第五章 深度学习
十二、光学字符识别(OCR)
2. 文字检测技术
2.1 CTPN(2016)
2.1.1 概述
CTPN全称Detecting Text in Natural Image with Connectionist Text Proposal Network(基于连接文本提议网络的自然图像文本检测),是发表于2016年的用于OCR的一篇著名论文。直到今天这个网络框架一直是OCR系统中做文本检测的一个常用网络,极大地影响了后面文本检测算法的方向。该模型在自然环境下水平文字的检测方面有着良好的表现。其基本思想是先使用固定宽度(16像素)的小文本框对图像进行检测,得到一系列含有文字的区域,然后对这些区域进行合并,合并成大的、完整的文本框。
2.1.2 具体步骤
CTPN主要包含以下几个步骤:
- 检测文本。使用固定宽度为16像素的小区域(proposal)在原图像上移动检测,每个proposal使用10个锚点高度在11~273之间(每次除以0.7)。检测器在每个窗口位置输出k个锚点的文本/非文本分数和预测的y轴坐标(v);

-
利用RNN连接多个proposal。检测出文本区域后,将这些小的文本区域进行连接。为了避免对与文本模式类似的非文本目标(窗口,砖块,树叶等)的误检,使用了双向LSTM(LSTM是RNN变种)利用前后两个方向上的信息对proposal进行连接。引入RNN进行连接操作,大大减少了错误检测,同时还能够恢复很多包含非常弱的文本信息的遗漏文本proposal;
-
边沿细化。完成连接后,对边沿进行细化处理,当两个水平边的proposal没有完全被实际文本行区域覆盖,或者某些边的提议被丢弃。通过连接其文本/非文本分数为>0.7的连续文本提议,文本行的构建非常简单。
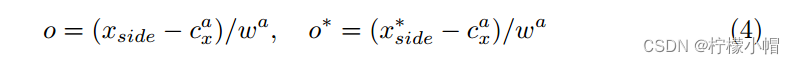
- 文本行构建如下:首先,我们为提议 ( B j ) (B_j) (Bj)定义一个配对邻居作 ( B i ) (B_i) (Bi)为 B j − > B i B_j−>B_i Bj−>Bi,当(i)是最接 ( B j ) (B_j) (Bj)近 ( B i ) (B_i) (Bi)的水平距离,(ii)该距离小于50像素,并且(iii)它们的垂直重叠是>0.7时。其次,如果 B j − > B i B_j−>B_i Bj−>Bi和 B i − > B j B_i−>B_j Bi−>Bj,则将两个提议分组为一对。然后通过顺序连接具有相同提议的对来构建文本行;

