今天我们来进行Mit6.S081实验一的内容。
实验任务
一、启动xv6(难度:Easy)
获取实验室的xv6源代码并切换到util分支。
$ git clone git://g.csail.mit.edu/xv6-labs-2020 Cloning into 'xv6-labs-2020'... ... $ cd xv6-labs-2020 $ git checkout util Branch 'util' set up to track remote branch 'util' from 'origin'. Switched to a new branch 'util'1.构建并运行xv6
make qemu
2.测试xv6
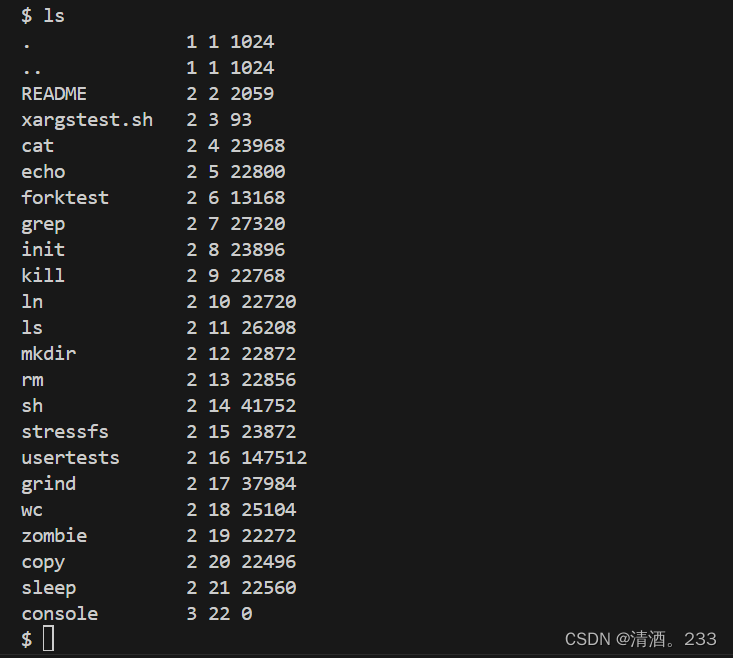
这些是
mkfs在初始文件系统中包含的文件;大多数是可以运行的程序。刚刚跑了其中的:ls、cat。3.退出qemu
查看xv6中的进程:Ctrl+p(xv6没有实现ps程序),
退出qemu启动的xv6:Ctrl+a x4.分析
xv6通过qemu启动完成后,启动了shell进程。通过shell,启动子进程ls、cat,显示了xv6目录下的文件。
参考:Lab1: Xv6 and Unix utilities · 6.S081 All-In-One (dgs.zone)


二、sleep(难度:Easy)
1.需求
实现xv6的UNIX程序sleep:您的
sleep应该暂停到用户指定的计时数。一个滴答(tick)是由xv6内核定义的时间概念,即来自定时器芯片的两个中断之间的时间。您的解决方案应该在文件user/sleep.c中2.提示
第一章 操作系统接口 · 6.S081 All-In-One (dgs.zone)(参考)
在你开始编码之前,请阅读《book-riscv-rev1》的第一章(上述链接)。
看看其他的一些程序(如/user/echo.c, /user/grep.c, /user/rm.c)查看如何获取传递给程序的命令行参数
如果用户忘记传递参数,
sleep应该打印一条错误信息命令行参数作为字符串传递; 您可以使用
atoi将其转换为数字(详见/user/ulib.c)使用系统调用
sleep请参阅kernel/sysproc.c以获取实现
sleep系统调用的xv6内核代码(查找sys_sleep),user/user.h提供了sleep的声明以便其他程序调用,用汇编程序编写的user/usys.S可以帮助sleep从用户区跳转到内核区。确保
main函数调用exit()以退出程序。将你的
sleep程序添加到Makefile中的UPROGS中;完成之后,make qemu将编译您的程序,并且您可以从xv6的shell运行它。参考以下代码(查看如何获取传递给程序的命令行参数)
types.h
typedef unsigned int uint; typedef unsigned short ushort; typedef unsigned char uchar;typedef unsigned char uint8; typedef unsigned short uint16; typedef unsigned int uint32; typedef unsigned long uint64;typedef uint64 pde_t;/* 这段代码是在 C 语言中使用 typedef 关键字定义了一些新的数据类型:uint:无符号整数,通常是 unsigned int 类型。 ushort:无符号短整数,通常是 unsigned short 类型。 uchar:无符号字符,通常是 unsigned char 类型。 然后定义了一些更具体的无符号整数类型:uint8:8 位无符号整数,通常是 unsigned char 类型。 uint16:16 位无符号整数,通常是 unsigned short 类型。 uint32:32 位无符号整数,通常是 unsigned int 类型。 uint64:64 位无符号整数,通常是 unsigned long 类型。 最后,定义了一个名为 pde_t 的类型,它被定义为 uint64 类型,通常用于表示页表项(Page Directory Entry)中的地址或者数据。 */start.h
