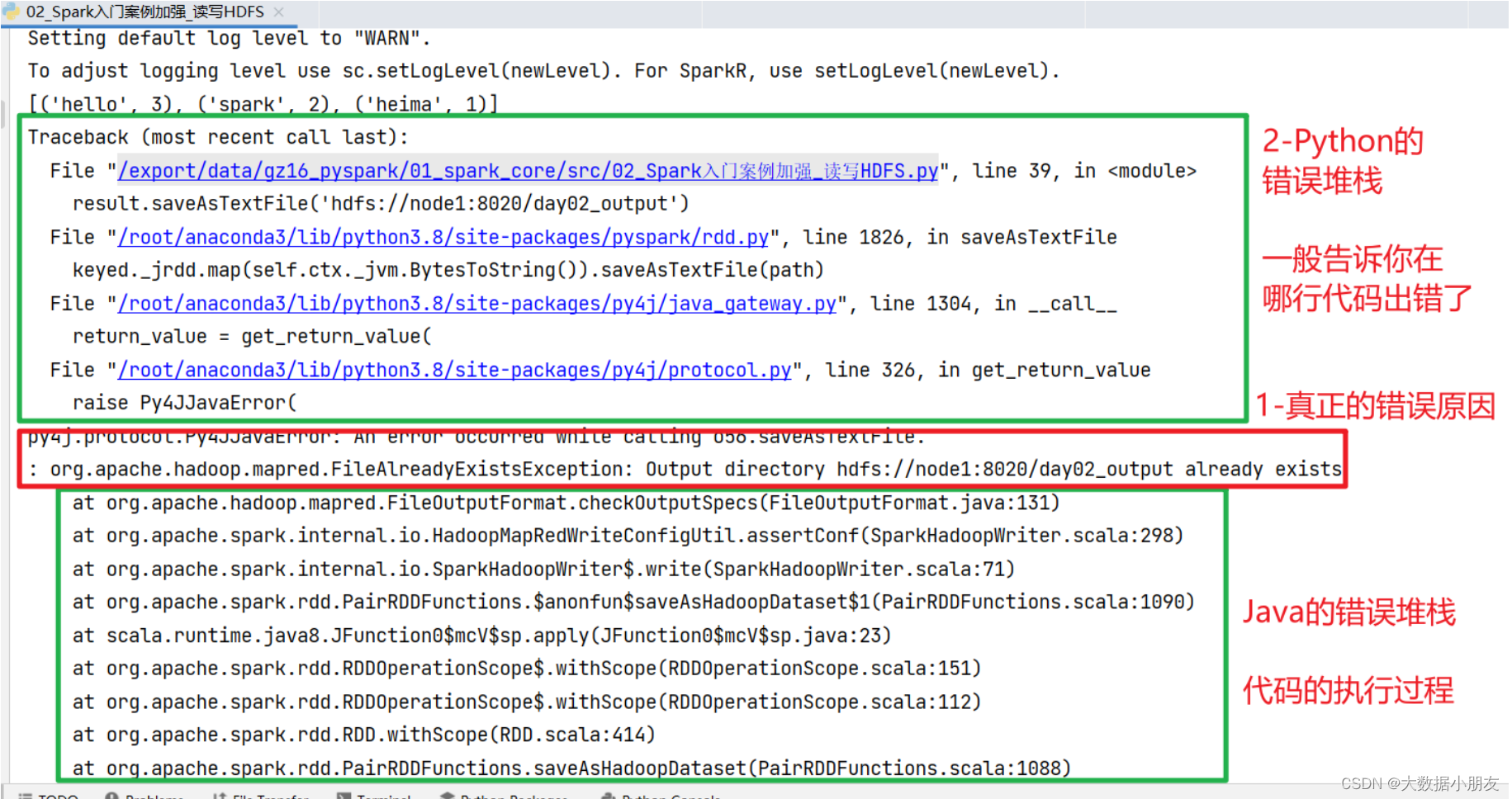
排错步骤:
1- 查看【真正的错误原因】,理解报错的含义
2- 查看【Python的错误堆栈】,找到具体报错的地方。再结合错误原因,进行分析,得到解决办法
6、代码模板设置

二、Spark On Yarn环境配置(操作)
1、Spark On Yarn的本质
Spark专注于分布式计算;Yarn专注于资源管理。
Spark将资源管理的工作交给了Yarn来负责!
2、环境启动相关指令
sparkonyarn_254">2.1启动sparkonyarn
注意:
配置完环境后需要先stop-all.sh停止,再重新启动服务生效
相比原理hadoop集群,需要多启动一个spark的自己的历史服务,它是依赖hadoop的历史服务的!

3、提交应用验证环境(掌握)
测试提交官方示例圆周率
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
${SPARK_HOME}/examples/src/main/python/pi.py \
10
测试提交自定义python类
将编写的WordCount的代码提交到Yarn平台运行* 注意1:需要修改setMaster的参数值为yarn,或者直接将setMaster代码删除
* 注意2:需要将代码中和文件路径相关的内容改成读写分布式文件系统,例如:HDFS。因为程序是分布式运行的,我们无法确保每台节点上面都有相同的本地文件路径,会导致报错。
cd /export/server/spark/bin./spark-submit --master yarn \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py# 注意:py代码文件路径改成自己的linux对应py文件路径!!!
4、如何查看日志
日志用途:主要用于排查问题
- 通过Spark提供的18080日志服务器查看, 推荐使用!

