什么是分桶表?
分桶是将数据集分解成更容易管理的若干部分的一个技术,是比分区更为细粒度的数据范围划分。
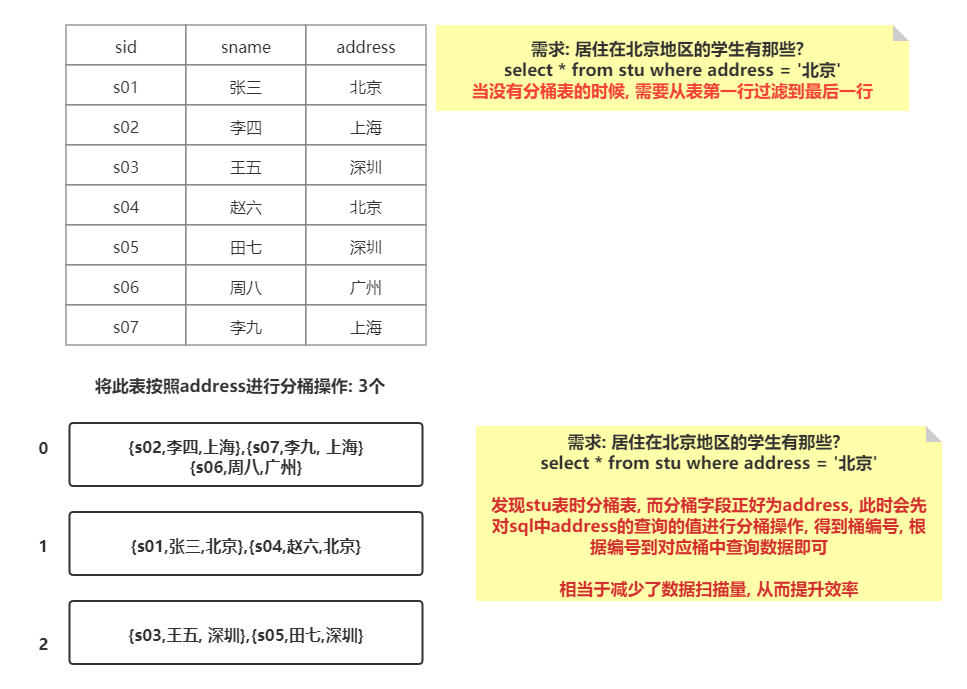
主要是用于分文件的,在建表的时候,指定按照那些字段执行分桶操作,并可以设置需要分多少个桶,当插入数据的时候,执行MR的分区的操作,将数据分散各个分区(hive分桶)中,默认分发方案: hash 取模
如何构建一个分桶表呢?
sql">create table test_buck(id int,name string)
clustered by(id) sorted by (id asc) into 6 buckets --创建分桶表的sql
row format delimited fields terminated by '\t';CLUSTERED BY来指定划分桶所用列;
SORTED BY对桶中的一个或多个列进行排序;
into 6 buckets指定划分桶的个数。
如何向分桶表添加数据呢?
标准格式:
1)创建一张与分桶表一样的临时表,唯一区别这个表不是一个分桶表2)将数据加载到这个临时表中
3)通过 insert into + select语句将数据导入到分桶表中
说明: sqoop不支持直接对分桶表导入数据
分桶是如何提高效率的?
在分区数量过于庞大以至于可能导致文件系统崩溃时,或数据集找不到合理的分区字段时,我们就需要使用分桶来解决问题了。
分区中的数据可以被进一步拆分成桶,不同于分区对列直接进行拆分,桶往往使用列的哈希值对数据打散,并分发到各个不同的桶中从而完成数据的分桶过程。
注意,hive使用对分桶所用的值进行hash,并用hash结果除以桶的个数做取余运算的方式来分桶,保证了每个桶中都有数据,但每个桶中的数据条数不一定相等。
如果另外一个表也按照同样的规则分成了一个个小文件。两个表join的时候,就不必要扫描整个表,只需要匹配相同分桶的数据即可,从而提升效率。
在数据量足够大的情况下,分桶比分区有更高的查询效率。
分桶和分区的区别:
- 分桶对数据的处理比分区更加细粒度化:分区针对的是数据的存储路径;分桶针对的是数据文件;
- 分桶是按照列的哈希函数进行分割的,相对比较平均;而分区是按照列的值来进行分割的,容易造成数据倾斜;
- 分桶和分区两者不干扰,可以把分区表进一步分桶。
分桶表有什么作用呢?
1.进行数据采样
在真实的大数据分析过程中,由于数据量较大,开发和自测的过程比较慢,严重影响系统的开发进度。此时就可以使用分桶来进行数据采样。采样使用的是一个具有代表性的查询结果而不是全部结果,通过对采样数据的分析,来达到快速开发和自测的目的,节省大量的研发成本。
2.提升查询的效率(单表|多表)
单表查询时,基于hash值进行分桶的机制下查询时可直接锁定对应桶,不需要全局扫描,节省查询时间,提高效率。
如何进行数据采样?
