一、实验目的
LL(1)的含义:第一个L表明自顶向下分析是从左向右扫描输入串,第2个L表明分析过程中将使用最左推导,1表明只需向右看一个符号便可决定如何推导,即选择哪个产生式进行推导。
LL(1) 预测分析方法是确定的自顶向下的语法分析技术。本次实验的主要目的就是要加深对LL(1)预测分析法的理论和预测分析程序工作过程的理解。
二、实验要求
实现LL(1)预测分析法需要:
(1)判别文法是否为LL(1)文法。为此需要依次计算FIRST集、FOLLOW集和SELLECT集,根据SELLECT集可判断文法否为LL(1)文法。
(2)构造出分析表。根据SELLECT集和文法产生式构造出LL(1)分析表。
(3)进行句子分析。依据分析表判断出某句子是否为给定文法的句子。
为了降低实现的难度,本实验只要求实现步骤(3)的部分,即手动实现步骤(1)和(2),然后依据步骤(2)建立的分析表编写一个总控程序,实现的句子的分析。
程序应满足下列要求:
- 输入一个分析表,则输出预测分析的步骤。要求从输入文件(input.txt)和键盘中输入预测分析表,把结果输出到结果文件(result.txt)和显示器。
输出格式,如:
步骤 符号栈 输入串 所用产生式
0 #E i1*i2+i3#
1 #ET i1*i2+i3# T-->FT
… ……… ………… …………
2、程序应能判断出某句子是否为该文法的句子。(结论)
3、准备多组测试数据存放于input.txt文件中,测试数据中应覆盖是文法的句子和不是文法的句子两种情况,测试结果要求以原数据与结果对照的形式输出并保存在result.txt中,同时要把结果输出到屏幕。
4、对于上面步骤(1)和(2)虽不需要通过程序来实现,但要求和测试数据一起在实验报告中写明。
5、提前准备
① 实验前,先编制好程序,上机时输入并调试程序。
- 准备好多组测试数据(存放于文件input.txt中)。
三、实验过程:
- 算法分析:
- 初始化文法和预测分析表:
- 首先,定义了文法的终结符集合 v1 和非终结符集合 v2。
- 接着,创建了几个产生式对象,并将它们赋值给预测分析表 C 的不同位置。
- 读取文件内容:
- 从指定的文件中读取文本内容,并存储在变量 exps 中,每行表示一个要分析的文法。
- 预测分析:
- 对于每个读取的文法,先检查是否只包含终结符,然后开始进行预测分析。
- 预测分析过程通过遍历输入字符并根据预测分析表中的产生式进行推导和匹配。
- 复杂度分析:
- 初始化阶段的时间复杂度取决于产生式数量和预测分析表的大小,通常为 O(n)。
- 读取文件内容和预测分析的时间复杂度主要取决于文法的长度和输入长度,通常为 O(m), 其中 m 为文法或输入的长度。
- 空间复杂度主要取决于预测分析表的大小和其他数据结构的空间占用,通常为 O(n^2)。
- 优点:
- 预测分析器具有较好的可读性和易于实现的特点。
- 可以快速识别输入串是否符合给定文法规则。
- 局限性:
- 预测分析器需要提前构建预测分析表,对于大型文法或复杂语言可能会变得复杂。
- 对于某些文法,可能需要使用其他类型的解析器来处理。
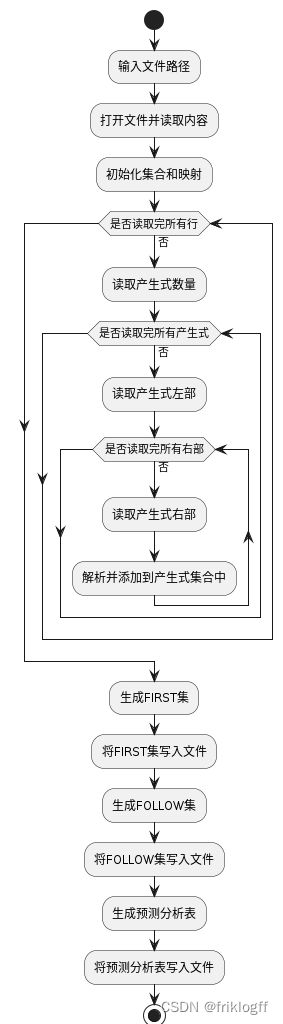
- 程序流程图:
- 程序代码:
class Type:def __init__(self):self.origin = 'N' # 产生式左侧字符 大写字符self.array = "" # 产生式右边字符self.length = 0 # 字符个数def init(self, a, b):self.origin = aself.array = bself.length = len(self.array)# 预测分析表C = [[Type() for _ in range(10)] for _ in range(10)]def is_terminator(c):# 判断是否是终结符v1 = "i+*()#"return c in v1def read_file(file_name):# 读文件res = []try:with open(file_name, 'r') as file:for line in file:res.append(line.strip())except Exception as e:print(e)return resdef init(exp):global ridx, len_exp, rest_stack, toptop = ridx = 0len_exp = len(exp) # 分析串长度rest_stack = list(exp)def print_stack():# 输出分析栈和剩余栈global top, ridx, len_exp, analye_stack, rest_stackprint(''.join(analye_stack[:top + 1]), end=' '*(20-top))for i in range(ridx):print(' ', end='')for