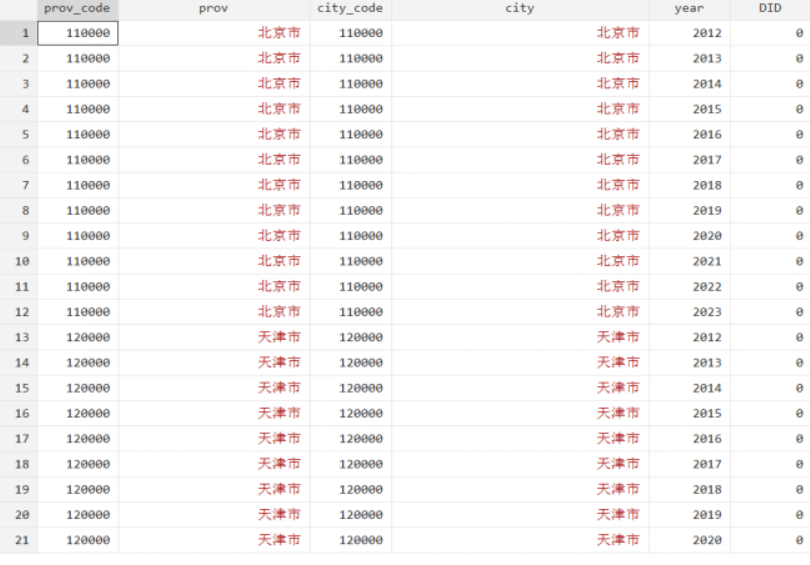
学习强化学习之父、加拿大计算机科学家理查德·萨顿( Richard S. Sutton )2019年的经典文章《The Bitter Lesson(苦涩的教训)》。
文章指出,过去70年来AI研究走过的最大弯路,就是过于重视人类既有经验和知识,而他认为最大的解决之道是摒弃人类在特定领域的知识、利用大规模算力的方法,才是通往AGI路径的方向。

过去70年人工智能研究领域最重要的一堂课,是只有通用计算方法(蛮力计算 brute-force)最终是最有效的,而且优势很大——因为摩尔定律,每单位计算成本持续呈指数下降。大多数人工智能研究都是假设Agent可用的计算量是恒定的(在这种情况下,利用人类知识将是提高性能的唯一方法之一),但是,在稍长的时间里看,可用的计算量必然会大大增加。
为了在短期内获得改善,研究人员试图启用本领域内的现存人类知识,但长远来看,唯一重要的是利用算力。基于人类知识的方法往往很复杂,不太适合利用好通用算力。有许多人工智能研究人员迟迟未能学习这个苦涩的教训的例子,回顾这些年的一些最突出的例子是很有启发性的。
在电脑国际象棋中,1997年击败世界冠军卡斯帕罗夫的方法基于大量的深度搜索。当时,许多计算机国际象棋研究人员对此感到失望,他们一直致力于利用人类对国际象棋特殊结构的理解的方法。当一种更简单的基于搜索的方法,结合特殊的硬件和软件,取得了更大的成功时,这些基于人类知识的国际象棋研究人员没有虚心接受失败。他们反驳道,“粗暴的”搜索可能这次赢了,但这不是一种通用的策略,而且也不是人们玩国际象棋的方式。这些研究人员希望基于人类的行棋思路获胜,当它没有获胜时他们感到失望。
在电脑围棋中,也出现了类似的研究进展,只是比国际象棋晚了20年。最初的巨大努力是避免用蛮力搜索,而是想办法利用人类知识(一千年的棋谱),或游戏的特殊特征,但是所有这些努力都被证明是无关紧要的。更糟糕的是,一旦有效地进行了大规模搜索,这些努力都是负向的。还有一点,通过自我对弈学习价值函数的方法,对于围棋和其他许多游戏而言都非常重要,尽管学习在1997年首次击败国际象棋的世界冠军的程序中并不起重要作用。
学习和搜索是利用大规模计算的人工智能研究中最重要的两类技术。在计算机围棋中,与计算机国际象棋一样,研究人员最初的努力是利用人类的理解(以减少搜索量),后来才通过搜索和学习取得更大的成功。
在语音识别方面,20世纪70年代有一场由美国国防部高级研究计划局赞助的早期竞赛。参赛者挖空心思,使用了一系列利用人类知识的招术,包括对单词、音素、人类声道等的理解。另一方面,还有一些更统计学的方法,它们基于隐马尔可夫模型(HMMs)做了更多的计算。再次,统计学方法胜过基于人类知识的方法。这导致自然语言处理领域出现了一个重大变化,几十年来,统计学和计算逐渐主导了这一领域。语音识别中最近深度学习的兴起是这一持续发展的最新一步。
深度学习方法甚至更少地依赖于人类知识,使用更多的计算,加上在巨大的训练集上的学习,来产生更好的语音识别系统。正如游戏中一样,研究人员总是试图制造出研究人员认为自己的大脑运作方式的系统——他们试图把这些知识放入他们的系统中——但最终证明是适得其反,也是研究人员时间的巨大浪费,因为通过摩尔定律,大规模计算变得可行,而且能得到很好的利用。
在计算机视觉/CV领域,也有类似的模式。早期的方法将视觉理解为寻找边缘、广义圆柱体或基于SIFT特征进行处理。但今天这一切都被抛弃了。现代的深度学习神经网络仅使用卷积和某些不变性的概念,并且表现得更好。
这是一个重要的教训。纵观整个AI 人工智能领域,我们仍然没有彻底地学习到这个教训,因为我们仍在犯同样的错误。为了看清这一点并有效地抵制它,我们必须理解这些错误的吸引力。我们必须学习苦涩的教训,即把我们认为的思维方式构建到系统中是行不通的。
这一苦涩的教训是基于历史观察,即
1)人工智能研究人员经常试图把知识构建到他们的代理系统中,
2)这在短期内总是有帮助的,并且对研究人员来说是个人满意的,但
3)从长远来看,它总会达到一个瓶颈,甚至会阻碍进一步的进展,
4)最终的突破性进展是通过一种相反的方法——基于搜索和学习的大规模堆算力——而获得的。
从这一苦涩的教训中应该学到的一件事是通用方法的巨大力量,即随着可用算力的增加,这些方法仍然可以继续扩展。似乎可以以这种方式无限扩展的两种方法是搜索和学习。
从这个苦涩的教训中学到的第二个普遍点是,人类心智的实际内容是极其复杂的,我们不应该再试图找到简单的方法来思考心智的内容,比如简单地思考空间,物体,多个代理或对称性。所有这些都是任意的、内在复杂的外部世界的一部分。它们不应该被构建,因为它们的复杂性是无止境的;相反,我们应该构建可以找到和捕获这种任意复杂性的元方法。这些方法的关键是它们可以找到良好的近似值,但算法应该是基于我们的方法(如学习),而不是我们已经学到的知识。我们希望AI Agent 能够像我们人类一样去发现,而不是在系统里集成我们已经发现的知识。
原文:The Bitter Lesson