- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、预备知识
中文文本分类和英文文本分类都是文本分类,为什么要单独拎出来个中文文本分类呢?
在自然语言处理(NLP)领域,中文处理和英文处理之间存在一些显著的区别,主要由于两种语言的语法、结构和表达方式的不同。以下是一些主要的区别:
- 分词(Tokenization):
- 英文处理通常以空格和标点符号作为分词的天然界限,因此分词相对简单。
- 中文处理则复杂得多,因为中文书写时词与词之间没有明显的分隔符。中文分词需要识别词语的边界,这通常涉及到复杂的算法和大量的词典资源。
- 词性标注(Part-of-Speech Tagging):
- 英文的词性变化相对规则,例如通过词尾变化可以区分动词的时态和语态。
- 中文词性标注需要识别每个词的词性,但由于中文词语没有明显的形态变化,这通常需要依赖于上下文信息。
- 句法分析(Parsing):
- 英文的句法结构通常由明确的词汇形态变化和固定的词序来表达。
- 中文句法结构更多地依赖于词序和功能词来表示,因此中文的句法分析需要考虑到这些因素。
- 语义分析(Semantic Analysis):
- 英文的语义可以通过词汇的词根和词缀来推断。
- 中文语义分析则需要更多地依赖于词汇的组合和上下文,因为中文词语往往具有多个意义。
- 机器翻译(Machine Translation):
- 英文和其他印欧语系的语言之间由于语法结构相似,机器翻译相对容易。
- 中文与英文之间的机器翻译更为复杂,需要处理语言结构的不对齐和文化差异。
- 语音和发音:
- 英文处理通常涉及到音标和发音规则。
- 中文处理则涉及到声调,声调的变化会改变词语的意义。
- 上下文依赖性:
- 中文更加依赖于上下文来解析词语和句子的意义,因为一个词语可能有多个意思,具体意思需要根据上下文来确定。
- 英文虽然也有多义词,但上下文依赖性通常没有中文那么强。
- 资源和工具:
- 英文NLP有大量的预训练模型、工具和资源可供使用。
- 中文NLP虽然也有不少资源,但相比英文来说还是较少,尤其是在开源领域。
二、准备工作
1.导入必要的包,检查设备
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms,datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
输出
device(type=‘cuda’)
2.导入数据
import pandas as pdtrain_data = pd.read_csv('./train.csv', sep='\t', header=None)
train_data.head()
输出

3.构建数据集迭代器
def coustom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x,ytrain_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
三、数据预处理
1.构建词典
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"]) # 设置默认索引,如果找不到单词,则会选择默认索引
输出

2.抽样检查
vocab(['你','和','他们','一起','上','空调','播放','农历'])
[18, 84, 1752, 444, 146, 43, 4, 44]
label_name = list(set(train_data[1].values[:]))
print(label_name) #打印标签以确认
[‘TVProgram-Play’, ‘Radio-Listen’, ‘Video-Play’, ‘HomeAppliance-Control’, ‘Weather-Query’, ‘Audio-Play’, ‘FilmTele-Play’, ‘Calendar-Query’, ‘Alarm-Update’, ‘Travel-Query’, ‘Music-Play’, ‘Other’]
lambda 表达式的语法为:
lambda arguments: expression
其中 arguments 是函数的参数,可以有多个参数,用逗号分隔。expression 是一个表达式,它定义了函数的返回值。
text_pipeline函数:将原始文本数据转换为整数列表,使用之前构建的vocb词表和tokenizer分词器函数。具体来说,它接受一个字符串x作为输入,首先使用tokenizer将其分词,然后将每个词在vocb词表中的索引放入一个列表中返回。
label_pipeline函数:将原始标签数据转换为整数,并使用一个字符xx作为输入,并使用 label_name.index(x) 方法获取 x 在 label_name 列表中的索引作为输出。
lambda表达式通常用于数据预处理阶段,将文本数据转换为可以输入到模型中的索引序列
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)
print(text_pipeline('我看见看和平精英上战神必备技巧的游戏视频'))
print(label_pipeline('Video-Play'))
[2, 9317, 13, 973, 1079, 146, 7724, 7574, 7793, 1, 186, 28]
2
3.生成数据批次和迭代器
from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text,_label) in batch:label_list.append(label_pipeline(_label))processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) return text_list.to(device), label_list.to(device), offsets.to(device)dataloader = DataLoader(train_iter,batch_size=4,shuffle=False,collate_fn=collate_batch)
这段代码定义了一个
collate_batch函数,用于将一批次的文本数据和标签数据整理成一个适合模型训练的格式,并创建一DataLoader对象来迭代处理这些批次数据。
