目录
3.1 冒泡排序
3.2 快速排序
Hoare版本快速排序
挖坑法快速排序
前后指针法快速排序
快速排序优化-三数取中法
快速排序非递归
3.1 冒泡排序
思想:升序情况下:左边大于右边就进行交换,每一次把最大的放在最后一位。
void Swap(int* p1, int* p2){int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void BubbleSort(int* a, int n){//int a[] = {6,7,2,1,9,4};int end = n;//end后方均有序while (end) {int flag = 1;//假设已经排序成功for (int i = 0; i < n-1; i++) {if(a[i] > a[i+1]){flag = 0;//发生交换就说明无序Swap(&a[i], &a[i+1]);}}if(flag == 1) break;//说明没有发生交换——》已经有序//跳出循环end--;}
}3.2 快速排序
Hoare版本快速排序
Hoare版本快速排序基本思想:取一值为key(一般取第一个数为key),在利用左右指针(双指针法),先右指针(right)找比key小的数,再左指针(left)找比key大的数据。如果找到了就交换左右指针的数据,当左右指针相遇的时候,就将相遇的数据与key进行交换,完成一次排序。接着对key的左边部分进行排序,方法与前相同,再对key右边排序,方法与前相同。由此可见,这是一个递归。
以接下来数组排序为例
int a[] = {9,5,6,3,15,13,32,18};
代码如下:
intPartSort(int* a,int left,int right){int key = left;//左找大 右找小while (left < right) {//右找小while (left < right && a[right] >= a[key]) {right--;}//左找大while (left < right && a[left] <= a[key]) {left++;}//交换左右指针数据Swap(&a[left], &a[right]);}//交换key值Swap(&a[key], &a[left]);return left;
}voidQuickSort(int* a,int left,int right){if(left >= right){return;}int key = PartSort(a, left, right);QuickSort(a, left, key-1);QuickSort(a, key+1, right);
}Hoare版本问题分析
1⃣️ 对于key值,一般取首元素作为key值,当然也可以使用最后元素作为key值,需要注意的是,当使用首元素作为key值的时候,left一定取在首元素(即key所在位置)位置,如果不在则会出现以下情况
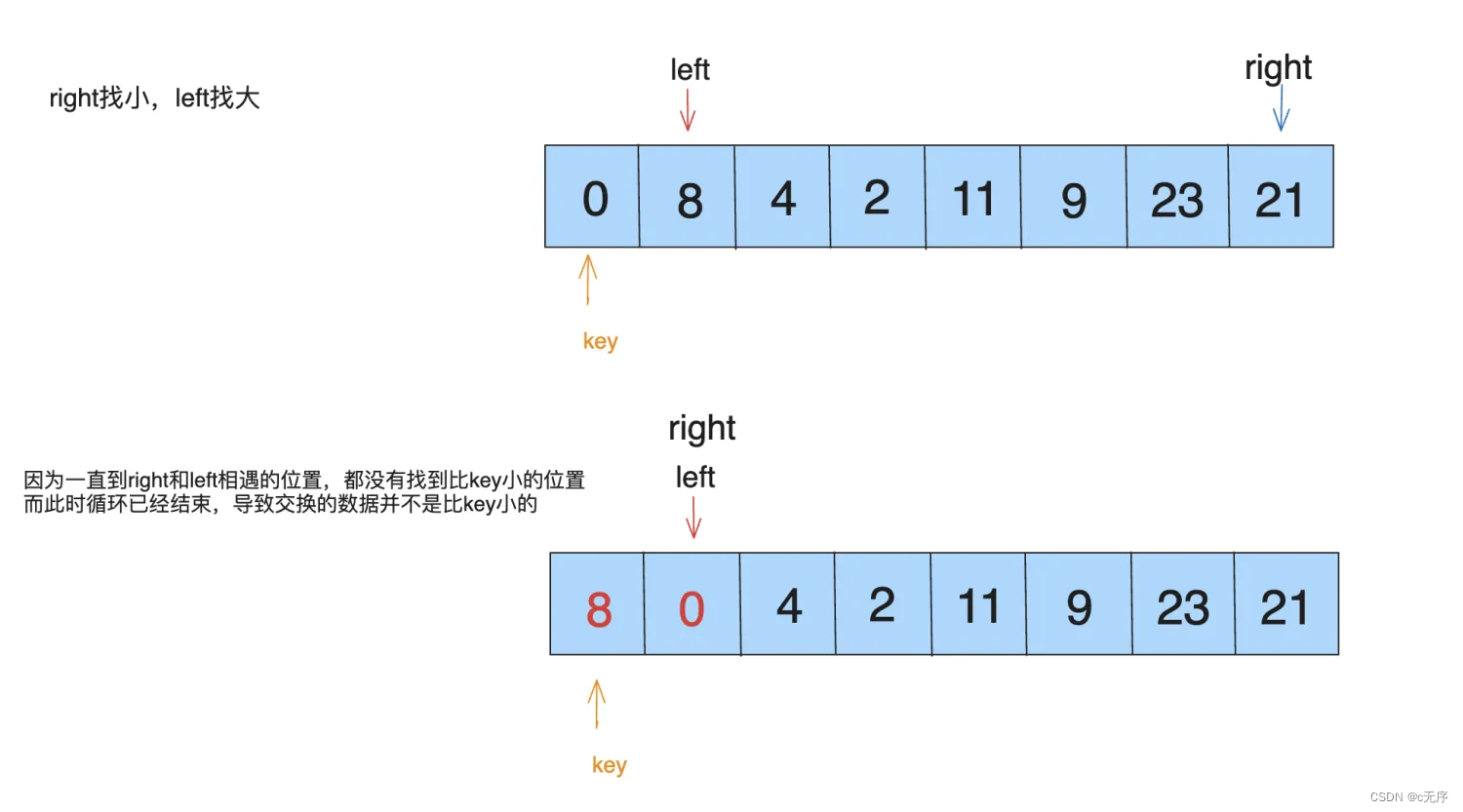
2⃣ ️当left指针和right指针移动的时候,一定要包含等于情况。如果不等于则出现以下情况

3⃣ 递归结束条件分析,为什么是left >= right,就返回?
当二分下去后只剩一个数或者一个数都没有的时候就是有序,无需排序。如果只有等于,当某边为空的时候,此时传过来的key值为0,且key = left 那么传到下一个递归区间就变成了【0,-1】显然不和规矩,因此必须加 > 。
