这里讲解DM数据库的操作,主要涉及聚集函数、分析函数、日期运算、日期操作等操作。
聚集函数
MAX、MIN、SUM、AVG、COUNT
SQL 中的聚集函数共包括 5 个 (MAX、MIN、SUM、AVG、COUNT),可以帮我们求某列的最大值、最小值及平均值等
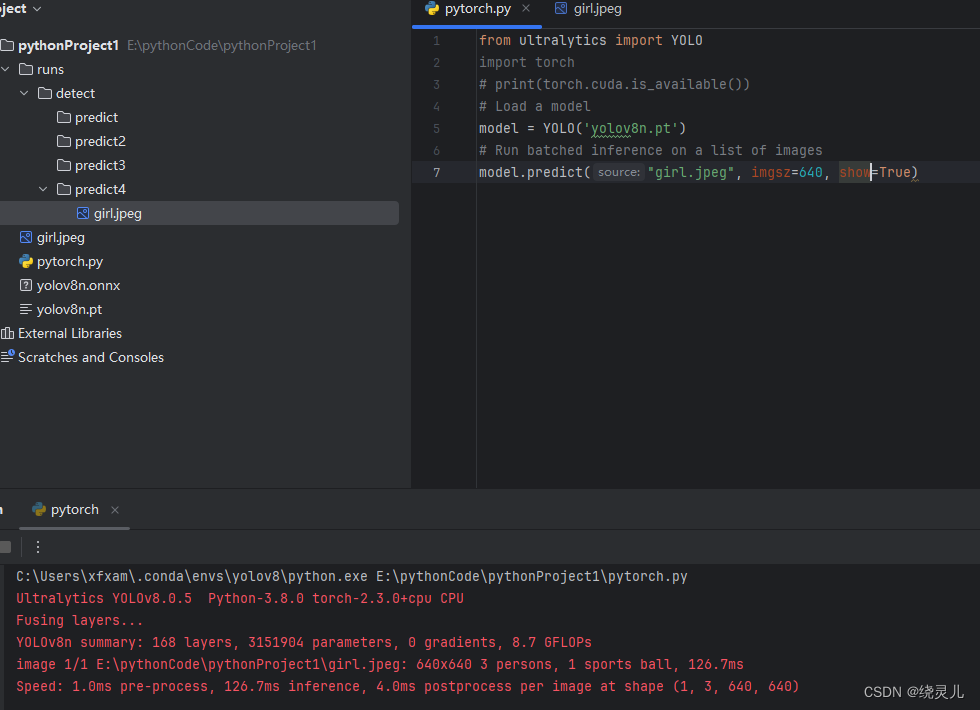
-- 查询每个部门员工的平均薪资、最小薪资、最大薪资、总工资及总记录SELECT deptno,AVG (salary) AS 平均值,MIN (salary) AS 最小值,MAX (salary) AS 最大值,SUM (salary) AS 工资合计,COUNT (*) AS 总行数FROM employee GROUP BY deptno;
查询结果如图
当表中没有数据时,不加 group by 会返回一行数据,加了 group by 无数据返回,先建空表
CREATE TABLE employee2 AS SELECT * FROM employee WHERE 1 = 2;
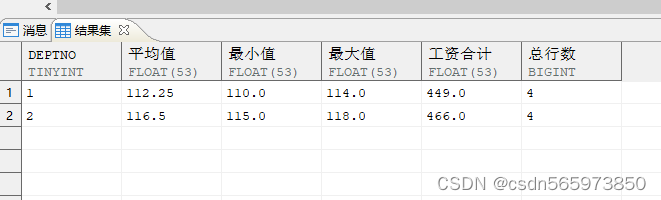
不加 group by
SELECT COUNT (*) AS cnt, SUM (salary) AS sum_sal FROM employee2 WHERE deptno = 11;
执行结果如图
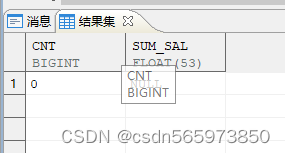
增加 group by
SELECT COUNT (*) AS cnt, SUM (salary) AS sum_sal FROM employee2 WHERE deptno = 11 group by deptno;
执行结果如图
清空表数据
truncate table TEST
使用分析函数 sum (…) over (order by…) 可以生成累计和
使用分析函数 sum (…) over (order by…) 可以生成累计和,查询部门1下的工资累计
-- 按员工编号排序对员工的工资进行累加SELECT empno AS 编号,ename AS 姓名,salary AS 人工成本,SUM (salary) OVER (ORDER BY empno) AS 成本累计FROM employeeWHERE deptno = 1;
执行结果如图
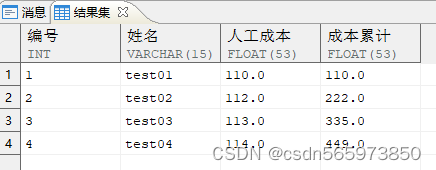
结果是当前部门下按照empno排序从第一行到当前行的所有工资之和,为了形象地说明这一点,我们用 listagg 模拟出每一行是哪些值相加
-- 使用 listagg 函数模拟员工总成本的累加值SELECT empno AS 编号,ename AS 姓名,salary AS 人工成本,SUM (salary) OVER (ORDER BY empno) AS 成本累计,(SELECT LISTAGG (salary, '+') WITHIN GROUP (ORDER BY empno)FROM employee bWHERE b.deptno = 1 AND b.empno <= a.empno) 计算公式FROM employee aWHERE deptno = 1ORDER BY empno;