采样函数:tablesample(bucket x out of y on column) ;
sql">select * from table tablesample(bucket x out of y on column)放置位置:紧紧跟在from后面,如果表有别名,放在别名前面。
说明:
x: 从第几个桶开始进行采样
y: 抽样比例(总桶数/y=分多少个桶)
column: 分桶的字段, 可以省略的注意:
x 不能大于 y
y 必须是表的分桶数量的倍数或者因子案例:
1) 假设 A表有10个桶, 请分析, 下面的采样函数, 会将那些桶抽取出来
tablesample(bucket 2 out of 5 on xxx)会抽取几个桶呢?总桶 / y = 分桶数量 2
抽取第几个编号的桶? (x+y)
2,7
2) 假设 A表有20个桶, 请分析, 下面的采样函数, 会将那些桶抽取出来
tablesample(bucket 4 out of 4 on xxx)会抽取几个桶呢?总桶 / y = 分桶数量 5
抽取第几个编号的桶? (x+y)
4,8,12,16,20
如何提升查询的效率?(多表查询)
思考: 当多表进行join的时候, 如何提升join效率呢?
小表和大表:
在进行join的时候, 将小表的数据放置到每一个读取大表的mapTask的内存中, 让mapTask每读取一次大表的数据都和内存中小表的数据进行join操作, 将join上的结果输出到reduce端即可, 从而实现在map端完成join的操作
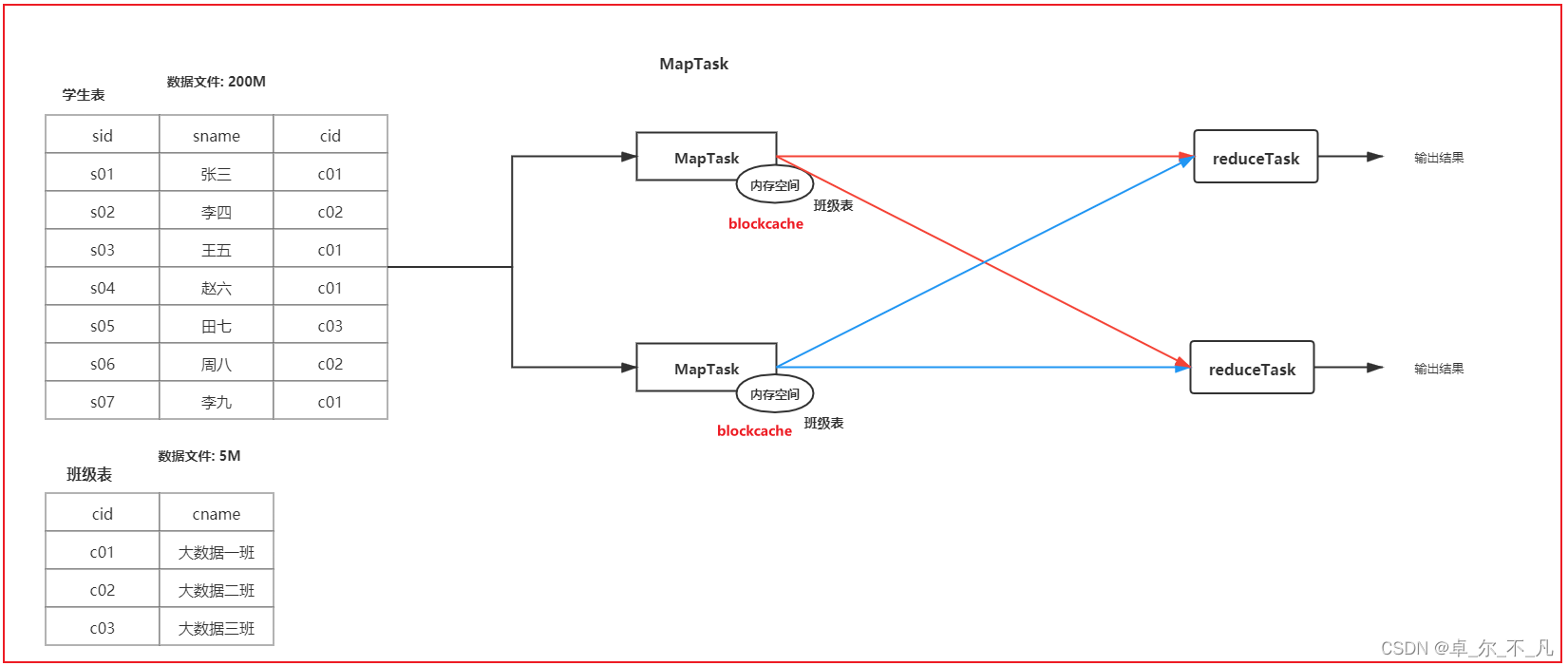
如何开启map Join?
set hive.auto.convert.join=true; -- 是否开启map Join
set hive.auto.convert.join.noconditionaltask.size=512000000; -- 设置小表最大的阈值(设置block cache 缓存大小)
map Join 不限制任何表
为什么不采用reduce join呢?
