1440 x 1080
0: 't'
1: 'i'
2: 'I'
3: '黄'中文显示异常:文末有解决方案

934 x 1408
0: '蓝朝路'
1: 'BaoanHwy'
2: 'GucunPark'
3: '宝安公路'
4: '顾村公园'
5: 'HutaiRd.'
6: '沪太路'
7: '东'中文显示异常:文末有解决方案
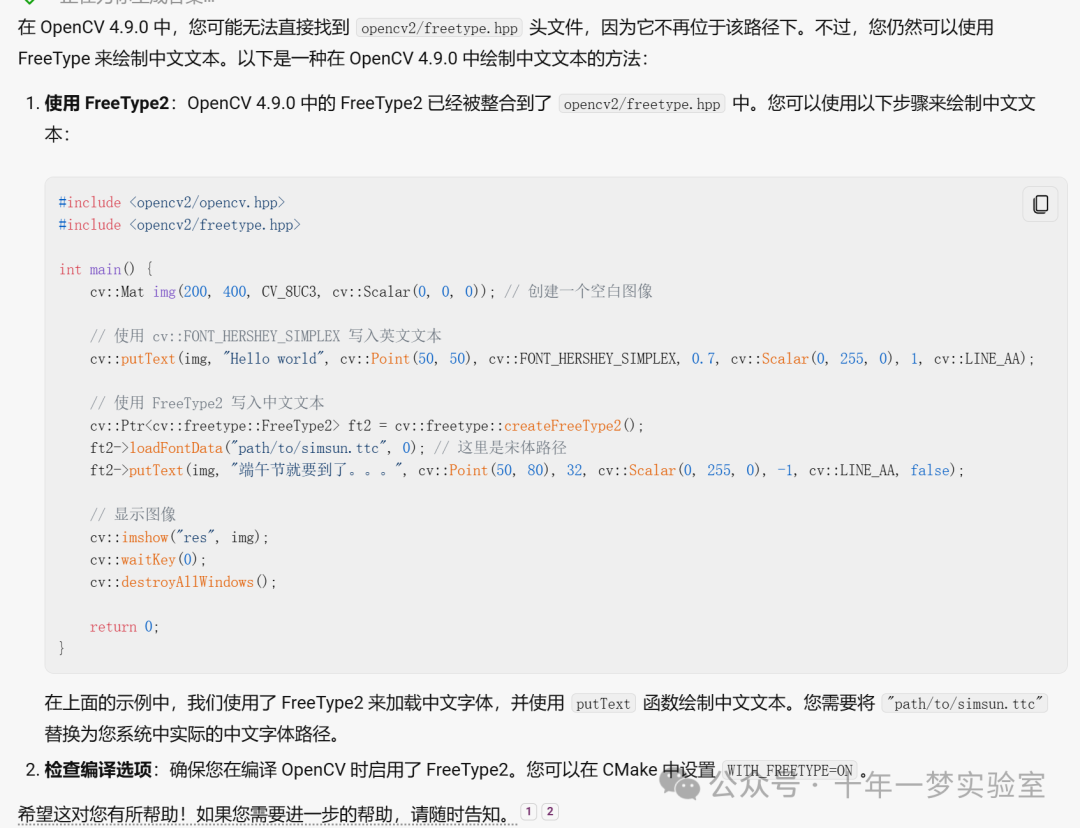
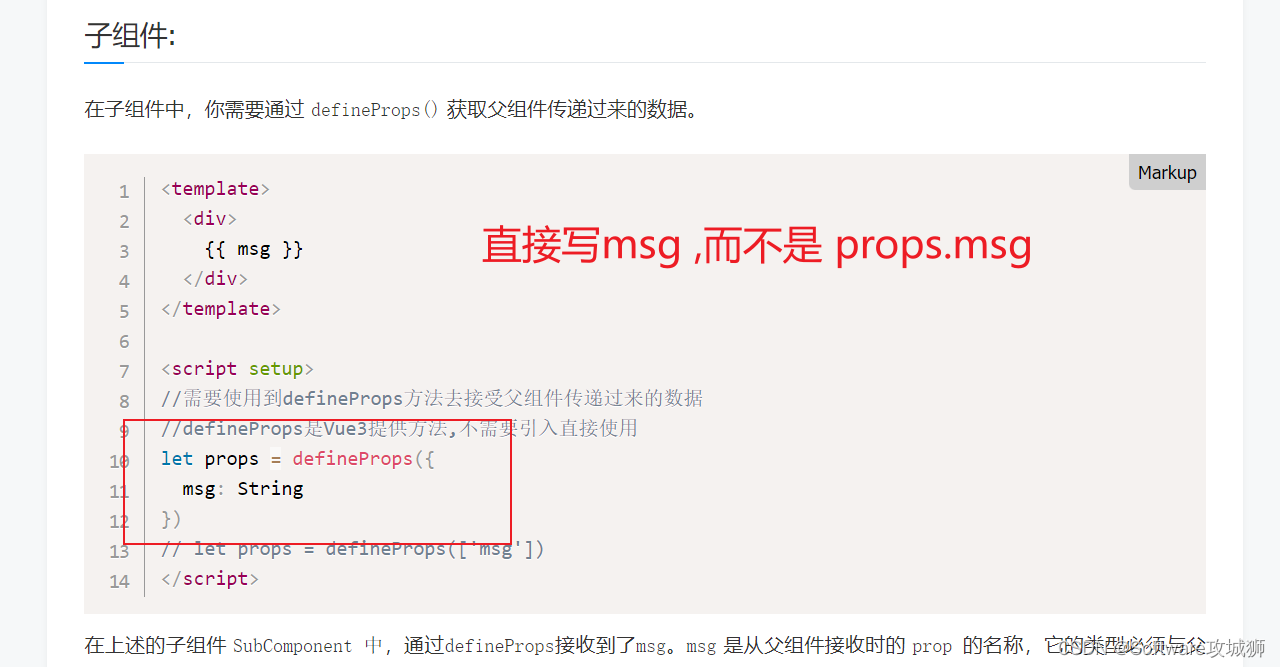
文件下载及参数设置参考:(文本识别、文本检测模型及参数)
TextRecognitionModel:
crnn.onnx:
url: https://drive.google.com/uc?export=dowload&id=1ooaLR-rkTl8jdpGy1DoQs0-X0lQsB6Fj
sha: 270d92c9ccb670ada2459a25977e8deeaf8380d3,
alphabet_36.txt: https://drive.google.com/uc?export=dowload&id=1oPOYx5rQRp8L6XQciUwmwhMCfX0KyO4b
parameter setting: -rgb=0;
description: The classification number of this model is 36 (0~9 + a~z).The training dataset is MJSynth.crnn_cs.onnx:
url: https://drive.google.com/uc?export=dowload&id=12diBsVJrS9ZEl6BNUiRp9s0xPALBS7kt
sha: a641e9c57a5147546f7a2dbea4fd322b47197cd5
alphabet_94.txt: https://drive.google.com/uc?export=dowload&id=1oKXxXKusquimp7XY1mFvj9nwLzldVgBR
parameter setting: -rgb=1;
description: The classification number of this model is 94 (0~9 + a~z + A~Z + punctuations).The training datasets are MJsynth and SynthText.crnn_cs_CN.onnx:
url: https://drive.google.com/uc?export=dowload&id=1is4eYEUKH7HR7Gl37Sw4WPXx6Ir8oQEG
sha: 3940942b85761c7f240494cf662dcbf05dc00d14
alphabet_3944.txt: https://drive.google.com/uc?export=dowload&id=18IZUUdNzJ44heWTndDO6NNfIpJMmN-ul
parameter setting: -rgb=1;
description: The classification number of this model is 3944 (0~9 + a~z + A~Z + Chinese characters + special characters).The training dataset is ReCTS (https://rrc.cvc.uab.es/?ch=12). TextDetectionModel:
- DB_IC15_resnet50.onnx:
url: https://drive.google.com/uc?export=dowload&id=17_ABp79PlFt9yPCxSaarVc_DKTmrSGGf
sha: bef233c28947ef6ec8c663d20a2b326302421fa3
recommended parameter setting: -inputHeight=736, -inputWidth=1280;
description: This model is trained on ICDAR2015, so it can only detect English text instances.- DB_IC15_resnet18.onnx:
