shell脚本(命令)放后台
sleep 300& 放到后台运行,脚本或命令要全路径
nohup:用户推出系统进程继续工作
【功能说明】
nohup 命令可以将程序以忽略挂起信号的方式运行起来,被运行程序的输出信息将不会显示到终端
如果当前目录的nohup.out文件不可写,输出重定向到$HOME/nohup.out文件中
企业应用:
nohup 路径/shell脚本 &
方法:screen
总结:让程序进入后台运行方法
1.ctrl+z,jobs,fg,bg前台的程序,进入后台,后台运行 ##临时用
2.使用screen (推荐) ##管理员常用,下班了想回家,xshell有没有执行完的任务。
3.使用&符号 ##后台运行脚本常用
screen命令
作用:保持操作过的窗口连接状态。
[root@calms ~]# yum install screen -y
2.开启一个screen窗口,指定名称
[root@calms ~]# screen -S sleep
3.在screen窗口中执行任务即可
while true;do echo wulin>>/tmp/wulin.log;sleep 1;done
#每隔一秒向/tmp/wulin.log追加wulin
4.平滑的退出screen,但不会终止screen中的任务。
ctrl+a+d
注意: 如果使用exit 才算真的关闭screen窗口
5.关闭xshell模拟下班回家,
第二天重开xshell连接。
查看当前正在运行的screen有哪些
[root@wulin ~]# screen -list

6.此时需要进入昨晚的会话,进入正在运行的screen
[root@calms ~]# screen -r sleep

[root@calms ~]# screen -r 2259
常用screen参数 screen -S yourname #新建一个叫yourname的session screen -ls
#列出当前所有的session screen -r yourname #回到yourname这个session screen -d yourname #远程detach某个session screen -d -r yourname
#结束当前session并回到yourname这个session
重点总结:
#1.创建screen 创建
screen 或 screnn -S 窗口名称
#2.退出窗口
ctrl+a+d
#3.显示当前所有screen窗口
screen -ls
#4.恢复,重新进入
screnn -r id
什么是进程优先级?
进程执行时候是排队执行的,需要插队,要调整。
进程重要性高,需要优先多分配CPU。调整优先级。
#记住用途
nice: 调整【程序运行时】的优先级 renice:调整【运行中的进程】的优先级
区别:
nice命令常用于修改未运行的程序再运行时的优先级,
但是对于正在运行的进程,若想要修改优先级,就需要用到renice命令。
strace:跟踪进程的系统调用
系统调用:系统为应用程序提供的连接接口
进程执行:调用很多接口。。
为什么要跟踪进程的系统调用?
查找进程执行异常的原因:
PHP进程,JAVA进程,cpu%100,怎么排查?
进程执行:调用很多接口,接口如果异常,进程就会不正常
strace是Linux环境下的一款程序调试工具,用来检查一个应用程序所使用的系统调用及它所接收的系统信息。strace会追踪程序运行时的整个生命周期,
输出每一个系统调用的名字、参数、返回值和执行消耗的时间等, 是高级运维和开发人员的排查问题的杀手锏。
-p pid 指定要跟踪的进程pid, 要同时跟踪多个pid, 重复多次-p选项即可※
-f 跟踪目标进程,以及目标进程创建的所有子进程※
-tt 在输出中的每一行前加上时间信息,精确到微秒。例子:11:18:59.759546※
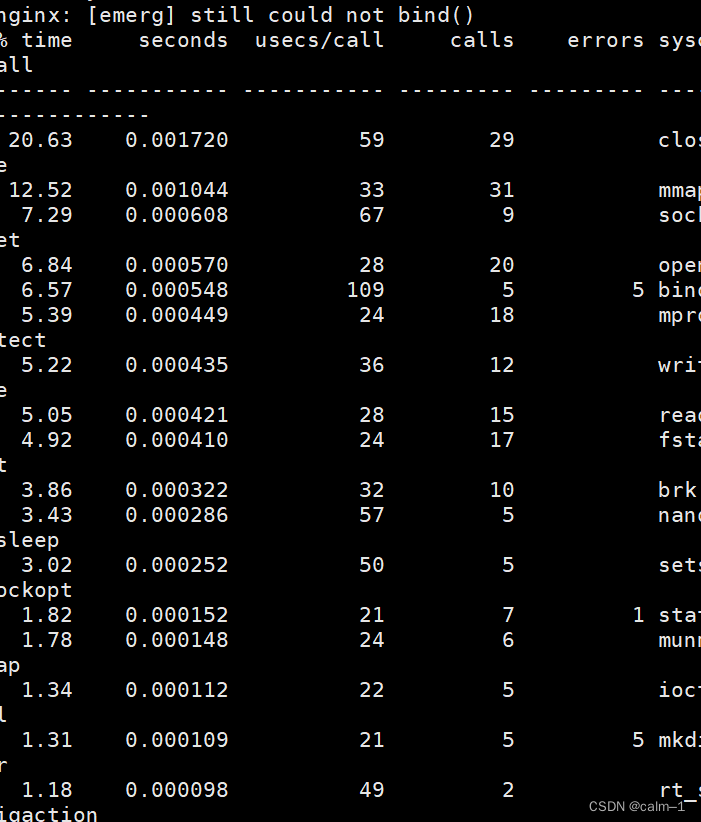
只跟踪和文件操作有关的系统调用。
命令结果输出太多了,很容易看花眼,因此可以使用过滤器,过滤掉无关信息,比如只查看文件操作信息。
[root@LNMP ~]# strace -tt -f -e trace=file /application/nginx/sbin/nginx
#<==-e trace=file的作用为只跟踪和文件操作有关的系统调用。
[root@calms ~]# strace -tt -p 80008
跟踪系统调用统计。
strace不仅能追踪系统调用,使用选项-c还能将进程所有的系统调用做一个统计分析。
[root@LNMP ~]# strace -c /application/nginx/sbin/nginx
#<==使用-c参数给进程所有的系统调用做一个统计分析。
使用-o选项将strace的结果输出到文件中
strace -c -o tongji.log /application/nginx/sbin/nginx
小结:strace命令很适合程序僵尸、命令执行报错等的问题,如果从程序日志和系统日志中看不出问题出现的原因,
就可以strace一下,也许有答案,不过也需要使用者有足够的耐心去查看输出!