if(left >= right){return;
}️挖坑法快速排序
挖坑法快速排序与Hoare版本的快速排序相比没有效率上的优化。
其基本思想是:从数据中随机选出一值为key,记录key的值,而该值的位置也是挖坑法中的坑(hole),接着利用左右指针,left在数组第一位,right在最后一位,两边向中间走,此时并没有规定谁先走,即可以left先走也可以right先走。我们假设right先走,先right找小(比key小),找到之后用right所指的数值覆盖hole的数值,再更新hole的位置到right上;再left走,找比key大的数值,找到之后,用left所指的数值覆盖hole的数值,再更新hole的位置到left上,与此反复直到两指针相遇,第一趟排序结束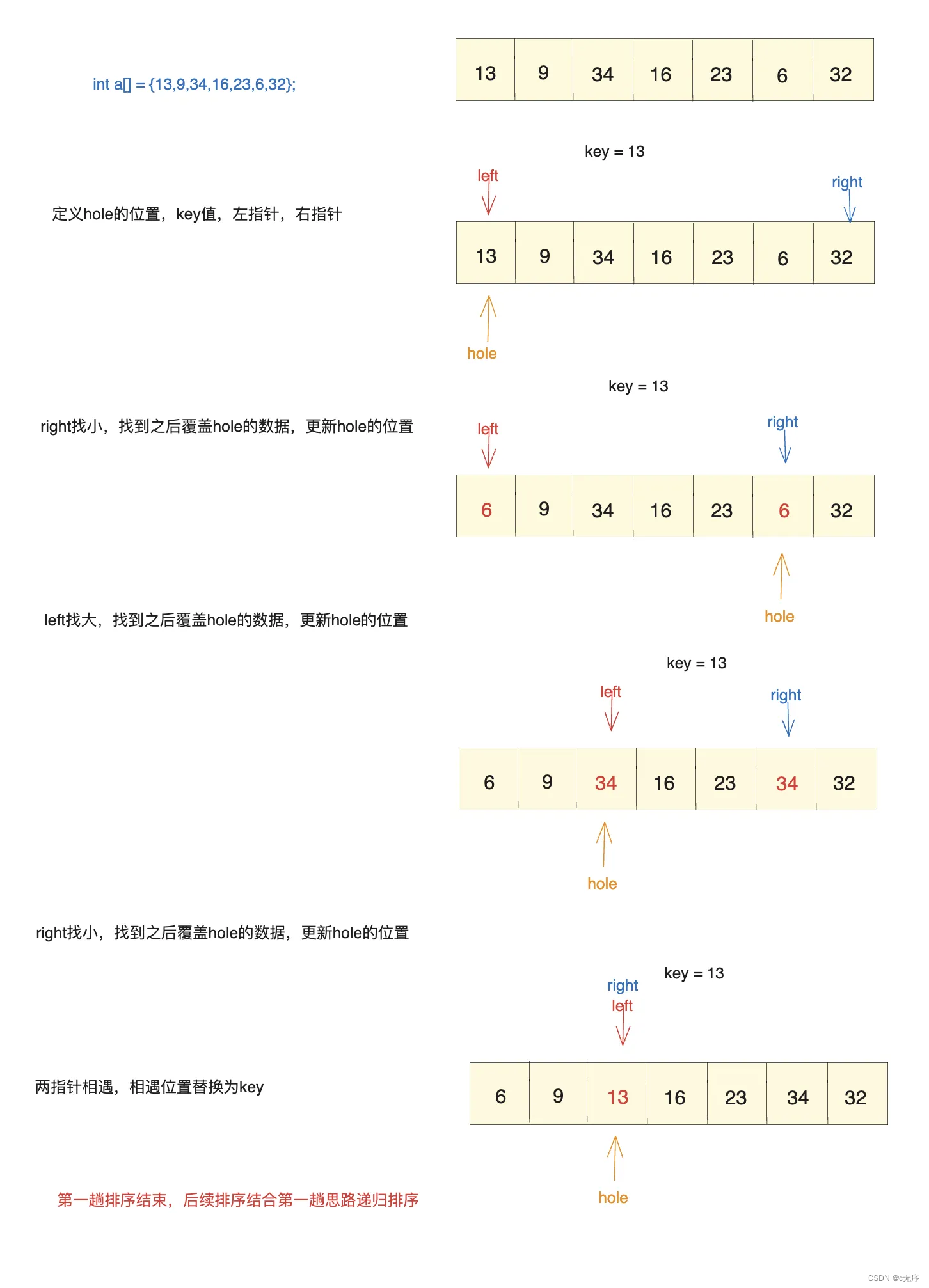
//快速排序3⃣️-挖坑法
int PartSort_DigHole(int* a, int left, int right){int hole = left;int key = a[left];while (left < right) {//右找小while (left < right && a[right] >= key) {right--;}int ahole = a[hole];a[hole] = a[right];hole = right;//左找大while (left < right && a[left] <= key) {left++;}ahole = a[hole];a[hole] = a[left];hole = left;}a[hole] = key;return hole;}
void QuickSort_DigHole(int* a, int left, int right){if(left >= right){return;}int hole = PartSort_DigHole(a,left,right);QuickSort_DigHole(a,left,hole-1);QuickSort_DigHole(a,hole+1,right);
}前后指针法快速排序
前后指针法快速排序,在效率上和挖坑法和Hoare快速排序效率所差无几。
其基本思想为:定义一个值为key(一般选第一个值为key),定义前指针(prev)后指针(cur)。先cur指针找比key小的数据,找到了就停下,在prev找比key大的数据,找到了就停下,交换前后指针数据。继续移动cur指针,直到cur指针超出排序个数(数组范围),交换prev与key的位置,完成一次排序,在如前两个方法一样进行递归排序。
以下是代码优化版
//快速排序2⃣️ 双指针法
void QuickSort2(int* a, int left, int right){int prev = left;int cur = left+1;int keyi = left;if(left >= right){return;}while (cur <= right) {//++prev != cur) 解决了自身交换的问题if(a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;//[left,keyi-1] key [keyi+1,right]QuickSort2(a,left,keyi-1);QuickSort2(a, keyi+1, right);//写递归一定要有出口