url: https://drive.google.com/uc?export=dowload&id=1vY_KsDZZZb_svd5RT6pjyI8BS1nPbBSX
sha: 19543ce09b2efd35f49705c235cc46d0e22df30b
recommended parameter setting: -inputHeight=736, -inputWidth=1280;
description: This model is trained on ICDAR2015, so it can only detect English text instances.- DB_TD500_resnet50.onnx:
url: https://drive.google.com/uc?export=dowload&id=19YWhArrNccaoSza0CfkXlA8im4-lAGsR
sha: 1b4dd21a6baa5e3523156776970895bd3db6960a
recommended parameter setting: -inputHeight=736, -inputWidth=736;
description: This model is trained on MSRA-TD500, so it can detect both English and Chinese text instances.- DB_TD500_resnet18.onnx:
url: https://drive.google.com/uc?export=dowload&id=1sZszH3pEt8hliyBlTmB-iulxHP1dCQWV
sha: 8a3700bdc13e00336a815fc7afff5dcc1ce08546
recommended parameter setting: -inputHeight=736, -inputWidth=736;
description: This model is trained on MSRA-TD500, so it can detect both English and Chinese text instances.这段源代码是一个使用OpenCV库和深度学习模型检测和识别图像中文本的完整示例。下面简要介绍一下这个代码的主要部分。
包含头文件 & 命名空间: 引入了必要的头文件,包括OpenCV库和深度神经网络模块,以及使用标准和OpenCV命名空间。
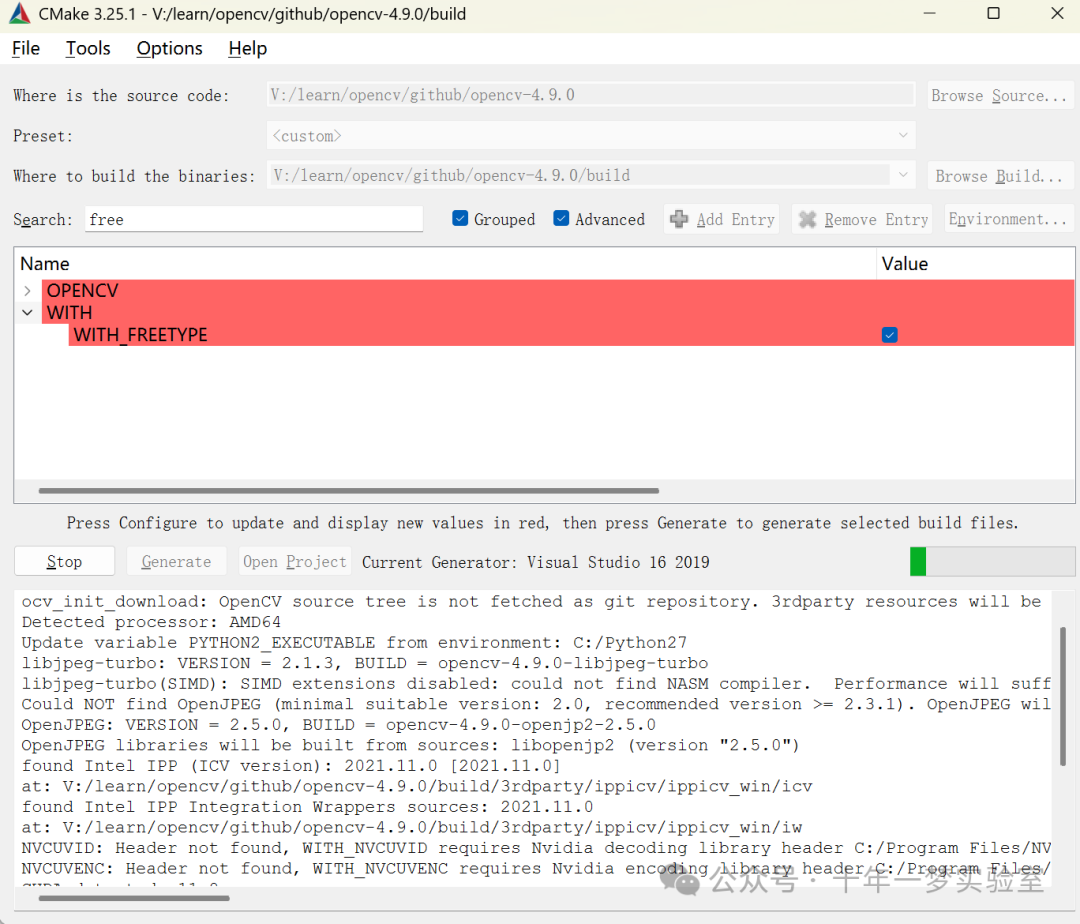
参数解析: 代码开始部分定义了一些参数,用于存储模型路径、输入图像大小、二值化阈值、多边形阈值,以及其他相关配置。这些参数可以通过命令行提供。
主函数 (main): 解析命令行参数后,加载文本检测模型和文本识别模型,检测模型使用DBNet算法,识别模型使用CRNN算法。
加载词汇: 为识别模型加载词汇表,词汇表通常是字符集文件。
参数设置: 为检测和识别模型设置输入参数,包括缩放比例、输入尺寸以及RGB均值等。
处理输入图像: 读取输入图像,执行文本检测,然后对检测到的文本区域进行识别。
绘制结果: 在图像上绘制检测到的文本多边形,并在每个检测到的文本区域旁边显示识别的结果。
fourPointsTransform 函数: 对于检测到的每个文本区域,使用透视变换校正倾斜的文本,以便在识别模型中使用。
sortPts 函数: 辅助函数用于排序点,可用于未来的功能扩展。
代码的功能总结:
从命令行接收输入参数,包括输入图像路径、检测和识别模型的路径,以及其他处理参数。
加载用于文本检测的DBNet模型和用于文本识别的CRNN模型。
对输入图像进行处理,使用检测模型识别文本区域。
对每个检测到的文本区域进行透视变换和裁剪。
使用识别模型对变换后的图块执行文本识别。
在原始图像上绘制检测到的文本区域,并显示识别的文本。
在屏幕上显示结果,并等待按键退出程序。
这段代码的核心在于集成OpenCV的DNN模块以及图像处理技术,实现从图像中自动检测和识别文本的流程。它可以作为一种端到端的文本检测和识别解决方案,在有文本的场景图片中自动识别出文字。
#include <iostream> // 引用输入输出库
