🔥个人主页:Quitecoder
🔥专栏:c++笔记仓

朋友们大家好,本篇文章我们来讲解优先级队列
priority_queue
目录
- `1.priority_queue的介绍和使用`
- `函数使用`
- `仿函数的使用与介绍`
- `greater和less`
- `2.priority_queue的模拟实现`
- `基本框架`
- `两个调整函数的优化`
- `对于自定义类型的其他仿函数使用`
1.priority_queue的介绍和使用
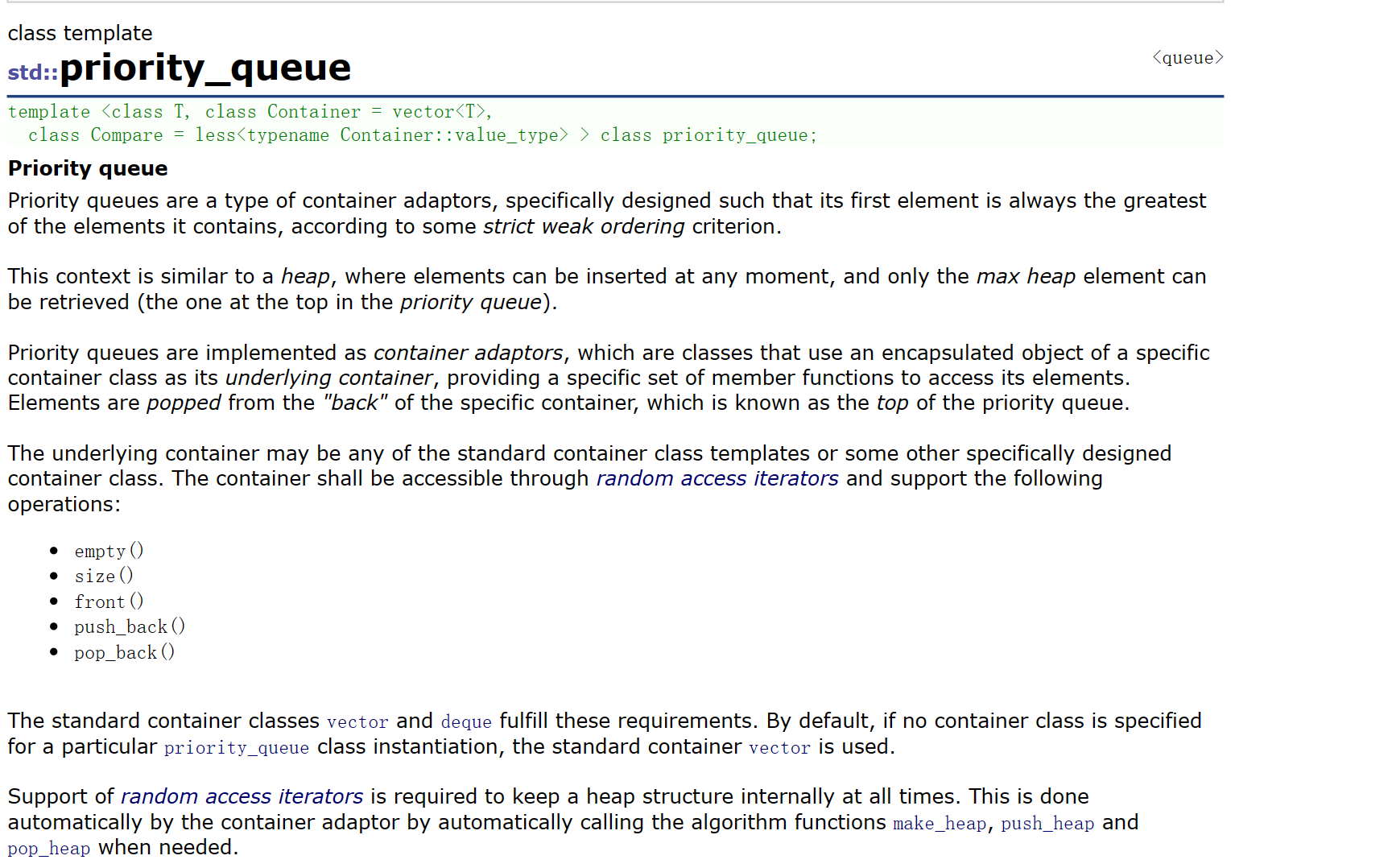
- 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
- 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
- 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部
- 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
empty():检测容器是否为空size():返回容器中有效元素个数front():返回容器中第一个元素的引用push_back():在容器尾部插入元素pop_back():删除容器尾部元素
- 标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector。
- 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作
函数使用

优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此
priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。注意:默认情况下priority_queue是大堆

🔥构造函数

有关这些参数的使用我们后文进行详细讲解,创建一个优先级队列:
priority_queue <int> pq;
🔥empty( )
检测优先级队列是否为空,是返回true,否则返回false
🔥top( )
返回优先级队列中最大(最小元素),即堆顶元素
🔥push( )
在优先级队列中插入元素x
🔥pop( )
删除优先级队列中最大(最小)元素,即堆顶元素
测试函数:
void test()
{priority_queue<int> pq;pq.push(3);pq.push(1);pq.push(5);pq.push(2);pq.push(4);while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;
}
我们按照不同顺序插入,来观察它的取顶端元素结果:
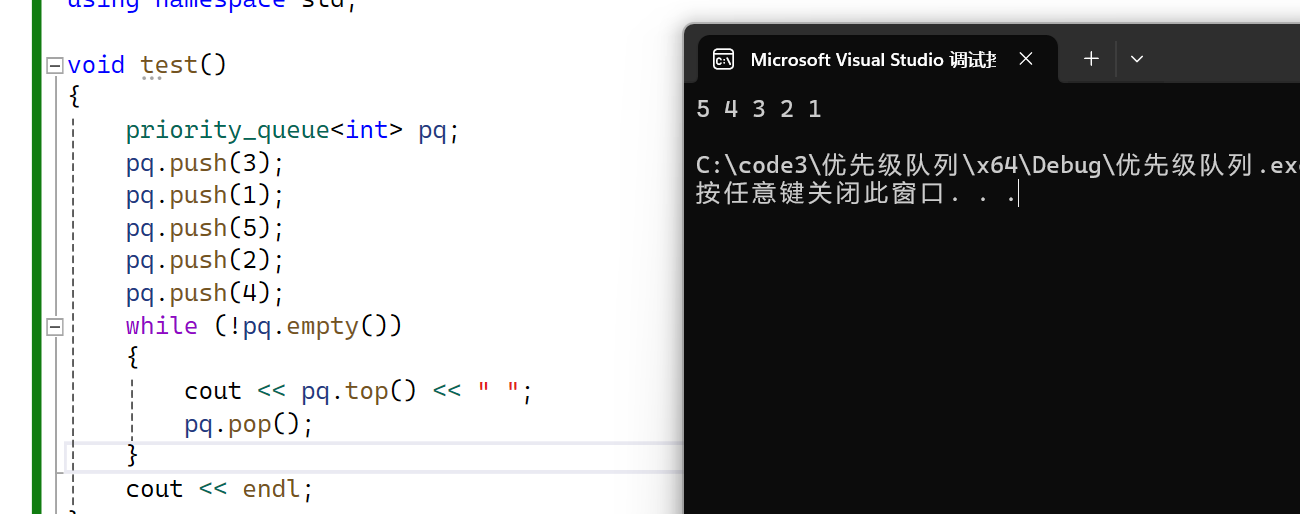
默认情况下,priority_queue是大堆
那么如何构建一个小堆呢?这里就涉及到仿函数
仿函数的使用与介绍

s在 C++ 的 std::priority_queue` 实现中,默认情况下,优先级是用元素之间的小于操作来判定的,即元素越大优先级越高
模板参数解释如下:
-
class Container = vector<T>:
这是用来内部存储队列中元素的容器类型。默认是std::vector,但也可以是其他符合要求的容器类型,比如std::deque。有一点要注意的是,必须支持随机访问迭代器(Random Access Iterator),以及front(),push_back(),pop_back()的操作 -
