OpenCompass(司南)是上海人工智能实验室发布的大模型评测工具。
目前已具有较为完备的生态,集成了大量主流的评测数据集。近期OpenCompass 作为大模型标准测试工具被Meta AI官方推荐。
一、大模型评测的意义
- 对于普通的使用者:选择对于自己来说最优的模型。了解模型的特色功能和实际效果。
- 对于模型开发者:监控模型能力变化,了解模型的能力边界,优化模型迭代。
- 对于管理者:减少大模型带来的社会风险。
- 对于产业界:选择最适合业务的大模型。
二、大模型评估的内容
拿到一个大模型,我们要从哪些维度来评估它呢?
从最基础的讲,我们肯定是要让大模型有输出正常的内容,如果输出是重复乱码等,那一定不是我们所预期的。
参考:https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers
将其分为了知识和能力评估、一致性评估和安全评估,还有专业领域大模型的评估。
比方说,对于一个通用模型,看一看知不知道一些百科常识,能不能续写文章等,这就是知识和能力评估。
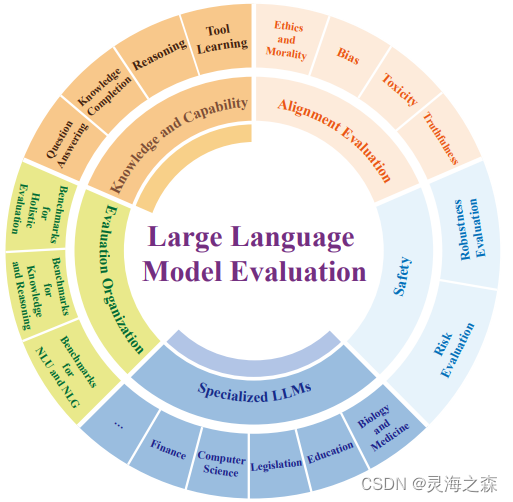
通用 vs 特色
司南大模型评估的内容划分为了通用能力和特色能力两大部分。
- 通用能力包括学科综合能力、知识能力、语言能力、理解能力、推理能力、安全能力,共计六大维度;
- 特色能力包括长文本、代码、工具、知识增强等能力。窃以为特色能力是跟着业务需求变化的。

三、大模型评估的数据集
基于我们想了解的模型性能的维度,目前主流的评估数据集(评测基准)有以下:
-
MMLU (Massive Multitask Language Understanding)
MMLU专注于零样本和少样本评估,使其更类似于我们评估人类的方式。它涵盖了STEM、人文学科、社会科学等57个领域,主要评估知识和解决问题的技能。 -
GSM8K
GSM8K 是一个包含 8,500 个高质量、语言多样化的小学数学单词问题的数据集,由人类问题编写者创建。需要想出一个由基本算术计算组成的多步骤过程。 -
C-Eval
类似于 MMLU,但是本基准是面向中文的,涵盖了52个不同的学科和四个难度级别。 -
LongBench
LongBench 是一个多任务、中英双语、针对大语言模型长文本理解能力的评测基准。
以上数据集均可在https://hub.opencompass.org.cn/home找到。
四、大模型评测的对象
一般为大语言模型,还有多模态大模型。这里以大语言模型来介绍。
- 基座模型(base):一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
- 对话模型(chat):一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。
五、评测方法(主客观结合)
客观评测
针对具有客观答案的客观问题,采用该方式。
OpenCompass采用提示词工程 (prompt engineering)和语境学习(in-context learning)进行客观评测。这是因为大模型输出不稳定,需要提示其按照数据集要求来生成回复。
在客观评测的具体实践中,通常采用下列两种方式进行模型输出结果的评测:
- 判别式评测:该评测方式基于将问题与候选答案组合在一起,计算模型在所有组合上的困惑度(perplexity),并选择困惑度最小的答案作为模型的最终输出。例如,若模型在
问题? 答案1 上的困惑度为 0.1,在 问题? 答案2 上的困惑度为 0.2,最终我们会选择 答案1 作为模型的输出。 - 生成式评测:该评测方式主要用于生成类任务,如语言翻译、程序生成、逻辑分析题等。具体实践时,使用问题作为模型的原始输入,并留白答案区域待模型进行后续补全。我们通常还需要对其输出进行后处理,以保证输出满足数据集的要求。
以c-eval的问题为例:
Question: 对于UDP协议,如果想实现可靠传输,应在哪一层实现____
A. 数据链路层 B. 网络层 C. 传输层 D. 应用层 Answer: D
我们输入了Question,就是要让其回答D,因此要在提示词中明确其回复格式。
主观评测
针对如模型安全和模型语言能力的评测,以人的主观感受为主的评测更能体现模型的真实能力,并更符合大模型的实际使用场景。
具体实践中,将不同模型对于同一问题的不同回复展现给受试者,收集受试者基于主观感受的评分。
同时由于人工打分的成本高昂,所以也采用使用性能优异的大语言模拟人类进行主观打分。
类似于大模型竞技场https://modelscope.cn/studios/LLMZOO/Chinese-Arena/summary
六、评测指标
对于不同的能力维度,对应不同的数据集,由此衍生出不同的评测指标。
比如考察综合知识的c-eval等数据集,是以选择题的形式呈现的,所以其评测指标就是准确率。

总结
本文以司南评估工具为例,介绍了大模型评测这一内容。
大模型评测和以往的nlp模型评测的不同在于要考虑非常多的维度,根源在于大模型的多维能力。传统nlp模型只需要针对文本分类、ner等某个具体任务,但是大模型具有文本对话、角色扮演、文本分类等传统nlp有和没有的能力。
因此,司南将其分为通用能力和特色能力两个部分,再分层划分各个子维度的能力。
再回顾下开发大模型的生命周期:模型基座(base),增量预训练,sft,奖励学习,人类偏好学习。目前大多还是只走到了sft。训练过程中还需要不断评估其性能,持续迭代。