给/etc/passwd加锁,然后用strace追踪。
[root@calms ~]# chattr +i /etc/passwd
[root@calms ~]# strace -f useradd abc
发现问题:无法打开/etc/passwd
open(“/etc/passwd”, O_RDWR|O_NOCTTY|O_NONBLOCK|O_NOFOLLOW) = -1 EACCES (Permission denied)
write(2, “useradd: cannot open /etc/passwd”…, 33useradd: cannot open /etc/passwd
企业案例:PHP进程CPU百分百了怎么解决?
1)pgrep 进程,获取进程号
2)strace -p 进程号 发现问题。
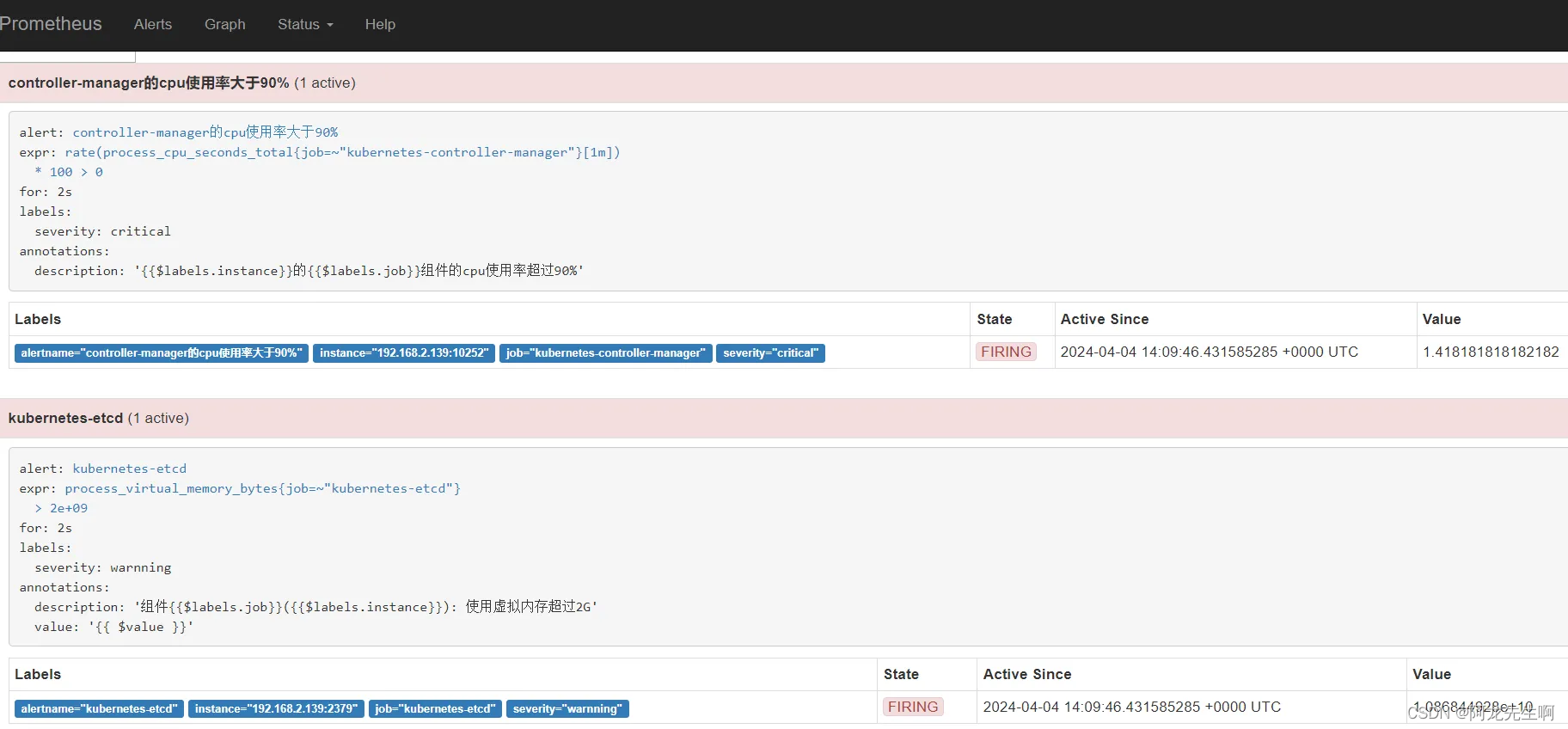
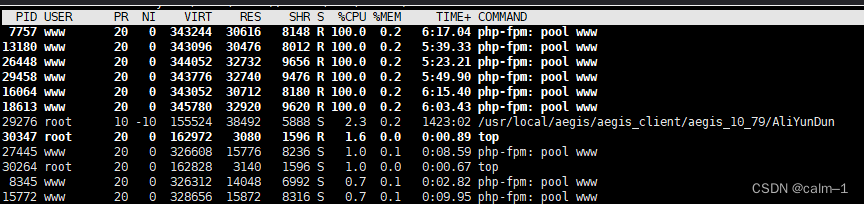
用户案例: 公司服务器CPU占用过高,报警了,第一反应是登录服务器, top 命令查看当前进程,输入 P 按cpu排序 :
看到有多个php-fmp进程占用cpu过高,都达到100%了于是打算监听一下进程,看看在执行什么操作,使用 strace 命令:
#监听进程
strace -o /tmp/output.txt -T -tt -F -e trace=all -p 7757
#查看log