直接查看对应executor的日志

发现不管是进程还是线程,日志内容都很少。原因如下:
1- 因为在进行环境部署的时候将日志级别,由INFO变成了WARN级别
2- 和部署方式有关。
- 查看对应线程的日志
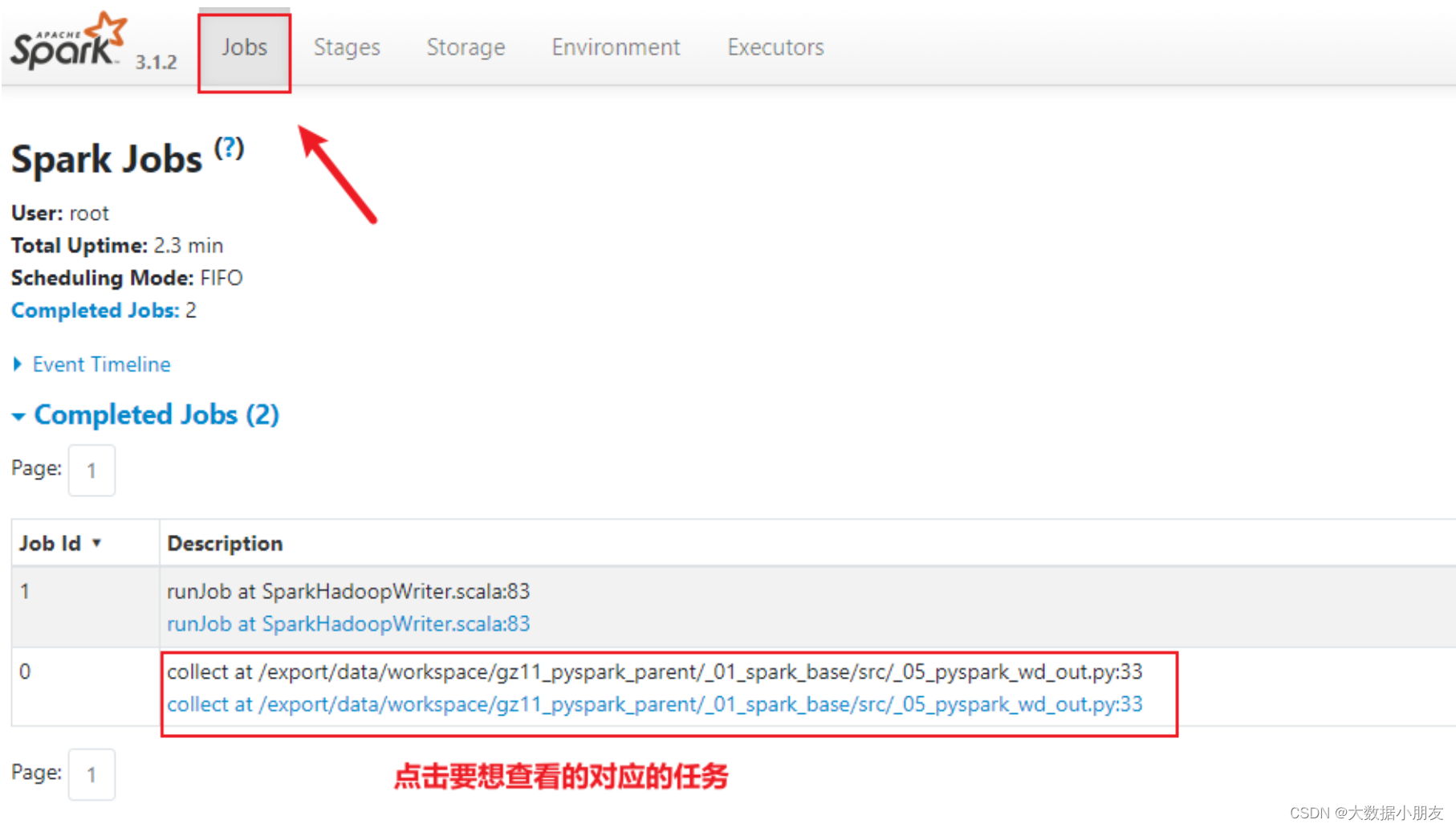
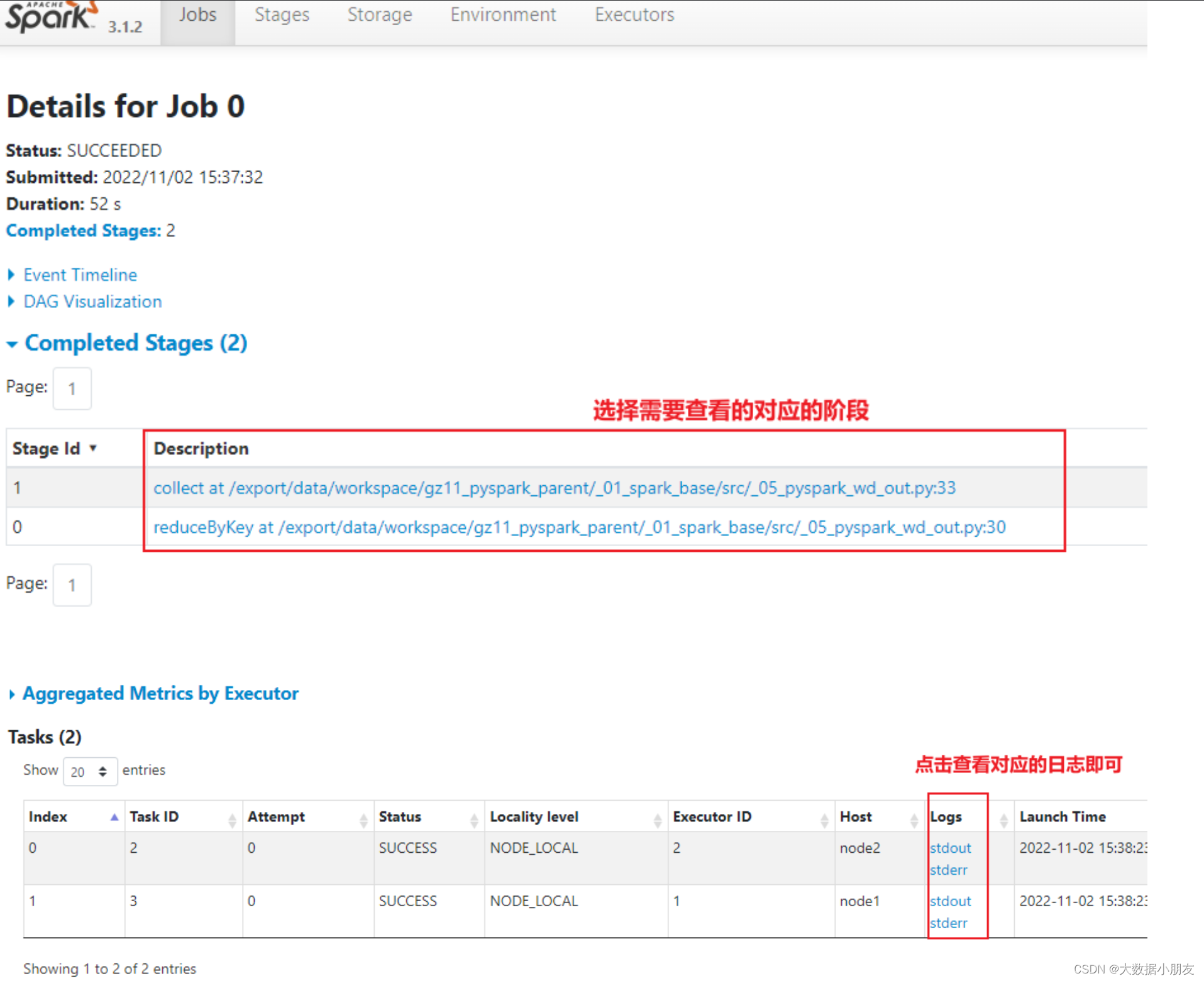
- 还可以通过Yarn的8088界面查看日志