class Compare = less<typename Container::value_type>:
这是用来比较元素优先级的比较函数对象。默认是std::less,该函数使得最大的元素被认为是最高优先级(形成最大堆)。如果想要最小的元素为最高优先级(形成最小堆),可以通过提供std::greater函数对象作为这个模板参数来改变这个行为
默认使用less这个仿函数,如果我们需要建立小堆,需要自己传参:
priority_queue<int,vector<int>,greater<int>> pq;
我们接下来详细讲解一下什么是仿函数
在C++中,仿函数是一种使用对象来模拟函数的技术。它们通常是通过类实现的,该类重载了函数调用操作符(operator())。仿函数可以像普通函数一样被调用,但它们可以拥有状态(即,它们可以包含成员变量,继承自其它类等)
下面是使用仿函数的一个简单例子:
#include <iostream>
using namespace std;
// 定义一个仿函数类
class Add {
public:// 构造函数,可以用来初始化内部状态,这里没有使用Add() {}// 重载函数调用操作符int operator()(int a, int b) {return a + b;}
};int main() {// 创建一个仿函数对象Add add_func;// 使用仿函数对象cout << add_func(10, 5) << endl;cout << add_func.operator()(10,5)<<endlcout << Add()(10,5)<<endl;return 0;
}
在这个例子中,我们定义了一个名为 Add 的仿函数类,它重载了 operator() 来实现两数相加的功能。然后在 main 函数中创建了该类的一个实例 add_func 并且像调用函数一样使用 add_func(10, 5) 来求和
Add()(10,5)使用了匿名对象
仿函数广泛用于C++标准库中,特别是在算法(std::sort, std::for_each 等)中作为比较函数或者操作函数,以及在容器(如 std::set 或者 std::map)中作为排序准则

这是如何在 std::sort 算法中使用仿函数的一个实例:
#include <algorithm>
#include <iostream>
#include <vector>
using namespace std;
class Compare {
public:bool operator()(int a, int b) {return a > b; // 降序排列}
};int main() {vector<int> v {2, 4, 1, 3, 5}; // 使用仿函数对象sort(v.begin(), v.end(), Compare());for (int i : v) {std::cout << i << " ";}// 输出:5 4 3 2 1 return 0;
}
在上面的例子中,Compare 仿函数用来定义一个降序规则,随后在 std::sort 中将其实例化并传递给算法进行降序排序
仿函数的一个主要优点是它们可以保持状态,这意味着它们可以在多次调用之间保存和修改信息。这使得它们非常灵活和强大。此外,由于它们是类的实例,它们也可以拥有额外的方法和属性
greater和less