2.1.3 网络结构

- VGG16+Conv5:CTPN的基础网络使用了VGG16用于特征提取,在VGG的最后一个卷积层Conv5,CTPN用了3×3的卷积核来对该feature map做卷积,这个Conv5 特征图的尺寸由输入图像来决定,而卷积时的步长却限定为16,感受野被固定为228个像素;
- 卷积后的特征将送入BLSTM继续学习,最后接上一层全连接层FC输出我们要预测的参数:2K个纵向坐标y,2k个分数,k个x的水平偏移量。
2.1.4 损失函数
CTPN有三个输出共同连接到最后的FC层,这三个输出同时预测文本/非文本分数(s),垂直坐标( v = { v c , v h } v=\lbrace v_c,v_h \rbrace v={vc,vh})和边缘细化偏移(o)。损失函数形式为:
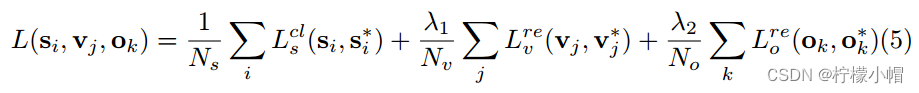
其中每个锚点都是一个训练样本,i是一个小批量数据中一个锚点的索引。 s i s_i si是预测的锚点i作为实际文本的预测概率。 s i ∗ = { 0 , 1 } s_i^*= \lbrace 0,1 \rbrace si∗={0,1}是真实值。j是y坐标回归中有效锚点集合中锚点的索引,定义如下。有效的锚点是定义的正锚点( s j ∗ = 1 s_j^*=1 sj∗=1,如下所述),或者与实际文本提议重叠的交并比(IoU)>0.5。 v j v_j vj和 v j ∗ v_j^* vj∗是与第j个锚点关联的预测的和真实的y坐标。k是边缘锚点的索引,其被定义为在实际文本行边界框的左侧或右侧水平距离(例如32个像素)内的一组锚点。 o k o_k ok和 o k ∗ o_k^* ok∗是与第k个锚点关联的x轴的预测和实际偏移量 L s c l L^{cl}_s Lscl是我们使用Softmax损失区分文本和非文本的分类损失。 L v r e L^{re}_v Lvre和 L o r e L^{re}_o Lore是回归损失。 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2是损失权重,用来平衡不同的任务,将它们经验地设置为1.0和2.0。 N s , N v , N o N_s,N_v,N_o Ns,Nv,No是标准化参数,表示 L s c l , L v r e , L o r e L^{cl}_s,L^{re}_v,L^{re}_o Lscl,Lvre,Lore分别使用的锚点总数。
2.1.5 性能
2.1.5.1 时间性能
使用单个GPU,CTPN(用于整个检测处理)的执行时间为每张图像大约0.14s。没有RNN连接的CTPN每张图像GPU时间大约需要0.13s。因此,所提出的网内循环机制稍微增加了模型计算,并获得了相当大的性能增益。
2.1.5.2 准确率
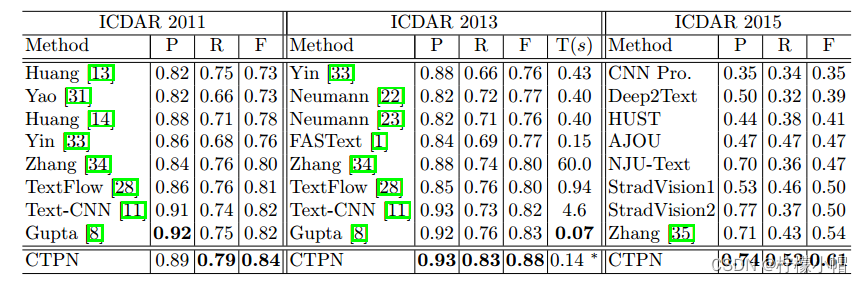
CTPN在自然环境下的文字检测中取得了优异的效果。如下图所示:

CTPN在五个基准数据集上进行了全面评估。在ICDAR 2013上,它的性能优于最近的TextFlow和FASText,将F-measure从0.80提高到了0.88。精确度和召回率都有显著提高,改进分别超过+5%和+7%。CTPN在检测小文本方面也有较好表现。在多个数据集下评估效果如下表所示:
2.1.6 缺陷
- 针对极小尺度文本检测有遗漏。如下图所示:

- 对于非水平的文本的检测效果并不好。
2.2 SegLink(2017)
2.2.1 概述
对于普通目标检测,我们并不需要对其做所谓的多方向目标检测。但文本检测任务则不一样,文本的特点就是高宽比特别大或特别小,而且文本通常存在一定的旋转角度,如果我们对于带角度的文本仍然使用通用目标检测思路,通过四个参数(x,y,w,h)来指定一个目标的位置(如下图红色框),显然误差比较大,而绿色框才是理想的检测效果。那如何才能实现带角度的文本检测呢?让模型再学习一个表示角度的参数θ,即模型要回归的参数从原来的(x,y,w,h)变成(x,y,w,h,θ)。

Seglink是一种多方向文本检测方法,该方法既融入CTPN小尺度候选框的思路,又加入了SSD算法的思路,达到了自然场景下文本检测较好的效果。Seglink核心是将文本检测转换成两个局部元素的检测:segment和link。segment 是一个有方向的box,覆盖文本内容的一部分,而link则连接了两个相邻的segments,表达了这两个segment是否属于同一个文本。该算法通过在多尺度上进行segment和link的检测,最终按照links的表达将相关的segment合并成最终的bounding box。如下图所示。