#include <fstream> // 引用文件操作库
#include <opencv2/core.hpp> // 引用OpenCV核心功能库
#include <opencv2/imgproc.hpp> // 引用OpenCV图像处理库
#include <opencv2/highgui.hpp> // 引用OpenCV高层GUI库
#include <opencv2/dnn/dnn.hpp> // 引用OpenCV深度学习模块库using namespace cv; // 使用OpenCV命名空间
using namespace cv::dnn; // 使用OpenCV深度学习命名空间// 定义程序接收的命令行参数
std::string keys ="{ help h | | Print help message. }""{ inputImage i | td3.png| Path to an input image. Skip this argument to capture frames from a camera. }""{ detModelPath dmp |DB_TD500_resnet18.onnx | Path to a binary .onnx model for detection. ""Download links are provided in doc/tutorials/dnn/dnn_text_spotting/dnn_text_spotting.markdown}""{ recModelPath rmp |crnn_cs_CN.onnx | Path to a binary .onnx model for recognition. ""Download links are provided in doc/tutorials/dnn/dnn_text_spotting/dnn_text_spotting.markdown}""{ inputHeight ih |736| image height of the model input. It should be multiple by 32.}""{ inputWidth iw |736| image width of the model input. It should be multiple by 32.}""{ RGBInput rgb |1| 0: imread with flags=IMREAD_GRAYSCALE; 1: imread with flags=IMREAD_COLOR. }""{ binaryThreshold bt |0.3| Confidence threshold of the binary map. }""{ polygonThreshold pt |0.5| Confidence threshold of polygons. }""{ maxCandidate max |200| Max candidates of polygons. }""{ unclipRatio ratio |2.0| unclip ratio. }""{ vocabularyPath vp | alphabet_3944.txt | Path to benchmarks for evaluation. ""Download links are provided in doc/tutorials/dnn/dnn_text_spotting/dnn_text_spotting.markdown}";// 定义用于文档透视变换的函数
void fourPointsTransform(const Mat& frame, const Point2f vertices[], Mat& result);// 定义用于对点进行排序的函数
bool sortPts(const Point& p1, const Point& p2);int main(int argc, char** argv)