std::greater 和 std::less 是预定义的函数对象模板,用于执行比较操作。它们定义在<functional>头文件中。std::greater 用来执行大于(>)的比较,而 std::less 用来执行小于(<)的比较
以下是 std::less 和 std::greater 的典型用法:
#include <functional>
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main() {vector<int> v {5, 2, 4, 3, 1};// 使用 std::less 来升序排序sort(v.begin(), v.end(), less<int>());for (int i : v) {cout << i << " ";}cout << endl;// 使用 std::greater 来降序排序sort(v.begin(), v.end(), greater<int>());for (int i : v) {cout << i << " ";}cout << endl;return 0;
}
输出:
1 2 3 4 5
5 4 3 2 1
函数对象模板 std::less 和 std::greater 的实现通常如下:
namespace std {template<class T>
struct less {bool operator()(const T& lhs, const T& rhs) const {return lhs < rhs;}
};template<class T>
struct greater {bool operator()(const T& lhs, const T& rhs) const {return lhs > rhs;}
};} // namespace std
在C++11及之后的版本中,由于引入了泛型 lambda 表达式,直接传递 lambda 函数给标准算法(如 std::sort),使得使用 std::greater 和 std::less 变得不那么必要了。以下是使用lambda表达式的例子:
#include <algorithm>
#include <iostream>
#include <vector>int main() {vector<int> v {2, 4, 1, 3, 5};// 使用lambda表达式作为比较函数进行升序排列sort(v.begin(), v.end(), [](int a, int b) { return a < b; });for (int i : v) {cout << i << " ";}cout << endl;// 使用lambda表达式作为比较函数进行降序排列sort(v.begin(), v.end(), [](int a, int b) { return a > b; });for (int i : v) {cout << i << " ";}cout << endl;return 0;
}
输出:
1 2 3 4 5
5 4 3 2 1
来看这里的参数传递
priority_queue<int,vector<int>,greater<int>> pq;
sort(v.begin(), v.end(), greater<int>());

priority_queue传的是一个类型,而sort需要传递对象,我们这里传递的是匿名对象
2.priority_queue的模拟实现
基本框架
基本框架如下:
#include<vector>
#include<iostream>
#include<list>using namespace std;
