ShardingSphere的诞生
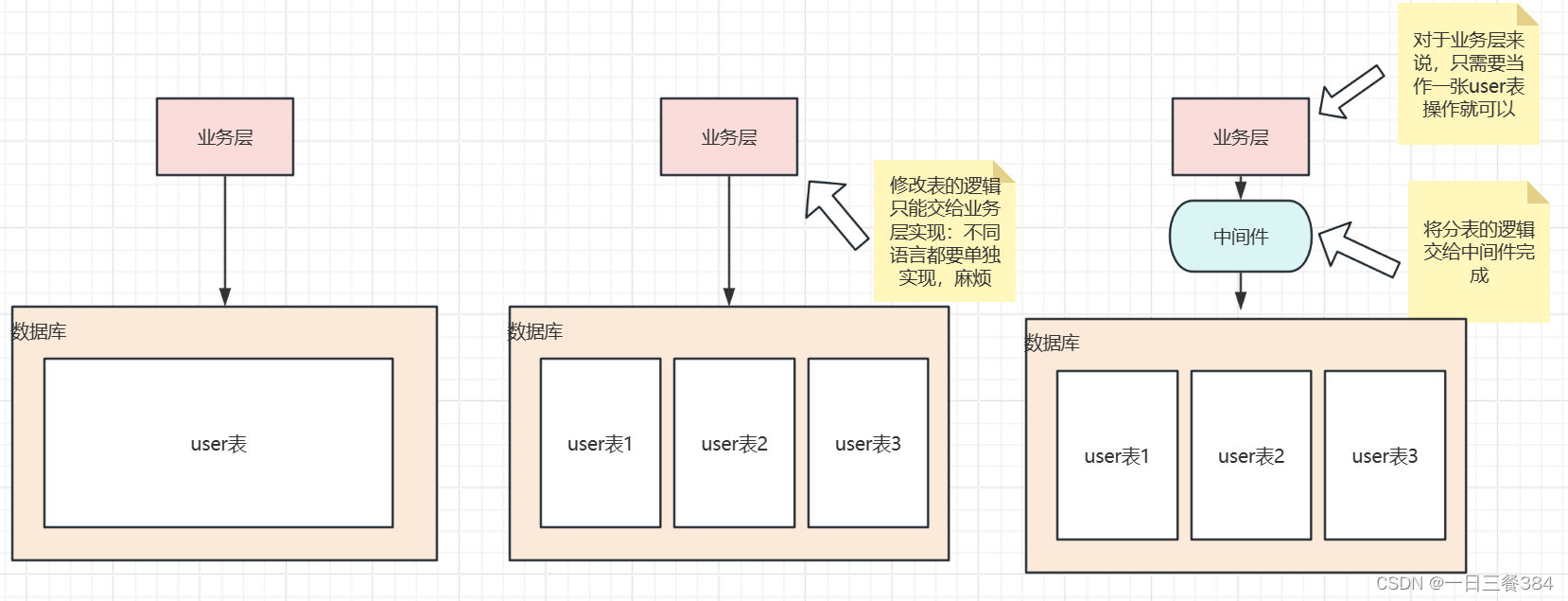
ShardingSphere的结构
Sharding-JDBC :它提供了一个轻量级的 Java 框架,在 Java 的 JDBC 层提供额外的服务。使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。Sharding-JDBC主要用于嵌入到应用程序中,使应用程序能够透明地使用分片和读写分离功能,而无需对应用程序进行大规模修改。
Sharding-Proxy :它以代理的形式部署在应用程序与数据库之间,实现了对 SQL 的解析和改写以及请求的转发。用户无需修改任何应用程序代码,只需通过配置文件或 API 接口进行分片规则设置,即可实现数据分片和读写分离等功能。Sharding-Proxy主要用于需要将数据库访问透明地分片化的情况,而不想在应用程序中引入Sharding-JDBC的情况。它也可以用于监控和审计数据库操作。
Sharding-Sidecar :它将作为一个独立的微服务,为用户提供更为灵活和强大的数据分片、分布式事务和数据治理等功能。Sarding-SideCar 主要用于云原生环境。目前正在开发

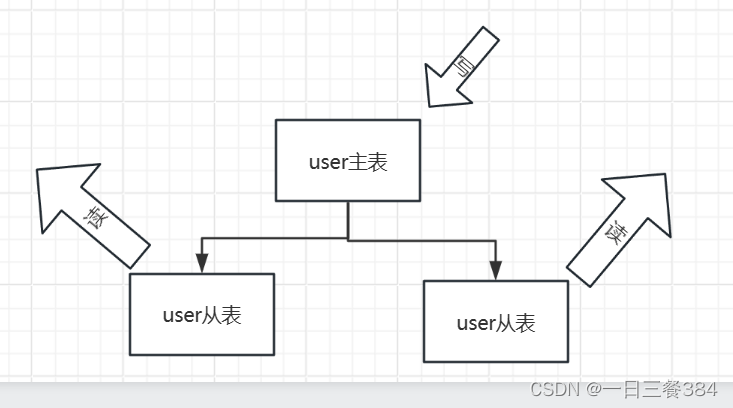
ShardingSphere支持的水平分片和垂直分片的不同
垂直分片:是在应用层面上进行的一种策略,它主要是为了解决单台数据库性能瓶颈的问题,将数据根据业务逻辑分类进行分片存储。每个表中的数据会被分散到不同的数据库中。它的优点是能够减轻单个库的负载压力,方便数据维护等;缺点是没有根本解决单库数据量过大、并发性高的性能瓶颈,并且可能会产生跨服务的事务一致性问题。在应用模块间存在较强耦合关系的情况下,这种策略可能更适合使用。
水平分片:是在数据库层面上进行的一种策略,能够将数据根据某种规则分散至多个库或表中,每个分片仅包含数据的一部分。例如,可以根据某个字段(或某几个字段),如主键进行分片存储。这种策略可以有效地解决单库数据量过大、并发性高的性能瓶颈,提高系统的稳定性和负载能力。水平分片在理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案。
