-
实现分布式的作用:
- 通过并行处理提高能力
- 通过复制机制进行容错处理
- 与传感器等物理设备的分布相匹配
- 通过隔离实现安全
-
难点:
- 许多并行的部件,他们之间有复杂的相互作用
- 必须应对处理部分故障
- 难以实现性能潜力
-
容错
- 1000多台服务器、庞大的网络----->总有故障发生
- 我们希望向应用程序隐藏这些故障
- 高可用性:尽管出现故障,但服务仍然能继续
- 复制服务器:如果一台服务器崩溃,可以使用另一台服务器继续运行。
-
一致性
- 实现良好的行为很难,“复制”服务器很难保持一致性
-
性能
- 目标:可扩展的吞吐量
- Nx台服务器->通过并行CPU、磁盘和网络获得Nx的总吞吐量。
- 随着N的增加,扩展变得越来越困难:
- 负载不均衡
- N 的延迟很大
- 初始化、交互等行为不会随着N的增加而加快
- 目标:可扩展的吞吐量
-
均衡
- 容错、一致性和性能不可能同时满足
- 容错和一致性需要通信
- eg:将数据发送到备份,检查我的数据是否最新
- 通信通常很慢,而且不可扩展
- 需要设计只提供弱一致性,以提高速度
- Get不一定会获得最新的Put()!
- 对程序员很痛苦,但是一个很好的权衡
- 我们将看到一致性/性能方面的许多设计要点
-
实施:
- RPC,线程,并发控制,配置
-
具体解释
Abstract view of a MapReduce job -- word countInput1 -> Map -> a,1 b,1Input2 -> Map -> b,1Input3 -> Map -> a,1 c,1| | || | -> Reduce -> c,1| -----> Reduce -> b,2---------> Reduce -> a,21) input is (already) split into M files2) MR calls Map() for each input file, produces set of k2,v2"intermediate" dataeach Map() call is a "task"3) when Maps are don,MR gathers all intermediate v2's for a given k2,and passes each key + values to a Reduce call4) final output is set of <k2,v3> pairs from Reduce()s -
伪代码
Word-count-specific codeMap(k, v)split v into wordsfor each word wemit(w, "1")Reduce(k, v_set)emit(len(v_set)) -
MapReduce的可扩展性很好:
- N个"worker"计算机(可能)会带来Nx的吞吐量
