节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集
Grok-1自开源以来,因作为高达314B参数的基础模型,且采用Rust+JAX框架构建,不适配transformers生态,导致使用其进行微调训练成本较高。
近期,Colossal-AI及时推出了解决方案,提供了更方便易用的 Python+PyTorch+HuggingFace Grok-1——grok-1-pytorch,目前模型已在HuggingFace、ModelScope上开源。
本文将分享在8卡环境下的微调grok-1-pytorch ,喜欢本文记得收藏、点赞、关注,技术交流欢迎加入我们讨论群
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要获取最新面试题、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流
环境准备
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[llm]
微调
实验环境
-
GPU:8*A100 80G
-
镜像:ModelScope官方镜像1.13.1版本
-
peft:0.10.0
数据集准备
Grok是base模型,因此我们使用了问题生成数据集DuReader作为训练集。该数据集约15000条,max-length设置为512,训练数据约10000条(平均长度305±92 tokens)。
模型准备
Grok模型我们使用了ColossalAI提供的版本,其中我们额外准备了符合transformers标准的tokenizer。
模型链接:
-
https://www.modelscope.cn/models/colossalai/grok-1-pytorch/summary
-
https://www.modelscope.cn/models/AI-ModelScope/grok-1-tokenizer/summary
训练
由于Grok模型过大,device_map和deepspeed zero3非offload均无法运行训练,因此本次实验我们使用了LoRA+deepspeed zero3 offload模式运行训练。训练完整脚本如下:
# cd examples/pytorch/llm first
nproc_per_node=8PYTHONPATH=../../.. \
torchrun \--nproc_per_node=$nproc_per_node \--master_port 29500 \llm_sft.py \--model_type grok-1 \--sft_type lora \--tuner_backend swift \--dtype bf16 \--output_dir output \--ddp_backend nccl \--dataset dureader-robust-zh \--train_dataset_sample -1 \--num_train_epochs 1 \--max_length 512 \--check_dataset_strategy warning \--lora_rank 8 \--lora_alpha 32 \--lora_dropout_p 