from torch.utils.data import DataLoader这行代码从torch.utils.data模块中导入DataLoader类,DataLoader是一个迭代器,它允许我们以批量形式加载数据集,并提供数据混洗等功能。def collate_batch(batch):这行代码定义了一个名为collate_batch的函数,它接受一个参数batch,这个batch是一个列表,包含了多个文本和标签对。label_list, text_list, offsets = [], [], [0]这行代码初始化了三个列表:label_list用于存储标签,text_list用于存储处理后的文本数据,offsets用于存储每个文本数据的偏移量,用于后续的打包操作。for (_text,_label) in batch:这个循环遍历batch中的每个元素,每个元素是一个包含文本和标签的元组。label_list.append(label_pipeline(_label))这行代码将每个标签通过label_pipeline函数处理后添加到label_list中。label_pipeline是一个未定义的函数,应该是用来将标签数据转换为模型可接受的格式。processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64),这行代码将每个文本通过text_pipeline函数处理后转换为PyTorch张量。text_pipeline是一个之前定义的lambda表达式,用于将文本转换为词汇索引列表。text_list.append(processed_text)这行代码将处理后的文本张量添加到text_list中。offsets.append(processed_text.size(0))这行代码计算每个文本的长度,并将其作为偏移量添加到offsets列表中。label_list = torch.tensor(label_list, dtype=torch.int64)这行代码将label_list列表转换为PyTorch张量。text_list = torch.cat(text_list): 这行代码使用torch.cat函数将text_list中的所有文本张量沿第一个维度(维度0)拼接成一个大的张量。offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)这行代码将offsets列表转换为PyTorch张量,并计算其累加和(cumulative sum),这样每个偏移量就表示了对应文本在拼接后张量中的起始位置。return text_list.to(device), label_list.to(device), offsets.to(device)这行代码将处理后的文本、标签和偏移量张量移动到定义的设备(如CPU或GPU)上,并作为函数的返回值。dataloader = DataLoader(train_iter, batch_size=4, shuffle=False, collate_fn=collate_batch)这行代码创建了一个DataLoader对象dataloader,它使用train_iter作为数据源,batch_size设置为4,shuffle设置为False表示不打乱数据顺序,collate_fn设置为collate_batch表示使用自定义的collate_batch函数来整理每个批次的数据。
四、模型构建
1.搭建模型
from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange) self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_() def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
这段代码定义了一个用于文本分类的神经网络模型
TextClassificationModel,它是一个基于PyTorch的nn.Module。
from torch import nn这行代码从torch库中导入nn模块,这个模块包含了构建神经网络所需的各种层和函数。class TextClassificationModel(nn.Module):这行代码定义了一个名为TextClassificationModel的新类,它继承自nn.Module。这意味着这个类会拥有nn.Module的所有方法和属性,包括神经网络的前向传播方法。def __init__(self, vocab_size, embed_dim, num_class):这行代码定义了类的初始化方法__init__,它接受三个参数:vocab_size(词汇表的大小),embed_dim(嵌入层的维度),num_class(分类任务的类别数)。super(TextClassificationModel, self).__init__()这行代码调用父类nn.Module的初始化方法。self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)这行代码创建了一个nn.EmbeddingBag对象,它是一个特殊的嵌入层,可以处理可变长度的序列数据,并且会自动计算所有嵌入向量的平均值。sparse=False表示不使用稀疏权重。self.fc = nn.Linear(embed_dim, num_class)这行代码创建了一个全连接层fc,它将嵌入层的输出映射到分类的类别数。self.init_weights()这行代码调用了类中定义的init_weights方法,用于初始化模型的权重。def init_weights(self):这行代码定义了init_weights方法,用于初始化嵌入层和全连接层的权重。initrange = 0.5这行代码定义了初始化范围initrange,用于权重初始化。self.embedding.weight.data.uniform_(-initrange, initrange)这行代码将嵌入层的权重初始化为在-initrange和initrange之间的均匀分布。这段代码是在Pytorch框架下用于初始化神经网络的词嵌入层(embedding layer)权重的一种方法。这里使用了均匀分布的随机值来初始化权重,其作用如下:
self.embedding.weight_data.uniform(-irange, irange): 这是神经网络中的词嵌入层(embedding layer)。词嵌入层的作用是将离散的单词表示为固定大小的连续向量(通常为整数索引)。这些向量捕捉了单词之间的语义关系,并作为网络的输入。self.embedding.weight_data: 它是词嵌入层的权重矩阵,它的形状为(vocab_size, embedding_dim),其中vocb_size是词汇表的大小,embedding_dim是维度参数。self.embedding.weight_data.uniform(-irange, irange): 这是一个原地操作(in-place operation),用于将权重矩阵的一个均匀分布进行初始化。均匀分布的分布范围由参数irange决定。uniform(-irange, irange), intrance(irange): 356度深度学习训练营 通过这种方式初始化词嵌入层的权重,可以使得模型在训练开始时具有一定程度的随机性,有助于避免梯度消失或梯度爆炸等问题。在训练过程中,这些权重将通过优化算法不断更新,以捕捉到更好的单词表示。
self.fc.weight.data.uniform_(-initrange, initrange)这行代码将全连接层的权重初始化为在-initrange和initrange之间的均匀分布。self.fc.bias.data.zero_()这行代码将全连接层的偏置初始化为0。def forward(self, text, offsets)::这行代码定义了模型的前向传播方法forward,它接受文本数据和偏移量作为输入。embedded = self.embedding(text, offsets):这行代码使用嵌入层处理文本数据,offsets用于指定每个序列的开始位置。return self.fc(embedded):这行代码将嵌入层的输出传递给全连接层,并返回最终的分类结果。
2.初始化模型
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)
3.定义训练和评估的函数
import time
def train(dataloader):model.train() # 切换为训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad()# grad属性归零loss = criterion(predicted_label, label) # 计算网络输出和真实值之间的差距,label为真实值loss.backward()# 反向传播torch.nn.utils.clip_grad_norm(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 每一步自动更新# 记录acc与losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:4d} | {:4d}/{:4d} batches | ''train_acc {:4.3f} | train_loss {:4.5f} |'.format(epoch, idx, len(dataloader),total_acc / total_count, train_loss / total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换为测试模式total_acc, val_loss, total_count = 0, 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算loss值# 记录测试数据total_acc += (predicted_label.argmax(1) == label).sum().item()val_loss += loss.item()total_count += label.size(0)return total_acc / total_count, val_loss / total_count
import time:导入time模块,用于计算训练和评估过程中的时间。def train(dataloader):定义一个名为train的函数,它接受一个名为dataloader的参数,这个参数应该是一个数据加载器,用于提供批量数据。model.train()将模型设置为训练模式,这对于一些层(如dropout和batch normalization)是必要的。total_acc, train_loss, total_count = 0, 0, 0初始化累加器,用于记录整个训练过程中的准确率、损失和总样本数。log_interval = 50定义一个日志打印间隔,每50个批次打印一次训练状态。start_time = time.time()记录训练开始的时间。for idx, (text, label, offsets) in enumerate(dataloader):遍历dataloader中的每个批次,idx是批次的索引,(text, label, offsets)是每个批次的数据。predicted_label = model(text, offsets)使用模型对输入的text和offsets进行前向传播,得到预测的标签。optimizer.zero_grad()清空模型的梯度,为下一次反向传播做准备。loss = criterion(predicted_label, label)计算预测标签和真实标签之间的损失。loss.backward()对损失进行反向传播,计算模型参数的梯度。torch.nn.utils.clip_grad_norm(model.parameters(), 0.1)对模型的梯度进行裁剪,防止梯度爆炸。torch.nn.utils.clip_grad_norm(model_parameters(), 1)是一个PyTorch函数,用于在训练神经网络时限制梯度的大小。这种操作被称为梯度裁剪(gradient clipping),可以防止梯度爆炸问题,从而提高神经网络的稳定性和性能。
在这个函数中:
- model_parameters()表示模型的所有参数。对于一个神经网络,参数通常包括权重和偏置项。
- 0.1是一个指定的阈值,表示梯度的最大范数(L2范数)。如果计算出的梯度范数超过这个阈值,梯度会被缩放,使其范数等于阈值。梯度裁剪的主要目的是防止梯度爆炸。梯度爆炸通常发生在训练深度神经网络时,尤其是在处理长序列数据的传播网络(RNN)中。当梯度爆炸时,参数可能会变得非常大,导致模型无法收敛或出现数值不稳定。通过限制梯度的大小,梯度裁剪有助于解决这些问题,使模型训练变得更加稳定。
