常量内存是一种专用内存,用于只读数据和统一访问线程束中线程的数据。常量内存对于内核代码是只读的,但对主机而言是可读写的。
常量内存位于设备的DRAM上,并且有一个专用的片上缓存。从每个SM的常量缓存中读取的延迟,比直接从常量内存中读取的低得多。
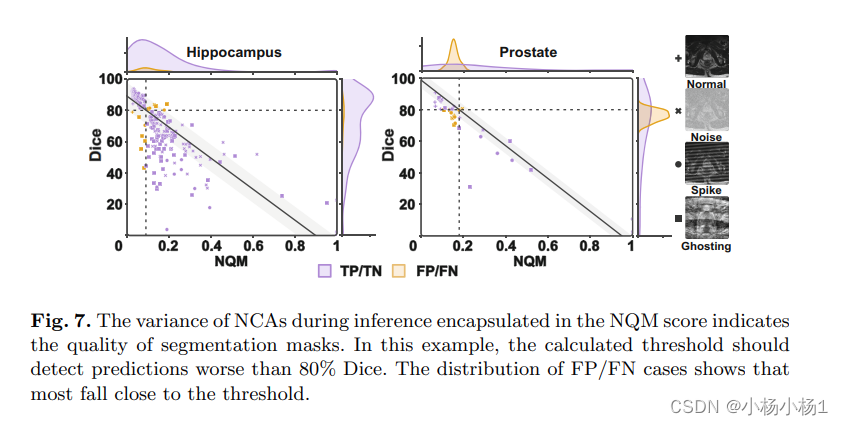
常量内存有一个不同于其他内存的最优访问模式。在常量内存中,如果线程束中的所有线程都访问相同的位置,那么这个访问模式就是最优的。如果线程束中的线程访问不同的地址,则访问就需要串行。因此,一个常量内存读取的成本与线程束中线程读取唯一地址的数量呈线性关系。
在全局作用域中用以下修饰符声明常量变量
__constant__常量内存变量的生存周期与整个应用程序相同,对网格内的所有线程都是可访问的。
例如,公式计算中的系数经常作为常量内存保存。
与只读缓存的比较
开普勒GPU使用GPU纹理流水线作为只读缓存。
一般来说,只读缓存在分散读取方面比一级缓存更好,当线程束中的线程都读取相同地址时,不应使用只读缓存。
只读缓存是独立的,而且区别于常量缓存。通过常量缓存加载的数据必须是相对较小的,而且访问必须一致以获得好的性能(一个线程束内的所有线程在任何给定时间内都访问相同的位置)。而通过只读缓存加载的数据可以是比较大的,而且能够在一个非统一的模式下进行访问。
线程束洗牌指令
从开普勒系列的GPU开始,洗牌指令被加入其中。只要两个线程在相同的线程束中,那么就允许这两个线程直接读取另一个线程的寄存器。
洗牌指令让线程束中的线程可以彼此之间直接交换数据,而不是通过共享内存或全局内存来进行。因为线程束洗牌指令在线程数内进行,首先要说明束内线程。
束内线程顾名思义就是一个线程束内的某个线程。每个线程有自己对应的束内线程索引,和线程束索引。因为这两个值没有内置变量,所以需要用计算求出来
laneID = threadIdx.x % 32;
warpID = threadIdx.x / 32;线程束洗牌指令的不同形式
有两组洗牌指令,一组用于整型变量,一组用于浮点型变量。每组有四种形式的指令。
在线程数内交换整型变量,其基本函数标记如下
int __shfl(int var, int srcLane, int width=warpSize);内部指令__shfl返回值是var,var通过srcLane确定的同一线程束中的线程传递给__shfl。srcLane的含义变化取决于宽度值。这个函数能使线程束中的每个线程都可以直接从一个特定的线程中获取某个值。线程束内所有活跃的线程都同时产生此操作,这将导致每个线程中有4字节数据的移动。
变量width可以被设置为2~32之间2的任何指数。当设置为默认的32时,洗牌指令跨整个线程束来执行,并且srcLane指定源线程的束内线程索引。如果width不是32,线程束被分段,每段包含width个线程。举个栗子

__shfl(val,2)

__shfl(val,2,16)
洗牌操作的另一种形式是从调用线程相关的线程中复制数据
int __shfl_up(int var, unsigned int delta, int width=warpSize)__shfl_up通过减去调用的束内线程索引delta来计算源束内线程索引。返回由源线程所持有的值。
对应的是从高索引值的线程中复制值。
int __shfl_down(int var, unsigned int delta, int width=warpSize)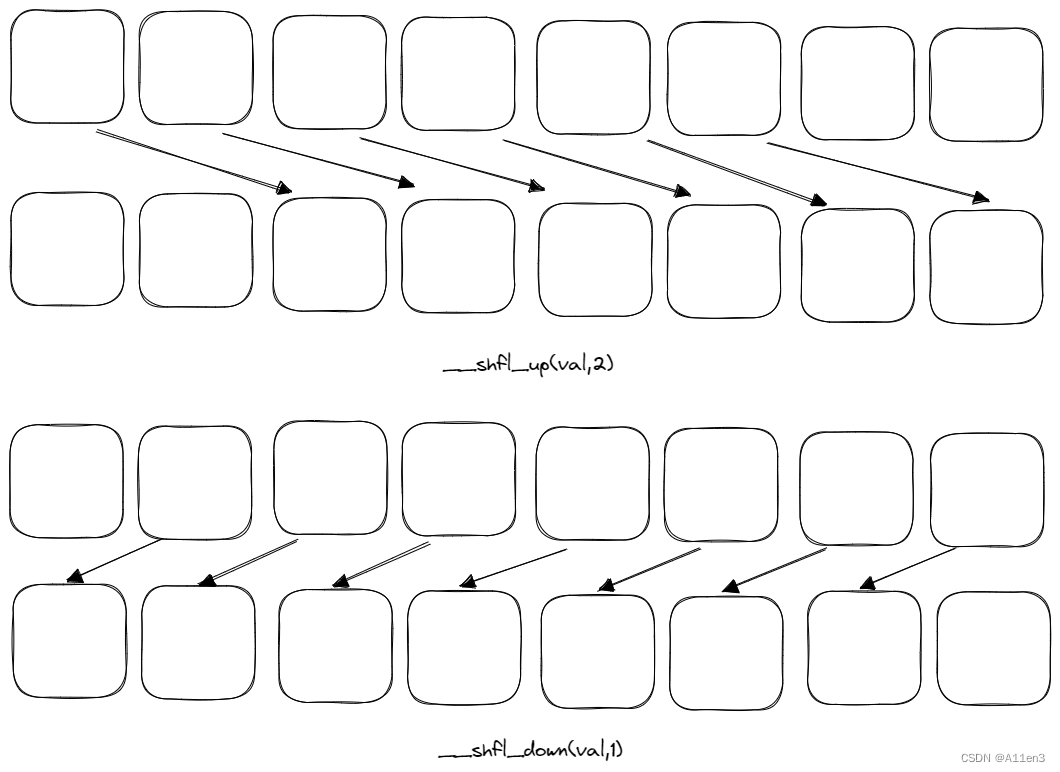
洗牌指令的最后一种形式是根据调用束内线程索引自身的按位异或来传输束内线程中的数据
int __shfl_xor(int var, int laneMask, int width=wrapSize)通过使用laneMask执行调用束内线程索引的按位异或,内部指令可计算源束内线程索引。返回源线程所持有的值。该指令适合于蝴蝶寻址模式。
蝴蝶寻址(Butterfly Addressing)通常用于描述一种数据交换算法,特别是在FFT(快速傅里叶变换)等算法中常见。在FFT算法中,蝴蝶寻址用于描述对数据进行重新排列的一种方式,以便在计算过程中能够有效地进行数据交换和计算。
蝴蝶寻址的基本思想是将数据分为不同的组,并在每一组内对数据进行重新排列。具体来说,蝴蝶寻址通常包括以下步骤:
- 将输入数据分为多个组,每个组包含一定数量的数据。
- 对每个组内的数据进行重新排列,使得数据之间的交换满足一定的规律。
- 重复上述步骤,直到所有数据都被重新排列。
蝴蝶寻址的名称源于其类似于蝴蝶展开翅膀的形状。在FFT算法中,蝴蝶寻址可以帮助实现数据的快速交换和计算,从而提高算法的性能和效率。
另外,浮点洗牌函数采用浮点型的var参数,并返回一个浮点数。
使用线程束洗牌指令比使用全局内存效率更高。