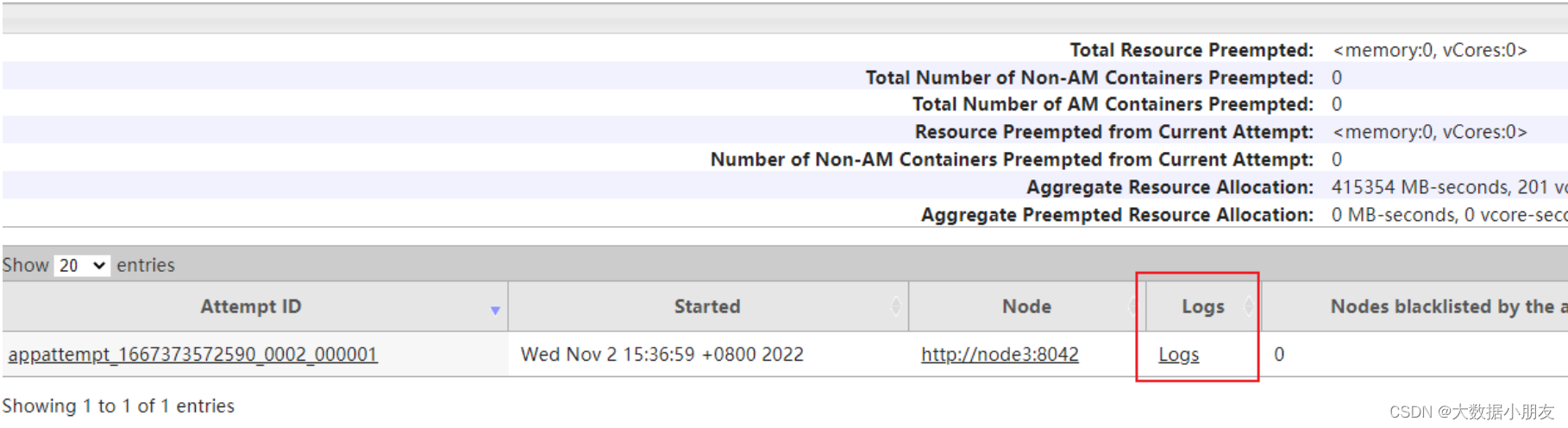
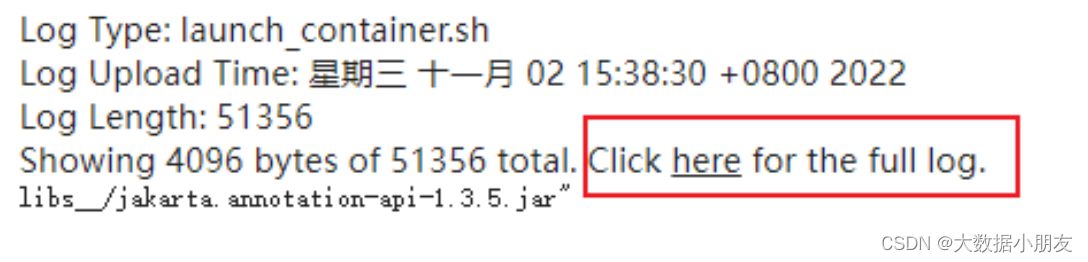
点进去后, 如果日志比较多, 也可以点击查看详细日志
5、Spark On Yarn两种部署方式(掌握)
Spark中有两种部署方式,Client和Cluster方式,默认是Client方式。这两种方式的本质区别,是Driver进程运行的地方不一样。
Client部署方式: Driver进程运行在你提交程序的那台机器上优点: 将运行结果和运行日志全部输出到了提交程序的机器上,方便查看结果缺点: Driver进程和Yarn集群可能不在同一个集群中,会导致Driver和Executor进程间进行数据交换的时候,效率比较低使用: 一般用在开发和测试中Cluster部署方式: Driver进程运行在集群中某个从节点上优点: Driver进程和Yarn集群在同一个集群中,Driver和Executor进程间进行数据交换的时候,效率比较高缺点: 需要去18080或者8088页面查看日志和运行结果使用: 一般用在生产环境使用
演示操作:
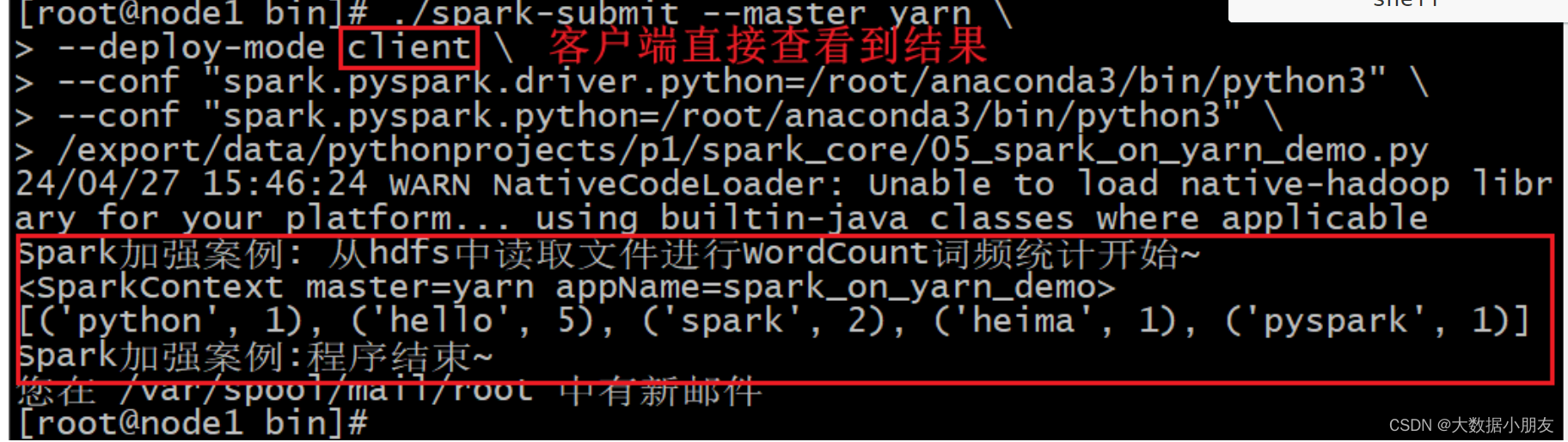
- client模式:
./spark-submit --master yarn \
--deploy-mode client \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py# 注意:py代码文件路径改成自己的linux对应py文件路径!!!