{// 解析命令行参数CommandLineParser parser(argc, argv, keys);parser.about("Use this script to run an end-to-end inference sample of textDetectionModel and textRecognitionModel APIs\n""Use -h for more information");if (argc == 0 || parser.has("help")){parser.printMessage();return 0;}// 提取命令行指定的参数float binThresh = parser.get<float>("binaryThreshold");float polyThresh = parser.get<float>("polygonThreshold");uint maxCandidates = parser.get<uint>("maxCandidate");String detModelPath = parser.get<String>("detModelPath");String recModelPath = parser.get<String>("recModelPath");String vocPath = parser.get<String>("vocabularyPath");double unclipRatio = parser.get<double>("unclipRatio");int height = parser.get<int>("inputHeight");int width = parser.get<int>("inputWidth");int imreadRGB = parser.get<int>("RGBInput");if (!parser.check()){parser.printErrors();return 1;}// 加载模型CV_Assert(!detModelPath.empty());TextDetectionModel_DB detector(detModelPath); // 加载文本检测模型detector.setBinaryThreshold(binThresh) // 设置二值化阈值.setPolygonThreshold(polyThresh) // 设置多边形阈值.setUnclipRatio(unclipRatio) // 设置非切割比例.setMaxCandidates(maxCandidates); // 设置最大候选数量CV_Assert(!recModelPath.empty());TextRecognitionModel recognizer(recModelPath); // 加载文本识别模型// 加载词汇表CV_Assert(!vocPath.empty());std::ifstream vocFile;vocFile.open(samples::findFile(vocPath));CV_Assert(vocFile.is_open());String vocLine;std::vector<String> vocabulary; // 创建用于存储词汇的向量while (std::getline(vocFile, vocLine)) {vocabulary.push_back(vocLine);}recognizer.setVocabulary(vocabulary);recognizer.setDecodeType("CTC-greedy");// 设置检测模型和识别模型的参数double detScale = 1.0 / 255.0;Size detInputSize = Size(width, height);Scalar detMean = Scalar(122.67891434, 116.66876762, 104.00698793);detector.setInputParams(detScale, detInputSize, detMean);double recScale = 1.0 / 127.5;Scalar recMean = Scalar(127.5);Size recInputSize = Size(100, 32);recognizer.setInputParams(recScale, recInputSize, recMean);// 创建窗口用于展示结果static const std::string winName = "Text_Spotting";// 载入输入图像Mat frame = imread(samples::findFile(parser.get<String>("inputImage")));std::cout << frame.size << std::endl;// 运行文本检测和识别推理std::vector< std::vector<Point> > detResults; // 存储检测结果detector.detect(frame, detResults); // 运行文本检测Mat frame2 = frame.clone(); // 克隆原图用于绘制结果if (detResults.size() > 0) {// 文本识别Mat recInput;if (!imreadRGB) {cvtColor(frame, recInput, cv::COLOR_BGR2GRAY); // 转换图像到灰度格式} else {recInput = frame;}std::vector< std::vector<Point> > contours;for (uint i = 0; i < detResults.size(); i++){const auto& quadrangle = detResults[i];CV_CheckEQ(quadrangle.size(), (size_t)4, ""); // 确保每个检测到的形状是四边形contours.emplace_back(quadrangle);std::vector<Point2f> quadrangle_2f;for (int j = 0; j < 4; j++)quadrangle_2f.emplace_back(quadrangle[j]);// 执行透视变换和裁剪Mat cropped;fourPointsTransform(recInput, &quadrangle_2f[0], cropped);std::string recognitionResult = recognizer.recognize(cropped); // 识别文本std::cout << i << ": '" << recognitionResult << "'" << std::endl;putText(frame2, recognitionResult, quadrangle[3], FONT_HERSHEY_SIMPLEX, 1, Scalar(0, 0, 255), 2); // 在图像上绘制识别结果}polylines(frame2, contours, true, Scalar(0, 255, 0), 2); // 绘制检测到的文本轮廓} else {std::cout << "No Text Detected." << std::endl;}imshow(winName, frame2); // 显示结果waitKey(); // 等待用户按键return 0; // 程序结束
}// 文档透视变换函数定义
void fourPointsTransform(const Mat& frame, const Point2f vertices[], Mat& result)
{const Size outputSize = Size(100, 32); // 设置输出图像尺寸// 定义透视变换的目标顶点Point2f targetVertices[4] = {Point(0, outputSize.height - 1),Point(0, 0),Point(outputSize.width - 1, 0),Point(outputSize.width - 1, outputSize.height - 1)};// 获取透视变换矩阵Mat rotationMatrix = getPerspectiveTransform(vertices, targetVertices);// 应用透视变换warpPerspective(frame, result, rotationMatrix, outputSize);#if 0imshow("roi", result); // 可以选择展示变换后的区域waitKey();
#endif
}// 点排序函数定义
bool sortPts(const Point& p1, const Point& p2)
{return p1.x < p2.x; // 按照X坐标排序
}