一、本文介绍
本文给大家带来的改进机制是YOLOv10提出的PSA注意力机制,自注意力在各种视觉任务中得到了广泛应用,因为它具有显著的全局建模能力。然而,自注意力机制表现出较高的计算复杂度和内存占用。为了解决这个问题,鉴于注意力头冗余的普遍存在,我们提出了一种高效的部分自注意力(PSA)模块设计,其能够在不显著增加计算成本的情况下提升YOLO模型的性能!本文附其网络结构图辅助大家理解该结构,同时本文包含YOLOv9添加该注意力机制的方法!
欢迎大家订阅我的专栏一起学习YOLO!
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏
目录
一、本文介绍
二、PSA介绍
三、PSA核心代码
四、手把手教你添加PSA注意力机制
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
五、PSA的yaml文件和运行记录
5.1 PSA的yaml文件
5.2 训练过程截图
五、本文总结
二、PSA介绍

论文地址:官方论文地址点击此处即可跳转
代码地址:官方代码地址点击此处即可跳转

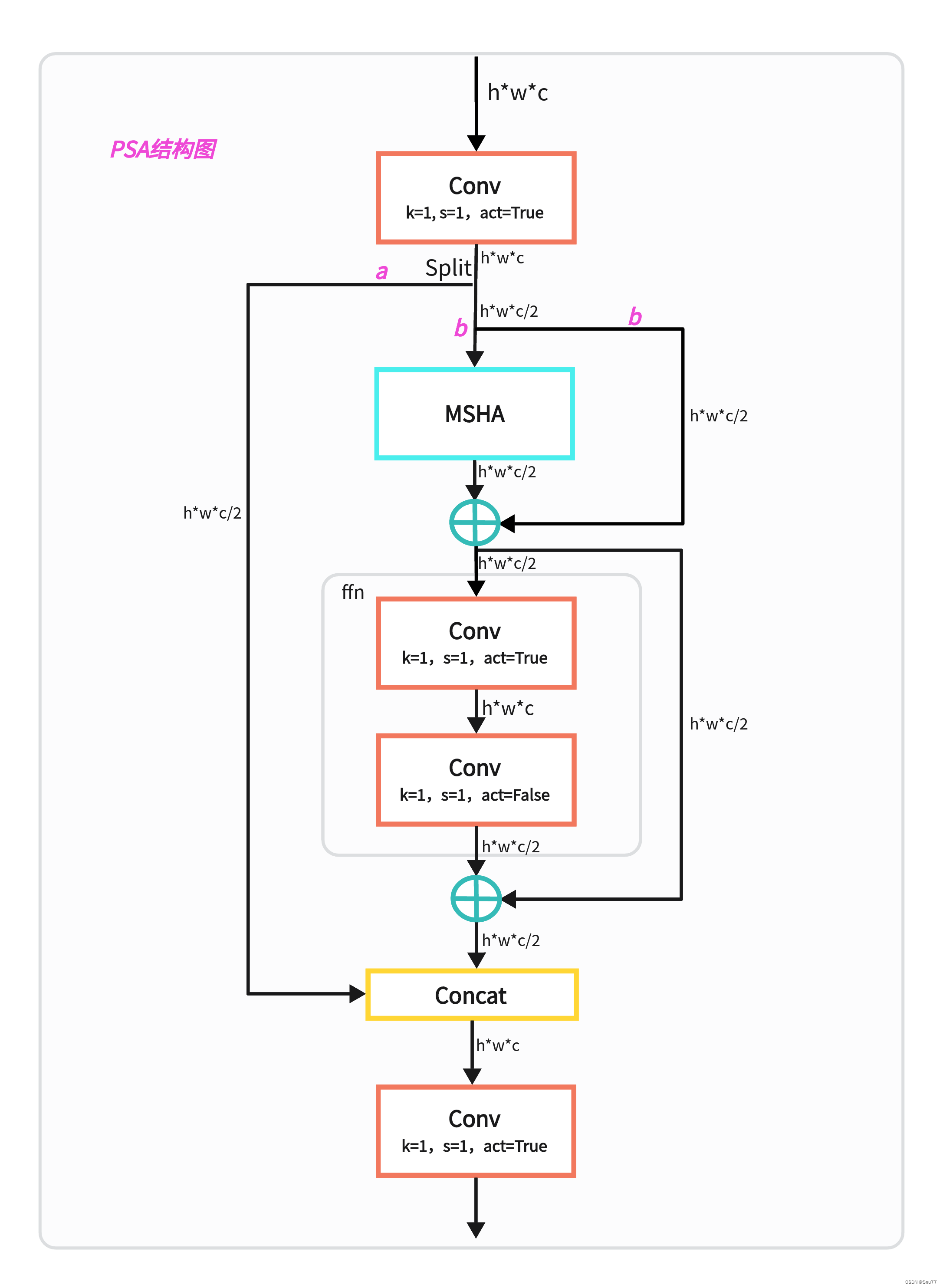
自注意力在各种视觉任务中得到了广泛应用,因为它具有显著的全局建模能力。然而,自注意力机制表现出较高的计算复杂度和内存占用。为了解决这个问题,鉴于注意力头冗余的普遍存在,我们提出了一种高效的部分自注意力(PSA)模块设计,如图3(c)所示。
具体来说,我们通过1×1卷积将特征均匀地划分为两部分。然后,我们仅将其中一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。两部分特征随后被连接并通过1×1卷积融合。此外,我们遵循将MHSA中查询和键的维度分配为值的一半,并将LayerNorm替换为BatchNorm以加快推理速度。
PSA仅在分辨率最低的Stage 4之后放置,以避免自注意力二次复杂性带来的过多开销。通过这种方式,可以在低计算成本下将全局表示学习能力引入YOLO模型,从而增强模型能力并提高性能。
通过这些精度驱动的设计,我们能够在不显著增加计算成本的情况下提升YOLO模型的性能。
三、PSA核心代码
核心代码的使用方式看章节四!
import torch
import torch.nn as nn__all__ = ['PSA']def autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class Attention(nn.Module):def __init__(self, dim, num_heads=8,attn_ratio=0.5):super().__init__()self.num_heads = num_headsself.head_dim = dim // num_headsself.key_dim = int(self.head_dim * attn_ratio)self.scale = self.key_dim ** -0.5nh_kd = nh_kd = self.key_dim * num_headsh = dim + nh_kd * 2self.qkv = Conv(dim, h, 1, act=False)self.proj = Conv(dim, dim, 1, act=False)self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)def forward(self, x):B, _, H, W = x.shapeN = H * Wqkv = self.qkv(x)q, k, v = qkv.view(B, self.num_heads, -1, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)attn = ((q.transpose(-2, -1) @ k) * self.scale)attn = attn.softmax(dim=-1)x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W) + self.pe(v.reshape(B, -1, H, W))x = self.proj(x)return xclass PSA(nn.Module):def __init__(self, c1, c2, e=0.5):super().__init__()assert (c1 == c2)self.c = int(c1 * e)self.