tail -f /tmp/output.txt
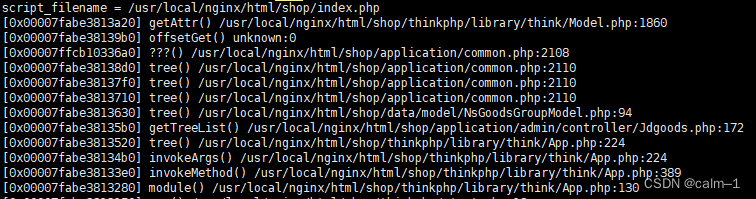
结果没有看出来,cpu占用率太高了通过php慢日志开启条件,需要php-fpm.conf配置:request_slowlog_timeout = 3 #脚本超时秒数 slowlog =
/var/log/php.log.slow #记录慢日志路径
tail -n 1000 /var/log/php.log.slow
然后进行优化代码
strace关键词。

企业生产经验:
资源不够用:网站运行慢。
1.没有给充足资源。
上线前压测,提前测出来承受能力。
提前预警。70% 预警时间是(资源增加的最长周期+当下百分比<80%)。
2.开发代码上线,BUG异常消耗资源,导致100%
strace,gdb.后知后觉。
3.公司推广部门(合作广告),大流量过来,广告页(CDN),(提前准备)。
运维感受到的:服务器流量增加,压力增大,CPU ,内存,磁盘都压力很大了。
所有和网站相关的部门,开发,运维、运营、市场,客服(查询 离线查询,和生产用户访问库,分开)
对于外部用户,检测,根据趋势预判。
ltrace:跟踪进程调用函数
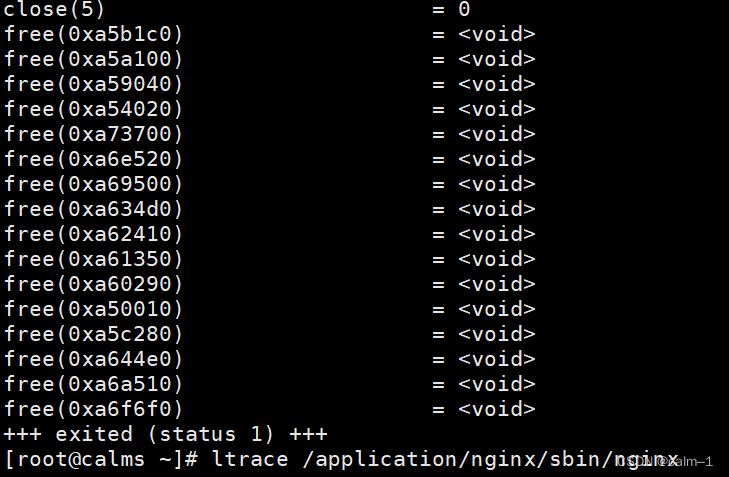
ltrace:能够跟踪进程的库函数调用,它会显示出那个库函数调用,而strace则是跟踪进程的每一个系统调用
[root@calms ~]# ltrace /application/nginx/sbin/nginx
