相关文章
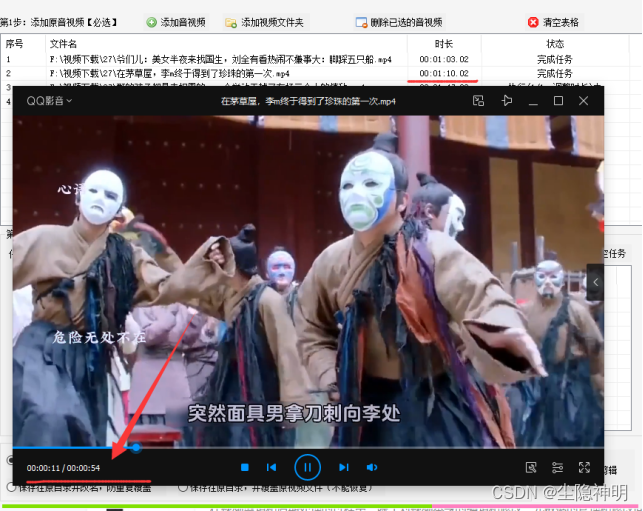
视频剪辑图文实例:一键操作,轻松实现视频批量片头片尾减时
视频剪辑是现代媒体制作中不可或缺的一环,而批量处理视频更是许多专业人士和爱好者的常见需求。在剪辑过程中,调整视频的片头片尾时长可以显著提升视频的质量和观感。本文将通过图文实例的方式,向您展示如何一键操作,轻松实现视频…

墨刀原型工具-小白入门篇
1.引言
作为一个小白,要怎么在短时间内快速学会原型设计?
“时间紧,任务重”,如何在短时间内理解、掌握一个原型设计工具的使用?据同事们的推荐,选择了入手“墨刀”这个软件!
2.软件介绍
墨…

鸿蒙内核源码分析(时间管理篇) | 谁是内核基本时间单位
时间概念太重要了,在鸿蒙内核又是如何管理和使用时间的呢?
时间管理以系统时钟 g_sysClock 为基础,给应用程序提供所有和时间有关的服务。
用户以秒、毫秒为单位计时.操作系统以Tick为单位计时,这个认识很重要. 每秒的tick大小很大程度上决…

TiDB数据库 使用tiup 缩容遇到的tikv处于下线中状态无法转为tombstone状态
官方的缩容文档
https://docs.pingcap.com/zh/tidb/stable/scale-tidb-using-tiup
论坛地址
https://tidb.net/
问题:使用tiup 缩容遇到的tikv处于下线中状态无法转为tombstone状态
解决方法
1.缩容 tiup cluster scale-in --node 10.0.1.5:20160 2.查看 tiup…

Hive内部表、外部表
Hive内部表、外部表
1. 内部表(Managed Table):
内部表是由Hive完全管理的表,包括数据和元数据。当你删除内部表时,Hive会同时删除表的数据和元数据。内部表的数据存储在Hive指定的默认位置(通常是HDFS上…

经典的设计模式和Python示例(一)
目录
一、工厂模式(Factory Pattern) 二、单例模式(Singleton Pattern)
三、观察者模式(Observer Pattern) 一、工厂模式(Factory Pattern) 工厂模式(Factory Pattern…

关于MS-DOS时代的回忆
目录
一、MS-DOS是什么?
二、MS-DOS的主要功能有哪些?
三、MS-DOS的怎么运行的?
四、微软开源MS-DOS源代码
五、高手与漂亮女同学 一、MS-DOS是什么? MS-DOS(Microsoft Disk Operating System)是微软公…