}快速排序优化-三数取中法
取中的是key的位置不再是首元素,而是中间(首元素下标和尾元素下表之和的一半),确保数据存在大量数据或者有序情况下进行优化。
int GetMidi(int* a, int left, int right){int mid = (left + right)/2;if(a[left] < a[mid]){if(a[left] > a[right]){return left;}else if(a[right] > a[mid]){return mid;}else{return right;}}else{//a[left] > a[mid]if(a[right] < a[mid]){return mid;}else if (a[right] > a[left]){return left;}else{return right;}}
}//快速排序1 右找小 左找大
// 时间复杂度:O(N*logN)
// 什么情况快排最坏:有序/接近有序 ->O(N^2)
// 但是如果加上随机选key或者三数取中选key,最坏情况不会出现,所以这里不看最坏
// 小区间优化
// 面试让你手撕快排,不要管三数取中和小区间优化
// Hoare
void QuickSort1(int* a, int left, int right){// 区间只有一个值或者不存在就是最小子问题if(left >= right) return;//1⃣️随机取keyi
// srand((unsigned int)time(NULL));
// int randi = rand()%(right-left+1);
// randi += left;
// Swap(&a[randi], &a[left]);//2⃣️三数取中法int keymid = GetMidi(a,left,right);Swap(&a[keymid], &a[left]);int keyi = left;int begin = left;int end = right;while (left < right) {//右边找小while (left < right && a[right] >= a[keyi]) {--right;}//左边找大while (left < right && a[left] <= a[keyi]) {++left;}Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);keyi = left;QuickSort1(a,begin,keyi-1);QuickSort1(a,keyi+1,end);
}快速排序非递归
//
// Stack.h
// 栈
//
// Created by 南毅 on 2024/2/15.
//#ifndef Stack_h
#define Stack_h#include <stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>#endif /* Stack_h */typedef int STDataType;typedef struct Stack{STDataType *a;int top;int capacity;
}ST;void STInit(ST* ps);