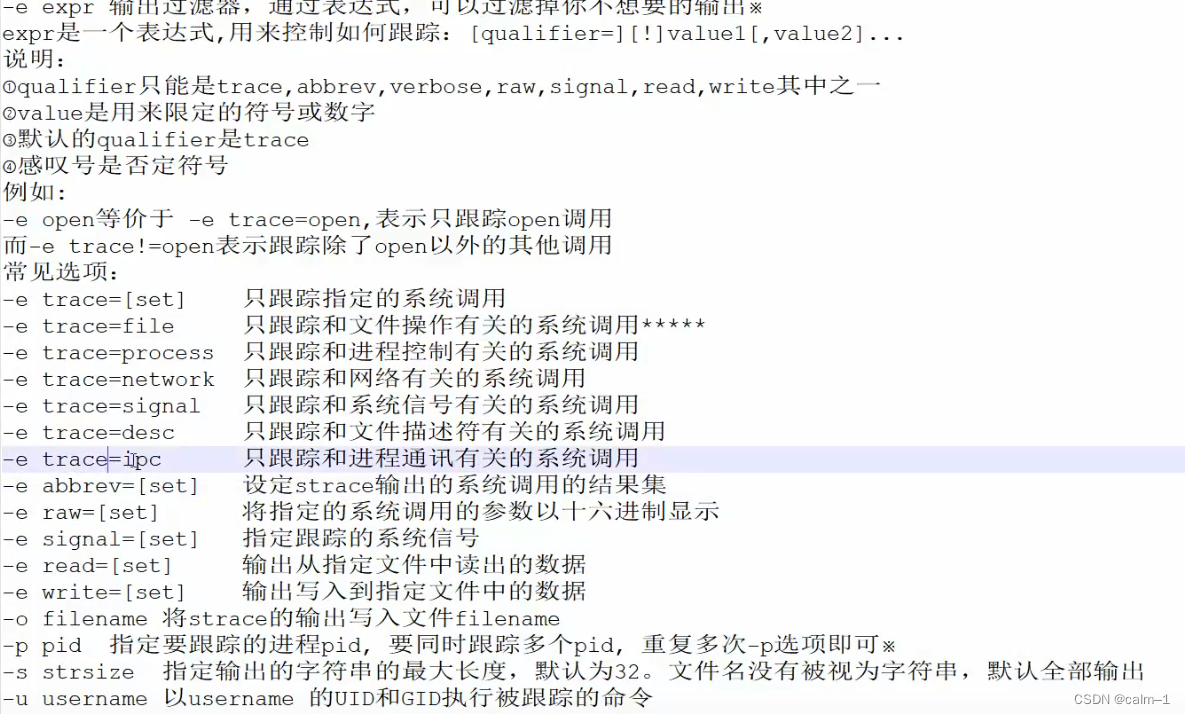
-e expr输出过滤器,通过表达式,可以过滤掉你不想要的输出
-e printf 表示之查看print函数的调用,而strace则是跟踪进程的每个系统调用
-e !printf表示查看除了printf 函数以外的所有函数调用
-f 跟踪子进程
-o filename将ltrace输出写入文件filename
-p pid指定跟踪的进程pid
[root@calms ~]# ltrace - o nginx.log /application/nginx/sbin/nginx
进程管理总结:
- 找出问题的进程
top ps - 调整优先级
nice renice - 进程在干什么(nginx,php,mysql)
strace lstrace gdb - 杀进程
kill killall pkill - 继承前后台切换
ctrl+z bg fg jobs kill %1
&后台运行
nohup 配合&,让程序放到后台运行,并且打印输出到日志里
screen 保持操作的对话,其不中断(运维人员客户端xshell用)
平均负载(load average)
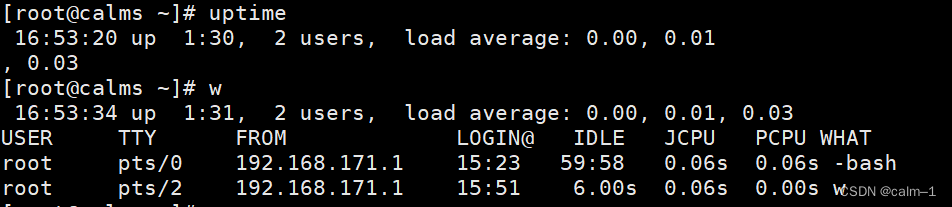
查看负载命令:
top,w,uptime
平时只看负载就使用uptime
也可以查看对应的文件:

什么是平均负载?