- Map()可以并行运行,因为他们之间没有交互
- Reduce()也可以并行运行
- 因此更多的计算机=更多的吞吐量 Nice
-
MapReduce隐藏了很多细节:
- 向服务器端发送应用程序的代码
- 跟踪哪些任务已经完成
- 将中间数据从Map,Shuffling,到Reduce
- 故障恢复
-
Map使得应用程序
- 没有交互或状态(中间输出除外)
- 没有迭代
- 无实时或流式处理
-
输入和输出存储在GFS集群文件系统中
- MR需要巨大的并行输入和输出吞吐量
- GFS将文件以64MB为单位分割到多个服务器上
- Map并行读取
- Reduce并行写入
- GFS还将每个文件复制到2或3台服务器上
- GFS是MapReduce的一个大优势
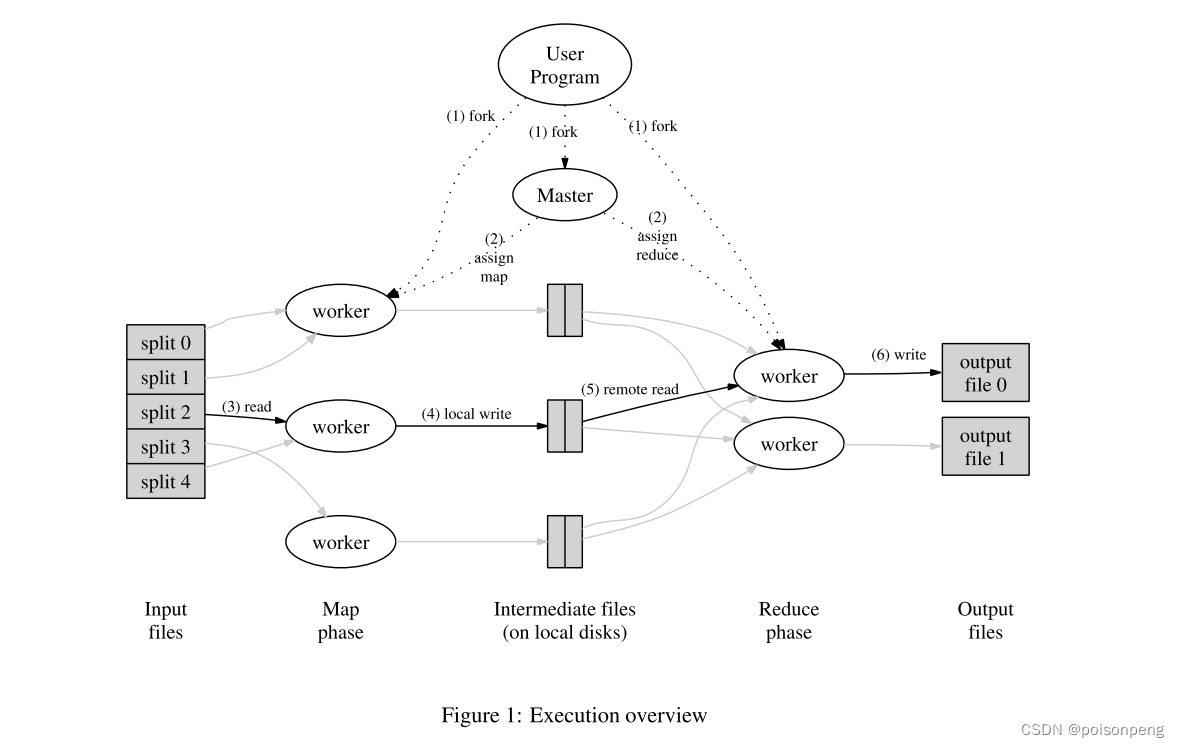
-
一个Master,负责向worker分配任务并记录进度
-
Master将Map分配给worker,直到所有的Map完成
Map将输出(中间数据)写入本地磁盘
Map分裂输出,通过哈希函数将其写入Reduce之前的预处理文件
-
在所有的Map完成之后,Master分配Reduce任务
每个Reduce任务从所有Map worker处获取其中间输出
每个Reduce在GFS上写入一个单独的输出文件
-
-
MR如何最小化网络的使用
- Master尝试在每一个GFS服务器中存储输入数据的位置运行Map任务
- 所有的计算机都同时运行GFS和MR worker,因此输入数据只是从本地磁盘读取而不通过网络。
- 中间数据只通过网络传输一次
- Map处理程序写出本地磁盘
- Reduce worker 通过网络从Map worker磁盘读取数据
- 如果存储在GFS中,则至少需要通过网络两次
- 中间数据被分割成包含多个关键字的文件
- R远远小于键的数量
- 大型网络传输效率更高
- Master尝试在每一个GFS服务器中存储输入数据的位置运行Map任务
-
MR如何获得好的负载均衡
- 如果N-1台服务器必须等待1台慢服务器完成任务,就会造成浪费,速度也会变慢
- 但有些任务可能比其他任务耗时更长
- 解决方案:
- Master将新任务分配给完成之前任务的worker,这样速度快的服务器就会比速度慢的服务器完成更多的任务。
-
容错能力
- MR只重新运行失败的Map和Reduce
-
worker崩溃后恢复的细节
- 一个Map worker 崩溃
- Master注意到worker不再响应ping
- Master知道该worker上运行哪些任务
- 这些任务的中间任务输出已经丢失必须重新创建,Master通知其他worker运行这些任务
- 一个Reduce worker 崩溃
- 已经完成的任务没有问题 ——保存在GFS中,并且有副本
- Master会在其他worker上重新启动未完成的任务
- 一个Map worker 崩溃