#define T_DIR 1 // Directory #define T_FILE 2 // File #define T_DEVICE 3 // Devicestruct stat {int dev; // File system's disk deviceuint ino; // Inode numbershort type; // Type of fileshort nlink; // Number of links to fileuint64 size; // Size of file in bytes };/* 这段代码定义了一些常量以及一个结构体 struct stat,用于描述文件系统中文件的状态信息。常量定义: T_DIR:表示目录类型,其值为 1。 T_FILE:表示文件类型,其值为 2。 T_DEVICE:表示设备类型,其值为 3。 结构体 struct stat 包含以下成员: int dev:表示文件所在的文件系统的磁盘设备。 uint ino:表示文件的 inode 号码。 short type:表示文件的类型,可以是 T_DIR、T_FILE 或者 T_DEVICE。 short nlink:表示指向该文件的硬链接数目。 uint64 size:表示文件的大小,以字节为单位。 这个结构体用于保存文件的各种属性信息,比如文件类型、大小、所在设备等。在实际的文件系统中,通过这些信息可以对文件进行管理和操作。 */user.h
struct stat; struct rtcdate;// system calls int fork(void); int exit(int) __attribute__((noreturn)); int wait(int*); int pipe(int*); int write(int, const void*, int); int read(int, void*, int); int close(int); int kill(int); int exec(char*, char**); int open(const char*, int); int mknod(const char*, short, short); int unlink(const char*); int fstat(int fd, struct stat*); int link(const char*, const char*); int mkdir(const char*); int chdir(const char*); int dup(int); int getpid(void); char* sbrk(int); int sleep(int); int uptime(void);// ulib.c int stat(const char*, struct stat*); char* strcpy(char*, const char*); void *memmove(void*, const void*, int); char* strchr(const char*, char c); int strcmp(const char*, const char*); void fprintf(int, const char*, ...); void printf(const char*, ...); char* gets(char*, int max); uint strlen(const char*); void* memset(void*, int, uint); void* malloc(uint); void free(void*); int atoi(const char*); int memcmp(const void *, const void *, uint); void *memcpy(void *, const void *, uint);/* 这段代码展示了一些结构体和系统调用函数的声明,以及一些在 ulib.c 文件中实现的库函数声明。这些声明通常用于操作系统的实现中,特别是在 Unix/Linux 系统中。struct stat; 和 struct rtcdate;:这些是结构体声明,但是具体的结构体定义并没有在这段代码中给出。这样的声明表明这些结构体在其他地方有定义,可能是在其他文件或者系统头文件中。 系统调用函数声明: 这些函数声明了一些常见的系统调用函数,如 fork、exit、wait、pipe 等,用于操作进程、文件和系统状态等。 每个函数声明描述了函数的参数和返回类型,有些函数使用了 __attribute__((noreturn)) 指示函数不会返回(如 exit)。 ulib.c 文件中的库函数声明: 这些函数声明了一些在 ulib.c 文件中实现的库函数,如字符串操作函数 strcpy、strcmp、内存操作函数 memmove、memset 等,以及输出函数 fprintf、printf 和内存分配函数 malloc、free 等。 这些声明描述了操作系统的核心功能,包括进程管理、文件操作、内存管理等。 */echo.c