衡量系统繁忙的一个综合性指标,主要是cpu/io的繁忙程度;在工作中非常常用。
工作中非常的常用,具体是哪一个指标繁忙
ps,top,sar看cpu
iostat,iotop看磁盘
一个进程的产生会占用很多的资源:
1.PID 2.内存 3.文件描述符 4. cpu 5.磁盘
平均负载是指单位时间内,系统处于可运行状态的平均进程数,也就是平均活跃进程数;(在特定的时间间隔内cpu运行队列中的平均进程数)
举例子
车:进程 桥:cpu队列
系统负载为0的时候(意味着一辆车没有)
0.5的时候(意味着大桥一半的路段有车)
1.0的时候(大桥的所有路段都有车,虽然桥上车辆是满的,但是此时的大桥还能进行顺畅流通)
1.7(车辆太多,大桥已经被占满了,后面等着上桥的车辆为前面车辆的70%)
2.0(桥上的车辆与桥面一样多)
3.0(等待桥上的车辆时桥面的2倍)
大桥的同行能力就是cpu的最大工作量,一个桥为1个cpu队列,2个桥为2个cpu队列
平均负载数字和cpu核数想等的时候就是cpu处理进程的临界点
2棵,每一颗4核,8核负载为8的时候,临界点为8*70%=5.6(5-8)慢的临界点
可运行状态进程:正在使用cpu或正在等待cpu处理的进程,ps命令看到处于R状态对的进程
不可中断进程:系统最常见的硬件设备的I/o相应
ps命令看到的d状态进程
最终解释(单位时间内的活跃进程数)
2颗,单颗四核cpu为例
1分钟:0.0.7 cpu处理进程1分钟的繁忙程度,忙碌1分钟
5分钟:8.0.1 cpu处理进程5分钟的繁忙程度,忙碌了5分钟
15分钟:5.05 cpu处理进程15分钟的繁忙程度,忙碌了连续15分钟,15分钟内平均为5个点
总结:
负载数值/总的核心数=1 开始慢的临界点,实际上1✖70%=关注的临界点;大于1就说明有问题。
需要关注负载的值:总的核数乘以70%(关注的点)
如何查cpu核心数?
查看物理cpu个数:
grep “physical id” /proc/cpuinfo|wc -l
grep -c "physical id " /proc/cpuinfo
查看每个物理cpu的core的个数(核数)
gfrep “cpu cores” /proc/cpuinfo|wc -l
查看逻辑cpu的个数(用以计算负载)
grep “processor” /proc/cpuinfo|wc -l
平均负载案例分析实战
用stress,mpstat,pidstat等工具,找出平均负载升高的根源
stress是Linux系统压力测试和工具,这里我们用作异常进程模拟平均负载升高的场景
mpstat是多核心cpu性能分析工具,用来临时查看每一个cpu的性能指标,以及所有的cpu平均指标
pidstat是一个常用的进程性能分析工具,用来实时查看进程的cpu,内存,I/O及上下文切换等性能指标
yum install stress -y
yum install sysstat -y
平均负载与cpu
:平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,并不能直接发现,到底是哪里出现了瓶颈。
平均负载阿公有可能是cpu密集型进程导致的;平均负载高并不一定代表cpu使用率高,还可能是I/O更加繁忙了;当发现负载高的时候,可以使用mpstat,pidstat工具,辅助分析负载来源
1.平均负载是运行队列中活跃的进程数
2.平均负载;1,5,15分钟内的负载
3.需要关注负载的值:总的核心数*70%关注的点
4.辅助opt,ps,uptime,sar,mpstat,pidstat,iostat,排查问题
5.starce跟踪进程系统调用
面试官会问:
你在工作中遇到过那些生产故障,是怎么解决的?
最好与数据库相关(负载高),web相关(php进程100%,java内存泄漏)
Linux系统服务管理
什么是运行级别?
就是Linux启动时处于不同的状态标识的集合
(文本模式,图形模式,重启模式,关机模式都会对应不同的运行级别)
面试可能会到:
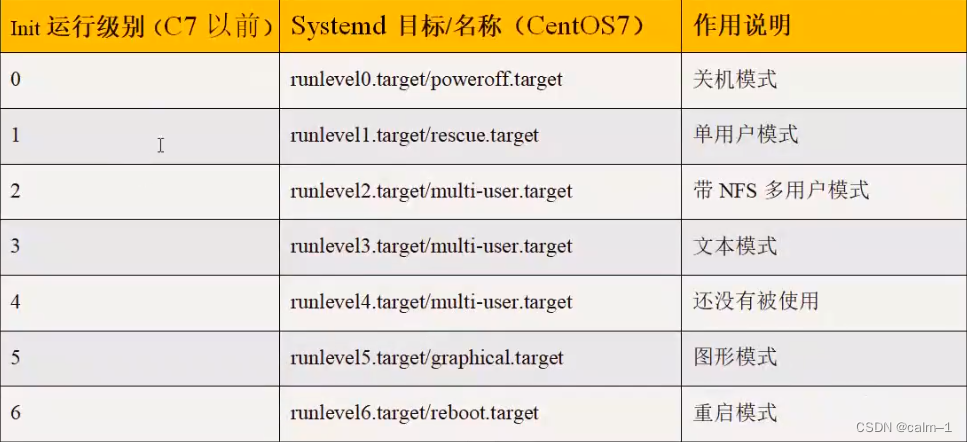
查看运行级别:

ls -l /usr/lib/systemd/system/runlevel[0-9].target
如何切换运行级别?
