文章目录
- 序言
- 认识磁盘
- 磁盘在系统中的管理
- 熟悉磁盘各个分区
- 软硬链接
- 软链接
- 硬链接
序言
首先熟悉一下一些专有名词(了解即可,但必须有一个概念认识)
固态:SSD,笔记本中常装的,台式机中也可以装,常见的对应接口M.2和SATA接口
磁盘:90年代常用的数据存储设备,或是现在企业级数据存放的重要设备
认识磁盘

磁盘中的数据存储
按0,1的充放电来改变磁盘表面的0,1状态,修改数据
磁盘的物理存储
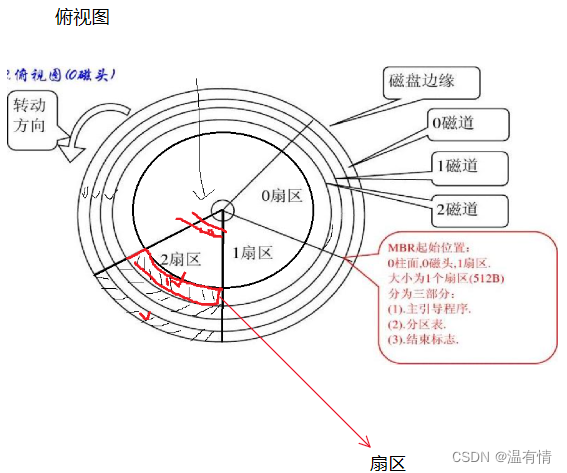
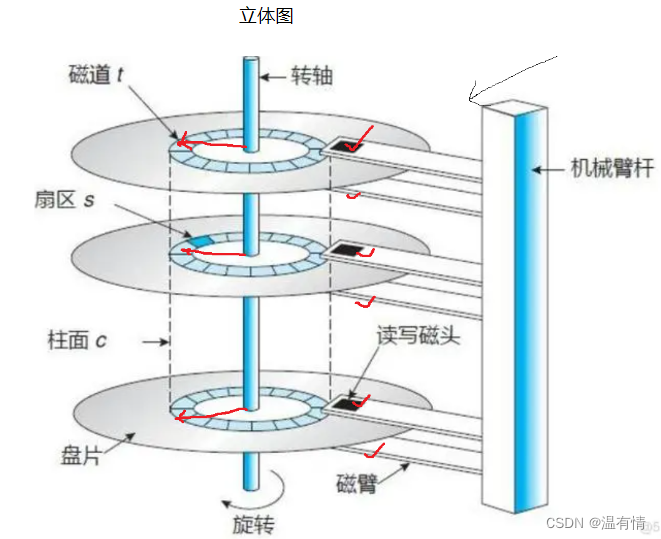
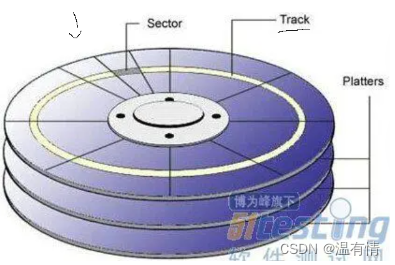

磁盘在系统中的管理
一个盘面有很多的同心磁道,这些磁道之间有很小的间距
一个磁道有很多的扇形扇区
磁盘的存储单元最小是512byte(主要)或者是4kb-----单只想改变1byte,但还是要加载512byte


