毕业设计(论文)
基于SpringBoot的游戏防沉迷系统的设计与实现
摘 要
随着网络游戏市场的持续火爆,其最明显的负面影响----“网络游戏沉迷问题”已成为当前社会普遍关心的热点问题。根据2010年8月1日实施的《网络游戏管理暂行办法》,网络游戏用户需使用有效身份证件进行实名注册。为保证流畅游戏体验,享受健康游戏生活、保护未成年人身心健康,未满18岁的用户将受到防沉迷系统的限制,在全国范围内强制推行网络游戏防沉迷系统。而这些网络游戏防沉迷系统主要由游戏生产商推出,因此每款游戏防沉迷系统只针对一款游戏,不能解决青少年玩多款游戏而拥有过多的游戏时间的问题。因此,有必要设计一种针对终端用户的游戏沉迷监控系统,以解决上述问题。
防沉迷软件的开发可以有效的掌控好未成年人的具体上网时间,合理的安排好时间的利用方向,使得劳逸结合。
本系统使用后台使用Springboot框架开发,数据库使用MySQL,完成系统功能模块的开发。
关键词:Springboot框架;防沉迷系统;MYSQL数据库
ABSTRACT
As the online game market continues to hot, its most obvious negative impact ---- "addiction to online games" has become a hot issue of general concern in the current society. According to the Interim Measures for the Administration of Online Games, which came into effect on August 1, 2010, users of online games need to register with their real names using valid id cards. Users under the age of 18 will be subject to a nationwide anti-addiction system to ensure smooth gaming experience, enjoy a healthy gaming life and protect the physical and mental health of minors. And these online game anti-addiction system is mainly launched by game manufacturers, so each game anti-addiction system is only for one game, can not solve the problem of teenagers playing multiple games and having too much game time. Therefore, it is necessary to design a game addiction monitoring system for end users to solve the above problems.
The development of anti-addiction software can effectively control the specific Internet time of minors, reasonable arrangement of the use of time direction, so that the combination of work and rest.
This system uses Springboot framework development background, database using MySQL, complete the development of system function modules.
Key words :Springboot framework; Anti-addiction system; The MYSQL database
目录
摘要...............................................
ABSTRACT
1 绪 论
1.1研究意义
1.2开发背景
2 相关技术介绍
2.1 Springboot技术
2.2 bootstrap
2.3 MYSQL数据库
2.4 springmvc
2.5 Spring
2.6 MyBatis
3 系统分析
3.1需求分析
3.2可行性分析
3.2.1经济可行性
