Playwright
Playwright是一款强大的自动化库,提供了一种简便易用、高性能的网页自动化解决方案。它支持同步和异步两种操作方式,用户无需为不同浏览器单独下载驱动程序,因为Playwright内置了对Chrome、Firefox、Safari等多种浏览器的支持。此外,Playwright引入了上下文(context)的概念,使得多个页面和浏览器实例的管理变得更加灵活。它支持无头模式运行,可以在后台静默执行,同时,运行脚本时还能开启开发者工具,便于调试。在元素定位上,Playwright允许使用传统的选择器,同时也提供了自己的定位机制和自定义定位方式。与Selenium相比,Playwright的启动和执行速度更快,它基于WebSocket实现了双向通信,而Selenium则是基于HTTP的单向通信。Playwright还提供了自动等待功能,简化了等待逻辑的处理。在操作上,Playwright提供了便捷的多页面切换功能,无需使用iframe,使得页面操作更加直观。对于不熟悉的方法或类,用户可以通过录制功能来了解其使用过程。Playwright的回放效率高,适合进行回归测试。其底层的高可用性和稳定性意味着用户可能不需要进行额外的二次封装。最后,Playwright支持多种编程语言,包括Python、Java、JavaScript和C#,满足了不同用户的需求。
简单来说,Playwright比Selenium更容易安装和使用,并且效率性能更高,支持更多的浏览器。首先使用Playwright库,请进行安装,命令如下。
pip install playwright
然后运行以下代码,playwright就会自动进行浏览器驱动下载和配置,比selenium更智能,配置过程非常简单。
注意:驱动下载速度比较慢,请耐心等待,若想加快速度,可尝试替换下载源。请找到/site-packages/playwright/driver/package/lib/server/registry/index.js文件,然后将constPLAYWRIGHT_CDN_MIRRORS变量中的3个值都改成国内的镜像就可以,如填入
https://registry.npmmirror.com/-/binary/playwright。
当全部驱动下载完毕后,便可以启动脚本录制,这样就能够一边操作网站,程序会自动记录操作过程,生成代码,大大提高编写脚本的效率,减少寻找数据定位的时间。启动脚本录制命令如下。
playwright codegen --target python -o gz_scrapy.py https://data.gz.gov.cn/
通过命令启动了一个脚本录制程序和一个浏览器,并且已经打开了广州政府数据开放平台。
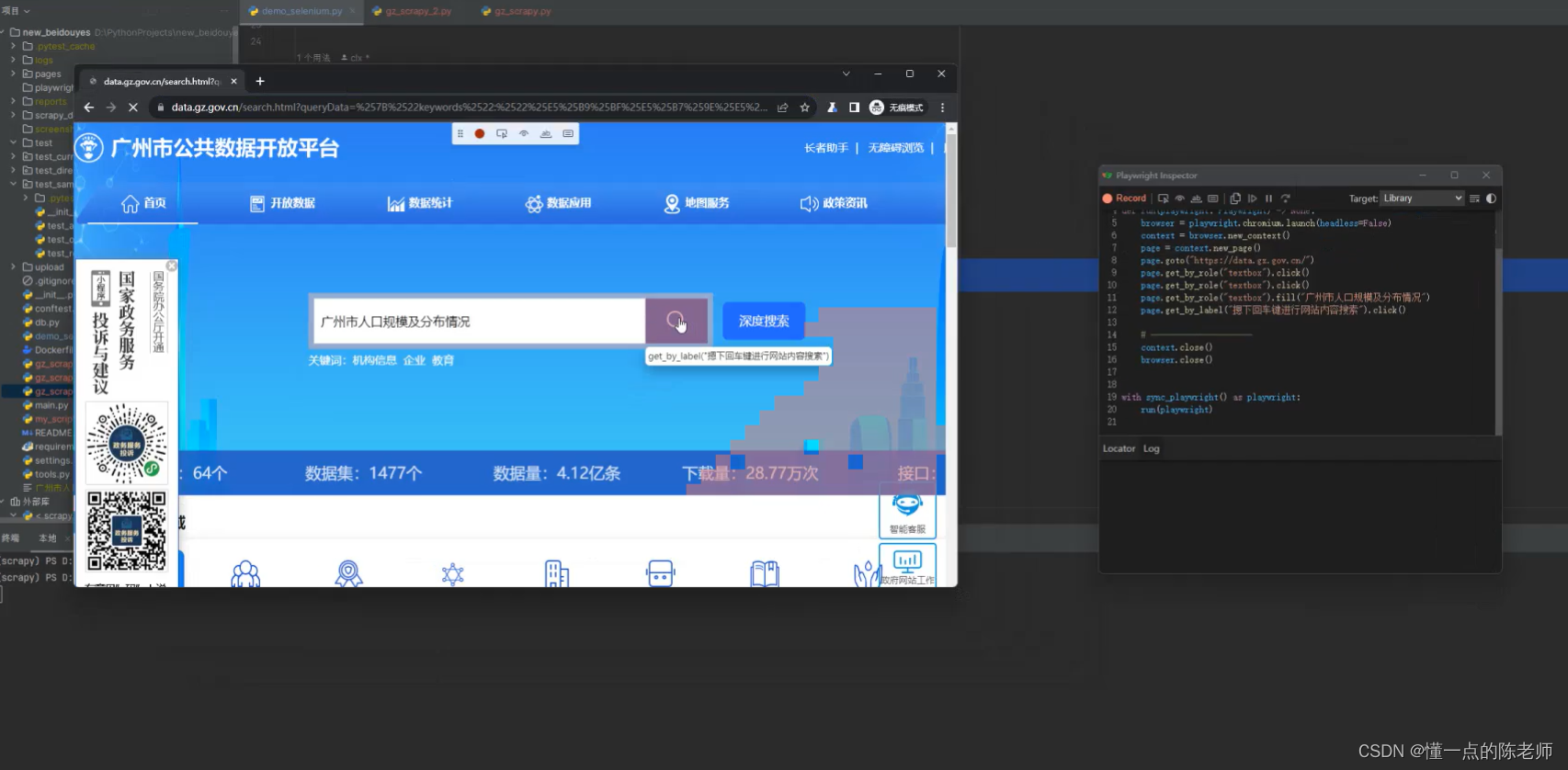