#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h"int main(int argc, char *argv[]) {int i;for(i = 1; i < argc; i++){write(1, argv[i], strlen(argv[i]));if(i + 1 < argc){write(1, " ", 1);} else {write(1, "\n", 1);}}exit(0); } /* #include "kernel/types.h"、#include "kernel/stat.h"、#include "user/user.h":这些是头文件包含语句,用于包含所需的系统头文件,以便在程序中使用相关的函数和数据结构。 main 函数:这是程序的入口函数,它接收命令行参数 argc 和 argv[],其中 argc 表示参数的个数,argv[] 是一个指向参数字符串数组的指针。 for 循环:遍历命令行参数数组 argv[],从索引 1 开始(跳过程序名称本身),将每个参数字符串使用 write 函数写入到标准输出(文件描述符 1)。 write 函数:用于向文件描述符写入数据,第一个参数是文件描述符(1 表示标准输出),第二个参数是要写入的数据,第三个参数是要写入的数据长度。 在循环中,如果不是最后一个参数,则在参数之间插入空格;如果是最后一个参数,则在参数后面插入换行符 \n。 exit(0):正常退出程序,参数 0 表示程序正常结束。 */grep.c
// Simple grep. Only supports ^ . * $ operators.#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h"char buf[1024]; int match(char*, char*);void grep(char *pattern, int fd) {int n, m;char *p, *q;m = 0;while((n = read(fd, buf+m, sizeof(buf)-m-1)) > 0){m += n;buf[m] = '\0';p = buf;while((q = strchr(p, '\n')) != 0){*q = 0;if(match(pattern, p)){*q = '\n';write(1, p, q+1 - p);}p = q+1;}if(m > 0){m -= p - buf;memmove(buf, p, m);}} }int main(int argc, char *argv[]) {int fd, i;char *pattern;if(argc <= 1){fprintf(2, "usage: grep pattern [file ...]\n");exit(1);}pattern = argv[1];if(argc <= 2){grep(pattern, 0);exit(0);}for(i = 2; i < argc; i++){if((fd = open(argv[i], 0)) < 0){printf("grep: cannot open %s\n", argv[i]);exit(1);}grep(pattern, fd);close(fd);}exit(0); }// Regexp matcher from Kernighan & Pike, // The Practice of Programming, Chapter 9.int matchhere(char*, char*); int matchstar(int, char*, char*);int match(char *re, char *text) {if(re[0] == '^')return matchhere(re+1, text);do{ // must look at empty stringif(matchhere(re, text))return 1;}while(*text++ != '\0');return 0; }// matchhere: search for re at beginning of text int matchhere(char *re, char *text) {if(re[0] == '\0')return 1;if(re[1] == '*')return matchstar(re[0], re+2, text);if(re[0] == '$' && re[1] == '\0')return *text == '\0';if(*text!