2.2.2 网络结构
网络使用预先训练的VGG-16网络作为主干(从conv1到pool5)。之后,VGG-16的全连接层被替换为卷积层(fc6替换为conv6;fc7替换为conv7)。接着是一些额外的卷积层(conv8_1到conv11),用于进行多尺度检测。结构如下图所示。
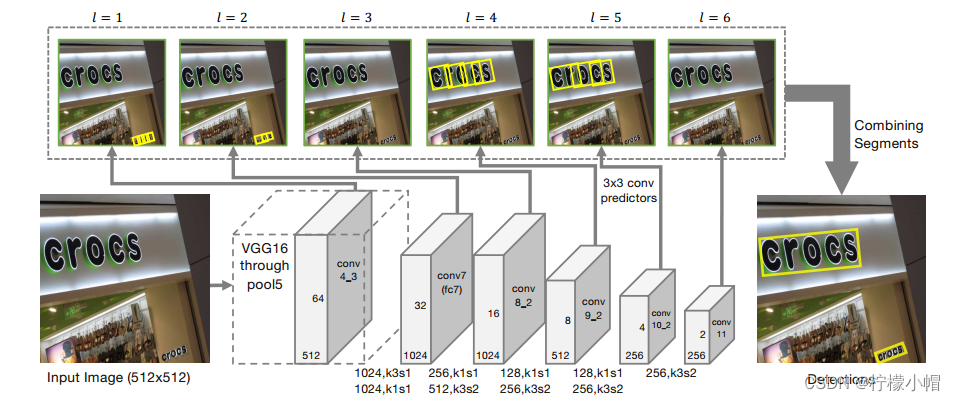
检测到的定向框称为Segment,用 s = ( x s , y s , w s , h s , θ s ) s=(x_s,y_s,w_s,h_s,θ_s) s=(xs,ys,ws,hs,θs)表示。预测器产生7个通道segment检测。其中,2个通道用来判断有没有文本(分类),其余5个用来计算定向框的几何偏移(回归)。
2.2.3 link(链接)
在检测到segment之后,会进行link,将segment合在一起。
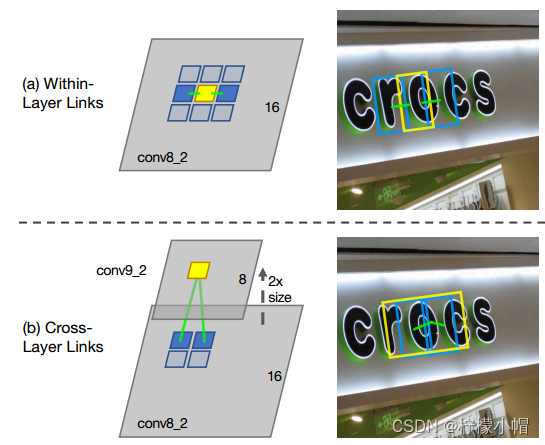
- 层内链接(with-in layer link):每个segment检测与其统一特征层周围的8个segment是否同属于一个字,如果属于则链接在一起。
- 跨层链接(cross layer link):跨层link使用相邻索引连接两个特征图层上的segment。
层内链接和跨层链接示意图如下图所示:
2.2.4 预测参数表示
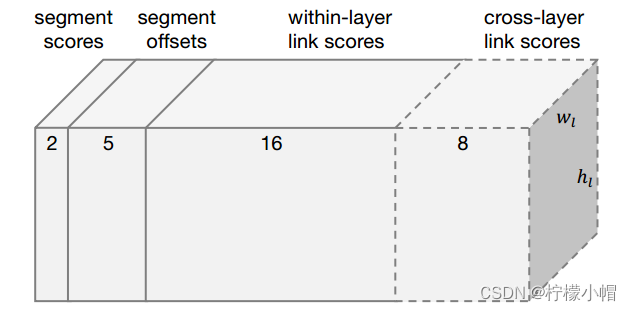
预测器针对每个feature map输出参数总数为(2+5+16+8=31)。假设当前的feature map的尺度为(w,h),那么该层卷积后输出为w×h×31。这些参数包括:
- 每个segment内的分类分数,即判断框内有字符还是无字符的分数(2分类),共2个参数;
- segment的位置信息 ( x , y , w , h , θ ) (x,y,w,h,θ) (x,y,w,h,θ),共5个参数;
- 同层(within-layer)的每个segment的link的分数,表示该方向有link还是没link(2分类问题),而一个segment有八邻域所以有八个方向,参数一共有2×8=16;
- 相邻层(cross-layer)之间也存在link,同样是该方向有link还是没link(2分类问题),而link的个数是4个,所以参数总数为2×4=8。如下图所示:
2.2.5 合并segment和link
网络会生成许多segment和link(数量取决于图像大小),需要将这些segment和link进行合并。合并之前,先根据置信度得分进行过滤。以过滤后的segment为节点,过滤后的link为边,在其上构造一个图。合并算法如下表所示:

合并算法:
- 设有一个集合B,里面有很多相关联的segment待合并;
- 每一个segment都有角度θ,求集合B中所有segment角度的平均值 θ b θ_b θb;
- 求一条直线L,使得所有segment的中心到这条直线的距离最小(最小二乘法线性回归);
- 每个segment的中心向直线L做垂直投影;
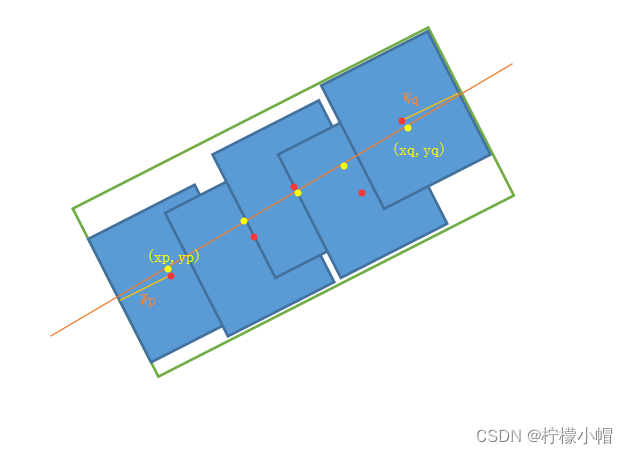
- 从所有投影点中选出相距最远的两个点,记做 ( x p , y p ) (x_p,y_p) (xp,yp)和 ( x q , y q ) (x_q,y_q) (xq,yq);
- 最终合并好的文本框的位置参数记为 ( x b , y b , w b , h b , θ b ) (x_b,y_b,w_b,h_b,θ_b) (xb,yb,wb,hb,θb),则
x b = x p + x q 2 y b = y q + y q 2 x_b=\frac{x_p + x_q}{2} \\ y_b=\frac{y_q + y_q}{2} xb=2xp+xqyb=2yq+yq
- 文本行的宽度 w b w_b wb就是两个最远点的距离(即 ( x p , y p ) (x_p,y_p) (xp,yp)和 ( x q , y q ) ) (x_q,y_q)) (xq,yq))再加上最远两个点所处的segment的宽度的一半( W p W_p Wp和 W q W_q Wq);
- 文本行高度 h b h_b hb就是所有segment高度求平均值。
如下图所示,橙色直线是拟合出的最佳直线,红色点表示segment的中心,黄点表示红点在直线上的投影,绿框就是合并后的完整本文框:
2.2.6 损失函数
SegLink所使用的损失函数由三个部分构成,是否是text的二分类的softmax损失,box的smooth L1 regression损失,是否link的二类的softmax损失。λ1和λ2控制权重,最后都设为1。
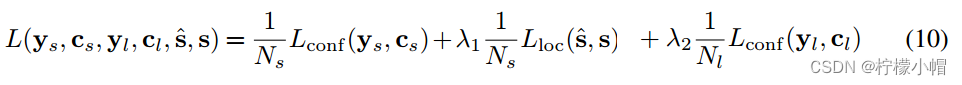
2.2.7 性能
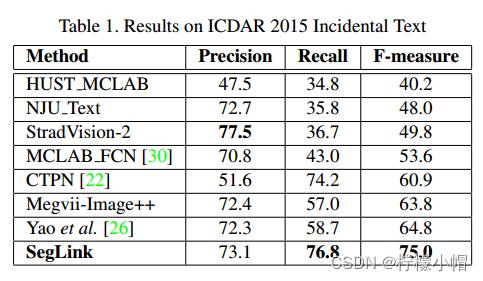
① 英语单语文本检测
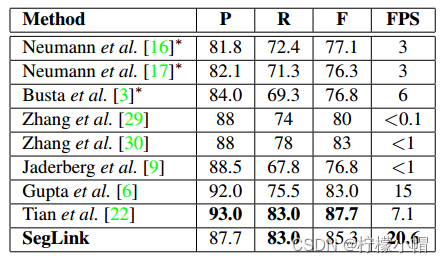
英语单语文本检测效果明显好于其它模型。如下表:
即使在杂乱的背景下也有较好的表现。如图:

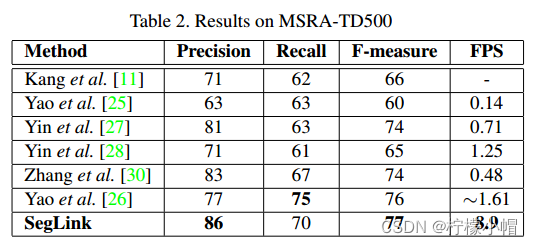
② 多种语言文本检测
SegLink在多语种场景检测中准确率、速度都有较好表现。如下表所示:

2.2.8 局限
① 水平文字检测效果不及CTPN
② 无法检测到字符间距非常大的文本和弯曲文本