执行一条sql语句时,ShardingSphere的步骤解析

ShardingSphere 解析配置信息,并且支持将配置信息上传到第三方注册中心。
将要执行的 SQL 语句解析。
根据解析上下文匹配数据库和表的分片策略,并生成 SQL 的路由路径。
ShardigSphere根据用户给的SQL语句通过改写引擎修改为在数据库中执行的语句
SQL改写分为正确性改写和优化改写。
ShardingSphere 采用一套自动化的执行引擎,负责将路由和改写完成之后的真实 SQL 安全且高效发送到底层数据源执行。
结果归并:将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端。ShardingSphere 内部实现了流式归并和内存归并两种方案。
面对读写分离情况,ShardingSphere如何处理的?
数据源配置:首先,在应用程序的配置中,你需要配置多个数据库数据源,包括主库(用于写操作)和多个从库(用于读操作)。每个数据源都有一个唯一的名称和连接信息。
SQL解析:当应用程序发送SQL查询请求时,ShardingSphere的SQL 执行引擎会拦截并解析SQL语句。
读写分离规则:ShardingSphere通过读写分离规则来确定查询应该发送到主库还是从库。这些规则可以在配置文件中定义,通常基于SQL的类型(SELECT、INSERT、UPDATE、DELETE)来决定路由。
路由查询:根据读写分离规则,Sharding-JDBC将查询请求路由到适当的数据源。如果是SELECT查询,它将路由到一个从库;如果是INSERT、UPDATE或DELETE操作,它将路由到主库。这确保了写操作总是发送到主库,而读操作可以发送到从库,以分担主库的负载。
执行查询:一旦确定了目标数据源,Sharding-JDBC会将查询请求转发到相应的数据库。主库用于写操作,从库用于读操作。
返回结果:数据库执行查询后,将结果返回给Sharding-JDBC,然后Sharding-JDBC将结果返回给应用程序。