🚀 【考纲要求】哈夫曼树和哈夫曼编码、并查集
🚀 第六章第一节内容请查看此链接 树的基本概念
🚀 第六章第二节内容请查看此链接 二叉树的定义、四种特殊的二叉树和二叉树的存储结构
🚀 第六章第三节内容请查看此链接 二叉树的遍历、线索化
🚀 第六章第四节内容请查看此链接 树和森林
五、树与二叉树的应用
在学习哈夫曼树之前,我们需要先直到几个名词的定义:
- 路径长度: 从一个节点到另外一个节点所经过的路径数目。
- 节点的带权路径长度: 从一个节点到另外一个节点所经过的路径数目*该节点的权值。
- 树的带权路径长度: 一个树中所有叶子节点的自身的权值*到达根节点所需要的路径数目之和为数的带权路径长度。

如上图所示,其该根节点到权值为10的叶子节点的路径长度就为3,权值为10的叶子节点的带权路径长度就为 3 ∗ 10 = 30 3*10=30 3∗10=30;这个数的带权路径长度为 4 ∗ 1 + 5 ∗ 3 + 1 ∗ 3 + 10 ∗ 3 + 3 ∗ 3 4*1+5*3+1*3+10*3+3*3 4∗1+5∗3+1∗3+10∗3+3∗3。
5.1哈夫曼树和哈夫曼树编码
①哈夫曼树的定义
而所谓的哈夫曼树就是要让带权路径长度(WPL)最小,也被称为最优二叉树。
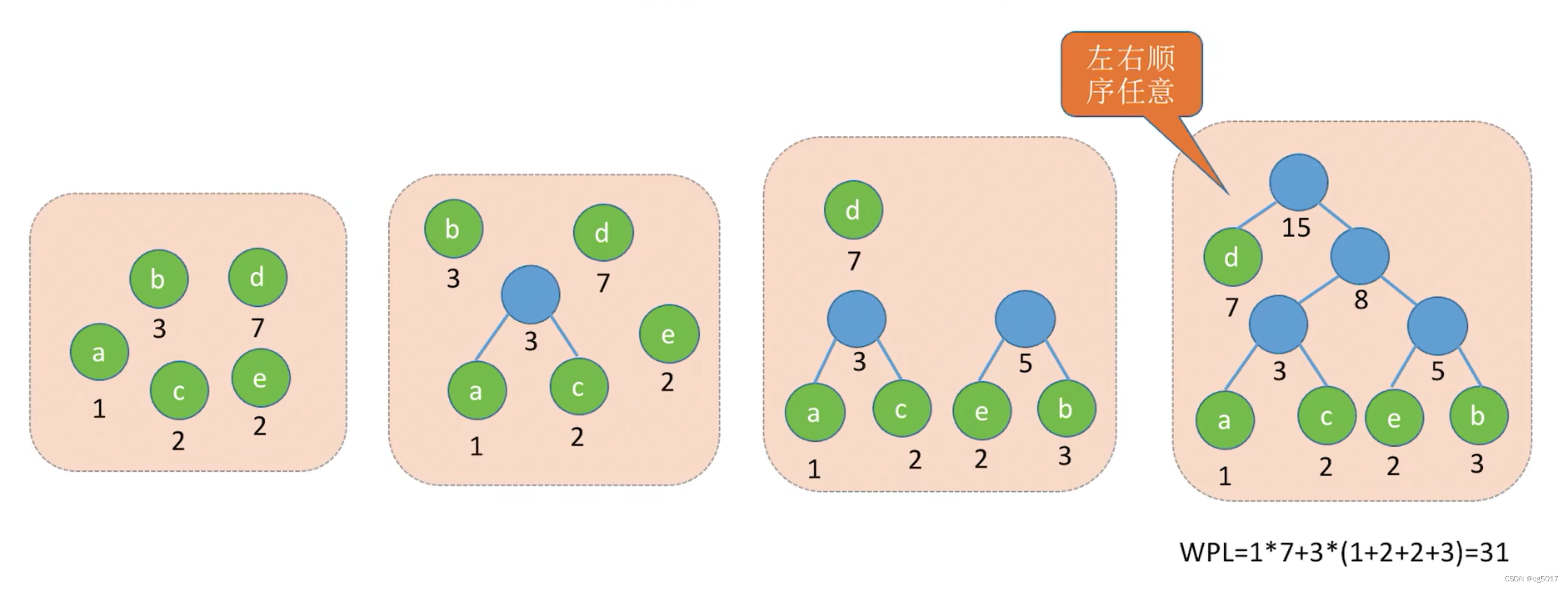
即让 W P L = ∑ i = 1 n w i l i WPL=\sum\limits_{i=1}^{n}w_{i}l_{i} WPL=i=1∑nwili最小。来计算以下以下四棵树树的WPL值。
- 1 ∗ 2 + 3 ∗ 2 + 4 ∗ 2 + 5 ∗ 2 = 26 1*2+3*2+4*2+5*2=26 1∗2+3∗2+4∗2+5∗2=26 第一个带权路径长度为26