0.05 \--lora_dtype bf16 \--lora_target_modules DEFAULT \--gradient_checkpointing true \--batch_size 2 \--weight_decay 0.1 \--learning_rate 1e-4 \--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \--max_grad_norm 0.5 \--warmup_ratio 0.03 \--eval_steps 100 \--save_steps 100 \--save_total_limit 2 \--logging_steps 10 \--deepspeed_config_path scripts/grok-1/lora_ddp_ds/zero3.json \--save_only_model true \
改脚本需要一个zero3.json文件,完整的训练文件可以在这里找到。
下面是训练过程的一些benchmark:

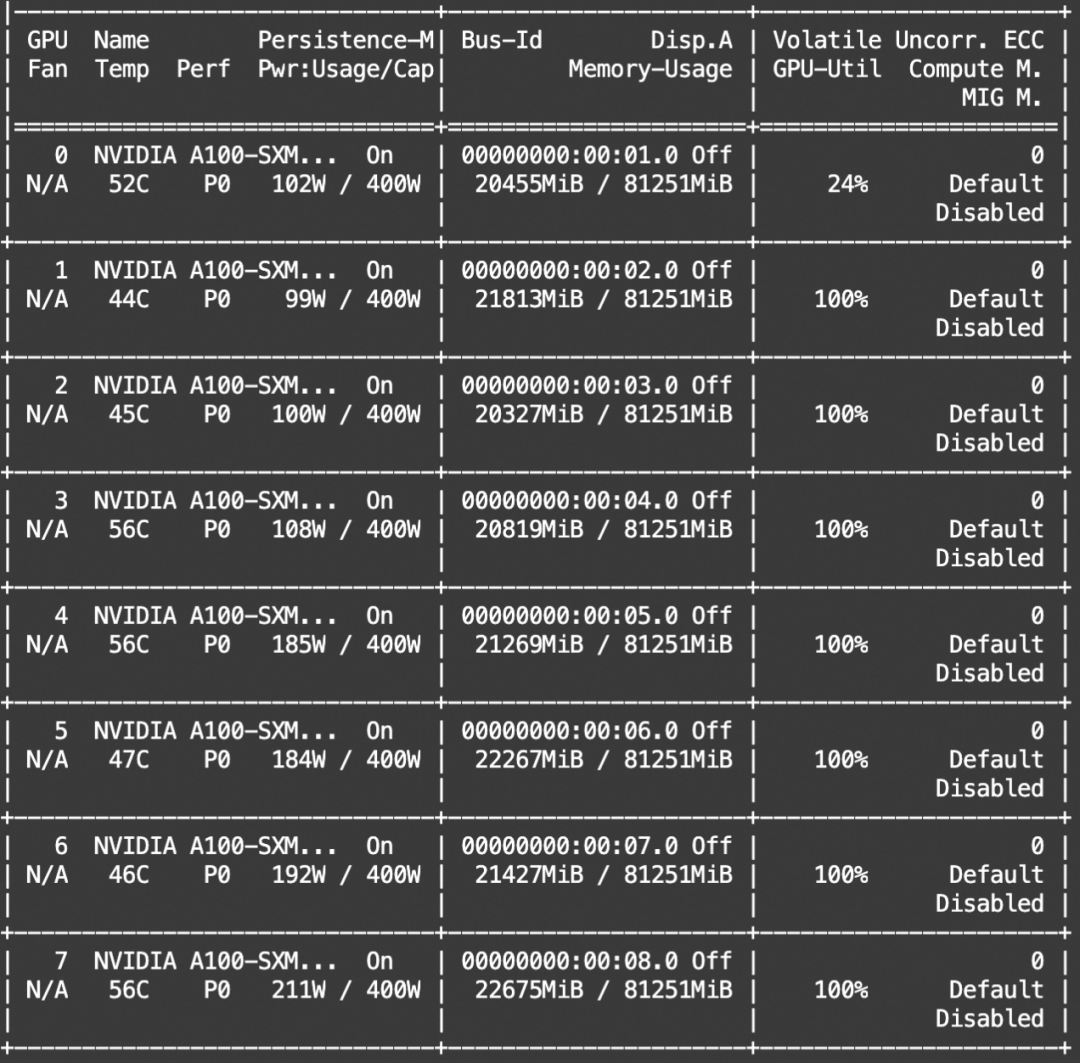
由于显存占用不到24G,理论上可以在RTX3090/A10环境中运行训练。
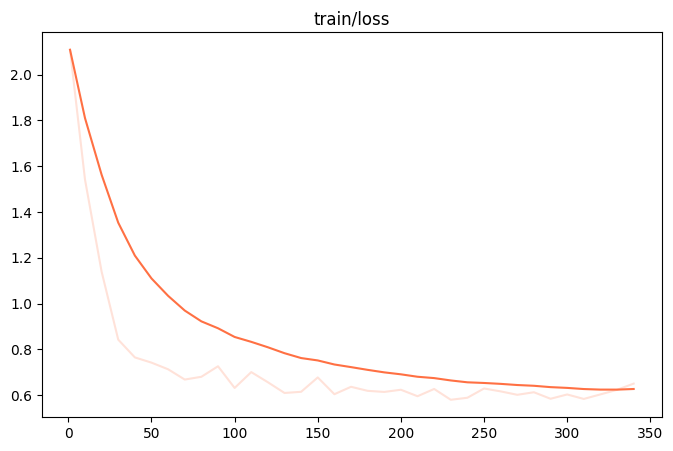
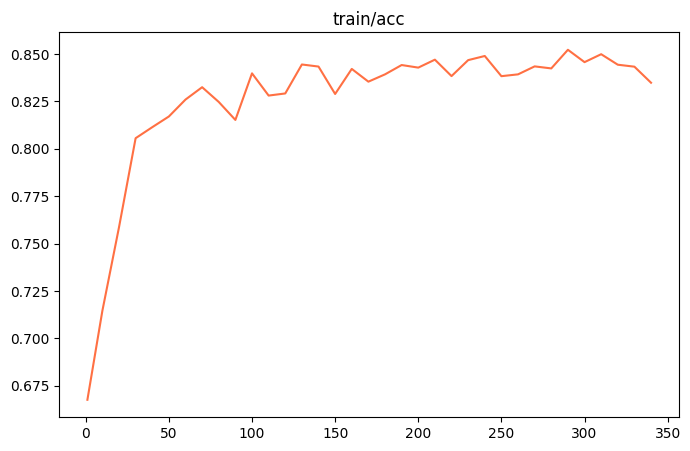
训练时长约4小时。
推理
SWIFT框架目前并不支持deepspeed推理,因此我们仍然使用transformers的device_map进行推理支持。但由于模型过大,因此部分layers会被offload到CPU上,并影响LoRA加载使推理出错,因此我们针对peft的实现进行了一定patch(原Linear在meta设备上时不迁移LoRA,并在运行时动态迁移weights)。
推理脚本如下:
# cd examples/pytorch/llm first
PYTHONPATH=../../.. \
python llm_infer.py \--ckpt_dir output/grok-1/vx-xxx-xxx/checkpoint-xxx \--dtype bf16 \--load_dataset_config true \--max_new_tokens 64 \--do_sample true \--dtype bf16 \--eval_human false \--merge_lora false \
推理结果:
[PROMPT]Task: Question Generation
Context: 我个人感觉是吕颂贤版,剧情和原著差别不大,虽然TVB演员颜值和风光没有大陆的好。但是香港特区人口和地域的限制,只能注重在演员的演技方面发挥很出色,楼主看过大陆排《笑傲江湖》吧!在台词上表现的很生硬没有香港的注重神色配台词,比如杜燕歌把吕颂贤表情和性格几乎和原著差别不大。武打几乎沿用徐克和程小东动作的风格很注重实际技巧,没有大陆版的在武打场面依靠电脑特效表现的太夸张了。李亚鹏版的武打动作和导演还是香港的元彬,大陆毕竟还是在武侠剧起步的比较晚,主要是还是靠明星大腕压阵而香港却是恰恰相反。
Answer: 吕颂贤版
Question:[OUTPUT]笑傲江湖哪个版本好看</s>[LABELS]笑傲江湖哪个版本好看