- cluster模式
./spark-submit --master yarn \
--deploy-mode cluster \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py# 注意:py代码文件路径改成自己的linux对应py文件路径!!!



观察两种模式结果区别?client模式: driver一直是node1(客户端) 运行输出结果在node1窗口直接输出cluter模式: driver是集群节点中切换 运行输出结果在driver对应stdout日志展示出
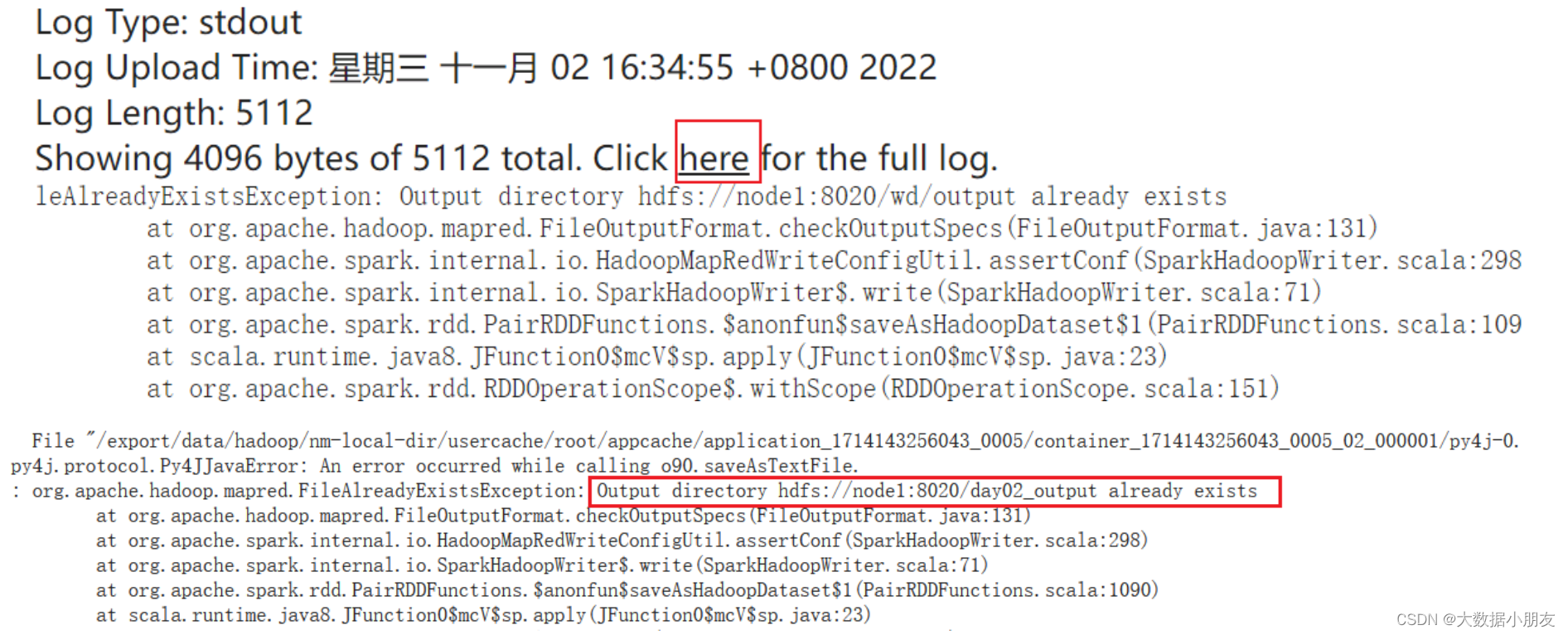
如果输出内容不是直接打印而是到hdfs,有可能报错,看日志可以从以下位置找:
sparksubmit_359">三、spark-submit命令(了解)
后续需要将自己编写的Spark程序提交到相关的资源平台上,比如说: local yarn spark集群(standalone)
Spark为了方便任务的提交操作,专门提供了一个用于进行任务提交的脚本文件: spark-submit
spark-submit在提交的过程中,设置非常多参数,调整任务相关信息。如果忘记了,可以使用spark-submit --help进行查看
- 基本参数设置

- Driver的资源配置参数

- executor的资源配置参数

示例 - 官方圆周率示例
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \--driver-memory 512m \
--executor-memory 512m \--executor-cores 1 \
--num-executors 2 \
--queue default \--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
${SPARK_HOME}/examples/src/main/python/pi.py \
10
四、PySpark程序与Spark交互流程(掌握)
1、client_Spark集群