1) 可能出现数据倾斜的问题
2) 导致reduce压力较大
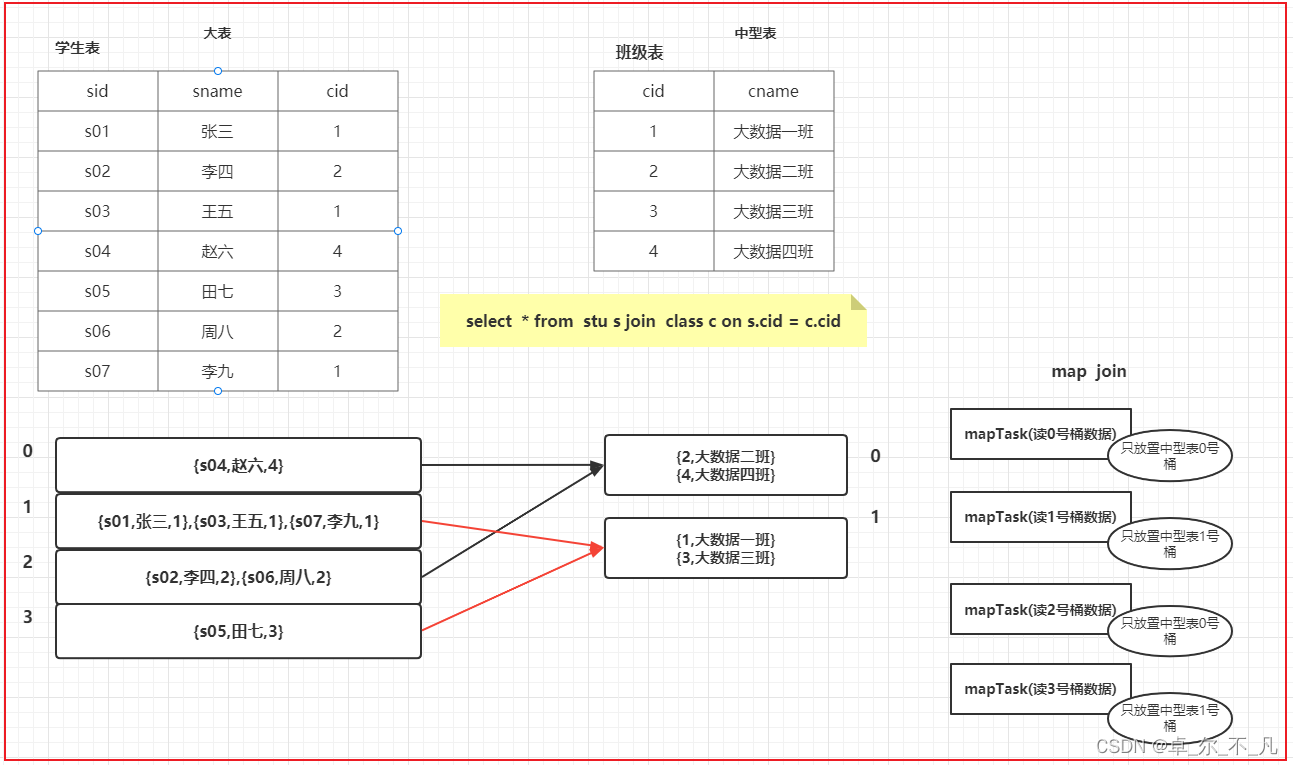
中型表和大表:
中型表: 与小表相比 大约是小表3~10倍左右
解决方案:
1.能提前过滤就提前过滤掉(一旦提前过滤后,会导致中型表的数据量会下降,有可能达到小表阈值)
2.如果join的字段值有大量的null,可以尝试添加随机数(保证各个reduce接收数据量差不多的,减少数据倾斜问题)
3.基于分桶表的: bucket map join
bucket map join条件
1) set hive.optimize.bucketmapjoin = true;
2) 一个表的bucket数是另一个表bucket数的整数倍
3) bucket列 == join列
4) 必须是应用在map join的场景中
注意:如果表不是bucket的,则只是做普通join
在这种机制下减少中型表的数据量,将对应的join条件的数据放到内存中进行关联,map join还是在内存中进行,只不过对应的数据量减少了。
大表和大表:
解决方案:
1. 能提前过滤就提前过滤掉(减少join之间的数量, 提升reduce执行效率)。
2. 如果join的字段值有大量的null, 可以尝试添加随机数(保证各个reduce接收数据量差不多的, 减少数据倾斜问题)。
3. SMB Map join (sort merge bucket map join)
sort merge bucket map join
实现SMB map join的条件要求:
1) 一个表的bucket数等于另一个表bucket数(分桶数量是一致)
2) bucket列 == join列 == sort 列
3) 必须是应用在bucket map join的场景中
4) 开启相关的参数:
-- 开启SMB map join
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
--写入数据强制排序
set hive.enforce.sorting=true;
set hive.optimize.bucketmapjoin.sortedmerge = true; -- 开启自动尝试SMB连接