--------------------------------------------------
[PROMPT]Task: Question Generation
Context: 这位朋友你好,女性出现妊娠反应一般是从6-12周左右,也就是女性怀孕1个多月就会开始出现反应,第3个月的时候,妊辰反应基本结束。而大部分女性怀孕初期都会出现恶心、呕吐的感觉,这些症状都是因人而异的,除非恶心、呕吐的非常厉害,才需要就医,否则这些都是刚怀孕的的正常症状。1-3个月的时候可以观察一下自己的皮肤,一般女性怀孕初期可能会产生皮肤色素沉淀或是腹壁产生妊娠纹,特别是在怀孕的后期更加明显。还有很多女性怀孕初期会出现疲倦、嗜睡的情况。怀孕三个月的时候,膀胱会受到日益胀大的子宫的压迫,容量会变小,所以怀孕期间也会有尿频的现象出现。月经停止也是刚怀孕最容易出现的症状,只要是平时月经正常的女性,在性行为后超过正常经期两周,就有可能是怀孕了。如果你想判断自己是否怀孕,可以看看自己有没有这些反应。当然这也只是多数人的怀孕表现,也有部分女性怀孕表现并不完全是这样,如果你无法确定自己是否怀孕,最好去医院检查一下。
Answer: 6-12周
Question:[OUTPUT]怀孕几个月开始反应</s>[LABELS]怀孕多久会有反应
--------------------------------------------------
用通俗易懂方式讲解系列
-
《大模型面试宝典》(2024版) 正式发布!
-
《大模型实战宝典》(2024版)正式发布!
-
用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
-
用通俗易懂的方式讲解:1.6万字全面掌握 BERT
-
用通俗易懂的方式讲解:NLP 这样学习才是正确路线
-
用通俗易懂的方式讲解:28张图全解深度学习知识!
-
用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
-
用通俗易懂的方式讲解:实体关系抽取入门教程
-
用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
-
用通俗易懂的方式讲解:图解 Transformer 架构
-
用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
-
用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
-
用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
-
用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
-
用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
-
用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
-
用通俗易懂的方式讲解:NLP 算法实习岗,对我后续找工作太重要了!。
-
用通俗易懂的方式讲解:基于 Langchain-Chatchat,我搭建了一个本地知识库问答系统
-
用通俗易懂的方式讲解:大模型微调方法汇总