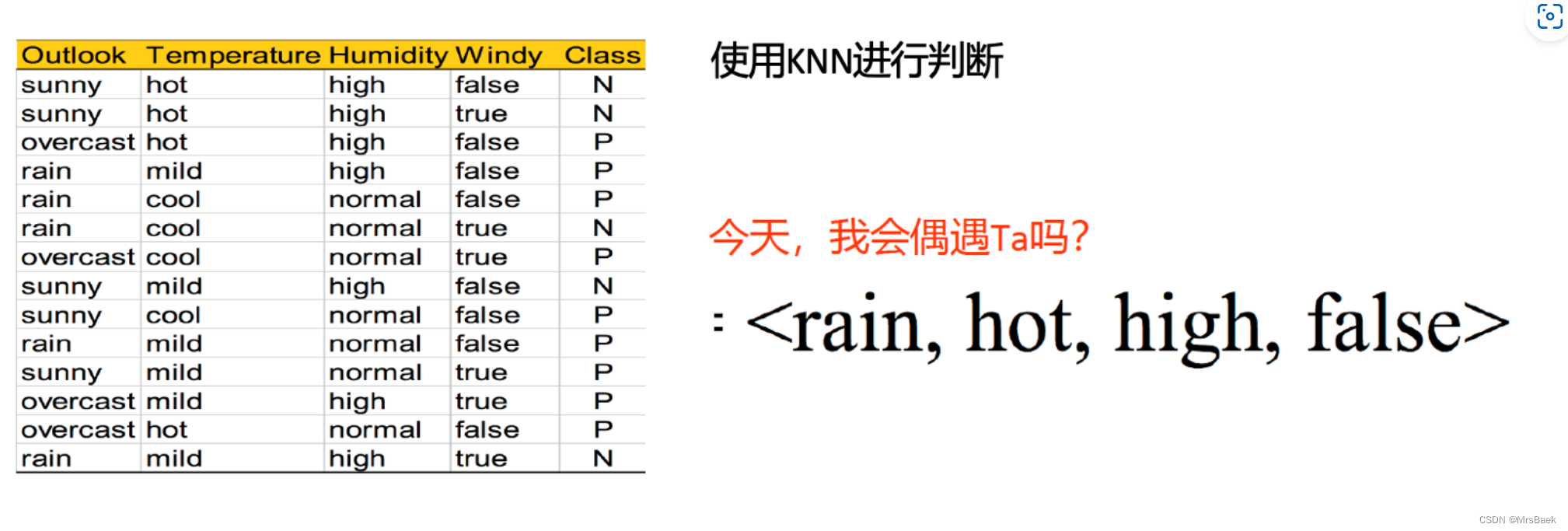
采用kNN算法回答红色字体提出的问题。要求写出算法过程和预测结果。
KNN原理
KNN(K-最近邻)算法是一个简单直观的分类方法。它的核心思想是“物以类聚”,即一个样本的类别通常由其周围最近的几个邻居决定。这里的“最近”是通过计算样本间的距离来确定的。
原理简述:
1. 距离测量:确定一个距离度量,以评估样本之间的相似性。常用的距离度量包括欧氏距离和曼哈顿距离。
2. 邻居选择:选择一个正整数K,表示最近邻居的数量。对于每个需要分类的样本点,算法会找出训练集中与它最近的K个样本点。
3. 多数投票:这K个样本点的多数类别将被赋予给测试样本。如果K=1,那么测试样本的类别就是那一个最近邻居的类别。
解这道题需要涉及的知识点:
1. 数据预处理:将所有的特征转换为数值型数据,因为KNN算法在计算距离时需要数值型数据。
2. 标签编码:将类别型特征(如“晴朗”、“多云”、“下雨”等)转换为数值,这样可以在算法中使用。
3. 选择K值:选择合适的K值对算法的性能影响很大。K值太小会使得噪声数据的影响增大,而K值太大又会使分类器过于简化。
4. 距离计算:理解并能够计算样本点之间的距离,通常使用欧氏距离公式。
欧氏距离是最常用来衡量两个点在多维空间中的真实距离的一种方法。
假设我们有两个点,P 和 Q,在一个n维空间中,它们的坐标分别为
和
,
那么点 P 和点Q 之间的欧氏距离d可以通过下面的公式计算:
或者更简洁地写为:
在二维空间中,这个公式可以简化为我们熟悉的勾股定理形式,计算两点间直线距离:
如果用欧氏距离来计算每个样本点之间的距离,需要将每个类别特征转换为数值,并且可能需要对这些数值进行规范化处理,以确保每个特征在距离计算中的权重是均等的。
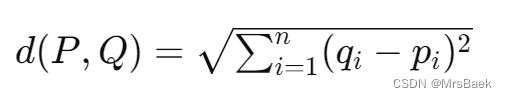
5. 分类决策规则:一旦找到最近的K个邻居,就需要根据这些邻居的类别通过投票的方式来确定新样本的类别。
解题思路
1. 数据准备:
- 首先,需要收集并准备好训练数据,它包括了特征集和标签。在你的案例中,特征集是Outlook、Temperature、Humidity和Windy,而标签是Class。
2. 特征处理:
- 因为KNN是一种基于距离的算法,所以所有的特征都需要是数值型的。如果特征是分类数据(如文字),需要使用编码方法(如标签编码)将其转换为数值。
3. 选择合适的K值:
- K值的选择对KNN算法的结果有很大影响。如果K值太小,模型可能会对噪声数据过于敏感;如果K值太大,邻居中可能会包含太多其他类别的数据点。通常通过交叉验证来选择一个较好的K值。
4. 计算距离:
- 对于新的观测点,计算它与训练集中每个点之间的距离。可以使用不同的距离度量标准,最常用的是欧氏距离。
5. 找到最近的邻居:
- 排序所有的训练实例,根据选择的K值,挑选出距离最近的K个实例作为最近邻居。
6. 多数投票规则:
- 根据这K个邻居的类别,使用多数投票的方式来预测新观测点的类别。具体来说,新观测点将被分配到邻居中最常见的类别。
7. 执行预测:
- 使用KNN模型进行预测。这涉及到将新的数据点输入模型,并根据模型的逻辑输出一个预测结果。
8. 评估模型:
- 如果有可用的测试数据,评估模型的准确性,这通过比较预测结果和实际结果来完成。
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import LabelEncoder# 数据准备