执行结果如图
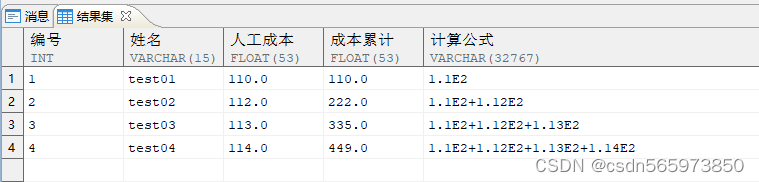
更改累计和的值
更改累计和的值,为了方便测试,创建视图
CREATE OR REPLACE VIEW v (id,amt,trx) ASSELECT 1,100,'PR' FROM dual UNION ALLSELECT 2,100,'PR' FROM dual UNION ALLSELECT 3,50,'PY' FROM dual UNION ALLSELECT 4,100,'PR' FROM dual UNION ALLSELECT 5,200,'PY' FROM dual UNION ALLSELECT 6,50,'PY' FROM dual;SELECT * FROM v;
创建完成后结果如图
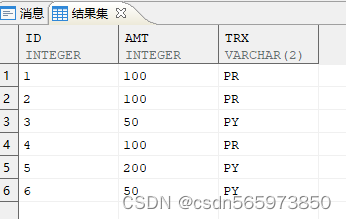
• id 是唯一列。
• amt 列表示每次事务处理(存款或取款)涉及到的金额。
• trx 定义了事务的类型,取款是 PY,存款是 PR。
先要求计算每次存/取款后的余额,如果 trx 是 PR,则加上 amt 值代表的金额;否则减去 amt 值代表的金额。这实际上是一个累加问题,我们可以把取款的值先变成负数。
SELECT id,CASE WHEN trx = 'PY' THEN '取款' ELSE '存款' END 存取类型,amt 金额,(CASE WHEN trx = 'PY' THEN -amt ELSE amt END) AS 余额FROM vORDER BY id;
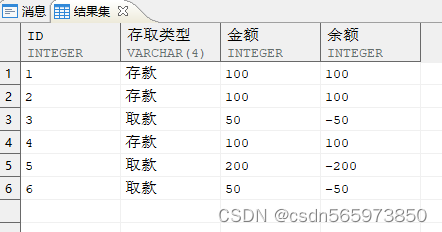
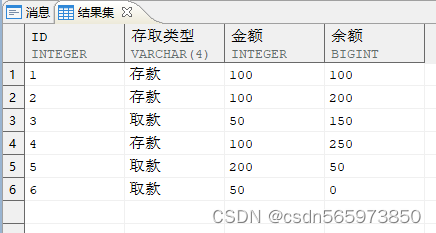
累加处理后的结果
SELECT id,CASE WHEN trx = 'PY' THEN '取款' ELSE '存款' END 存取类型,amt 金额,SUM (CASE WHEN trx = 'PY' THEN -amt ELSE amt END) OVER (ORDER BY id)AS 余额FROM vORDER BY id;
执行结果如图
计算出现次数最多的值
使用 partition by 子句查看部门中哪个工资等级的员工最多
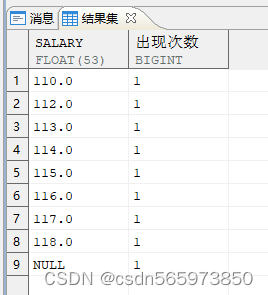
1.计算不同工资出现的次数
SELECT salary, COUNT (*) AS 出现次数 FROM employee GROUP BY salary;
执行结果如图
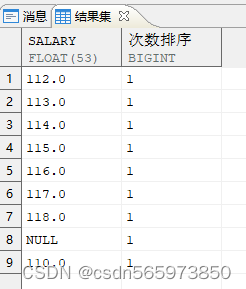
2.按次数排序生成序号
SELECT salary,DENSE_RANK () OVER (ORDER BY 出现次数 DESC) AS 次数排序 FROM ( SELECT salary, COUNT (*) AS 出现次数 FROM employee GROUP BY salary);