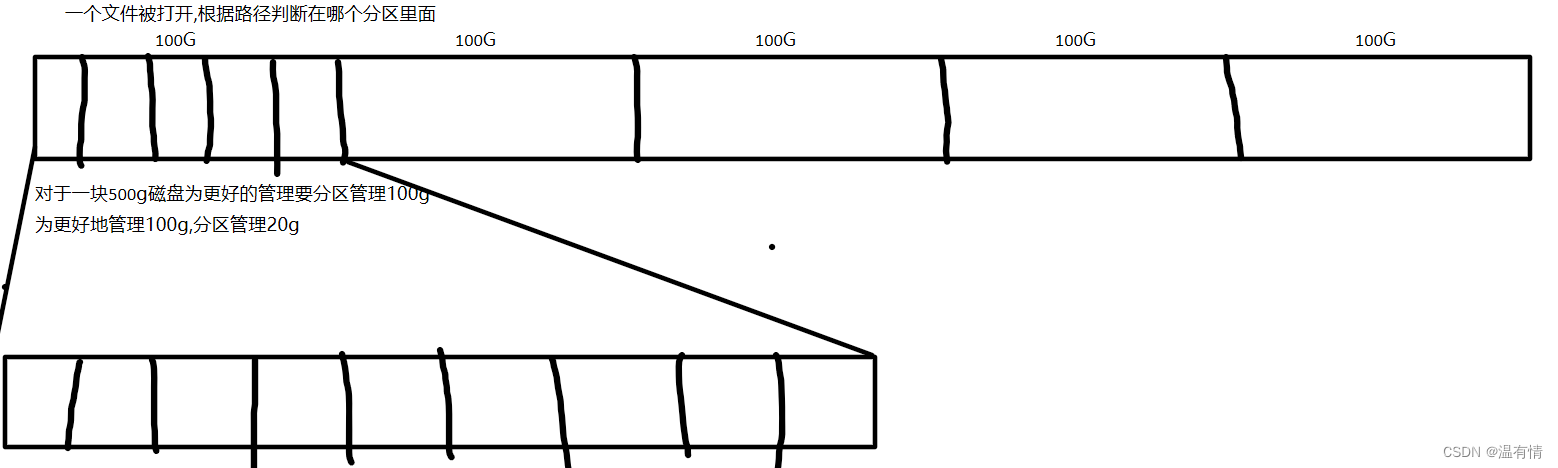
熟悉磁盘各个分区
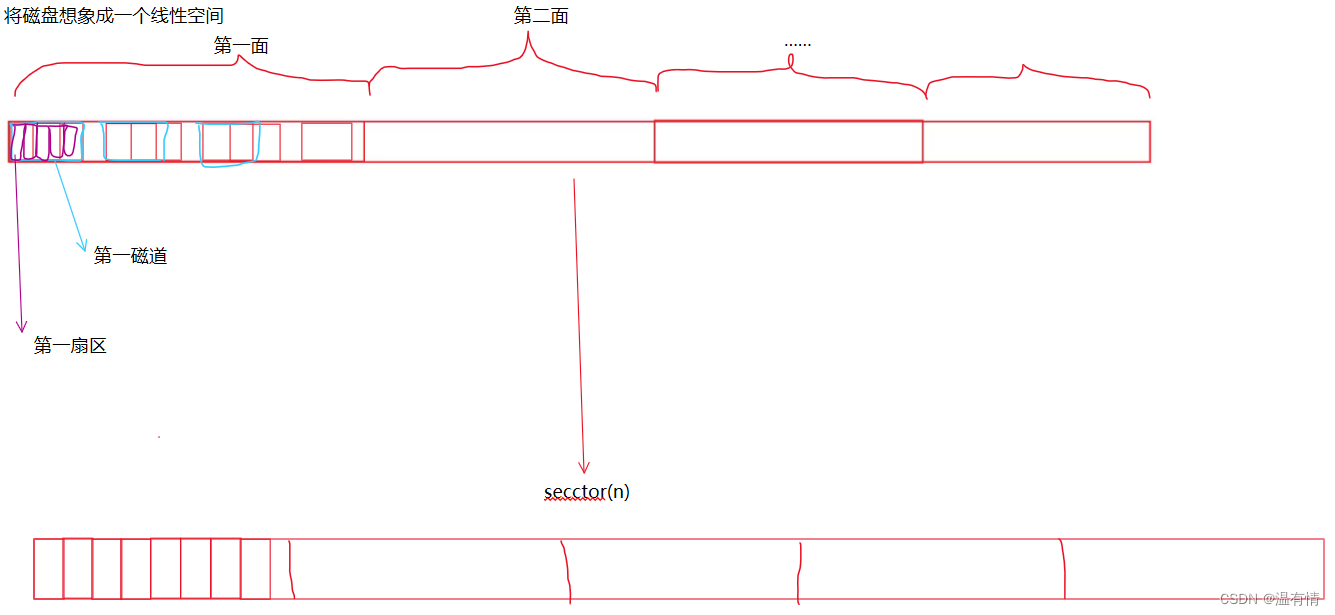
1-100000 第一面 100001-200000第二面1-10000 第一磁道10001-20000 第二磁道......