void STDestroy(ST* ps);void STPush(ST* ps, STDataType x);
void STPop(ST* ps);
STDataType STTop(ST* ps);
int STSize(ST* ps);
bool STEmpty(ST* ps);//
// Stack.c
// 栈
//
// Created by 南毅 on 2024/2/15.
//#include "Stack.h"
void STInit(ST* ps){assert(ps);ps->a = NULL;ps->top = ps->capacity = 0 ;
}void STDestory(ST* ps){assert(ps);free(ps->a);ps->a = NULL;ps->top = ps->capacity = 0;
}void STPush(ST* ps, STDataType x){assert(ps);if(ps->top==ps->capacity){int newcapacity = ps->capacity == 0 ? 4 : ps->capacity*2;STDataType* tmp = realloc(ps->a, newcapacity * sizeof(STDataType));if(tmp == NULL){perror("relloc fail");return;}ps->a = tmp;ps->capacity = newcapacity;}ps->a[ps->top++] = x;}void STPop(ST* ps){assert(ps);assert(!STEmpty(ps));ps->top--;
}STDataType STTop(ST* ps){assert(ps);assert(!STEmpty(ps));return ps->a[ps->top-1];
}int STSize(ST* ps){assert(ps);return ps->top;
}bool STEmpty(ST*ps){assert(ps);return ps->top==0;
}
//快速排序 非递归
void QuickSortNonR(int* a, int left, int right){ST st;STInit(&st);STPush(&st, right);STPush(&st, left);while (!STEmpty(&st)) {int begin = STTop(&st);STPop(&st);int end = STTop(&st);STPop(&st);//单躺排序int prev = begin;int cur = begin+1;int keyi = begin;while (cur <= end) {//++prev != cur) 解决了自身交换的问题if(a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;//[begin,keyi-1] keyi [keyi+1,end]if(keyi+1 < end){STPush(&st, end);STPush(&st, keyi+1);}if(begin < keyi-1){STPush(&st, keyi-1);STPush(&st, begin);}}//STDestroy(&st);
}快速排序的时间复杂度为,空间复杂度为
,属于不稳定算法