执行结果如图
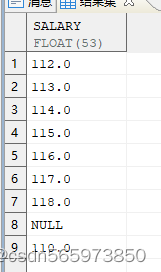
3.根据序号过滤得到需要的结果
SELECT salary FROM (SELECT salary, DENSE_RANK () OVER (ORDER BY 出现次数 DESC) AS 次数排序FROM ( SELECT salary, COUNT (*) AS 出现次数 FROM employee GROUP BY salary) x) yWHERE 次数排序 = 1;
执行结果如图
4.利用 partition by 子句查询各部门哪个工资等级的员工最多
SELECT deptno, salary FROM (SELECT deptno,salary,DENSE_RANK () OVER (PARTITION BY deptno ORDER BY 出现次数 DESC)AS 次数排序FROM ( SELECT salary, deptno, COUNT (*) AS 出现次数 FROM employee GROUP BY deptno, salary) x) yWHERE 次数排序 = 1;
执行结果如图
部门 1 、 2 中各工资档次出现次数都为 1,所以返回所有的数据。
日期运算
加减日、月、年
date 类型的数据可以直接加减天数,加减月份需要使用 add_months 函数,同时也可以使用 add_days 加减天数
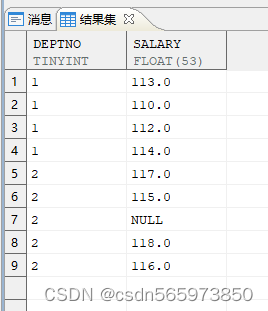
SELECT hiredate AS 聘用日期,add_days (hiredate, -5) AS 减5天,add_days (hiredate, 5) AS 加5天,add_months (hiredate, -5) AS 减5月,add_months (hiredate, 5) AS 加5月,add_months (hiredate, -5 * 12) AS 减5年,add_months (hiredate, 5 * 12) AS 加5年FROM employeeWHERE ROWNUM <= 1;
执行结果如图
加减时、分、秒
时间类型的数据可以直接加减时、分、秒,1/24 指的是 1 小时
select sysdate as 当前日期,sysdate - 5.0 / 24 as 减5小时,sysdate + 5.0 / 24 as 加5小时,sysdate - 5.0 / 24 / 60 as 减5分钟,sysdate + 5.0 / 24 / 60 as 加5分钟from dual;
执行结果如图

日期间隔之时、分、秒
两个 date 相减,得到的是天数,乘以 24 即为小时,以此类推可计算出秒。employee 表数据如下
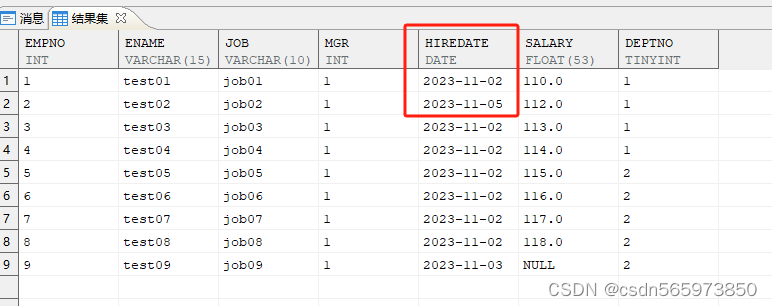
计算日期间隔
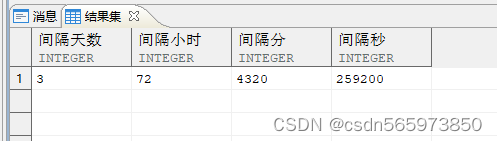
