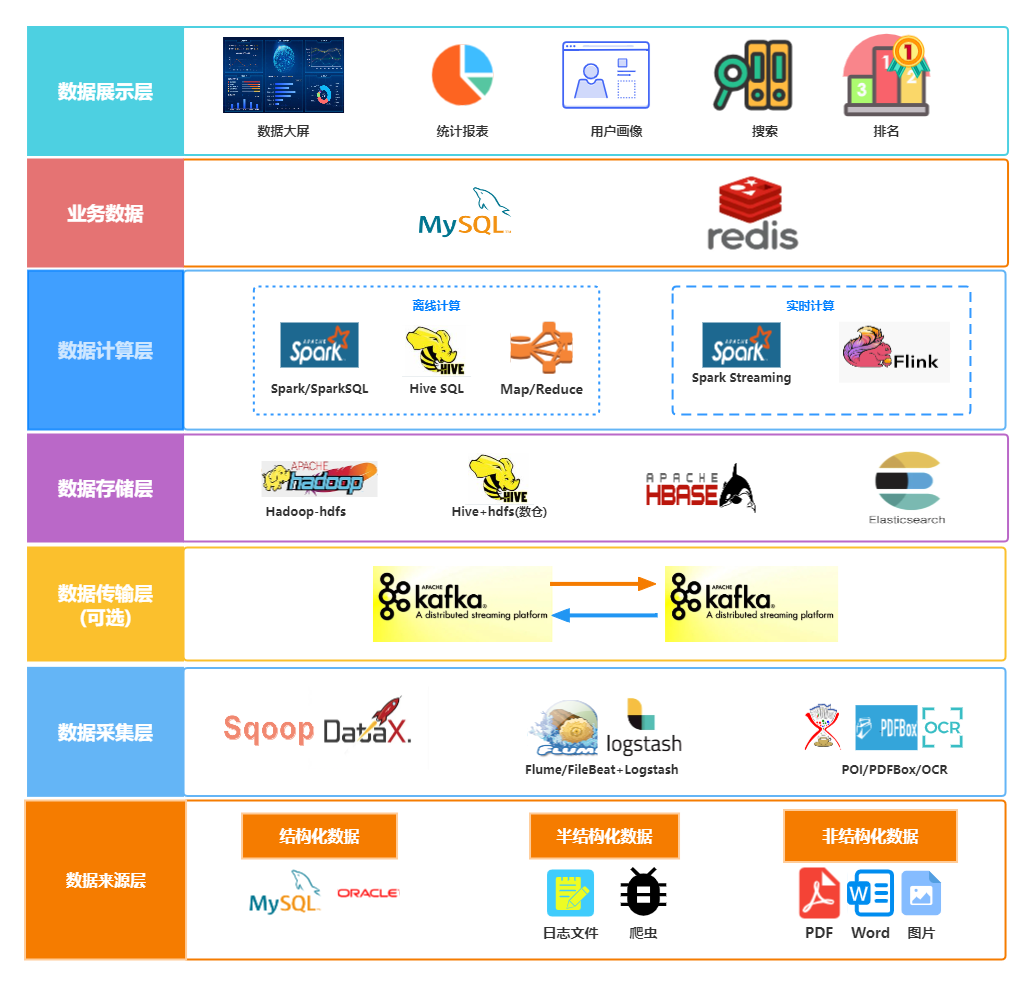
一、数据采集层

负责从各种数据源采集、清洗、转换、丰富以及格式化数据,可能包括结构化、半结构化和非结构化的数据。
1.1、常用的技术
在大数据领域,数据采集是一个关键的环节,常用的数据采集技术包括:
- Flume:Apache Flume是一个分布式、可靠、并且可用于高可用性环境的日志收集、聚合和传输系统。它通常用于从各种数据源(如网络服务器日志、传感器数据等)收集大量数据,并将其传输到数据存储或处理系统中。
- Sqoop:Apache Sqoop是用于在Apache Hadoop和关系型数据库之间进行数据传输的工具。它允许用户将结构化数据从关系型数据库(如MySQL、Oracle等)导入到Hadoop生态系统中(如HDFS、Hive等),也可以将数据从Hadoop导出到关系型数据库中。
- Logstash+Filebeat:Logstash是一个开源的日志收集和处理引擎,它可以从多个来源收集数据、转换数据格式并将数据发送到各种目的地。Filebeat是一个轻量级的日志收集工具,通常与Logstash配合使用,用于收集和传输日志文件。Logstash负责对数据进行过滤、解析和转换,然后将其发送到目标存储或处理系统(如Elasticsearch、Hadoop等)。
1.2、数据分类
结构化、半结构化和非结构化数据是指在数据管理和处理中的不同类型的数据:
- 结构化数据:这些数据以一种预定义的模型或格式进行组织,通常存储在数据库表格中,并且可以轻松地通过查询语言(如SQL)进行访问和处理。结构化数据具有明确定义的数据模式,其字段和值之间的关系清晰明确。例如,关系型数据库中的表格数据就是一种典型的结构化数据,其中每一列都有特定的数据类型,而每一行代表一个记录或实体。
- 半结构化数据:这类数据包含结构化数据和非结构化数据的混合体。虽然它们没有严格的数据模型,但它们可能具有某种程度的标记或标签,以便组织和查询。半结构化数据通常以XML、JSON等格式存储,具有层次结构或标记,但不像结构化数据那样具有明确的模式。例如,XML文档或JSON对象就是半结构化数据的常见形式,其中包含了数据的结构化组织,但某些字段可能是可选的或者不具有严格的数据类型。
- 非结构化数据:这种类型的数据没有明确的结构或组织方式,通常以自然语言、图像、音频或视频等形式存在。非结构化数据不容易用传统的数据库或表格来存储和处理,因为它们缺乏明确的模式或格式。例如,文档、电子邮件、社交媒体帖子、图像和视频文件等都属于非结构化数据的范畴。处理非结构化数据通常需要使用特殊的技术和工具,如自然语言处理(NLP)或图像识别技术。
二、数据存储层

1、主要职能
