-
线程=“执行线程”
- 线程允许一个程序同时做很多事
- 每一个线程就像普通非线程程序一样,都是串行执行
- 线程之间共享内存
- 每个线程都包含每个线程的状态,所以它们有
- 程序计数器,寄存器,堆栈,就绪挂起执行等状态
-
线程的好处
- I/O并发
- 客户端并行的向多个服务器发送请求并且等待响应
- 服务器端处理多个客户端请求;每个请求都可能阻塞
- 当等待从磁盘读取客户机X的数据时,处理来自客户端Y的请求
- 多核性能
- 在多个核心上并行执行代码
- 便捷性
- 在后台,每秒检查一次每个worker是否还活着
- I/O并发
-
除了线程有可替代方案吗
-
有:在单线程中编写明确交错活动的代码。通常称其为“事件驱动”
-
保存每个活动的状态表。 eg:每个客户端的请求
-
One "event" loop that:checks for new input for each activity (e.g. arrival of reply from server),does the next step for each activity,updates state. -
事件驱动可以实现I/O并发,并且消除了线程的成本(可观),但无法获得多核的速度,并且编程很麻烦
-
-
编写线程的挑战
- 安全的共享数据
- 如果两个线程同时执行n=n+1或者一个线程读取数据,另一个线程递增此数据。这就是所谓的竞争——通常是一个常见的错误,
- 可以通过使用锁来避免
- 可以刻意避免共享可变数据
- 如果两个线程同时执行n=n+1或者一个线程读取数据,另一个线程递增此数据。这就是所谓的竞争——通常是一个常见的错误,
- 线程之间的协调
- 一个线程在生成数据,另一个线程在消费数据(消费者如何等待(并释放CPU),生产者如何唤醒消费者)
- 使用GO中的channels
- sync.Cond or sync.WaitGroup
- 一个线程在生成数据,另一个线程在消费数据(消费者如何等待(并释放CPU),生产者如何唤醒消费者)
- 死锁
- 通过锁和通信进行循环(如RPC或者Go channels)
- 安全的共享数据
-
最简单的故障处理方案:“尽最大努力交付”的RPC
- Call() 等待响应一段时间
- 如果没有回应重新发送请求
- 这样做几次
- 然后放弃并返回错误
-
“尽最大努力交付”对应用程序来说如何?
- 一种特别糟糕的情况
- 客户端执行:
- put(“k”,10);
- put(“k”,20);
- 均成功(但网络延迟)
- 当get(“k”)
- [diagram, timeout, re-send, original arrives late]
- 客户端执行:
- 一种特别糟糕的情况
-
什么时候用“尽最大努力交付”
- 只读操作
- 重复执行无任何反作用的操作