- 1 ∗ 3 + 3 ∗ 3 + 4 ∗ 2 + 5 ∗ 1 = 25 1*3+3*3+4*2+5*1=25 1∗3+3∗3+4∗2+5∗1=25 第二个带权路径长度为25
- 3 ∗ 3 + 1 ∗ 3 + 4 ∗ 2 + 5 ∗ 1 = 25 3*3+1*3+4*2+5*1=25 3∗3+1∗3+4∗2+5∗1=25 第三个带权路径长度为25
- 1 ∗ 1 + 5 ∗ 3 + 4 ∗ 3 + 3 ∗ 2 = 34 1*1+5*3+4*3+3*2=34 1∗1+5∗3+4∗3+3∗2=34 第四个带权路径长度为34

由于第二个和第三个的带权路径长度是最小的,所以将其称为哈夫曼树。
②构造哈夫曼树
实际中,我们该如何构造哈夫曼树呢,其实哈夫曼的思想是让WPL的值最小,也就是我们可以通过让权值大的尽量的在上方,权值小的尽量让其在下方,那么这样就可以让WPL最小,所有在构建哈夫曼树的时候,我们也可以根据这个思想进行构造。
如下图所示,对于给定5个带权节点构建哈夫曼树
- 选择其中两个权值最小的成为兄弟,因为我们想让权值小的尽量在下方;所以这里选择了ac成为了兄弟,他们组合成为了权值为3的节点。
- 接下去继续选择最小的节点,即选择合成的蓝色权值为3的节点和e成为兄弟节点;当然下图所示选择的是b和e节点,这也是可以的,只要选中其中两个最小的合成就行。
- 此时最小的是两个蓝色的,即让其合成为8。
- 现在最小的为d和8,即再将其合成为15,此时一个哈夫曼树就构建完成了,其WPL最小的带权路径长度为31.
构建完成的哈夫曼树的性质
- n n n个节点构建哈夫曼树,最后会有 2 n − 1 2n-1 2n−1个节点。
- 添加了 n − 1 n-1 n−1个节点。