在搜索框输入”广州市人口规模及分布情况“,然后进入数据集,再选择文件下载,下载一个csv的文件,最后关闭录制,便可以看到gz_scrapy.py脚本已经编写完成。然后增加下载文件的复制保存功能,就完成脚本程序,整个过程非常简单便捷,完整代码如下。
python">from playwright.sync_api import Playwright, sync_playwright, expect
import shutil
import osdef run(playwright: Playwright) -> None:browser = playwright.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()page.goto("https://data.gz.gov.cn/")page.get_by_role("textbox").click()page.get_by_role("textbox").fill("广州市人口规模及分布情况")page.get_by_label("摁下回车键进行网站内容搜索").click()with page.expect_popup() as page1_info:page.get_by_role("link", name="广州市人口规模及分布情况", exact=True).click()page1 = page1_info.valuepage1.get_by_text("文件下载").click()with page1.expect_download() as download_info:page1.get_by_role("link", name="广州市人口规模及分布情况.csv_csv.zip 2023").click()download = download_info.value# 以上是录制好的脚本,下面增加保存文件的代码download_path = download.path()print(f"完成下载,临时存储: {download_path}")# 定义保存文件的路径save_path = "广州市人口规模及分布情况.csv"# 复制下载的文件到保存路径shutil.copy(download_path, save_path)# 检查文件是否已保存if os.path.exists(save_path):print(f"文件保存成功,保存到: {save_path}")else:print("文档保存失败")# ---------------------context.close()browser.close()
运行代码,能够直观感受到脚本启动和打开浏览器的速度比selenium快速。若把浏览器设置了不显示,执行速度会更快,只需要修改一行代码,把headless参数变成True,代码如下。
python">browser = playwright.chromium.launch(headless=True)
通过脚本录制,能够快速完成了自动下载“广州市人口规模及分布情况”的数据文件脚本。