3.2.2技术可行性
3.2.3操作可行性
3.2.4 法律可行性
3.3界面需求分析
1.输出设计
2.输入设计
4 系统设计
4.1概述
4.2系统功能设计
4.3数据库设计
4.3.1数据库设计原则
4.3.2数据库表设计
5 系统实现
5.1系统登录界面
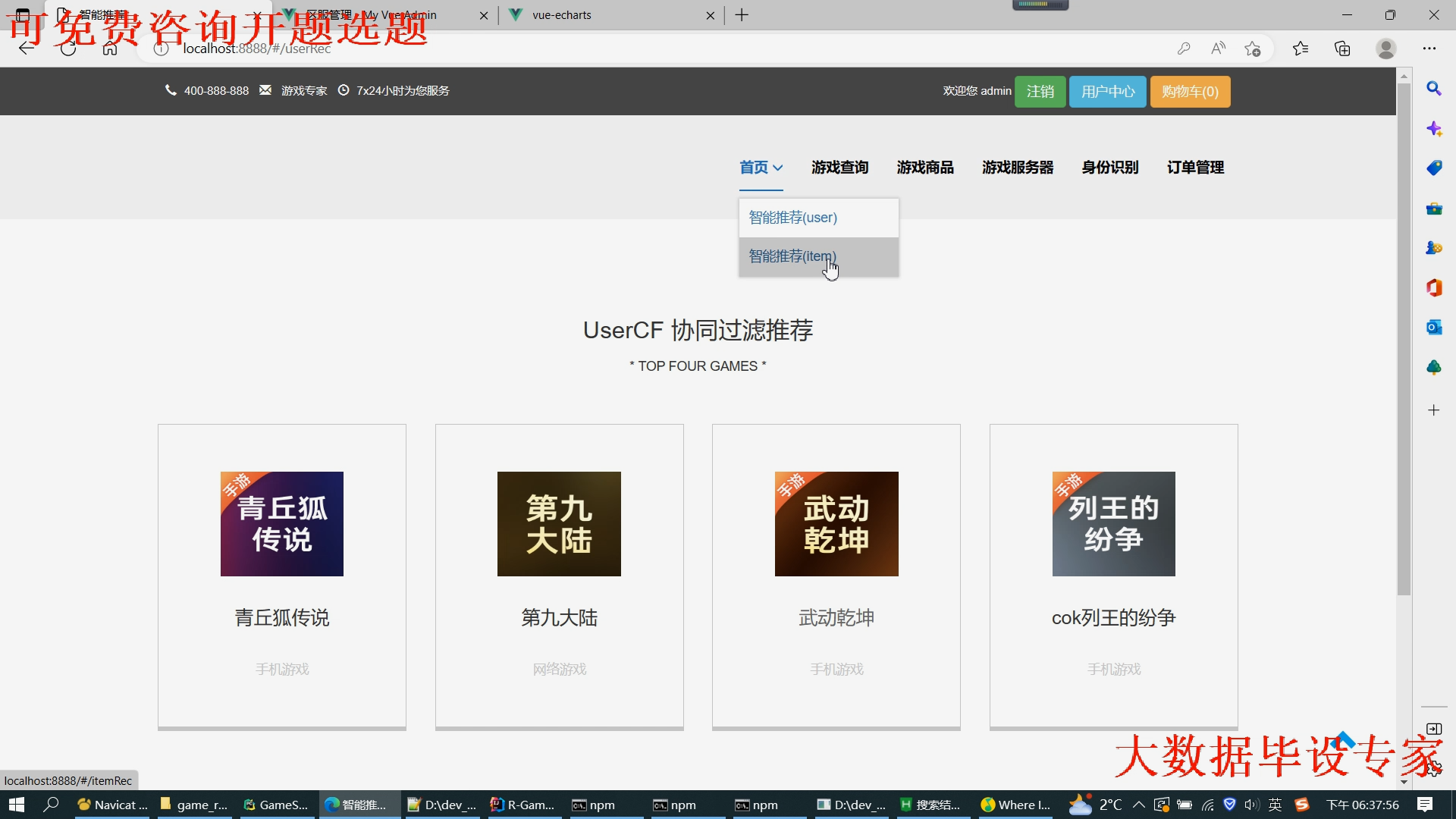
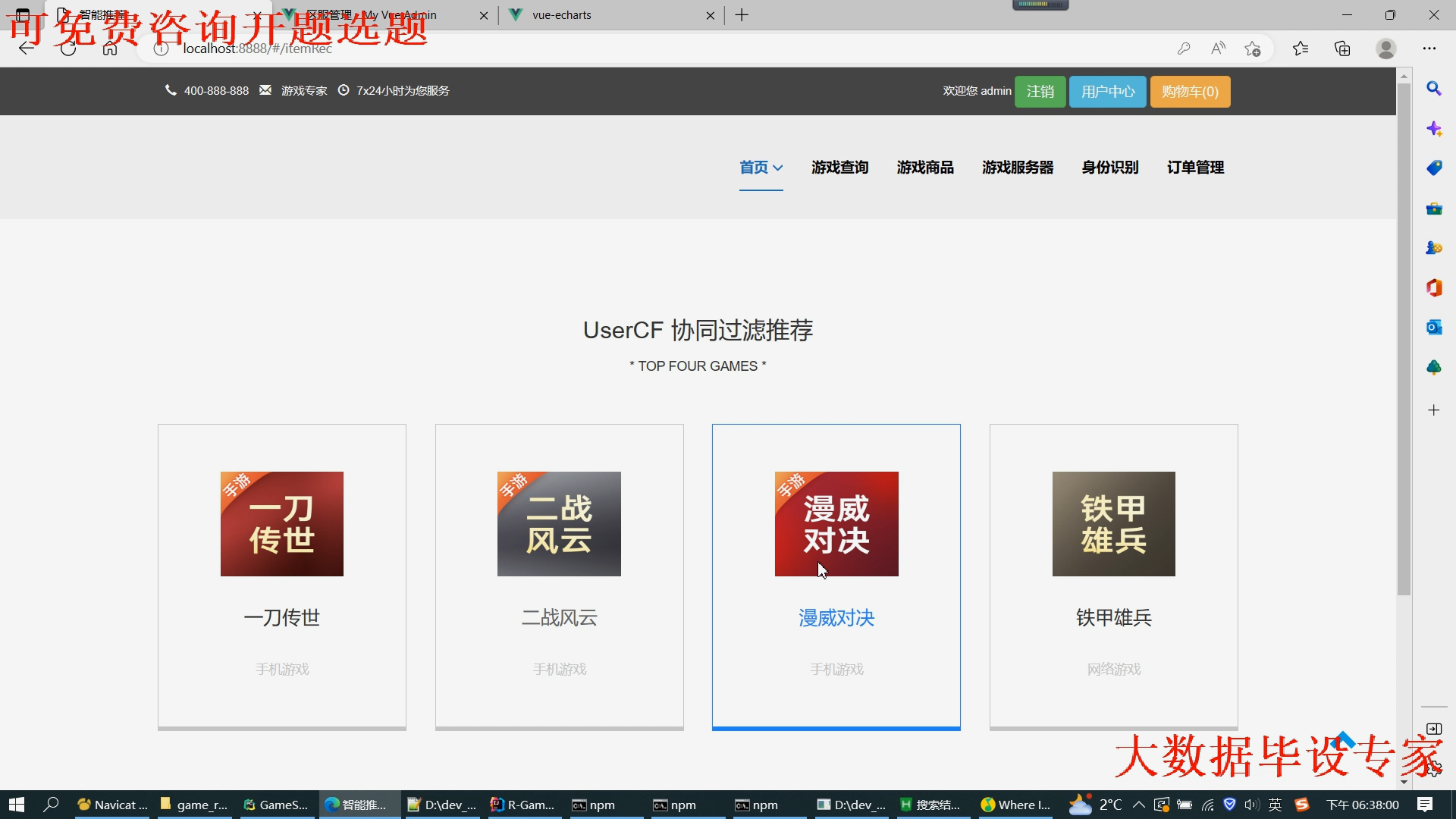
5.2租号主页界面
5.3账号租用界面
5.4号主界面
6 系统测试
6.1系统测试的意义
6.2单元测试
6.2.1 黑盒测试
6.2.2 白盒测试
6.2.3模块接口测试
6.3性能测试
6.4测试分析
总 结
参考文献
致 谢



核心算法代码分享如下:
# coding=utf-8
import random
import sysimport math
from operator import itemgetterimport pymysql
from rate import Rate
from tool import db"""
"""
class ItemBasedCF():# 初始化参数def __init__(self):self.n_sim_movie = 8self.n_rec_movie = 4self.trainSet = {}self.testSet = {}self.movie_sim_matrix = {}self.movie_popular = {}self.movie_count = 0print('Similar movie number = %d' % self.n_sim_movie)print('Recommneded movie number = %d' % self.n_rec_movie)def get_dataset(self, pivot=0.75):trainSet_len = 0testSet_len = 0# sql = ' select * from tb_rate'results = db.session.query(Rate).all()# print(results)for item in results:user, movie, rating = item.uid, item.iid, item.rateself.trainSet.setdefault(user, {})self.trainSet[user][movie] = ratingtrainSet_len += 1self.testSet.setdefault(user, {})self.testSet[user][movie] = ratingtestSet_len += 1# cnn.close()# db.session.close()print('Split trainingSet and testSet success!')print('TrainSet = %s' % trainSet_len)print('TestSet = %s' % testSet_len)# 读文件,返回文件的每一行def load_file(self, filename):with open(filename, 'r') as f:for i, line in enumerate(f):if i == 0: # 去掉文件第一行的titlecontinueyield line.strip('\r\n')print('Load %s success!' % filename)# 计算电影之间的相似度def calc_movie_sim(self):for user, movies in self.trainSet.items():for movie in movies:if movie not in self.movie_popular:self.movie_popular[movie] = 0self.movie_popular[movie] += 1self.movie_count = len(self.movie_popular)print("Total movie number = %d" % self.movie_count)for user, movies in self.trainSet.items():for m1 in movies:for m2 in movies:if m1 == m2:continueself.movie_sim_matrix.setdefault(m1, {})self.movie_sim_matrix[m1].setdefault(m2, 0)self.movie_sim_matrix[m1][m2] += 1print("Build co-rated users matrix success!")