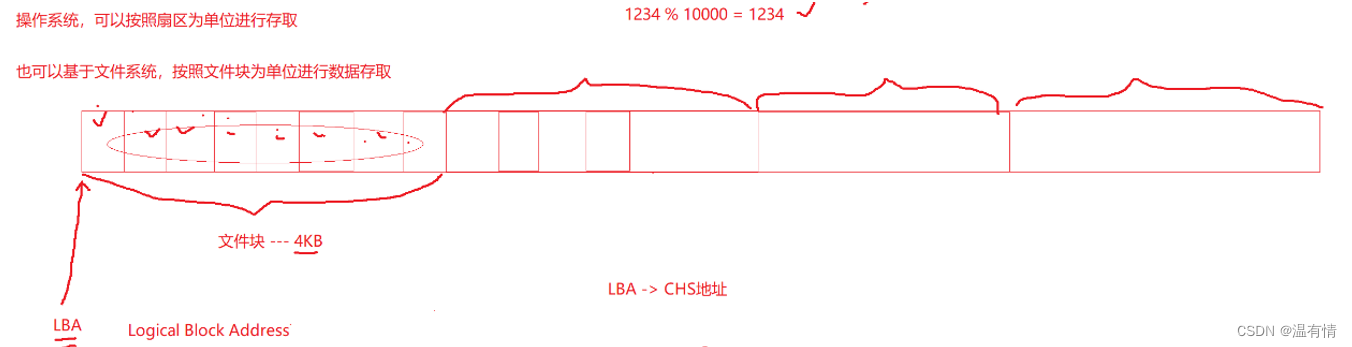

手绘一个图来理解这个分区的具体情况
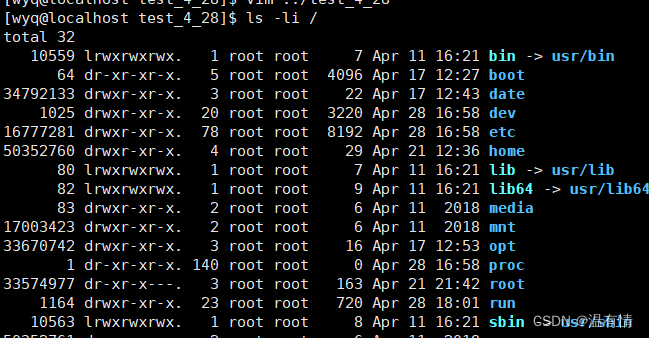
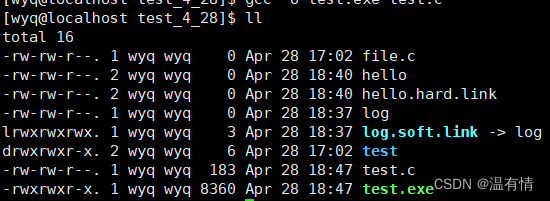
ls- li
会多一列数据