C6:init
startx 切换到桌面
c7:
启动时加载的文件
systemctl get-default

设置默认运行级别方式:
systemctl set-default TARGET.target
cnetos7之前是/etc/inittab里面设置的
id:3:initdefault系统启动时,将linux设定固定的运行级别的配置行(面试可能会问到)
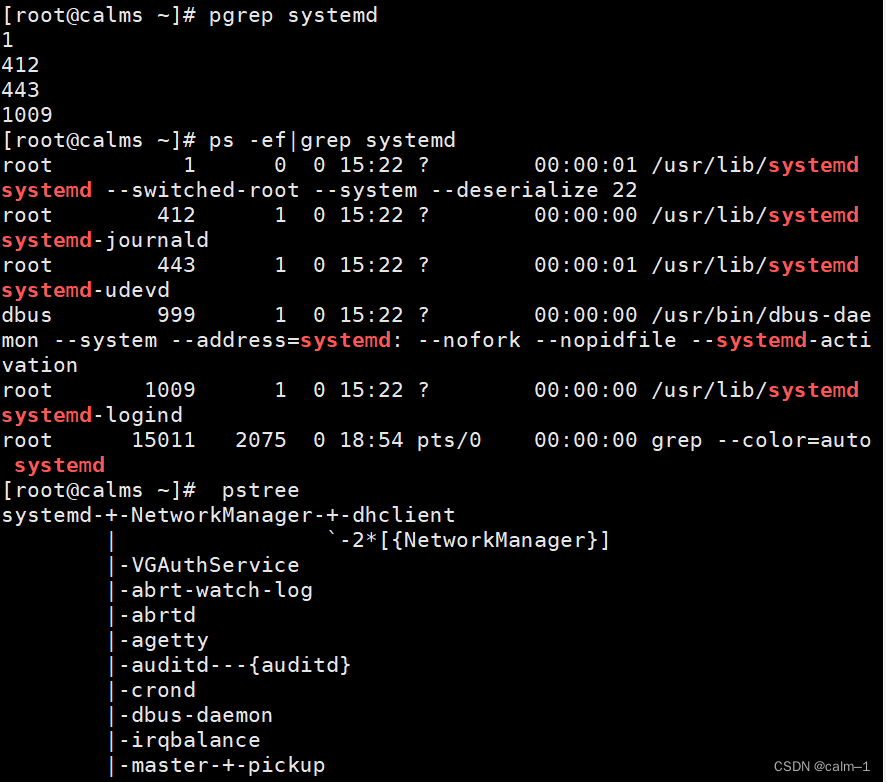
Linux系统systemd知识
系统管理守护进程,工具和库的进程,早期是init进程。
功能:用于集中管理守护进程,工具和库的集合
systemd是centos7系统启动的第一个进程,其他所有的进程是它的子进程
为什么要用systemd?
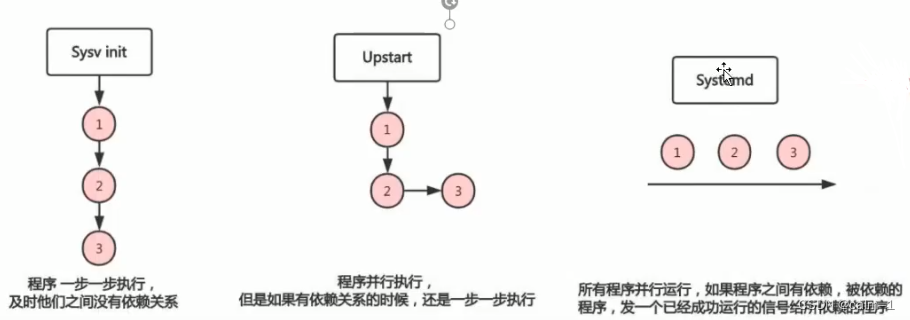
init启动方式缺点:
- 启动时间长,串行执行,启动完成后再启动另外的
- 启动脚本复杂,依赖关系很杂,靠脚本自己处理
- 相关的管理命令很多很杂
centos5-centos7启动过程
systemd相关路径文件
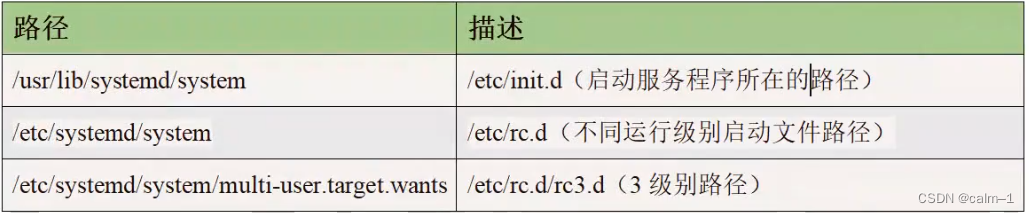
查看不同文件运行级别的文件路径:
systemctl管理服务相关命令
systemctl start crond(定时任务)
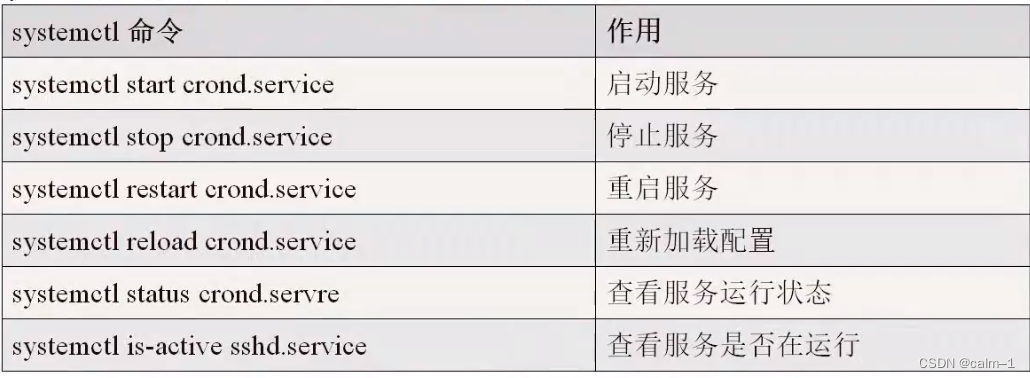
使用systemctl启动一个守护进程之后,可以通过systemctl status查看守护进程状态

systemctl设置服务开机启动,不启动,查看各个级别下服务启动状态常用命令
systemctl enable crond.service 原理就是创建一个软链接
systemctl enable crond.service 移除一个软链接
启动图解:

手工设置开机自启动:
(enable与disabled原理:对应级别的target下面做一个服务的软链接,然后在启动这个服务的时候,它会加载这个级别下的所有软链接,所有软链接就会找到程序启动的所有路径)
[root@calms ~]# rm -f /etc/systemd/system/multi-user.target.wants/crond.service
[root@calms ~l#systemctlstatus crondcrond.service -Command SchedulerEv:kunlun991
Loaded: loaded (/usr/lib/systemd/system/crond.service; disabled; vendor preset: enabled)
Active:inactive(dead)