- eg:DB检查记录是否已被插入
-
更好的RPC行为:“最多执行一次的”RPC
-
理念:如果没有resp,客户端重新发送请求
- 服务器端的RPC代码检测重复请求
- 返回之前的回复,而不需要重新处理
-
如何检测重复请求
-
客户端每次请求时包含唯一性索引 ID(XID),再次发送时使用相同的XID
-
服务器端:
-
server:if seen[xid]:r = old[xid]elser = handler()old[xid] = rseen[xid] = true
-
-
-
-
如何避免庞大的seen[xid]表
- 想法:
- 每个客户端有一个唯一性ID(也许是一个大随机数),为每一个RPC分配递增的序列号
- 客户端在每次RPC中包括“已看到所有回复<=X”
- 就类似于TCP序列号和ACKs,或者只允许客户端同时有一个未完成的RPC
- 这样服务器就能保持O(客户端数),而不是O(XID)
- 想法:
-
服务器最终必须丢弃旧RPC或者旧客户端的信息,何时丢弃是安全的,当原始请求仍在执行时,如何处理重复请求
- 为每一个正在执行的RPC设置“待处理”标志;等待或者忽略
-
当线程并行执行的时候,如果内核数量少于可运行的线程数,运行时将抢先在线程之间分配内核
-
单线程和多线程在程序内存地址空间的区别
-
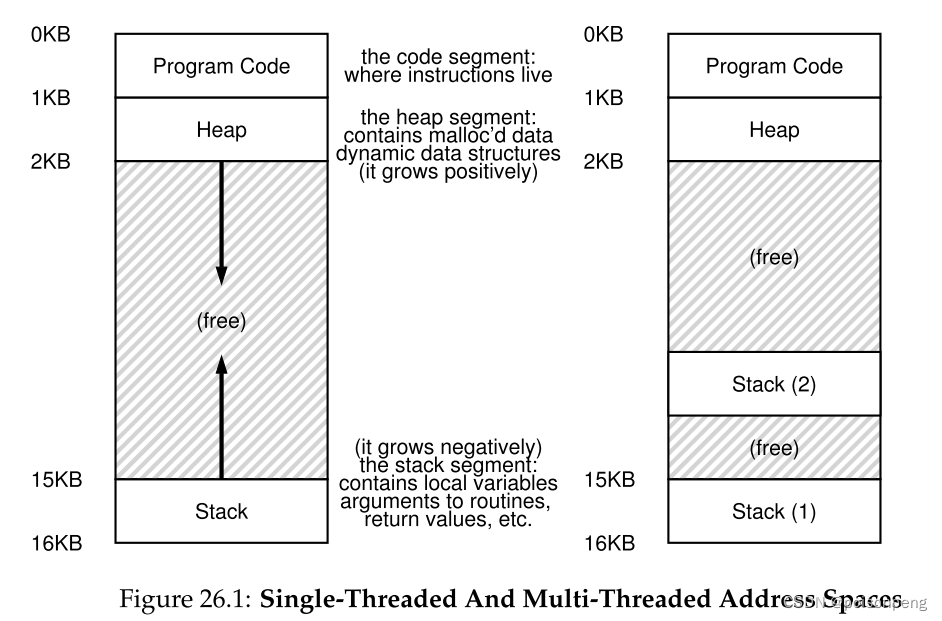
- 如果两个线程在单核CPU上运行,当从运行一个线程 (T1) 切换到运行另一个线程 (T2) 时,必须进行上下文切换。线程之间的上下文切换与进程之间的上下文切换非常相似,因为在运行T2之前必须保存T1的寄存器状态并恢复T2的寄存器状态。对于进程,我们将状态保存到进程控制块(PCB);现在,我们需要一个或多个线程控制块(TCB)来存储进程的每个线程的状态。与进程相比,我们在线程之间执行的上下文切换有一个主要区别:地址空间保持不变(即不需要切换我们正在使用的页表)。
- 线程和进程的另一个主要区别是堆栈,每个线程都有一个堆栈。假设我们有一个多线程进程,其中有两个线程;生成的地址空间看起来有所不同(图 26.1,右)。
- 以前,堆栈和堆可以独立增长,只有当地址空间空间不足时才会出现问题。在这里,我们不再有这么好的情况了。幸运的是,这通常是可以的,因为堆栈通常不必很大。
-
协程与线程的区别在于协程是完全在应用程序内 (低特权运行级) 实现的,不需要操作系统的支持,占用的资源通常也比操作系统线程更小一些。协程可以随时切换执行流的特性,用于实现状态机、actor model, goroutine 等。
RPC与Thread笔记
devtools/2024/9/24 7:28:56/
相关文章

MongoDB聚合运算符:$toBool