这是iNode编号,一般情况下,一个文件一个iNode编号,每个文件都有
在整个分区都有唯一性,不同的分区可能有相同的iNode
在Linux中识别文件根据iNode编号
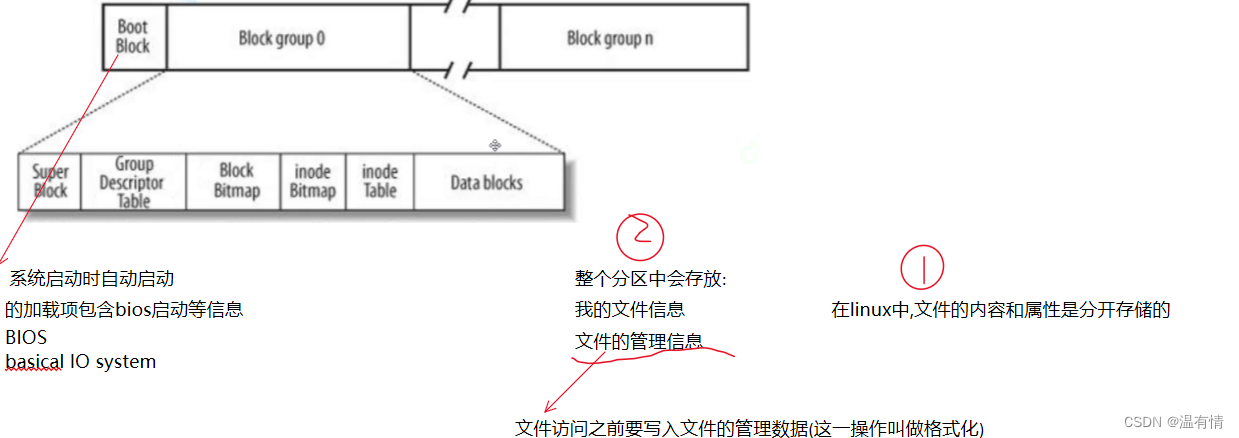
 针对上述这个表进行详细的说明一下:
针对上述这个表进行详细的说明一下:
i节点表:
存放文件的文件属性 如:大小,所有者,最近修改时间
保存文件属性是通过inode保存的
struct inode
{文件大小属性,等…
int blocks[N]
int ref_count;
}
这个一个inode大小固定为128字节 ,每一个inode的大小都是固定的
这个i节点表就是struct inode inode_table{N}
在每个分区之前都有一个struct inode_number
要找某个inode对应的组内的位置只要inode - inode_number就能找到
Data blocks
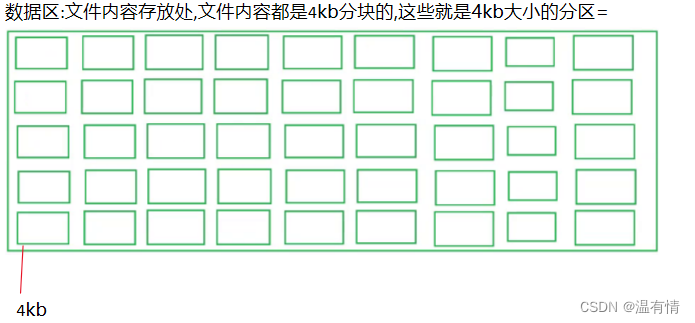
根据inode编号 -------> 找到inode区间 -----> 然后找到对应的组
inode Bitmap
位图:标识每一个bit的inode编号,标识文件是否被使用,内容(0/1)
block bitmap
bit位的位置表示block的编号,标识这个block是否被使用
group Descriptor tabl:
块组描述符:inode,一共有多少inode,有多少被使用,分组多大,
保存整个块的管理信息
每一个块都有这五个字段(group descriptor table,)
super block
简称sb,这个超级块不属于这一个分组,可能有100个块,7 8个块组跟
super有关,里面放的是整个块的主要信息
当super block出现错误就在相当于整个磁盘都会报废
所以一般这个super block会多副本的形式保存在其他块区内
这样等super出错后,系统就能自己进行拷贝完成修复
新建,删除:知道iNode,怎么删除?
根据inode编号找到对应的位置将这个位置的数据由1----->0
找到对应的block改位图就能删除
这个删除表示文件的block 不可用
误删了怎么办?
知道inode编号,找到对应的块组,将位图的将0改为1
找到对应的inode数组,对应对的data block从0->1改回来
linux中会将删除的文件的inode保存下来
不做恢复处理(要知道原理)
super block
简称sb,这个超级块不属于这一个分组,可能有100个块,7 8个块组跟
super有关,里面放的是整个块的主要信息
当super block出现错误就在相当于整个磁盘都会报废
所以一般这个super block会多副本的形式保存在其他块区内
这样等super出错后,系统就能自己进行拷贝完成修复
补充细节:
ib中,这个block[N]的大小是15
0-12对应的数据直接映射
13往后间接映射 保存其他数据块的信息
14三级映射 保存更多其他块的信息
类似于一颗多叉树
134kb+4kb/44kb+1000*4kb…
以这样的计算得到文件的大小,这样的文件的大小很大,足够满足用户使用
当文件很大时,一般是占据索引映射的文件都沾满了,会在上层进行必要的分开…
这样的文件都是ext2文件系统,其他的ext3,4都是在此基础上添加了日志等信息
从上层来看,系统一直使用inode,用户一直使用文件名称,如何对应起来?
将文件名转化为inode文件映射(OS处理).