SELECT 间隔天数,间隔天数 * 24 AS 间隔小时,间隔天数 * 24 * 60 AS 间隔分,间隔天数 * 24 * 60 * 60 AS 间隔秒FROM (SELECT MAX (hiredate) - MIN (hiredate) AS 间隔天数FROM employeeWHERE empno IN (1,2)) x;
执行结果如图
日期间隔之日、月、年
使用 months_between 函数计算间隔月份,以此类推计算出间隔年
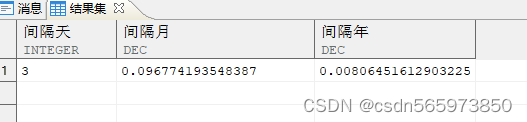
SELECT max_hd - min_hd 间隔天,MONTHS_BETWEEN (max_hd, min_hd) 间隔月,MONTHS_BETWEEN (max_hd, min_hd) / 12 间隔年FROM (SELECT MAX (hiredate) max_hd, MIN (hiredate) min_hdFROM employee);
执行结果如图
求两个日期间的工作天数
查询原始数据
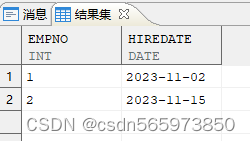
SELECT empno, hiredate FROM employee WHERE empno IN (1,2);
执行结果如图
将原始数据转为一行
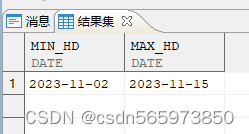
SELECT MIN (hiredate) AS min_hd, MAX (hiredate) AS max_hd FROM employee WHERE empno IN (1,2);
枚举两个日期之间的天数
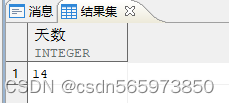
select (max_hd-min_hd)+1 as 天数 from (SELECT MIN (hiredate) AS min_hd, MAX (hiredate) AS max_hd FROM employee WHERE empno IN (1,2));
创建中间表t500
CREATE TABLE t500 AS SELECT LEVEL AS ID FROM dual CONNECT BY LEVEL <= 500;
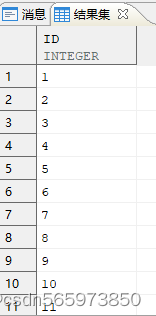
与 t500 做笛卡尔积枚举 30 天的所有日期
SELECT min_hd + (t500.id - 1) AS 日期FROM (SELECT MIN (hiredate) AS min_hd, MAX (hiredate) AS max_hd FROM employee WHERE empno IN (1,2)) x,t500WHERE t500.id <= ( (max_hd - min_hd) + 1);
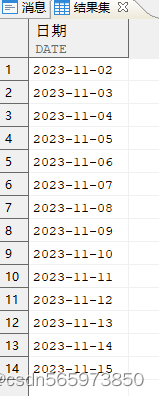
根据日期得到对应的工作日信息
SELECT 日期, TO_CHAR (日期, 'DY', 'NLS_DATE_LANGUAGE = American') AS dy FROM (SELECT min_hd + (t500.id - 1) AS 日期FROM (SELECT MIN (hiredate) AS min_hd, MAX (hiredate) AS max_hd FROM employee WHERE empno IN (1,2)) x,t500WHERE t500.id <= ( (max_hd - min_hd) + 1));