namespace myown {template<class T, class Container = vector<T>, class Compare = less<T>>class priority_queue{public:void adjust_up(size_t child){}void push(const T& x){}void adjust_down(size_t parent){}void pop(){}bool empty(){}size_t size(){}const T& top(){}private:Container _con;};
}
它的底层是堆,我们就使用vector作为底层容器
我们先补充简单的接口
🔥push( )
优先级队列里面,我们要插入数据,会进行向上调整
所以实现如下:
void push(const T& x)
{_con.push_back(x);adjust_up(_con.size() - 1);
}
🔥pop( )
pop需要删除堆顶的数据,我们的方式是首尾交换,尾删,再向下调整
void pop()
{swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);
}
🔥empty( )
直接判断即可
bool empty()
{return _con.empty();
}
🔥size( )
size_t size()
{return _con.size();
}
🔥top( )
取堆顶元素
const T& top()
{return _con[0];
}
接着我们来完成两个关键的函数,向上调整和向下调整
🔥adjust_up( )

当前位置每次和他的父节点比较
void adjust_up(size_t child)
{int parent = (child - 1) / 2;while (child > 0){if (_con[child]>_con[parent]){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
- 对于给定的子节点索引child,其父节点的索引计算为(child - 1) / 2
- 循环条件:while (child > 0)循环确保我们不会尝试移动根节点(因为根节点的索引为0,没有父节点)。循环继续执行,只要当前节点的索引大于0。
- 完成交换后,更新child变量为原父节点的索引,因为交换后当前元素已经移动到了父节点的位置。然后,对新的child值重新计算parent索引,继绀执行可能的进一步交换
- 循环终止条件:如果当前节点的值不小于其父节点的值(即堆的性质得到了满足),循环终止,else break;执行
🔥adjust_down( )
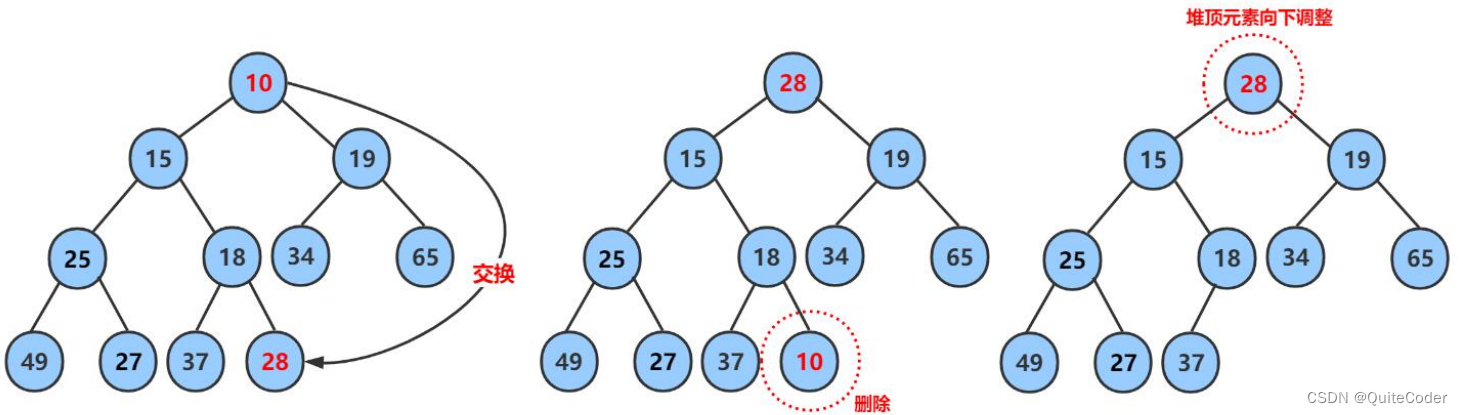
void Ajustdown(size_t parent)
{size_t child = parent * 2 + 1;while (child<_con.size()){if (child + 1 < _con.size() && _con[child + 1] >_con[child])//防止只有左孩子而越界{child++;}if (_con[child] >_con[parent]){Swap(&a[child], &a[parent]);parent = child;child = child * 2 + 1;}else{break;}}
}
两个调整函数的优化
我上面实现的代码只能完成一种堆的实现,如何进行封装使我们能够根据传参实现大堆或小堆呢?