- 举例说明:
- 集群交互图:
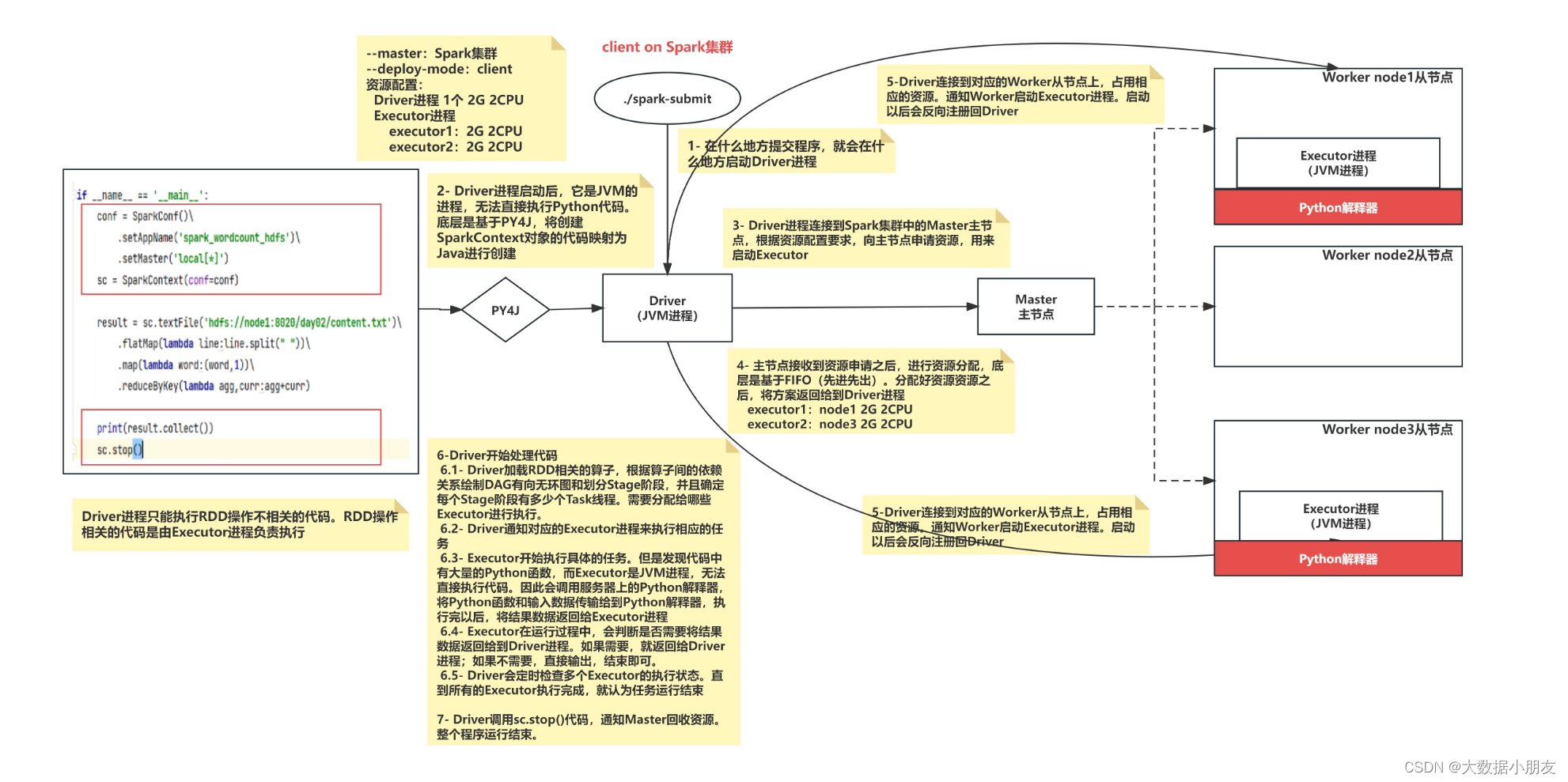
driver任务: Driver进程中负责资源申请的工作并且负责创建SparkContext对象的代码映射为Java对象,进行创建任务的分配、任务的管理工作。1- submit提交任务到主节点Master2- 在提交任务的那个客户端上启动Driver进程3- Driver进程启动后,执行main函数,首先创建SparkContext对象。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建4- Driver进程连接到Spark集群中的Master主节点,根据资源配置要求,向主节点申请资源,用来启动Executor5- 主节点接收到资源申请之后,进行资源分配,底层是基于FIFO(先进先出)。分配好资源资源之后,将方案返回给到Driver进程executor1:node1 2G 2CPUexecutor2:node3 2G 2CPU6-Driver连接到对应的Worker从节点上,占用相应的资源。通知Worker启动Executor进程。启动以后会反向注册回Driver7-Driver开始处理代码7.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。7.2- Driver通知对应的Executor进程来执行相应的任务7.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程7.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。7.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束8- Driver调用sc.stop()代码,通知Master回收资源。整个程序运行结束。
2、cluster_Spark集群