optimizer.step()使用优化器更新模型的参数。total_acc += (predicted_label.argmax(1) == label).sum().item()累加本次批次的准确率。train_loss += loss.item()累加本次批次的损失。total_count += label.size(0)累加本次批次的样本数。if idx % log_interval == 0 and idx > 0:如果达到日志打印间隔,打印当前的训练状态。elapsed = time.time() - start_time计算自训练开始以来的时间。print('| epoch {:4d} | {:4d}/{:4d} batches | train_acc {:4.3f} | train_loss {:4.5f} |'.format(...)打印训练进度、准确率和损失。total_acc, train_loss, total_count = 0, 0, 0重置累加器,为下一个训练周期做准备。start_time = time.time()重置开始时间,为下一个训练周期做准备。def evaluate(dataloader):定义一个名为evaluate的函数,用于评估模型的性能。model.eval()将模型设置为评估模式,这对于一些层(如dropout和batch normalization)是必要的。total_acc, val_loss, total_count = 0, 0, 0初始化累加器,用于记录整个评估过程中的准确率、损失和总样本数。with torch.no_grad():在这个上下文中,所有的计算都不会计算梯度,这样可以节省内存和计算资源。for idx, (text, label, offsets) in enumerate(dataloader):遍历dataloader中的每个批次。predicted_label = model(text, offsets)使用模型进行前向传播,得到预测的标签。loss = criterion(predicted_label, label)计算预测标签和真实标签之间的损失。total_acc += (predicted_label.argmax(1) == label).sum().item()累加本次批次的准确率。val_loss += loss.item()累加本次批次的损失。total_count += label.size(0)累加本次批次的样本数。return total_acc / total_count, val_loss / total_count返回整个评估过程中的平均准确率和平均损失。 总的来说,train函数用于训练模型,而evaluate函数用于评估模型的性能。这两个函数都遍历数据加载器中的所有批次,并累加准确率和损失,最后打印或返回这些统计信息。
五、训练模型
1.拆分数据集并运行模型
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset# 超参数
EPOCHS = 10
LR = 5
BATCH_SIZE = 32criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 构建数据集
train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)
split_train_, split_valid_= random_split(train_dataset, [int(len(train_dataset) * 0.8), int(len(train_dataset) * 0.2)])
train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| epoch {:1} | time:{:4.2f} ''| valid_acc {:4.3f} | valid_loss {:4.3f} | lr {:6f} '.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-' * 69)
torchtext.data.functional_map style dataset函数的作用是将一个迭代式的数据集(iterable-style dataset)转换为映射为索引的数据集(Map-style dataset)。这个转换使得我们可以通过索引(例如:整数)更方便地访问数据集中的元素。
在PyTorch中,数据集可以分为两种类型:Iterable-style和Map-style。Iterable-style数据集实现了一个迭代器方法,可以用于遍历数据集中的元素,但不支持通过索引访问。而Map-style数据集实现了getitem()和len()方法,可以直接通过索引访问特定元素,并能获取数据集的大小。
TorchText是PyTorch的一个扩展库,专注于处理文本数据。torchtext.data.functional_map_style dataset函数可以帮助我们将一个Iterable-style数据集转换为一个易于操作的Map-style数据集。这样,我们可以通过索引直接访问数据集中特定的样本,从而简化了训练、验证和测试过程中的数据处
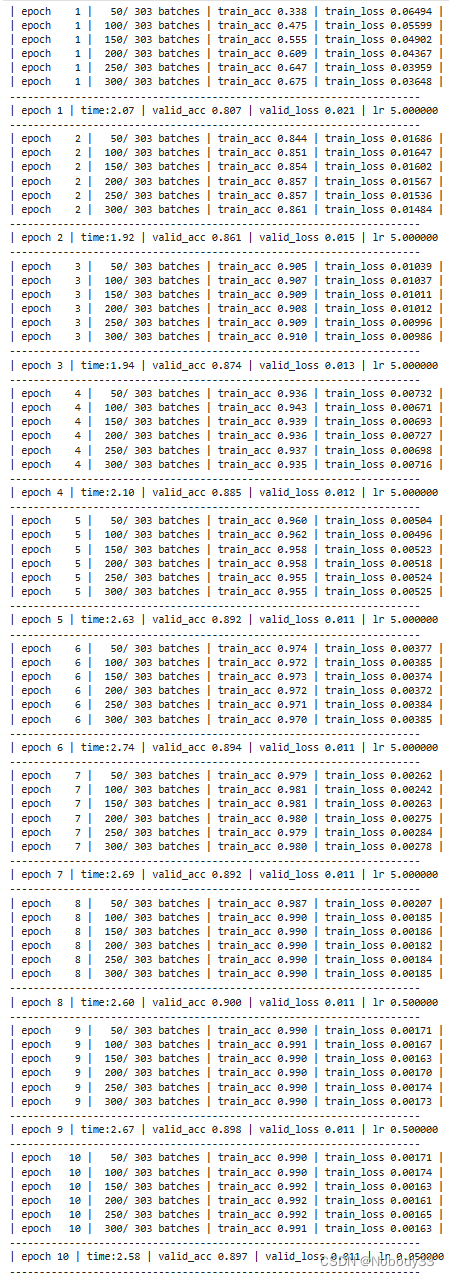
test_acc, test_loss = evaluate(valid_dataloader)
print('模型准确率为:{:5.4f}'.format(test_acc))
模型准确率为:0.8971
2.测试数据
def predict(text, text_pipeline): with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()
ex_text_str1 = "随便播放一首专辑阁楼里的佛里的歌"
ex_text_str2 = "还有双鸭山到淮阴的汽车票吗13号的"
model = model.to("cpu")
print("该文本的类别是:%s" % label_name[predict(ex_text_str1,text_pipeline)])
print("该文本的类别是:%s" % label_name[predict(ex_text_str2,text_pipeline)])
该文本的类别是:Music-Play
该文本的类别是:Travel-Query