- 每个初始节点都成为了叶子节点,同时构建完成的哈夫曼树无度为1的节点。
③哈夫曼编码
哈夫曼编码具有重要意义,它可以按着权值进行编码,从而可以使用短的比特位数传递更多的信息,以一个例子讲述哈夫曼编码。
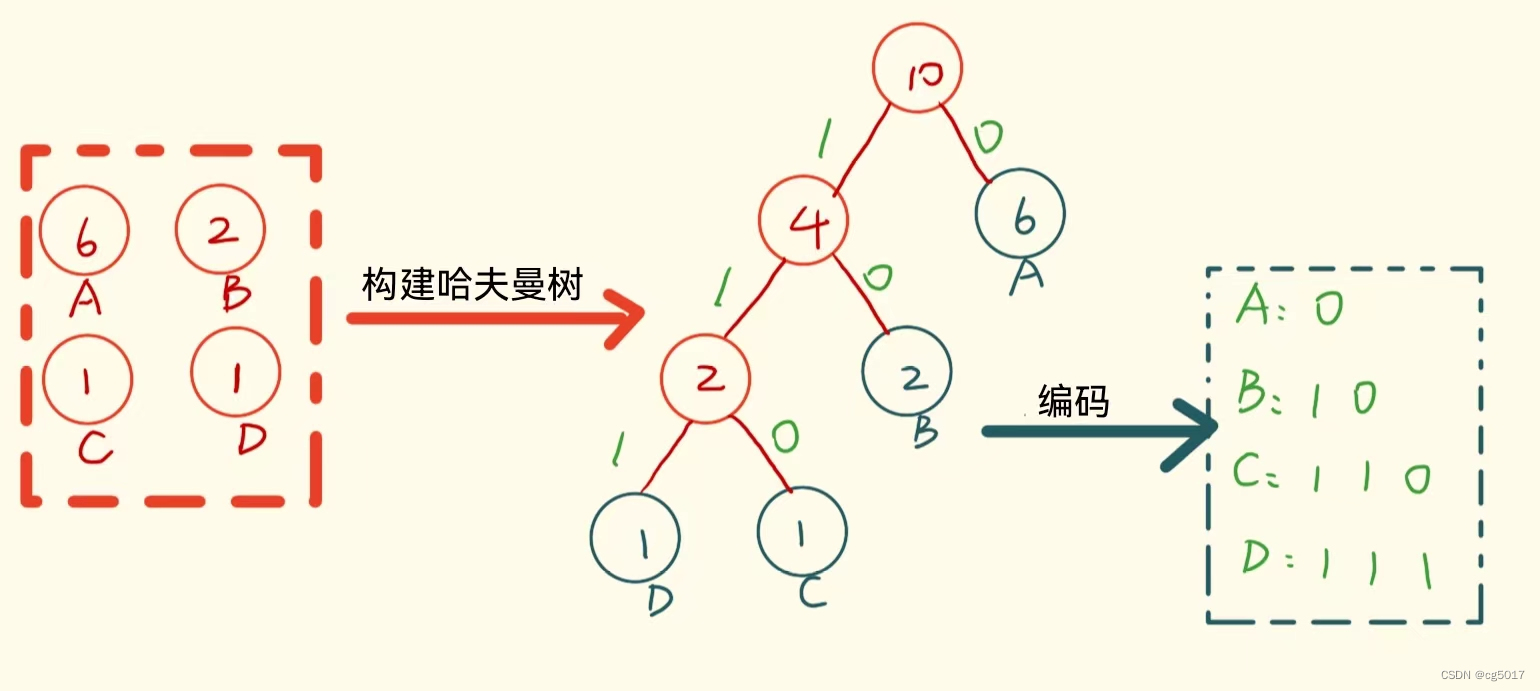
假设老王想向小王传递6个A,2个B,1个C,1个D。
- 按着传统的方式,我们可以将ABCD进行编码,A–00,B–01,C–10,D–11;这样话,老王向小王传递消息的话就需要传递10*2=20bit的数据就可以。
- 使用哈夫曼编码,首先构建哈夫曼树,构建好的哈夫曼树如下,然后在构建好的哈夫曼树左右路径都写上1和0,对于A来说,路径为0,所以哈夫曼编码为1;对于B来说,其路径是10,所以编码为10;依次类推就可以得到每个字母的哈夫曼编码,此时计算一下要传递6个A,2个B,1个C,1个D需要多少个bit位。 1 ∗ 7 + 2 ∗ 2 + 3 + 3 = 17 1*7+2*2+3+3=17 1∗7+2∗2+3+3=17,只需要17位就可以传递。通过哈夫曼编码压缩了编码长度的。
5.2并查集
①并查集的概念
并查集就是一种简单的集合表示,对集合实现并集操作和查找操作。
Initial(s)初始化操作,将每一个元素都初始化为一个元素一个集合。Union(s,root1,root2)将集合S中的子集合root1和子集合root2合并成为一个集合。Find(s,x)在s中寻找其在哪个子集合。
②并查集的存储结构
对于集合的存储我们是采用树来进行存储的,因为集合之间的不相交性和森林中每一个子树非常的类似,所以我们就可以采用存储森林的存储方式来存储集合,首先来回顾一下是如何存储森林的。
如何存储森林?
对于如下一个森林,有三棵树,这三棵树互不相交,可以采用双亲表示法来存储该森林,当然也可以使用孩子表示法和孩子兄弟表示法来存储该森林。

使用双亲表示法存储该森林
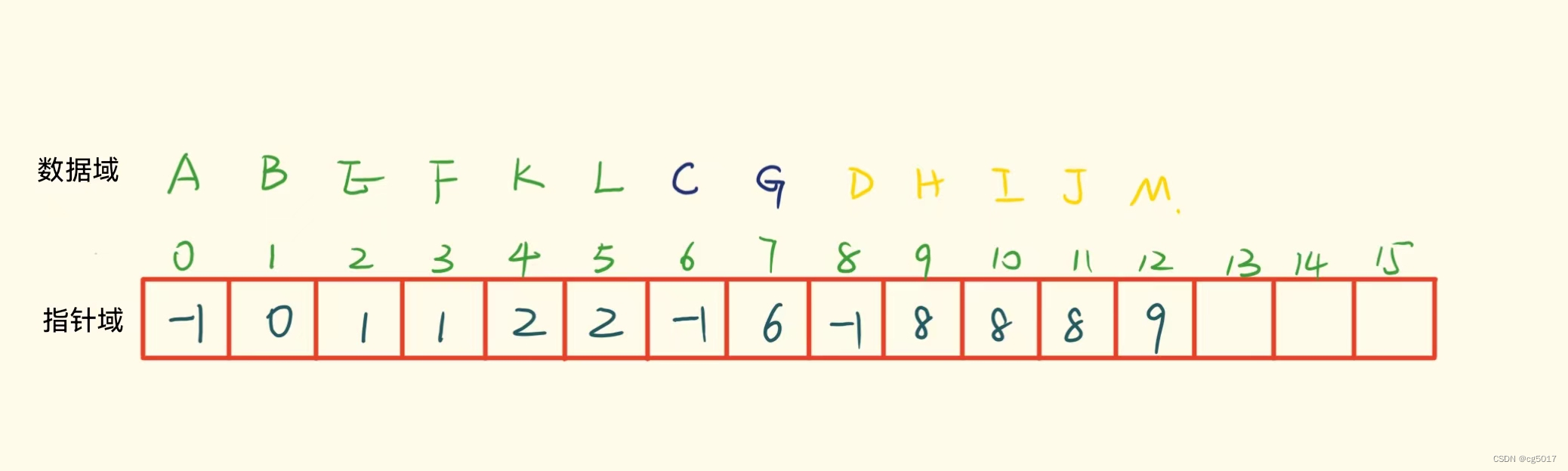
通过双亲表示法,我们很好的将森林进行了存储,而我们的集合其实也就可以采用这种存储方式,使用双亲表示法来存储。对于上图,我们就可以将其看作为三个互不相交的集合,对于想要查询某个节点属于哪个集合的话,其实我们就只需不断的向上查找,直到根节点,就可以得到属于哪个集合,例如查询M节点属于哪个集合,M的指针域为9,9处的指针域不为-1,即不为根节点,继续往上,9处的指针域为8,8处的指针域为-1,所以8处的节点为根节点,8处的数据域为D,就可以知道该元素为橙色的集合。
通过上述查的操作,我们也不难发现,其实所谓的查操作就是不断查找双亲节点的操作,在前一节我们学习了三种存储树和森林的方式:双亲表示法,孩子表示法,孩子双亲表示法三种,由于不断的需要查询双亲操作,所以选用双亲表示法来存储集合。
而对于并的操作其实是很好实现的,若要将绿色集合和紫色集合合并成为一个集合,其实只需改变紫色集合根节点的指针域,让其指向绿色集合的根节点,就可以完成并的操作;同样的也可以改变绿色集合的指针域,使其指向紫色的集合从而完成并的操作。
③并查集的实现
#include<stdio.h>
#define size 100typedef char elementType;typedef struct Setnode {elementType data; //数据域int parent; //指针域
}Setnode;// 初始化集合
void Initial(Setnode set[]) {int i = size-1; //标号从size-1开始while (i >= 0) {set[i].parent = -1;i--;}
}int main() {Setnode set[size]; //set[0].data = 'A'; set[1].data = 'B'; set[2].data = 'E'; set[3].data = 'F';set[4].data = 'K'; set[5].data = 'L'; set[6].data = 'C'; set[7].data = 'G';set[8].data = 'D'; set[9].data = 'H'; set[10].data = 'I'; set[11].data = 'J';set[12].data = 'M'; Initial(set);for (int i = 0; i <= 12; i++) {printf("数据:%c 指针:%d\n", set[i].data, set[i].parent);}return 0;
}

为构建上述绿紫黄三个集合,先将其都初始化,继续划分集合
set[0].parent = -1; set[1].parent = 0; set[2].parent = 1; set[3].parent = 1;
set[4].parent = 2; set[5].parent = 2; set[6].parent = -1; set[7].parent = 6;
set[8].parent = -1; set[9].parent = 8; set[10].parent = 8; set[11].parent = 8;
set[12].parent = 9;
printf("\n");
for (int i = 0; i <= 12; i++) {printf("数据:%c 指针:%d\n", set[i].data, set[i].parent);
}

此时上述绿紫黄三个集合构建完成,并使用了双亲表示法将其存储了,现在进一步实现并操作和查操作;
查操作:
#include<stdio.h>
#define size 100typedef char elementType;typedef struct Setnode {elementType data; //数据域int parent; //指针域
}Setnode;// 初始化集合
void Initial(Setnode set[]) {int i = size-1; //标号从size-1开始while (i >= 0) {set[i].parent = -1;i--;}
}//查操作
int Find(Setnode set[], elementType data) {int i = 0;while (set[i].data != data && i<size) {i++;}if (set[i].data == data) {while (set[i].parent >= 0) {i = set[i].parent;}return i;}return -1;
}int main() {Setnode set[size]; //set[0].data = 'A'; set[1].data = 'B'; set[2].data = 'E'; set[3].data = 'F';set[4].data = 'K'; set[5].data = 'L'; set[6].data = 'C'; set[7].data = 'G';set[8].data = 'D'; set[9].data = 'H'; set[10].data = 'I'; set[11].data = 'J';set[12].data = 'M'; Initial(set);set[0].parent = -1; set[1].parent = 0; set[2].parent = 1; set[3].parent = 1;set[4].parent = 2; set[5].parent = 2; set[6].parent = -1; set[7].parent = 6;set[8].parent = -1; set[9].parent = 8; set[10].parent = 8; set[11].parent = 8;set[12].parent = 9;printf("\n");for (int i = 0; i <= 12; i++) {printf("数据:%c 指针:%d\n", set[i].data, set[i].parent);}printf("元素M所属于的集合的根节点的元素为%c\n", set[Find(set, 'M')].data);printf("元素B所属于的集合的根节点的元素为%c\n", set[Find(set, 'B')].data);return 0;
}

并操作:
#include<stdio.h>
#define size 100typedef char elementType;typedef struct Setnode {elementType data; //数据域int parent; //指针域
}Setnode;// 初始化集合
void Initial(Setnode set[]) {int i = size-1; //标号从size-1开始while (i >= 0) {set[i].parent = -1;i--;}
}//查操作
int Find(Setnode set[], elementType data) {int i = 0;while (set[i].data != data && i<size) {i++;}if (set[i].data == data) {while (set[i].parent >= 0) {i = set[i].parent;}return i;}return -1;
}//并操作
void Union(Setnode set[], int root1, int root2) {if (root1 != root2) {set[root1].parent = root2;}
}int main() {Setnode set[size]; //set[0].data = 'A'; set[1].data = 'B'; set[2].data = 'E'; set[3].data = 'F';set[4].data = 'K'; set[5].data = 'L'; set[6].data = 'C'; set[7].data = 'G';set[8].data = 'D'; set[9].data = 'H'; set[10].data = 'I'; set[11].data = 'J';set[12].data = 'M'; Initial(set);set[0].parent = -1; set[1].parent = 0; set[2].parent = 1; set[3].parent = 1;set[4].parent = 2; set[5].parent = 2; set[6].parent = -1; set[7].parent = 6;set[8].parent = -1; set[9].parent = 8; set[10].parent = 8; set[11].parent = 8;set[12].parent = 9;printf("\n");for (int i = 0; i <= 12; i++) {printf("数据:%c 指针:%d\n", set[i].data, set[i].parent);}printf("元素M所属于的集合的根节点的元素为%c\n", set[Find(set, 'M')].data);printf("元素B所属于的集合的根节点的元素为%c\n", set[Find(set, 'B')].data);Union(set, 8, 0); //将绿色和橙色集合合并printf("绿色和橙色集合合并后\n");printf("元素M所属于的集合的根节点的元素为%c\n", set[Find(set, 'M')].data);printf("元素B所属于的集合的根节点的元素为%c\n", set[Find(set, 'B')].data);return 0;
}

合并之前,元素M属于橙色集合,元素B属于绿色集合,将绿色集合和橙色集合合并后,元素M和元素B都属于绿色集合了。
④并查集的优化
为什么需要优化呢,是因为查询操作的最坏的时间复杂度是O(N),N是树结构的深度,若树的深度不断增加,可能就会导致查询操作较慢,而在Union操作的时候,就可能会导致树的深度增加,若是大树向小数并入的话就会造成合并完成后的树森度增加,所以我们可以优化Union操作,使其每一步的Union操作都是小树并入大树,这样就可以避免掉树的深度增加。
优化后的代码如下,只需要加个判断即可。
#include<stdio.h>
#define size 100typedef char elementType;typedef struct Setnode {elementType data; //数据域int parent; //指针域
}Setnode;// 初始化集合
void Initial(Setnode set[]) {int i = size-1; //标号从size-1开始while (i >= 0) {set[i].parent = -1;i--;}
}//查操作
int Find(Setnode set[], elementType data) {int i = 0;while (set[i].data != data && i<size) {i++;}if (set[i].data == data) {while (set[i].parent >= 0) {i = set[i].parent;}return i;}return -1;
}//并操作
void Union(Setnode set[], int root1, int root2) {if (root1 != root2) {set[root1].parent = root2;}
}void GoodUnion(Setnode set[], int root1, int root2) {if (root1 == root2) {return;}else {if (set[root1].parent > set[root2].parent) { //root1的值(负值)大,说明root1是小树//小树并入大树set[root2].parent = set[root2].parent + set[root1].parent;set[root1].parent = root2;}else {set[root1].parent = set[root2].parent + set[root1].parent;set[root2].parent = root1;}}