driver任务: Driver进程中负责资源申请的工作并且负责创建SparkContext对象的代码映射为Java对象,进行创建任务的分配、任务的管理工作。和client on spark集群的区别点: Driver进程不是运行在提交任务的那台机器上了,而是在Spark集群中随机选择一个Worker从节点来启动和运行Driver进程1- submit提交任务到主节点Master2- Master主节点接收到任务信息以后,根据Driver的资源配置要求,在集群中随机选择(在资源充沛的众多从节点中随机选择)一个Worker从节点来启动和运行Driver进程3- Driver进程启动以后,执行main函数,首先创建SparkContext对象。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建4- Driver进程连接到Spark集群中的Master主节点,根据资源配置要求,向主节点申请资源,用来启动Executor5- 主节点接收到资源申请之后,进行资源分配,底层是基于FIFO(先进先出)。分配好资源资源之后,将方案返回给到Driver进程executor1:node1 2G 2CPUexecutor2:node3 2G 2CPU6-Driver连接到对应的Worker从节点上,占用相应的资源。通知Worker启动Executor进程。启动以后会反向注册回Driver7-Driver开始处理代码7.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。7.2- Driver通知对应的Executor进程来执行相应的任务7.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程7.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。7.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束8- Driver调用sc.stop()代码,通知Master回收资源。整个程序运行结束。
3、client on Yarn集群
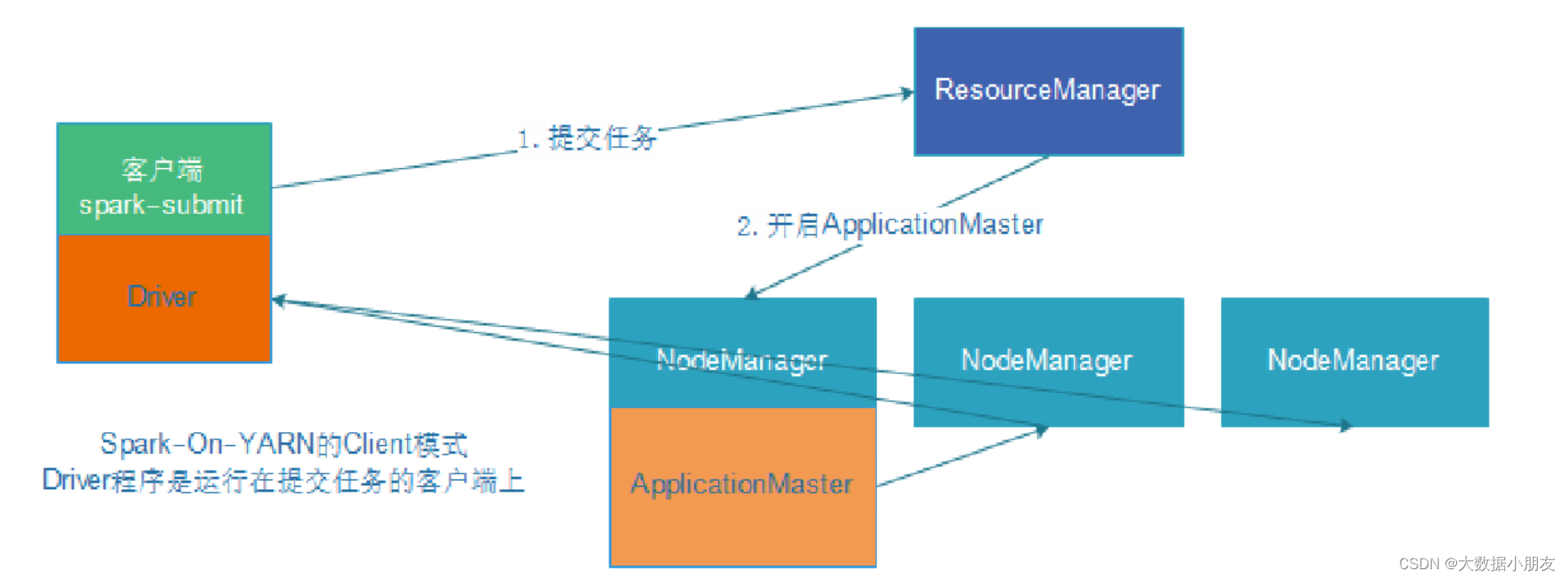
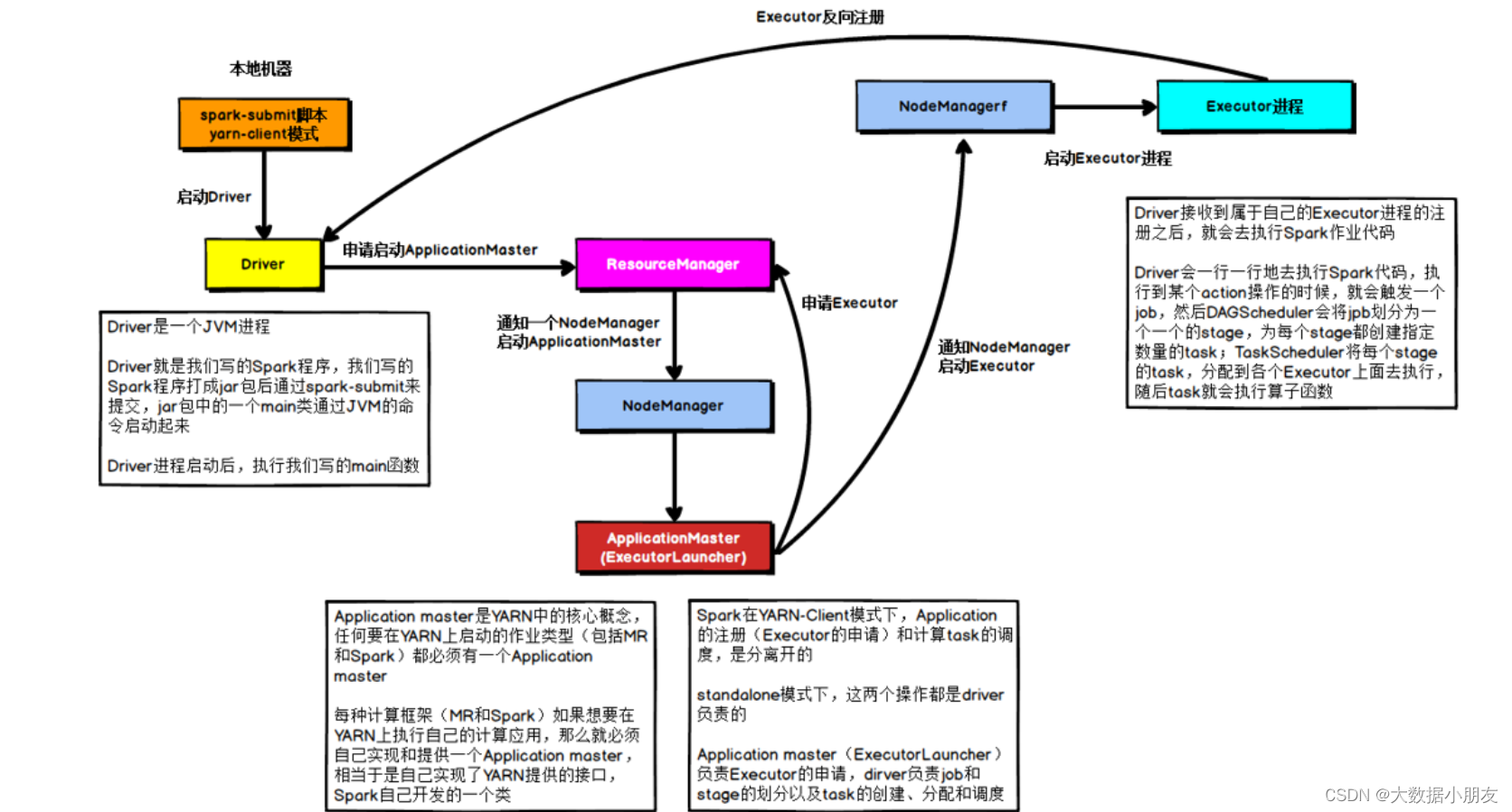
区别点: 将Driver进程中负责资源申请的工作,转交给到Yarn的ApplicationMaster来负责。Driver负责创建SparkContext对象的代码映射为Java对象,进行创建任务的分配、任务的管理工作。1- 首先会在提交的节点启动一个Driver进程2- Driver进程启动以后,执行main函数,首先创建SparkContext对象。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建3- 连接Yarn集群的主节点(ResourceManager),将需要申请的资源封装为一个任务,提交给到Yarn的主节点。主节点收到任务以后,首先随机选择一个从节点(NodeManager)启动ApplicationMaster4- 当ApplicationMaster启动之后,会和Yarn的主节点建立心跳机制,告知已经启动成功。启动成功以后,就进行资源的申请工作,将需要申请的资源通过心跳包的形式发送给到主节点。主节点接收到资源申请后,开始进行资源分配工作,底层是基于资源调度器来实现(默认为Capacity容量调度器)。当主节点将资源分配完成以后,等待ApplicationMaster来拉取资源。ApplicationMaster会定时的通过心跳的方式询问主节点是否已经准备好了资源。一旦发现准备好了,就会立即拉取对应的资源信息。5- ApplicationMaster根据拉取到的资源信息,连接到对应的从节点。占用相应的资源,通知从节点启动Executor进程。从节点启动完Executor之后,会反向注册回Driver进程6-Driver开始处理代码6.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。6.2- Driver通知对应的Executor进程来执行相应的任务6.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程6.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。6.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束。同时ApplicationMaster也会接收到各个节点的执行完成状态,然后通知主节点。任务执行完成了,主节点回收资源,关闭ApplicationMaster,并且通知Driver。7- Driver执行sc.stop()代码。Driver进程退出
4、cluster on Yarn集群