='\0' && (re[0]=='.' || re[0]==*text))return matchhere(re+1, text+1);return 0; }// matchstar: search for c*re at beginning of text int matchstar(int c, char *re, char *text) {do{ // a * matches zero or more instancesif(matchhere(re, text))return 1;}while(*text!='\0' && (*text++==c || c=='.'));return 0; }/* 这段代码实现了一个简单的 grep 命令,可以在文本中搜索指定的模式(pattern)。它支持基本的正则表达式操作符 ^、.、* 和 $。以下是代码中主要部分的解释:grep 函数: 接收一个模式 pattern 和一个文件描述符 fd(如果为 0,则表示从标准输入读取)。 使用 read 函数从文件描述符中读取数据到缓冲区 buf 中。 使用 match 函数匹配模式并输出匹配的行。 main 函数: 解析命令行参数,如果参数个数不符合要求则打印用法信息并退出。 提取模式 pattern 和需要搜索的文件。 对每个文件,打开文件并调用 grep 函数进行搜索,最后关闭文件。 match、matchhere 和 matchstar 函数: 这些函数实现了简单的正则表达式匹配逻辑。 match 函数用于在文本中查找模式。 matchhere 函数用于在文本开头匹配模式。 matchstar 函数用于处理 * 操作符。 这个程序的核心逻辑在于 match 函数和相关的匹配函数,它们用于实现基本的正则表达式匹配功能。 */rm.c
#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h"int main(int argc, char *argv[]) {int i;if(argc < 2){fprintf(2, "Usage: rm files...\n");exit(1);}for(i = 1; i < argc; i++){if(unlink(argv[i]) < 0){fprintf(2, "rm: %s failed to delete\n", argv[i]);break;}}exit(0); }/* 这段代码实现了一个简单的 rm(删除文件)命令,可以删除指定的文件。让我们来看一下代码的主要部分:#include "kernel/types.h"、#include "kernel/stat.h"、#include "user/user.h":这些是头文件包含语句,用于包含所需的系统头文件和声明相关的函数和数据结构。 main 函数:这是程序的入口函数,它接收命令行参数 argc 和 argv[],其中 argc 表示参数的个数,argv[] 是一个指向参数字符串数组的指针。 参数检查:程序首先检查参数个数是否符合要求,如果小于 2,则打印用法信息并退出程序。 循环删除文件:程序使用 unlink 函数删除每个指定的文件。如果删除失败(unlink 返回值小于 0),则打印错误信息,并退出循环。 exit:正常退出程序,参数 0 表示程序正常结束。 */3.sleep代码(写在user/sleep.c)
#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" // 必须以这个顺序 include,由于三个头文件有依赖关系int main(int argc, char **argv) {if (argc < 2){printf("usage: sleep <ticks>\n");exit(0);}sleep(atoi(argv[1]));exit(0); }/* 代码实现了一个简单的 sleep 命令,用于让当前进程睡眠指定的时钟 tick 数量。以下是代码的一些说明:错误处理: 如果参数个数小于 2,即用户未提供睡眠时间参数,程序会打印用法信息并退出。 参数转换: 通过 atoi 函数将字符串形式的睡眠时间参数转换为整数。 睡眠功能: 使用 sleep 系统调用使当前进程睡眠指定的时钟 tick 数量。 退出码: 程序成功执行后,返回退出码 0,表示正常结束。 */4.编译配置
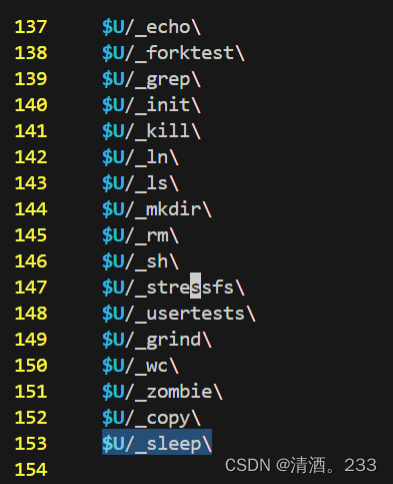
在Makefile下添加配置。
5.测试sleep程序
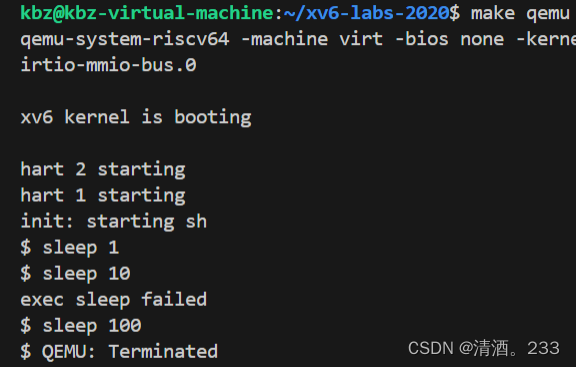
xv6通过qemu启动完成后,启动了shell进程。通过shell,启动子进程sleep。