目录文件的数据块内容存的是什么?
存的是自己目录内部保存的文件的文件名 和 inode与文件名称的映射关系,所以同一个目录下不允许存在同名文件(文件名称被当做key来使用,inode要不同,这俩相互监视)
这样根据inode就能找到对应的db的数据
so,我想在一个目录下想新建,修改,删除文件时,需要的是该目录的w权限!!!
在linux中文件名不属于文件属性,文件名存在于目录文件中
怎么找到test.c文件
首先要找到这个文件,要找到目录,并打开目录文件,这样就得到了文件名和inode的映射关系
有了这个关系就能根据inode找到在哪个分区下,在哪个分区的分组里面,
再根据inode在inode table中找到存放该inode信息的那个表,那么文件的所有属性就能找到
然后根据用户输入的指令,例如ls,就会将信息转化为字符串输出到界面
又如:cat test.c
一直到找到inode编号,根据inode在data blocks中,将数据导入到内存,再输出出来
这个找,从根目录开始找
可以通过vim查看这个目录文件的信息(仅做演示)
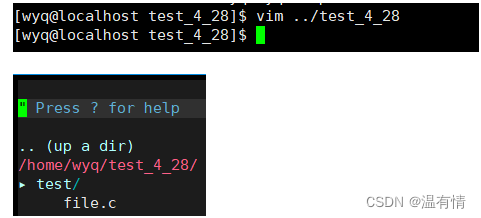
每个文件在哪,都是从路径中找到,这些路径都被记录下来(这些由一个进程启动时,进程会记录路径)
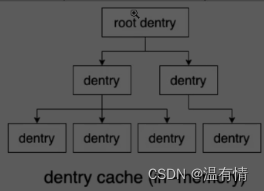
当一次进程启动,这个进程的所有路径信息会被缓存在内存中
系统中存在struct dentry{},在启动时将路径各个记录在这里面,以一种多叉树的形式
一个磁盘被分区格式化之后,linux要中使用这个分区,要把这个分区进行挂载mount(运维相关,不多做介绍)
FILE* fp = fopen("./log.txt","w");
执行这条语句,操作系统干了什么事?
首先确定的是是进程打开这个文件,进程有自己的CWD
根据进程的cwd和传入的路径,定位到该路径在磁盘的哪一个分区,哪一个分组.
找到上级目录的inode和文件内容,映射关系找到.这个文件的inode找到,属性加载到内存中,
在内存中构建struct FILE结构体,这个结构体指向这个inode,文件属性就这样出现了;
然后根据inode将数据块预加载到文件中,缓冲区就有了,此时再读将数据从缓冲区拷贝到应用层,这样这条语句就执行完成
软硬链接
软硬链接:
linux:软链接
硬链接
软链接
软链接:(是独立文件,有自己的inode编号) 功能像快捷方式,内部内容是指向目标文件的内容
bash">ln -s log log.soft.link
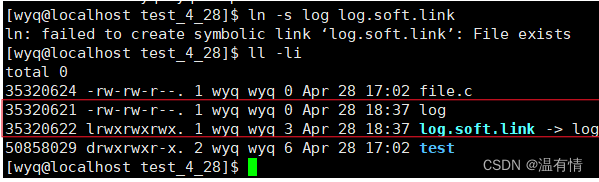
软链接:windows的快捷方式
linux下的场景跟win差不多
在多层深入的文件中打开不方便,建立连接快速打开
原文件路径
建立连接