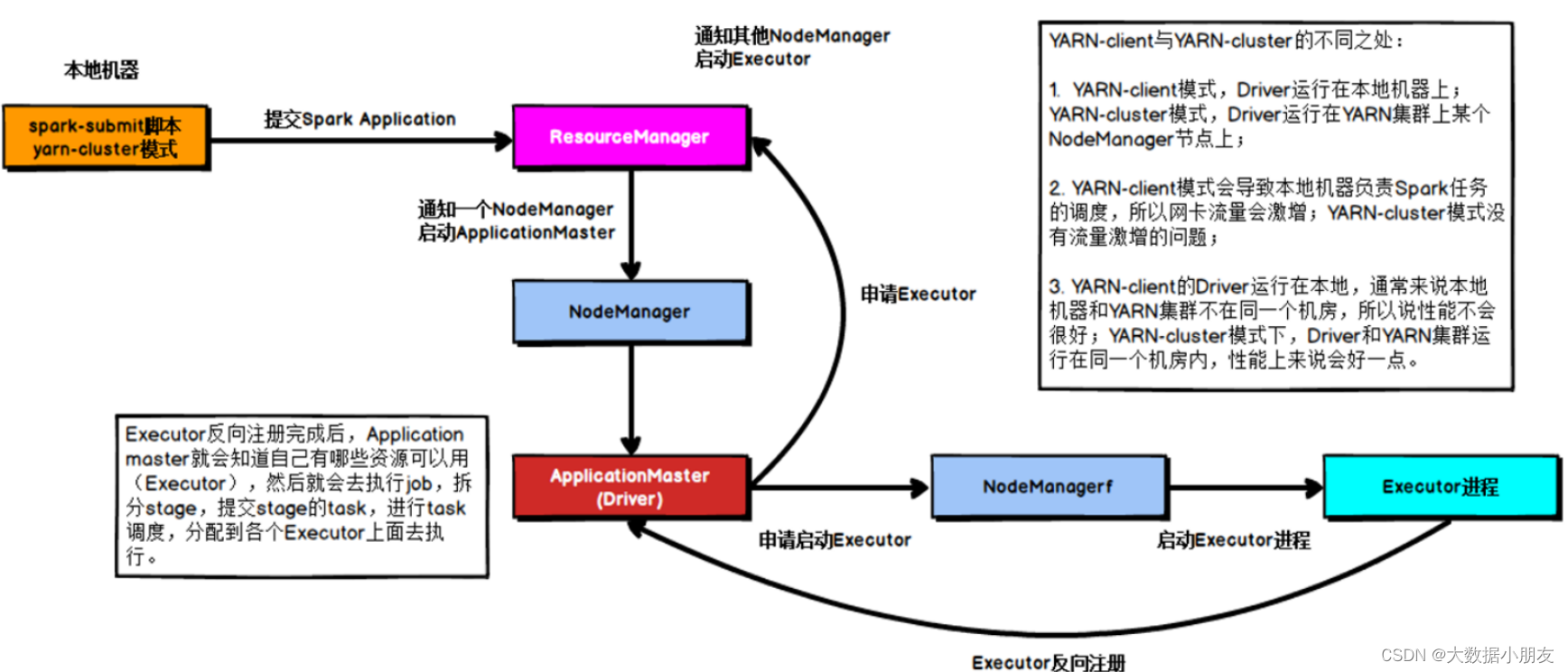
区别点: 在集群模式下,Driver进程的功能和ApplicationMaster的功能(角色)合二为一了。Driver就是ApplicationMaster,ApplicationMaster就是Driver。既要负责资源申请,又要负责任务的分配和管理。1- 首先会将任务提交给Yarn集群的主节点(ResourceManager)2- ResourceManager接收到任务信息后,根据Driver(ApplicationMaster)的资源配置信息要求,选择一个
nodeManager节点(有资源的,如果都有随机)来启动Driver(ApplicationMaster)程序,并且占用相对应资源3- Driver(ApplicationMaster)启动后,执行main函数。首先创建SparkContext对象(底层是基于PY4J,识
别python的构建方式,将其映射为Java代码)。创建成功后,会向ResourceManager进行建立心跳机制,告知已经
启动成功了4- 根据executor的资源配置要求,向ResourceManager通过心跳的方式申请资源,用于启动executor(提交的任
务的时候,可以自定义资源信息)5- ResourceManager接收到资源申请后,根据申请要求,进行分配资源。底层是基于资源调度器来资源分配(默认
为Capacity容量调度)。然后将分配好的资源准备好,等待Driver(ApplicationMaster)拉取操作executor1: node1 2个CPU 2GB内存executor2: node3 2个CPU 2GB内存6- Driver(ApplicationMaster)会定时询问是否准备好资源,一旦准备好,立即获取。根据资源信息连接对应的
节点,通知nodeManager启动executor,并占用相应资源。nodeManager对应的executor启动完成后,反向注册
回给Driver(ApplicationMaster)程序(已经启动完成)7- Driver(ApplicationMaster)开始处理代码:7.1 首先会加载所有的RDD相关的API(算子),基于算子之间的依赖关系,形成DAG执行流程图,划分stage阶
段,并且确定每个阶段应该运行多少个线程以及每个线程应该交给哪个executor来运行(任务分配)7.2 Driver(ApplicationMaster)程序通知对应的executor程序, 来执行具体的任务7.3 Executor接收到任务信息后, 启动线程, 开始执行处理即可: executor在执行的时候, 由于RDD代
码中有大量的Python的函数,Executor是一个JVM程序 ,无法解析Python函数, 此时会调用Python解析器,执
行函数, 并将函数结果返回给Executor7.4 Executor在运行过程中,如果发现最终的结果需要返回给Driver(ApplicationMaster),直接返回
Driver(ApplicationMaster),如果不需要返回,直接输出 结束即可7.5 Driver(ApplicationMaster)程序监听这个executor执行的状态信息,当Executor都执行完成后,
Driver(ApplicationMaster)认为任务运行完成了8- 当任务执行完成后,Driver执行sc.stop()通知ResourceManager执行完成,ResourceManager回收资源,
Dri8ver程序退出即可
五、常见面试题
1.请列举常见的RDD算子,以及对应功能
读取文件: textFile(path): 读取外部数据源,支持本地文件系统和HDFS文件系统将结果数据输出文件上: saveAsTextFile(path): 将数据输出到外部存储系统,支持本地文件系统和HDFS文件系统文件路径协议: 本地: file:///路径hdfs: hdfs://node1:8020/路径排序相关的API: sortBy(参数1,参数2):参数1: 自定义函数,通过函数指定按照谁来进行排序操作参数2: 可选的,boolean类型,表示是否为升序。默认为True,表示升序sortByKey(参数1):参数1: 可选的,boolean类型,表示是否为升序。默认为True 表示升序top(N,函数):参数N: 取RDD的前N个元素参数函数: 可选的。如果kv(键值对)类型,默认是根据key进行排序操作,如果想根据其他排序,可以定义函数指定相关其他API/算子: flatMap(函数): 根据指定的函数对元素进行转换操作,支持将一个元素转换为多个元素map(函数): 根据指定的函数对元素进行转换操作,支持一对一的转换操作,传入一个返回一个reduceByKey(函数): 根据key进行分组操作,将同一分组内的value数据合并为一个列表,然后执行传入的函数。函数传入的参数有两个,参数1表示的是局部聚合结果,默认值是列表中的第一个元素;参数2表示遍历的每一个列表中value值,默认从第二开始collect(): 收集,将程序中全部的结果数据收集回来,形成一个列表返回
spark_submit_558">2.请列举常见的spark_submit参数,以及对应功能
基本参数设置:

Driver的资源配置参数:

executor的资源配置参数:
*
spark_566">3.请表述下spark中核心概念
在Spark中,核心概念主要包括以下几个方面:
- 1.Spark概述:
Spark是一个快速、通用、可扩展的大数据分析引擎,最初由加州大学伯克利分校AMPLab开发,并于2010年开源。
它集成了离线计算、实时计算、SQL查询、机器学习、图计算等多种功能,为大数据分析提供了一个统一的计算框架。
RDD(Resilient Distributed Datasets,弹性分布式数据集):
RDD是Spark的核心概念,它代表了一个不可变、可分区、里面元素可并行计算的集合。
RDD的特性包括:
弹性:数据可以根据内存情况选择在内存或磁盘中存储和计算。
分布式:RDD的数据被分为多个分区,每个分区分布在集群的不同节点上,以实现并行操作。
RDD是Spark计算的基本单元,通过转换(Transformation)和行动(Action)两种操作来构建和计算。 - 2.Spark核心组件:
Master & Worker:
Master负责资源的调度和分配,进行集群的监控。
Worker运行在集群中的一台服务器上,由Master分配资源进行数据的并行处理和计算。
Driver & Executor:
Driver是Spark的驱动器节点,负责执行Spark任务中的main方法,包括将用户程序转化为作业、在Executor之间调度任务、跟踪Executor的执行情况等。
Executor是集群工作节点(Worker)中的一个JVM进程,负责在Spark作业中运行具体的任务,并将结果返回给Driver。
SparkContext:控制整个应用程序的生命周期,包括DAGScheduler和TaskScheduler等组件。 - 3.Spark调度与执行:
DAGScheduler:负责将Spark作业分解成多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,并生成相应的Task set放到TaskScheduler中。
TaskScheduler:负责将DAGScheduler划分的任务(以Task的形式)交付给Executor执行。 - 4.Stage & Task:
一个Spark作业一般包含一到多个Stage,每个Stage由多个Task组成,通过多个Task并行执行来完成整个作业的计算。
综上所述,Spark的核心概念包括其作为一个集成多种计算功能的框架、弹性分布式数据集RDD、以及用于管理和执行计算任务的核心组件和调度机制。这些核心概念共同构成了Spark高效、可扩展的大数据分析能力的基础。
4.请表述下cluster on yarn集群的执行流程
参考本文第4章详细说明