MongoDB聚合运算符:$toBool 文章目录 MongoDB聚合运算符:$toBool语法使用举例 $toBool聚合运算符将指定的值转换为布尔类型boolean。 语法
{$toBool: <expression>
}$toBool接受任何有效的表达式。
$toBool是$convert表达式的简写形式࿱…
2000-2020年县域创业活跃度数据
2000-2020年县域创业活跃度数据
1、时间:2000-2020年
2、指标:地区名称、年份、行政区划代码、经度、纬度、所属城市、所属省份、年末总人口万人、户籍人口数万人、当年企业注册数目、县域创业活跃度1、县域创业活跃度2、县域创业活跃3
3、来源&#…
ZooKeeper以及DolphinScheduler的用法
目录 一、ZooKeeper的介绍
数据模型
编辑 操作使用
①登录客户端
编辑 ②可以查看下面节点有哪些
③创建新的节点,并指定数据
④查看节点内的数据
⑤、删除节点及数据 特殊点:
运行机制:
二、DolphinScheduler的介绍 架构&#…
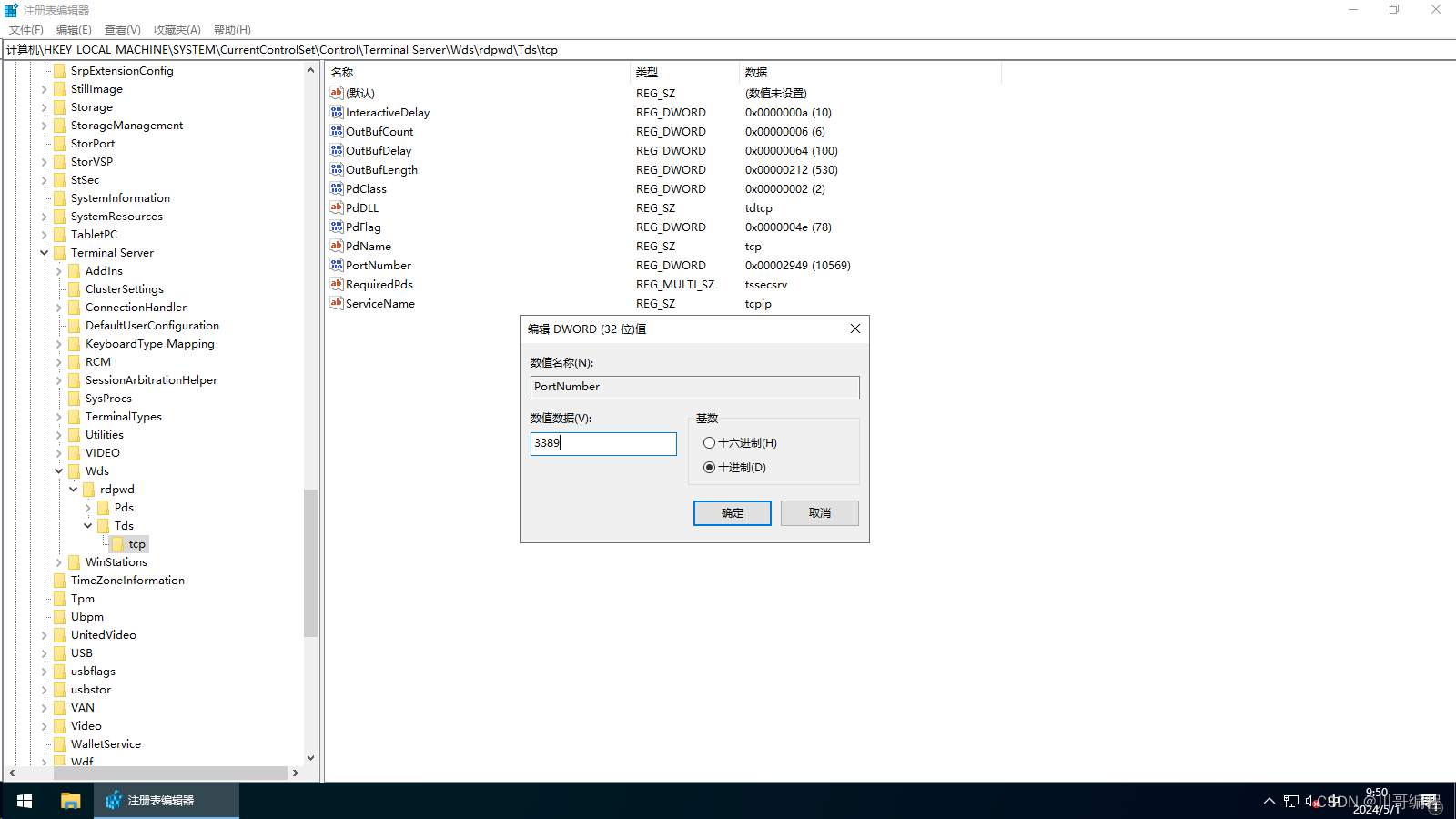
修改 Windows 服务器远程端口,以阿里云服务器 ECS 为例
一、WinR - mstsc.exe 登录远程服务器
二、WinR - regedit.exe 打开注册表
三、打开注册表 tcp 路径: 计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TerminalServer\Wds\rdpwd\Tds\tcp 双击右侧 PortNumber 子健,勾选十进制&a…

同创优配正规股票交易高盛午评:是的,中国交易回来了
查查配中国经济强劲复苏的预期下,港股上演了一场史诗级大反攻!
同创优配是AAA 级诚信经营示范单位,中国人民银行备案认证,天眼查可查询。是一家专注于股票投资、金融服务、及资产管理的专业机构
自1月低点至今,恒生指数累计上涨近21%,恒生科技指数累计上涨逾28%。最近几周,港…

Java并发编程面试问题与答案
1. 什么是线程安全?
答: 线程安全意味着多个线程可以同时访问一个类的实例而不引起任何问题或不一致的结果。线程安全的代码会通过同步机制来确保所有线程都能正确地访问共享资源。
2. 解释Java中的synchronized关键字。
答: synchronized…
2024-04-30 问AI: 介绍一下VGG16深层网络模型
文心一言
VGG16 是一种深度卷积神经网络(CNN)模型,由牛津大学的 Visual Geometry Group (VGG) 开发。这个模型在 2014 年的 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 竞赛中取得了显著的成绩,证明了深度网络…