这里就涉及到仿函数了,注意看我们模版中的第三个参数:
template<class T, class Container = vector<T>, class Compare = less<T>>
我们首先补充greater和less两个类:
template<class T>class less{public:bool operator()(const T& x, const T& y){return x < y;}};template<class T>class greater{public:bool operator()(const T& x, const T& y){return x > y;}};
我们控制大小堆,则需要控制两个adjust函数的比较逻辑
仿函数本质是一个类,可以通过模版参数进行传递,默认传的为less,控制它为大堆
template<class T, class Container = vector<T>, class Compare = less<T>>
void adjust_up(size_t child)
{Compare com;int parent = (child - 1) / 2;while (child > 0){//if (_con[child] > _con[parent])//if (_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
com是Compare的对象,它的对象可以像函数一样使用
void adjust_down(size_t parent)
{Compare com;size_t child = parent * 2 + 1;while (child < _con.size()){//if (child + 1 < _con.size() && _con[child + 1] >_con[child])//if (child + 1 < _con.size() && _con[child] < _con[child +1])if (child + 1 < _con.size() &&com(_con[child],_con[child +1])){++child;}//if (_con[child] > _con[parent])//if (_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
对于自定义类型的其他仿函数使用
如果在priority_queue中放自定义类型的数据,用户需要在自定义类型中提供> 或者< 的重载
class Date
{
public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){} bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}
private:int _year;int _month;int _day;
};
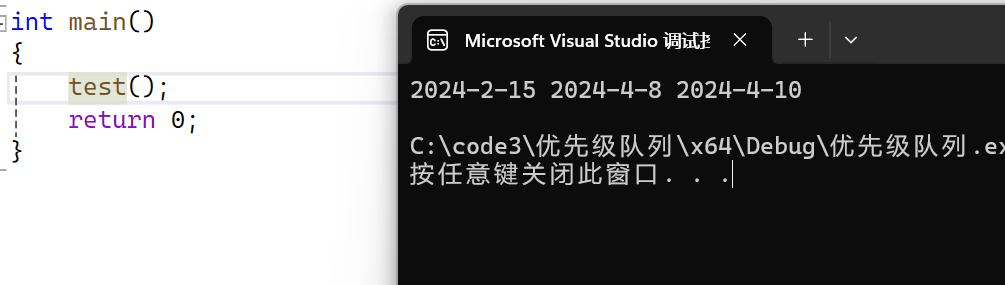
void test()
{myown::priority_queue<Date, vector<Date>, myown::greater<Date>> pq;Date d1(2024, 4, 8);pq.push(d1);pq.push(Date(2024, 4, 10));pq.push({ 2024, 2, 15 });while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;
}
结果如下:
再看下面这个:我如果存的是指针呢?
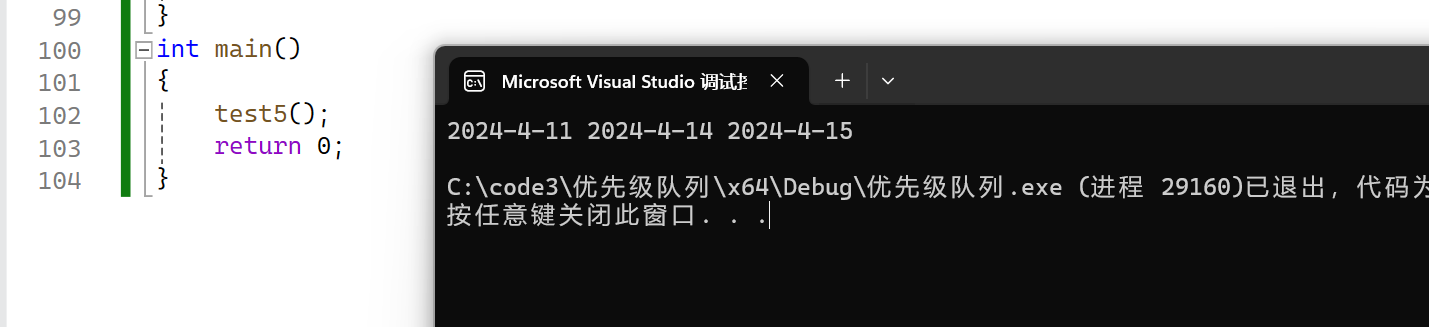
void test5()
{myown::priority_queue<Date*, vector<Date*>, myown::greater<Date*>> pqptr;pqptr.push(new Date(2024, 4, 14));pqptr.push(new Date(2024, 4, 11));pqptr.push(new Date(2024, 4, 15));while (!pqptr.empty()){cout << *(pqptr.top()) << " ";pqptr.pop();}cout << endl;
}
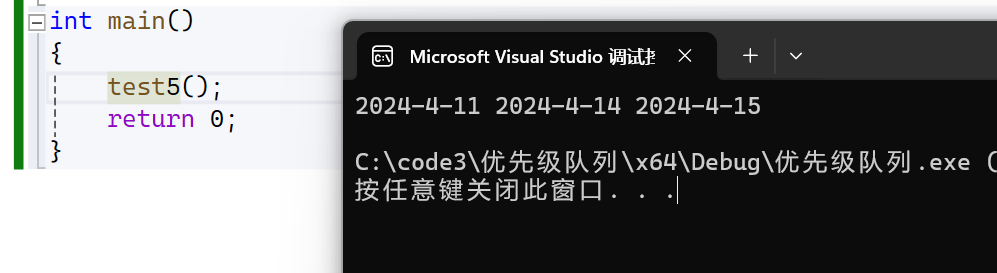
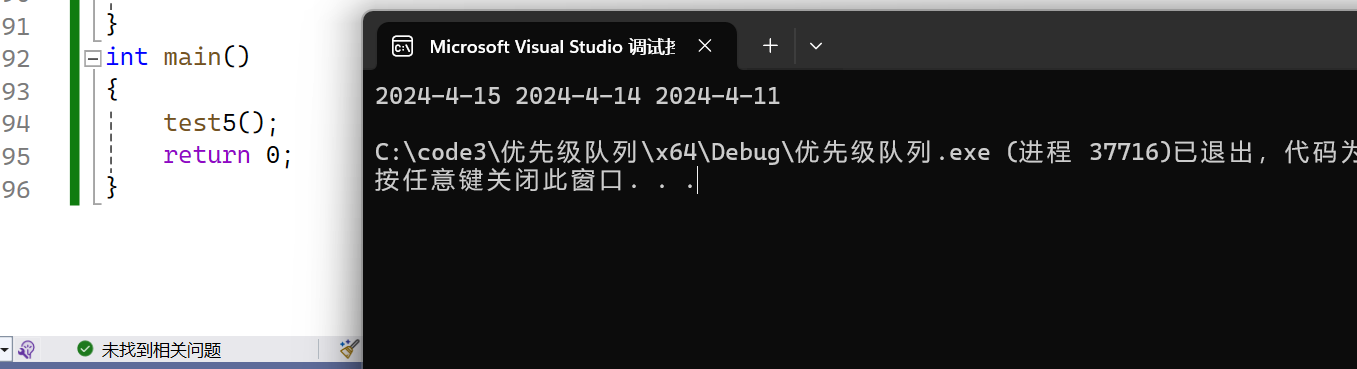
我们发现两次运行的结果不一样,这里是因为我们比较的是地址,而不是值,地址是new出来的,无法保证大小
我们需要重新构造一个仿函数:
class GreaterPDate
{
public:bool operator()(const Date* p1, const Date* p2){return *p1 > *p2;}
};myown::priority_queue<Date*, vector<Date*>,GreaterPDate> pqptr;
再看一个实际问题,如果我的一个结构体存储一个商品
struct Goods
{string _name; // 名字double _price; // 价格int _evaluate; // 评价Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}
};
我们可以利用仿函数来实现对不同指标的排序
struct ComparePriceLess
{bool operator()(const Goods& gl, const Goods& gr){return gl._price < gr._price;}
};
struct ComparePriceGreater
{bool operator()(const Goods& gl, const Goods& gr){return gl._price > gr._price;}
};struct CompareEvaluateLess
{bool operator()(const Goods& gl, const Goods& gr){return gl._evaluate < gr._evaluate;}
};
struct CompareEvaluateGreater
{bool operator()(const Goods& gl, const Goods& gr){return gl._evaluate > gr._evaluate;}
};
int main()
{vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };sort(v.begin(), v.end(), ComparePriceLess());sort(v.begin(), v.end(), ComparePriceGreater());sort(v.begin(), v.end(), CompareEvaluateLess());sort(v.begin(), v.end(), CompareEvaluateGreater());
}
有了仿函数,我们就可以对这种自定义类型实现想要的排序