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv(2 * self.c, c1, 1)self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)self.ffn = nn.Sequential(Conv(self.c, self.c * 2, 1),Conv(self.c * 2, self.c, 1, act=False))def forward(self, x):a, b = self.cv1(x).split((self.c, self.c), dim=1)b = b + self.attn(b)b = b + self.ffn(b)return self.cv2(torch.cat((a, b), 1))四、手把手教你添加PSA注意力机制
4.1 修改一
第一还是建立文件,我们找到如下yolov9-main/models文件夹下建立一个目录名字呢就是'modules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
4.3 修改三
第三步我门中到如下文件'yolov9-main/models/yolo.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!

4.4 修改四
然后我们找到parse_model方法,按照如下修改->
到此就修改完成了,大家可以复制下面的yaml文件运行。
五、PSA的yaml文件和运行记录
5.1 PSA的yaml文件
此yaml文件使用方法和YOLOv10保持一致,大家如果可以尝试替换更多的Conv!
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []],# conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# conv down[-1, 1, Conv, [256, 3, 2]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# conv down[-1, 1, Conv, [512, 3, 2]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# conv down[-1, 1, Conv, [512, 3, 2]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 11[-1, 1, PSA, [512]], # 添加一行我们的改进机制# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)# conv-down merge[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)# conv-down merge[-1, 1, Conv, [512, 3, 2]],[[-1, 11], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)# routing[5, 1, CBLinear, [[256]]], # 24[7, 1, CBLinear, [[256, 512]]], # 25[9, 1, CBLinear, [[256, 512, 512]]], # 26# conv down[0, 1, Conv, [64, 3, 2]], # 27-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 28-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29# conv down fuse[-1, 1, Conv, [256, 3, 2]], # 30-P3/8[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 33-P4/16[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 36-P5/32[[26, -1], 1, CBFuse, [[2]]], # 37# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38# detect[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]
5.2 训练过程截图

五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv9改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏




