目录
自定义函数
apply函数
分类汇总函数aggregate
自定义函数
R语言中的自定义函数更像是在自定义一种运算规则。
自定义函数的语法是
函数名
函数体
}
比如

表示定义了一个名为BMI_function的函数,这个函数代表了一种运算规则,就是把传入的x和y进行x/((y/100)^2)的操作。然后把体重与身高作为实参并把运行结果产生的向量作为新的一列加到原来的数据框中。R语言中return并不是刚需。
本次代码中自定义的函数只能在本次代码中使用,如果我们想要在其他工程中使用这次写的函数,可以把本次定义函数的代码复制下来保存到一个txt格式的文档里,在开启一个新工程的时候我们就可以使用source函数,source() 函数用于读取并执行一个R脚本文件中的代码。当你在R环境中运行source()函数时,它会将指定脚本中的代码逐行读取并执行,就像你在R控制台中手动输入并执行这些代码一样。source函数只接收一个参数,就是想要让他读取的R代码的路径。
再举个例子,有这样一个表格,这个表格用数据框mydata存储
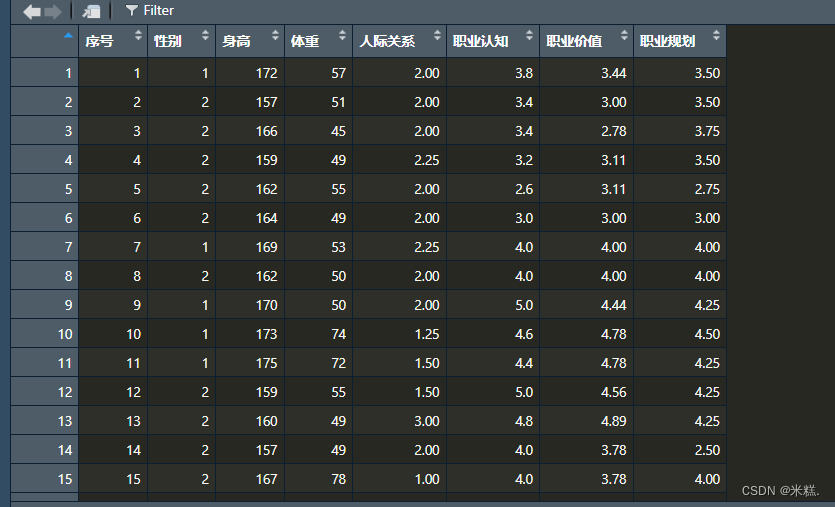
我想要看看整体的人际关系评估,展示形式是所有人人际关系得分的平均值±所有人人际关系得分的标准差,自定义的函数如下

这是一个针对单个向量的函数,round(mean(x),2)表示对向量x的平均值保留两位小数,paste函数用于把x的均值和标准差连接起来,连接符号为±
如图是我们把数据框mydata的某一列作为参数时候的运行结果

我们当然也可以直接使用循环来得到mydata每一列这个向量的运算结果
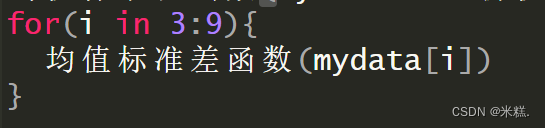
其中mydata[i]表示提取数据框的第i个元素,也就是第i列的向量
可以写成mydata[,i],表示提取第i列所有行的元素。但是这样难免造成一些理解上的困扰,这两种写法就好比我买糖,第一种是老板用一个袋子把糖装起来给我,第二种写法是老板直接抓了一把糖给我,至于我能不能接受就要看我的脾气好坏了,回到这个代码,至于R能不能识别,就要看R的兼容能力了。不过测试来看R是可以理解这种写法的。实际上我们通过all(mydata[2]==mydata[,2])这句代码的运行结果为TRUE可以知道这两个向量是完全一样的。
注:比较两个向量(假设是x和y)是否相等的方法:如果是比较两个向量每个位置上的元素是否相等,可以直接使用x==y,这样会返回很多结果,如果单纯想要比较两个向量是否相等,可以搭配函数all,例如all(x==y),如果两个向量的比较结果中所有元素都是TRUE,则返回TRUE。
如果想要把这个for循环的结果存储起来,应该先找一个空盒子,也就是代码中的ret,然后使用rbind函数按行合并即可。这里我们在每次合并的时候还把每一列的名字加了进去,以便于清楚地看到反映的是哪一列的整体水平。

但是这样的运行结果是产生了一个向量,这个向量的内容是列名与均值标准差函数的运行结果相间的,我们如何把这个向量分成两列?思路就是把名字和函数运行结果分别提取出来存到两个向量(比如x和y)里面,然后再使用data.frame(x,y)就可以了,首先是提取列名,因为使用的就是列表中三到九列的名字,因此x
apply函数
apply函数族比较常用的函数有apply,lapply,sapply,vapply,mapply等。
重点来介绍一下apply函数,语法为apply(数据集,行/列,计算规则),第一个参数指定要操作的数据集,一般是数据框或者矩阵,第二个参数指定是按照行为单位进行运算,如果该参数为1则表示按照行进行运算,该参数为2则表示按照列进行运算。第三个参数指定运算的规则,本质上这个参数是一个函数,因此实际上我们在对apply函数传参的时候第三个参数通常是传的函数名,但是要求这个函数必须是针对单一向量进行运算的。整个一句代码的意思是数据框或者矩阵中的所有行(或者列)都按照指定的运算规则来运算,所以调用一次apply函数就相当于调用了一次循环。实际上apply函数能做的事情使用for循环都可以解决,但是apply胜在语法简洁,而对于一些比较复杂的逻辑,还是推荐使用for循环。
比如有这样一个名为mydata2的数据框

我想要对后四列求一个均值来观察这几个向量整体的水平。则可以运行代码apply(mydata2[5:8],2,mean),其中mydata2[5:8]表示提取5到8列,2表示按列进行运算,mean表示对每一列进行的运算都是求均值。运行结果如图

使用for循环的话就业这样写
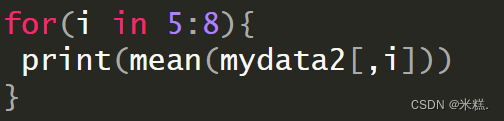
运行结果如下

注:在求均值的时候mean函数的参数传的是mydata2[,i],这表示第i列所有的元素,每个元素都是一个数值型的,如果我们传mydata2[i],表示拿到数据框mydata2的第i个元素,也就是他的第i列,这仍然是一个数据框,只不过这个数据框只有一列罢了,而mean函数的参数要求必须是数值型或者逻辑型。因此要注意函数参数需要的是一列,还是这一列的每个元素。
我们还想用均值±标准差的形式展示后四列的整体状况,可以这样写

其中均值标准差函数使我们自定义的,apply中mydata2[,5:8]表示提取mydata2这个数据框5到8列的所有元素,对拿到的每一列都进行均值标准差函数的运算,运行结果如图

我们使用ret把这个结果存储起来并查看他的类型,发现是字符型,为了方便后续的操作,我们把它转换成具有表格形式的类型也就是数据框或者矩阵,这里是转换成了数据框,最后把转换完成之后的ret结果保存起来写出到当前目录中去。
我们现在又想要观察mydata2这个数据框的5到8列整体的概况,那就可以写成

但是class(ret)结果显示ret的类型是一个列表,列表这种类型属于是对后续的操作非常不友好,ret的内容如图
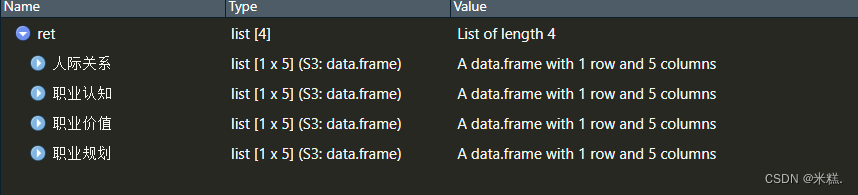
没有表格,就像是一个清单一样,没法复制到excel进行后续操作,因此我们现在要把这个列表转换成数据框,从而方便操作,前面我们介绍过类似的例子,列表转数据框,如果直接使用as.data.frame,将会得到一个这样的数据框

这个数据框有1行,20列,这仍然不符合后续分析的格式。
将列表转换成数据框常用的方法是do.call函数,但是并不是说do.call函数是用来专门把列表转换成数据框类型的。do.call根据一个名称或函数以及要传递给它的参数列表构造并执行一个函数调用。
ret长这样子

本来的ret是一个列表,列表的内容如下
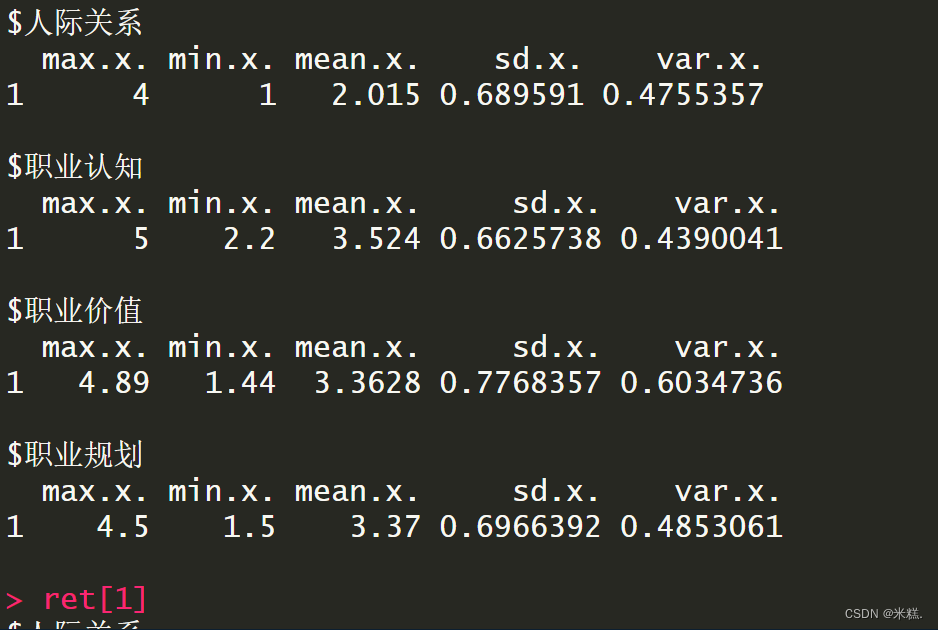
do.call函数会把ret这个列表的元素作为rbind函数的参数并调用rbind。列表的每一个元素仍然是列表类型,这一点可以通过class函数验证。列表中每个元素都有名字,这些名字被当做了合并后的数据框的行名。
刚才对于apply的应用都是按照列来的,再来介绍一个按照行来应用的例子。
有这样一个名为mydata1的数据框
里面的内容是根据这样的一个量表得到的

但是有几个反向计分题,需要先进行逆向化处理以确保每一类的题目得分都是同一方向的。由于存在多个需要处理的题目,所以我们干脆写一个逆向化处理的函数以避免后续代码的冗余。需要处理的题目分别在mydata1的第7,9,13列,准备工作可以通过这段代码来完成

首先自定义了一个函数re,则个函数的功能是让x向量里面的1变成5,2变成4等等,中间用分号连接且需要用引号括起来。之后使用apply把mydata1的7,9,13列作为参数调用re,这样调用完apply函数之后7,9,13列的逆向化处理就做完了,同时返回一个数据框,这个数据框就是逆向化之后的这三列,我们使用ret接收这个数据框,并把这个数据框的列名修改掉,最后合并到mydata1这个数据框中去。这样准备工作就做完了,我们开始想要求这些学生某一类问题的平均得分,比如计算一号学生继续承诺的平均得分,就需要把继续承诺这类问题中对应的题号下得分加起来求平均值,这显然是一个按行处理的方法,因此运行代码
apply(mydata1[,c(4,29,30,12,20,25)],1,mean)即可得到每个学生继续承诺这类问题的平均得分。其中第一个参数是这一类问题的题号对应的列,第二个参数是1表示按照行处理,第三个参数是mean表示要对每一行这些列的元素求平均值。
分类汇总函数aggregate
有这样一个名为mydata的数据框

现在要求出除了性别和是否患病的其他列的平均值,代码为
apply(mydata[,c(2,4:14)],2,mean)
结果如图

但是如果我们想要根据性别分别统计这些数据,就要使用aggregate函数了。
语法为aggregate(x=list(数据框),by=list(分组向量),FUN=函数名),aggregate函数无法指定按照行还是按照列来进行操作,这个函数只能以列进行运算。
运行代码
aggregate(x=list(mydata[,c(2,4:14)]),by=list(mydata$性别),FUN=mean)
结果如图

也可以通过代谢综合征进行分类,代码为
aggregate(x=list(mydata[,c(2,4:14)]),
by=list(mydata$代谢综合征),FUN=mean)
结果如图

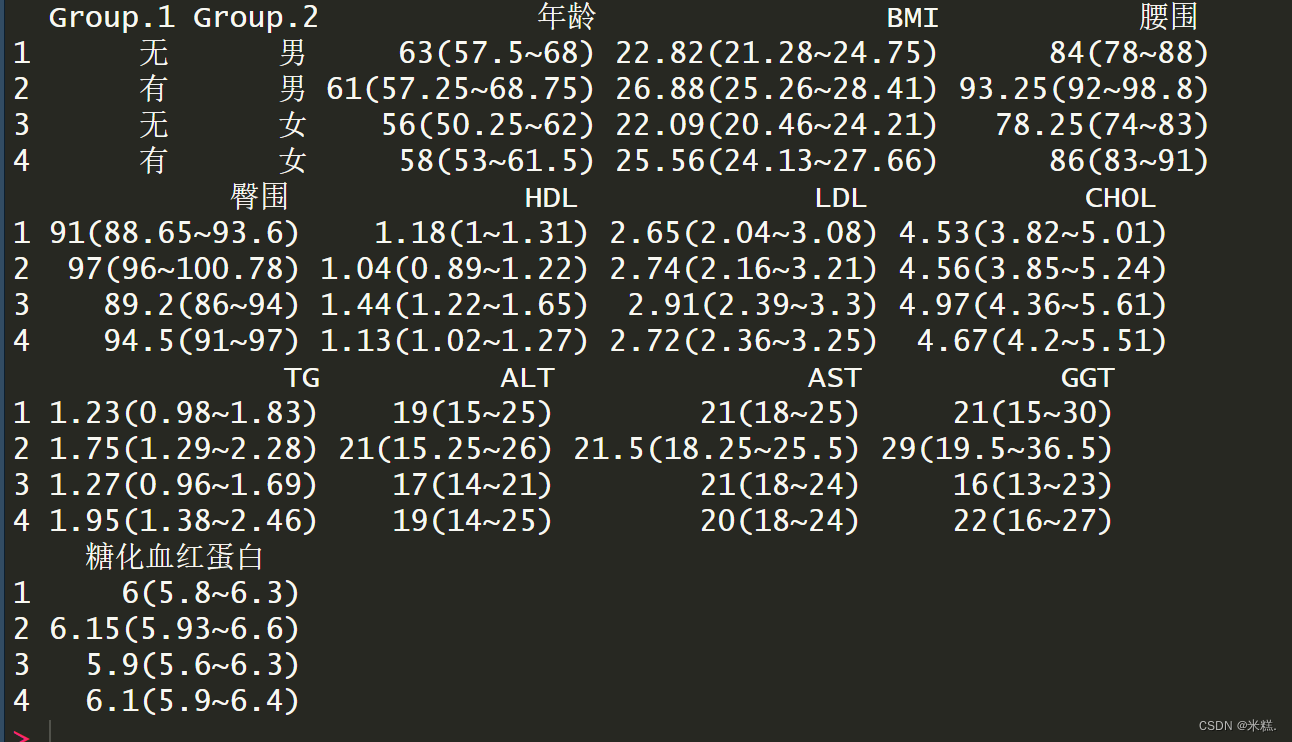
还可以通过性别和是否有代谢综合征这两个标准进行分类,代码为
aggregate(x=list(mydata[,c(2,4:14)]),
by=list(mydata$代谢综合征,mydata$性别),FUN=mean)
只需要在by这个参数中把两个分类标准都加进去就行。

aggregate中的FUN参数还可以是自定义的函数名,比如

运行结果为

有时候样本不遵循正态分布,需要用中位数(下四分位点~上四分位点)这样的格式来统计数据。这时候我们就这样写

运行结果如图