i in range(ridx, len_exp):print(rest_stack[i], end='')print('\t\t\t', end='')def analyze(exp):# 分析一个文法global ridx, len_exp, analye_stack, rest_stack, C, topinit(exp)k = 0analye_stack[top] = '#'top += 1analye_stack[top] = 'E' # '#','E'进栈print("步骤\t\t分析栈 \t\t\t\t\t剩余字符 \t\t\t\t所用产生式 ")while True:ch = rest_stack[ridx]x = analye_stack[top]top -= 1 # x为当前栈顶字符print(str(k + 1).ljust(8), end='')if x == '#':print("分析成功!AC!\n") # 接受returnif is_terminator(x):if x == ch: # 匹配上了print_stack()print(ch, "匹配")ridx += 1 # 下一个输入字符else: # 出错处理print_stack()print("分析出错,错误终结符为", ch) # 输出出错终结符returnelse: # 非终结符处理m = v2.find(x) if x in v2 else -1 # 非终结符下标n = v1.find(ch) if ch in v1 else -1 # 终结符下标if m == -1 or n == -1: # 出错处理print_stack()print("分析出错,错误非终结符为", x)returnelif C[m][n].origin == 'N': # 无产生式print_stack()print("分析出错,无法找到对应的产生式") # 输出无产生式错误returnelse: # 有产生式length = C[m][n].lengthtemp = C[m][n].arrayprint_stack()print(x, "->", temp) # 输出所用产生式for i in range(length - 1, -1, -1):if temp[i] != '^':top += 1analye_stack[top] = temp[i] # 将右端字符逆序进栈k += 1ExpFileName = "./input.txt"v1 = "i+*()#" # 终结符v2 = "EGTSF" # 非终结符e = Type()t = Type()g = Type()g1 = Type()s = Type()s1 = Type()f = Type()f1 = Type()e.init('E', "TG")t.init('T', "FS")g.init('G', "+TG")g1.init('G', "^")s.init('S', "*FS")s1.init('S', "^")f.init('F', "(E)")f1.init('F', "i")C[0][0] = C[0][3] = eC[1][1] = gC[1][4] = C[1][5] = g1C[2][0] = C[2][3] = tC[3][2] = sC[3][4] = C[3][5] = C[3][1] = s1C[4][0] = f1C[4][3] = fexps = read_file(ExpFileName)analye_stack = [' ' for _ in range(20)]for exp in exps:flag = Truefor ch in exp:if not is_terminator(ch):flag = Falsebreakif flag:analyze(exp)- 程序运行结果截图:
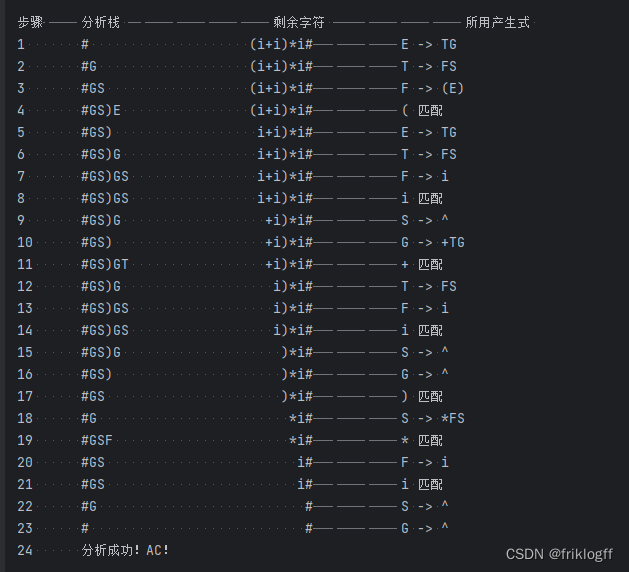
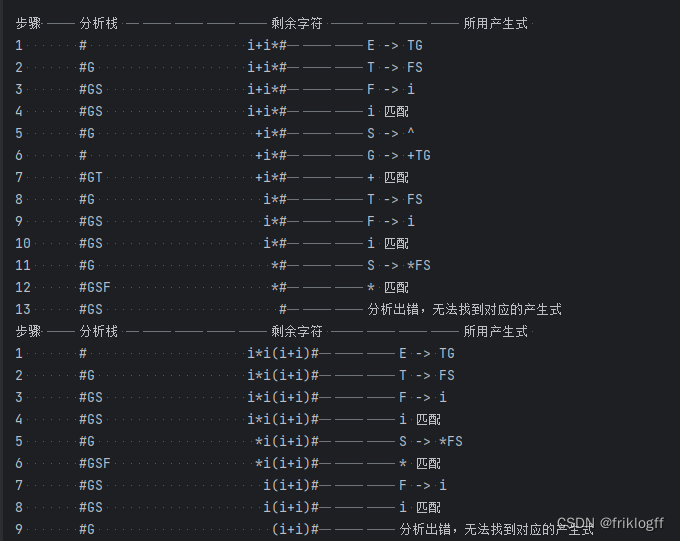
四、思考题:
请描述确定的自顶向下分析思想。
确定的自顶向下分析思想是指自顶向下地对输入串进行分析,在每一步都根据当前的符号栈顶符号和输入串的当前符号,在分析表中查找所用产生式,然后将产生式右部的符号依次推入符号栈中,直到符号栈中只剩下底符号和输入串中所有符号都被读入为止。如果在分析过程中遇到了分析表中没有对应的产生式,则分析失败。
五、实验小结:
通过本次实验,我初步了解了LL(1)预测分析法的基本原理和实现方法,掌握了自顶向下分析思想。在实验过程中,我手动计算了文法的FIRST集、FOLLOW集和SELECT集,构造出了LL(1)分析表,并编写了一个总控程序,实现了句子的分析。在测试过程中,我准备了多组测试数据,覆盖了是文法的句子和不是文法的句子两种情况,测试结果以原数据与结果对照的形式输出并保存在result.txt中,同时输出到屏幕。通过本次实验,我深刻理解了LL(1)预测分析法的工作原理,并掌握了其实现方法。