[root@calms ~]# ln -s /usr/lib/systemd/system/crond.service/etc/systemd/system/multi-user.target.wants/crond.servicerootd
[root@calms ~]#systemctlstatus crond
Crond.service -Command SchedulerLoaded: loaded (/usr/lib/systemd/system/crond.service; enabled; vendor preset: enabled)Active:inactive (dead)root
[root@calms ~]#rm -f /etc/systemd/system/multi-user.target.wants/crond.service
[root@calms ~]#systemctl status crond
Crond.service -Command Scheduler
Loaded: loaded (/usr/lib/systemd/system/crond,service; disabled; vendor preset: enabled)
systemd文件格式
- systemctl文件路径说明:
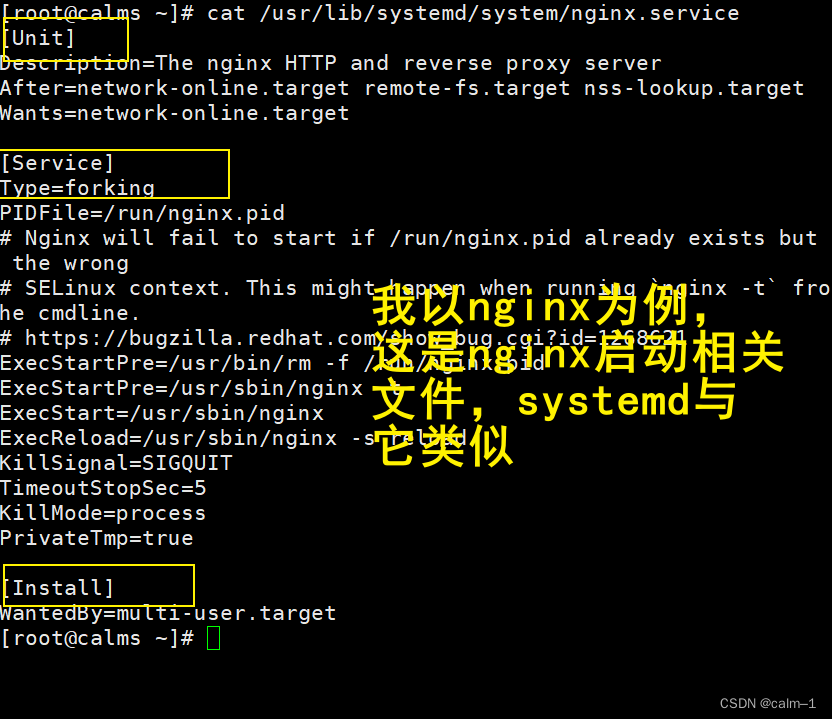
- 说明
Unit 定义通用的选项,描述信息,依赖关系
Srevice 特殊的服务类型,具体启动,关闭,重启选项都在此部分配置
Install 定义开机自启和不开机自启动命令实现的选项
unit常用段:
description 描述信息
documentation 说明文档的在线地址
after 定义自启动顺序,表示当前配置的服务应该晚于那些服务之后启动
wants 依赖其他的关系
serivce段常用说明
Type#定义服务类型
forking#需要父进程启动子进程的服务类型为forking
PIDFile#定义PID 文件路径(进程 PID)
ExecStart#指定启动服务命令绝对路径
ExecReload#指定重新加载服务的配置文件的命令绝对路径
ExecStop#指定停止服务命令绝对路径
ExecStartPre#在启动之前运行的命令
ExecStartPost#在启动之后运行的命令
install:
WantedBy#哪些服务需要被依赖
nginx的systemd启动文件解释:
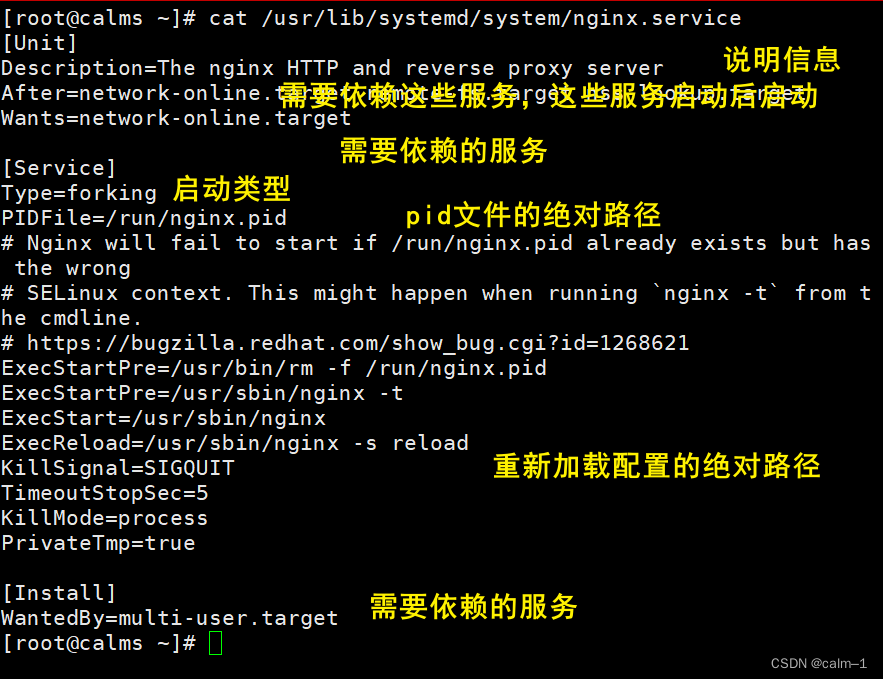
自定义服务启动文件(条件):
PIDFile=/var/run/nginx.pid #pid 文件的绝对路径
ExecStart=/usr/sbin/nginx-c