}int main() {Setnode set[size]; //set[0].data = 'A'; set[1].data = 'B'; set[2].data = 'E'; set[3].data = 'F';set[4].data = 'K'; set[5].data = 'L'; set[6].data = 'C'; set[7].data = 'G';set[8].data = 'D'; set[9].data = 'H'; set[10].data = 'I'; set[11].data = 'J';set[12].data = 'M'; Initial(set);set[0].parent = -6; set[1].parent = 0; set[2].parent = 1; set[3].parent = 1;set[4].parent = 2; set[5].parent = 2; set[6].parent = -2; set[7].parent = 6;set[8].parent = -5; set[9].parent = 8; set[10].parent = 8; set[11].parent = 8;set[12].parent = 9;printf("\n");for (int i = 0; i <= 12; i++) {printf("数据:%c 指针:%d\n", set[i].data, set[i].parent);}printf("元素M所属于的集合的根节点的元素为%c\n", set[Find(set, 'M')].data);printf("元素B所属于的集合的根节点的元素为%c\n", set[Find(set, 'B')].data);Union(set, 8, 0); //将绿色和橙色集合合并printf("\n");printf("绿色和橙色集合合并后\n");printf("元素M所属于的集合的根节点的元素为%c\n", set[Find(set, 'M')].data);printf("元素B所属于的集合的根节点的元素为%c\n", set[Find(set, 'B')].data);GoodUnion(set,0, 6);printf("\n");printf("绿色和紫色集合合并后(只会让小树紫色的并入大树绿色的)\n");printf("元素L所属于的集合的根节点的元素为%c\n", set[Find(set, 'L')].data);printf("元素G所属于的集合的根节点的元素为%c\n", set[Find(set, 'G')].data);return 0;
}
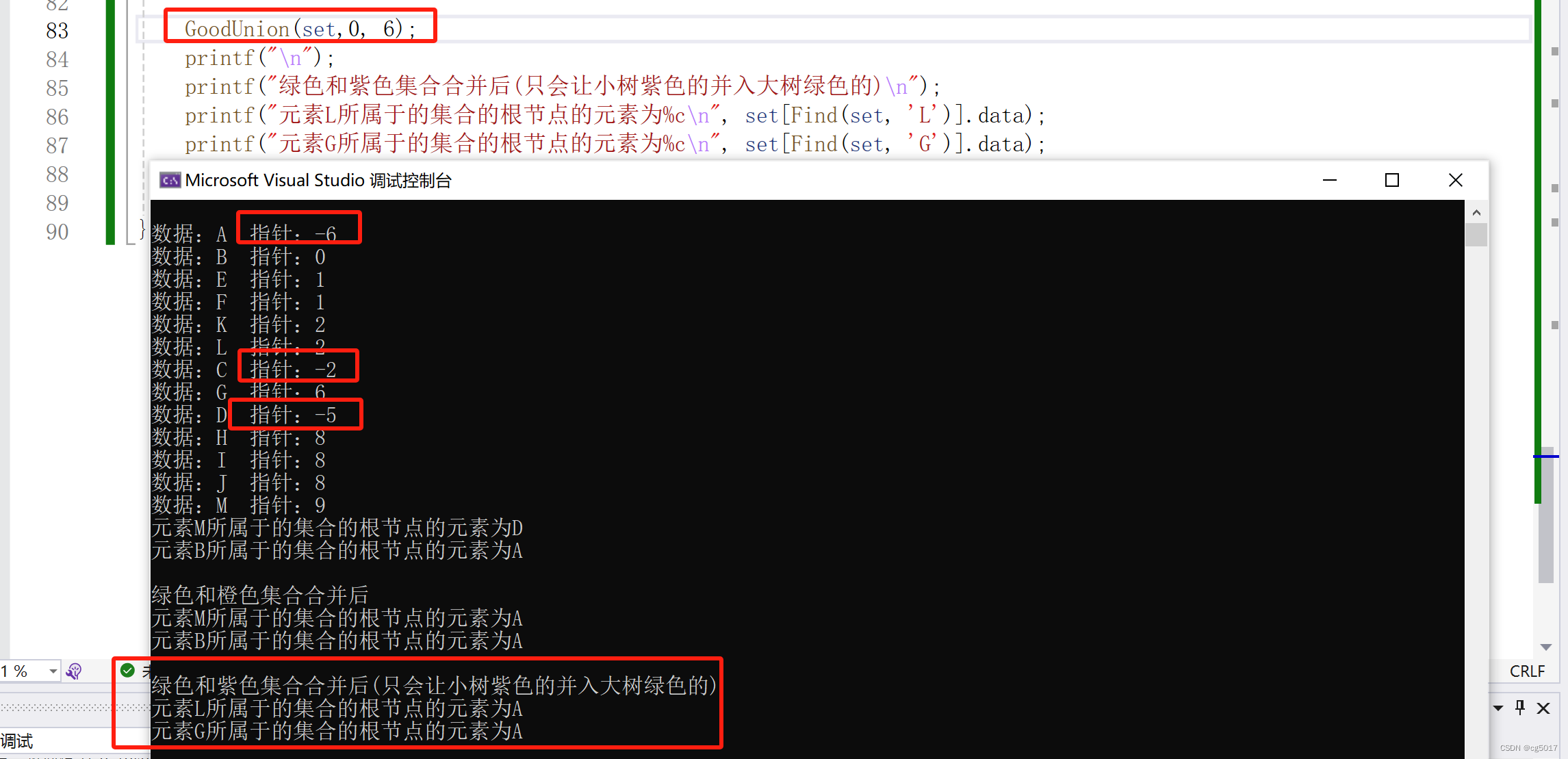
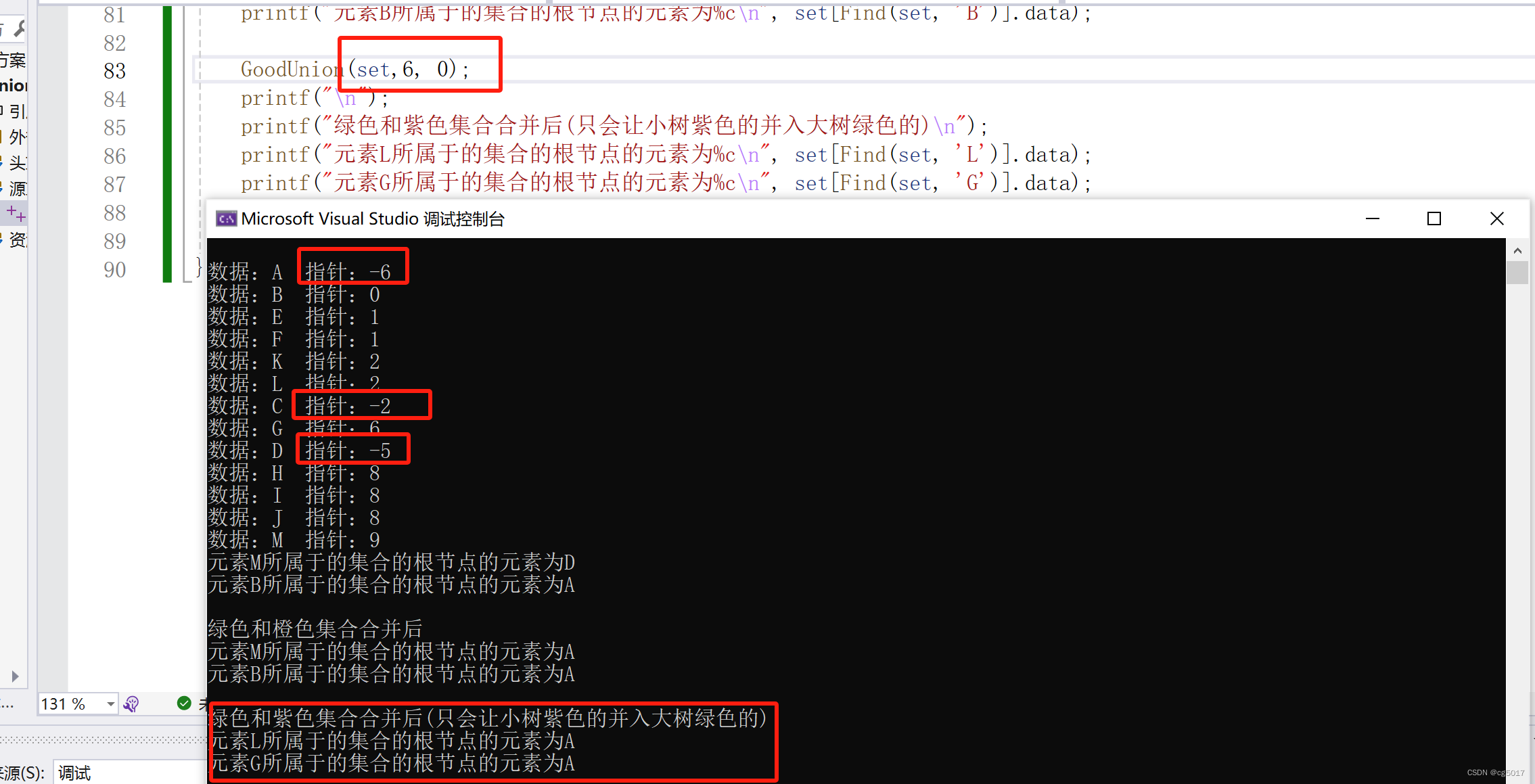
更换了合并顺序,其结果只会是小树向大树合并!