- 持久性存储:数据存储层负责将大数据系统中的数据永久性地保存在存储介质中,以便长期保留和访问。这包括结构化、半结构化和非结构化数据。持久性存储通常需要提供高容量、高可靠性和高性能的存储解决方案。
- 数据管理:数据存储层管理数据的组织、存储、备份、恢复和归档等任务。这包括数据的分区、索引、压缩、加密和权限控制等。数据管理的目标是确保数据的完整性、可靠性、安全性和可用性。
2、常用技术
在大数据领域,数据存储层的常用技术包括:
- Hadoop HDFS:HDFS是Apache Hadoop的核心组件之一,用于存储大规模数据集。它将数据分散存储在多个节点上,并提供高可靠性、容错性和高吞吐量。
- Apache HBase:HBase是一个分布式、面向列的数据库,用于实时读写大规模结构化数据。它建立在Hadoop HDFS之上,提供了高度可扩展性和实时访问能力。
- Elasticsearch:Elasticsearch是一个分布式搜索和分析引擎,用于存储和检索大规模半结构化和非结构化数据。它提供了强大的全文搜索、实时分析和数据可视化功能。
三、数据计算层

大数据计算层的主要职能是处理和分析大规模数据集,以支持数据驱动的决策制定。这一层包括了离线计算和在线计算两个部分,每个部分都有其专用的技术和工具。
离线计算主要用于处理大量的非实时数据。它可以进行深入的数据分析,通常用于生成报告、数据挖掘、机器学习等场景。常用的离线计算技术包括:
- Spark SQL: 用于执行SQL查询的分布式计算框架。
- Hadoop MapReduce: 一个可扩展的数据处理工具,适用于大数据集的分析。
- Apache Impala: 提供高性能、低延迟的SQL查询功能,适用于Hadoop数据。
- Apache Kylin: 为大规模数据提供OLAP(在线分析处理)功能。
- Hive: 一个数据仓库工具,可以处理大数据并提供SQL查询功能。
在线计算则更侧重于实时数据处理,支持快速的数据查询和分析,适用于需要即时反馈的应用场景。常用的在线计算技术包括:
- Spark Streaming: 用于处理实时数据流的分布式计算系统。
- Flink: 专注于分布式流处理和批处理的开源平台。
- Storm: 一个实时大数据处理框架。
- Clickhouse: 一个用于在线分析处理查询的列式数据库管理系统。
- Presto: 一个分布式SQL查询引擎,适用于大规模数据集。
四、数据应用层

这一层负责将数据结果可视化或提供给第三方应用,常用的技术有:
- Tableau:数据可视化工具。
- Zeppelin:基于Web的笔记本,支持数据驱动、交互式数据分析和协作。
- Superset:数据探索和可视化平台。