执行:
硬链接
硬链接: (不是独立文件)
bash">ln hello hello.skft.link(
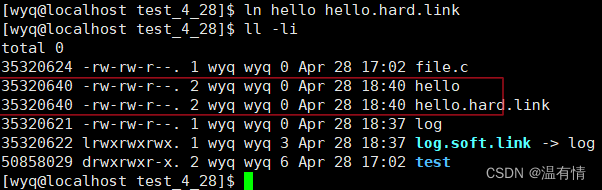
硬链接本质就是在指定目录内部的一组映射关系: 文件名<->inode的映射关系
文件硬链接删除,可以使用rm,但是更推荐unlink
先使用rm删除看结果:
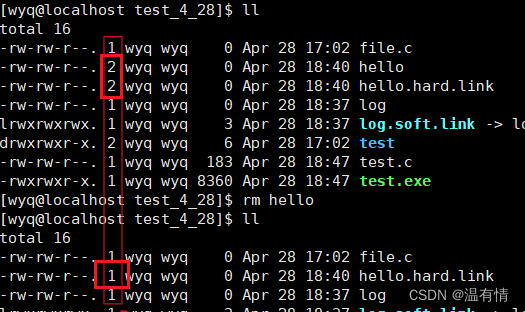
在删除这个hello之后,这个数字减小了
一个文件真正被删除是指文件名和inode没有映射关系,
在系统层次目标文件怎么知道文件名指向了我? inode内的引用计数,表明有几个文件映射关系(默认为1)
硬链接后进行++
文件名在目录里具有唯一性,文件名->"指针"
int ref_count;//引用计数
硬链接数,哪些文件指向对应的inode
普通文件硬链接数是1,文件系统的硬链接数为2,因为文件系统内的 . 文件也包括在内
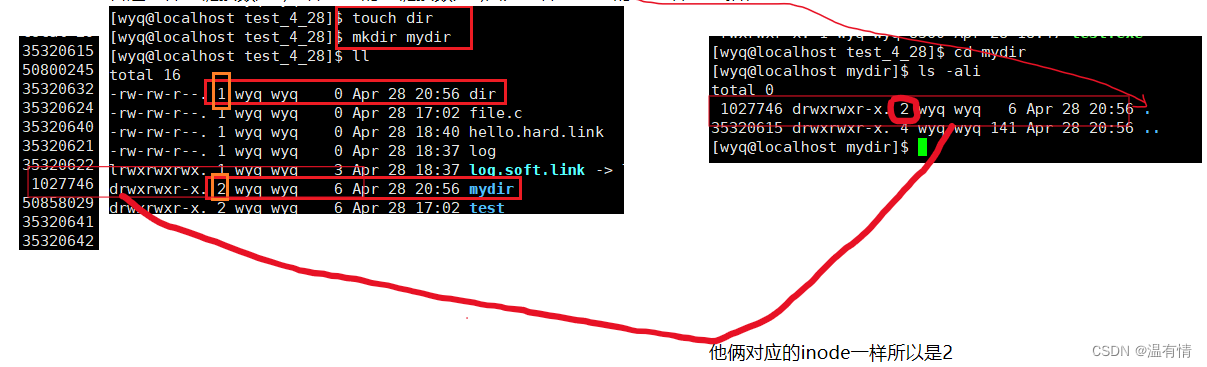 此时,在里面创建一个 dir文件
此时,在里面创建一个 dir文件
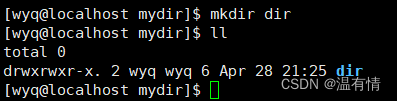
退回mydir的目录

发现这个硬链接数变成3,
在新建的dir里面他的. . 文件与mydir又有相同的inode编号,所以这个也是硬链接创建的文件,这也是…能回退上级的原因(应用场景)

区别:
软链接就是新文件
硬链接是文件名和inode的一组映射关系
关于本次就到此结束,喜欢请三连,任何问题可以评论留言~~




![buuctf——[CISCN2019 华北赛区 Day2 Web1]Hack World](https://img-blog.csdnimg.cn/direct/524e8c15b49744208d8cda058ae1b43f.png)