# 计算电影之间的相似性 similarity matrixprint("Calculating movie similarity matrix ...")for m1, related_movies in self.movie_sim_matrix.items():for m2, count in related_movies.items():# 注意0向量的处理,即某电影的用户数为0if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:self.movie_sim_matrix[m1][m2] = 0else:self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])print('Calculate movie similarity matrix success!')# 针对目标用户U,找到K部相似的电影,并推荐其N部电影def recommend(self, user):K = self.n_sim_movieN = self.n_rec_movierank = {}if user > len(self.trainSet):user = random.randint(1, len(self.trainSet))watched_movies = self.trainSet[user]for movie, rating in watched_movies.items():for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:if related_movie in watched_movies:continuerank.setdefault(related_movie, 0)rank[related_movie] += w * float(rating)return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]# 产生推荐并通过准确率、召回率和覆盖率进行评估def evaluate(self):print('Evaluating start ...')N = self.n_rec_movie# 准确率和召回率hit = 0rec_count = 0test_count = 0# 覆盖率all_rec_movies = set()for i, user in enumerate(self.trainSet):test_moives = self.testSet.get(user, {})rec_movies = self.recommend(user)for movie, w in rec_movies:if movie in test_moives:hit += 1all_rec_movies.add(movie)rec_count += Ntest_count += len(test_moives)precision = hit / (1.0 * rec_count)recall = hit / (1.0 * test_count)coverage = len(all_rec_movies) / (1.0 * self.movie_count)print('precisioin=%.4f\trecall=%.4f\tcoverage=%.4f' % (precision, recall, coverage))def rec_one(self,userId):print('推荐一个')rec_movies = self.recommend(userId)# print(rec_movies)return rec_movies# 推荐算法接口
def recommend(userId):itemCF = ItemBasedCF()itemCF.get_dataset()itemCF.calc_movie_sim()reclist = []recs = itemCF.rec_one(userId)return recsif __name__ == '__main__':param1 = sys.argv[1]# param1 = "1"result = recommend(int(param1))list = []for r in result:list.append(dict(iid=r[0], rate=r[1]))print(list)