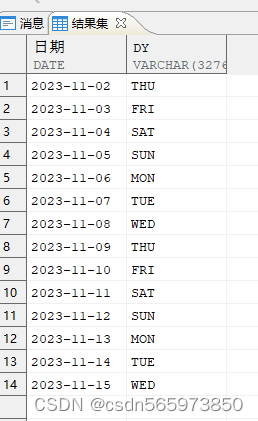
过滤工作日数据汇总
SELECT COUNT(*) FROM (SELECT 日期, TO_CHAR (日期, 'DY', 'NLS_DATE_LANGUAGE = American') AS dy FROM (SELECT min_hd + (t500.id - 1) AS 日期FROM (SELECT MIN (hiredate) AS min_hd, MAX (hiredate) AS max_hd FROM employee WHERE empno IN (1,2)) x,t500WHERE t500.id <= ( (max_hd - min_hd) + 1))) WHERE dy NOT IN ('SAT','SUN');
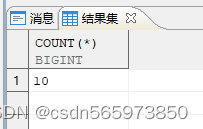
得到10个工作日。
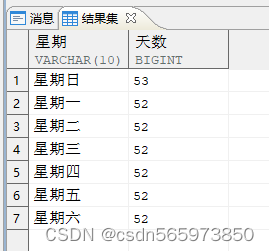
求一年中周内各日期的天数
可以按照以下步骤分析
• 取得大当前年度信息。
• 计算一年有多少天。
• 生成日期列表。
• 转换为对应的星期标识。
• 汇总统计。
WITH x0 AS (SELECT TO_DATE ('2023-01-01', 'yyyy-mm-dd') AS 年初 FROM DUAL),x1 AS (SELECT 年初, ADD_MONTHS (年初, 12) AS 下年初 FROM x0),x2 AS (SELECT 年初, 下年初, 下年初 - 年初 AS 天数 FROM x1),x3 AS (SELECT 年初 + (LEVEL - 1) AS 日期 FROM x2 CONNECT BY LEVEL <= 天数),x4 AS (SELECT 日期, TO_CHAR (日期, 'DY') AS 星期 FROM x3)SELECT 星期, COUNT (*) AS 天数 FROM x4 GROUP BY 星期;
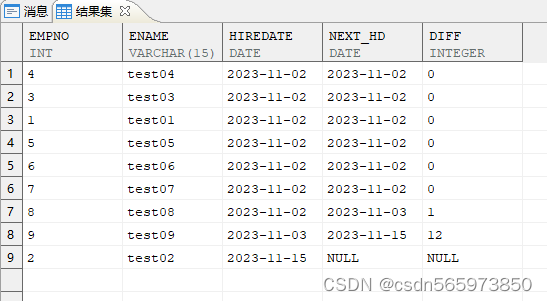
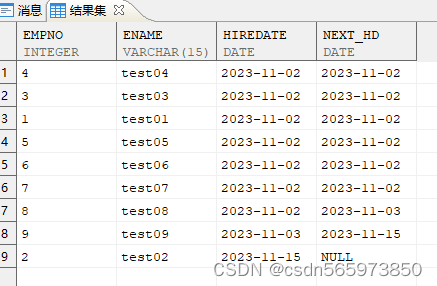
确定当前记录和下一条记录之间相差的天数
使用 lead() over() 分析函数
SELECT empno,ename,hiredate,LEAD (hiredate) OVER (ORDER BY hiredate) next_hd FROM employee;
计算日期差值
SELECT empno,ename,hiredate,next_hd,next_hd-hiredate diff FROM (SELECT empno,ename,hiredate,LEAD (hiredate) OVER (ORDER BY hiredate) next_hd FROM employee);