/etc/nginx/nginx.conf
ExecStop=/bin/sh-c “/bin/kil1 -s TERM $ (/bin/cat /var/run/nginx.pid)”
#启动命令的绝对路径#停止服务命令的绝对路径
centos6:
| centos6 | centos7 |
|---|---|
| /etc/init.d/nginx start(shell脚本) | systemctl start nginx(systemd启动文件) |
| serivce nginx start | |
| chkconfig nginx on chkconfid nginx off | systemctl enable nginx systemctl disable nginx |
| chkconfig - -list grep 3:on | systemctl list-unit-files |
面试题:
开发了一个nginx脚本/etc/init.d/nginx start如何配置脚本,能让那个脚本使用chkconfig进行开机自启动设置
答:chkconfig:2345 21 81
description:rsync service start and stop scripts
自定义一个nginx脚本
cat >/usr/lib/systemd/system/wulinnginx…service << EOF
[Unit]
Description=DIY nginx
Documentation=https://www.wulin.com/
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
PIDFile=/application/nginx/pid/nginx.pid
Execstart=lapplication/nginx/sbin/nginx-c /application/nginx/conf/nginx.conf
ExecReload=/appalication/nginx/sbin/nginx -s reload
Execstop=/application/nginx/sbin/nginx -s stop
ExecStartPre=/bin/sh -c “/usr/bin/chown -R www:www /application/nginx/”
[Install]
wantedBy=multi-user.target
EOF
重新加载systemd配置:
systemctl daemon-reload
启动我们自己的服务
systemctl start wulinnginx
这一篇小编先写到这里了,更多内容请关注小编专栏!!!