data = {'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast','sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain'],'Temperature': ['hot', 'hot', 'hot', 'mild', 'cool', 'cool', 'cool', 'mild', 'cool', 'mild', 'mild', 'mild', 'hot', 'mild'],'Humidity': ['high', 'high', 'high', 'high', 'normal', 'normal', 'normal', 'high', 'normal', 'normal', 'normal', 'high', 'normal', 'high'],'Windy': ['false', 'true', 'false', 'false', 'false', 'true', 'true', 'false', 'false', 'false', 'true', 'true', 'false', 'true'],'Class': ['N', 'N', 'P', 'P', 'P', 'N', 'P', 'N', 'P', 'P', 'P', 'P', 'P', 'N']
}
df = pd.DataFrame(data)# 编码类别数据
le = LabelEncoder()
df_encoded = df.apply(le.fit_transform)# 分离特征和目标变量
X = df_encoded.drop('Class', axis=1)
y = df_encoded['Class']# 创建KNN分类器,设置K值为3
knn = KNeighborsClassifier(n_neighbors=3)# 训练模型
knn.fit(X, y)# 准备新的观测数据
new_data = pd.DataFrame([['rain', 'hot', 'high', 'false']], columns=['Outlook', 'Temperature', 'Humidity', 'Windy'])# 编码新实例
new_data_encoded = new_data.apply(lambda col: le.fit(df[col.name]).transform(new_data[col.name]))# 预测新数据的类别
prediction = knn.predict(new_data_encoded)# 解码预测结果
decoded_prediction = le.inverse_transform(prediction)# 输出预测结果
print(f'预测结果: {"遇见" if decoded_prediction[0] == "P" else "不遇见"}')
预测结果
![]()
当k值为3时,预测结果为不遇见
结果分析
首先,我们需要理解模型是如何根据输入的数据点(新的天气条件)和训练集中的数据点来做出决策的。
- “不遇见”的原因:
1. 数据特征与类别关系:预测结果受输入特征与类别标签的关系影响。如果大多数与新输入相似(基于设定的特征:雨天、温度热、湿度高、无风)的数据点在训练集中都标记为“N”,KNN将倾向于预测“不遇见”。
2. K值的选取:如果选择的K值不适合当前数据的分布,可能会导致误判。例如,如果K值过大,并且数据类别不均衡,那么多数类别可能会对结果产生过大影响。
3. 训练数据的分布:如果类别“P”(遇见)的样本在特征空间中离新的观测点较远,而类别“N”(不遇见)的样本更接近新的观测点,那么预测结果自然会倾向于“不遇见”。
- 如何尝试得到“遇见”的结果:
- 1. 调整K值:可以尝试减小K值,这样模型将更加依赖于与新观测点最接近的少数邻居的标签。这可能有助于捕捉到少数但更相关的邻居数据点的影响。
2. 数据重采样:如果“P”类的样本数量较少,可以尝试对其进行上采样,以平衡类别分布。这样,类别“P”的影响力会增加,可能会改变预测结果。
3. 特征工程:检查是否所有的特征都有助于模型的预测能力。有时候,删除一些不相关或噪声特征可能会提高模型的表现。也可以尝试引入新的特征或转换现有特征。
4. 改变距离度量方式:如果默认的欧氏距离不适合问题的特性,可以尝试其他距离度量方式,如曼哈顿距离或切比雪夫距离。
5. 模型调优和交叉验证:使用交叉验证来找到最优的K值和其他模型参数。这可以通过网格搜索等方法来实现。