相关文章
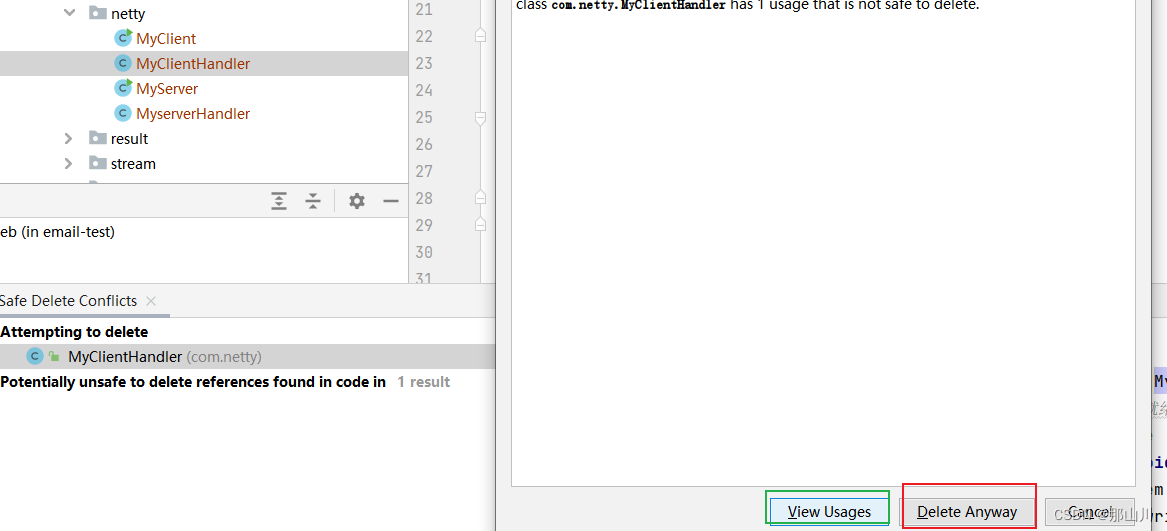

c++ new delete 相关应用——申请连续空间不允许部分释放
new delete 详解
实验1 int **all_a new int* [2]; // 申请了一片空间足够存储两个int类型指针。// 返回对象是指向空间头的指针,因此是int**int* a new int [3];//申请了足够存储3个int 的空间,返回空间开始位置的指针 int* b new int [3];//申请了…
【Transformer原理解析】
Transformer是一种基于自注意力机制(Self-Attention Mechanism)的深度学习模型,它在自然语言处理(NLP)领域取得了显著的成就,特别是在机器翻译任务中。以下是Transformer原理的简要介绍以及使用PyTorch实现…

DBA-现在应该刚刚入门吧
说来话长
在2023年以前,我的DBA生涯都是“孤独的”。成长路径除了毕业前的实习期有人带,后续几乎都是靠自学。如何自学,看视频、看文档、网上查阅资料、项目实战。 可能是学疏才浅 ,一直都是在中小公司混,在中小公司通…
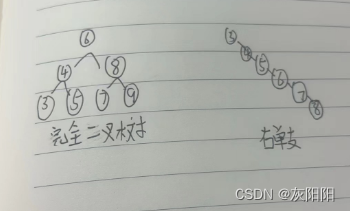
DS进阶:二叉搜索树
目录 一、概念
二、搜索二叉树相关操作
1.查找
2.插入
3.删除(难点)
第一类:
第二类:
第三类:
三、性能分析 一、概念
二叉搜索树,又称二叉排序树,它或者是一颗空树,也是具…

Excel文件解析--超大Excel文件读写
使用POI写入 当我们想在Excel文件中写入100w条数据时,我们用普通的XSSFWorkbook对象写入时会发现,只有在将100w条数据全部加载入内存后才会用write()方法统一写入,这样效率很低,所以我们引入了SXSSFWorkbook进行超大Excel文件的读…
八、Python+FFmpeg,实战直播推流
1,环境变量 将 python.exe 的路径添加到环境变量中。 2,创建 py 文件,调用 ffmpeg import subprocess
import time
#ffmpeg 录屏:5 秒
ffmpeger=subprocess.Popen(ffmpeg -thread_queue_size 16 -f gdigrab -i desktop -s 1280x720
-vcodec libx264 -y test2.mp4,
she…