Selenium是一个开源的基于WebDriver实现的自动化测试工具。WebDriver提供了一套完整的API来控制浏览器,模拟用户的各种操作,如点击、输入文本、获取页面元素等。通过Selenium,我们可以编写自动化脚本,实现网页的自动化测试、数据采集等功能。它支持多种浏览器,如Chrome、Firefox、Edge等,并且提还供了丰富的语言绑定,包括Python、Java、C#等,使得开发者可以根据自己的需求选择合适的语言和工具链进行开发。
本文所有内容基于作者本人在使用python selenium进行web自动化任务时所遇到的实际问题和解决方案进行整理和总结。希望这些经验能够帮助到正在学习或使用python selenium进行web自动化的朋友们。
目录
selenium%E4%B8%8B%E8%BD%BD-toc" name="tableOfContents" style="margin-left:0px">selenium下载
WebDriver下载
添加到环境变量
selenium%E6%95%99%E7%A8%8B-toc" name="tableOfContents" style="margin-left:0px">selenium教程
导入的库
设置webdriver对象
设定options
打开网页
查找和定位元素
查找元素
定位元素
XPATH和CSS_SELECTOR 定位
ID定位
CLASS_NAME定位
LINK_TEXT与PARTIAL_LINK_TEXT定位
TAG_NAME定位
NAME定位
总结
WebDriver常用方法
打开网页
获得当前浏览器界面内打开过的所有窗口句柄列表
利用browser.window_handles切换当前窗口至最新打开的窗口
切换到iframe
关闭警告或广告弹窗
回退至上一个网页
跳转至下一个网页
关闭当前窗口
获得当前窗口的url
获得当前的窗口句柄
刷新当前界面
在当前页面内执行js脚本
在当前页面内执行异步js脚本
向元素输入指定内容
模拟元素被按下键盘上的指定按键
页面截图
元素截图
添加Cookie实现免登录
关闭webdriver
等待机制
隐形等待
显性等待
time.sleep
异常处理机制
ActionChains常用方法
鼠标左键单击元素
鼠标右键单击元素
鼠标移动并悬停在元素
鼠标左键单击长按一个元素
双击元素
将元素1拖动到元素2上(比如:上传文件)
模拟鼠标从当前位置按照偏移量移动到指定位置
将一个元素按照指定偏移量拖转到目的地(滑块验证)
点击元素时出现 element click intercepted exception的两个解决办法
结语
selenium%E4%B8%8B%E8%BD%BD" name="selenium%E4%B8%8B%E8%BD%BD" style="margin-left:0.0001pt; margin-right:0px; text-align:justify">Selenium下载
python">pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple seleniumWebDriver下载
在使用python Selenium进行web自动化测试或数据采集之前,我们需要下载与浏览器相对应的WebDriver。WebDriver是Selenium与浏览器进行交互的桥梁,不同的浏览器需要下载对应的WebDriver。对于Chrome浏览器,我们需要下载ChromeDriver;对于Firefox浏览器,我们需要下载GeckoDriver。这些WebDriver可以从各自浏览器的官方网站或Selenium的官方GitHub仓库中下载。
下载完成后,我们需要将WebDriver的路径添加到系统的环境变量中,或者在代码中指定WebDriver的路径,以便Selenium能够正确地找到并使用它。正确下载和配置WebDriver是使用Selenium进行web自动化的第一步。
这里以edgedriver为例,其他浏览器的webdriver配置大同小异。
前往Edge的webdriver官网,https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?form=MA13LH![]() https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?form=MA13LH
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?form=MA13LH 
根据自己的电脑配置选择一个版本下载即可(不需要选择特别新的版本,稳定版本的就可以)
下载时有的用户不知道自己的windows电脑的cpui架构是x86还是x64的,这里,我们只需要在cmd中输入systeminfo命令后在弹出的提示符中的系统类型中便可以看到自己电脑的cpu架构。
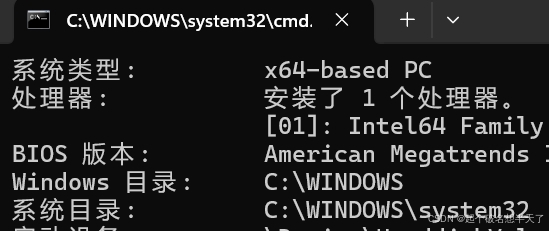
下载完成之后将edgedriver.exe文件的路径复制,并添加到环境变量中即可,
添加到环境变量
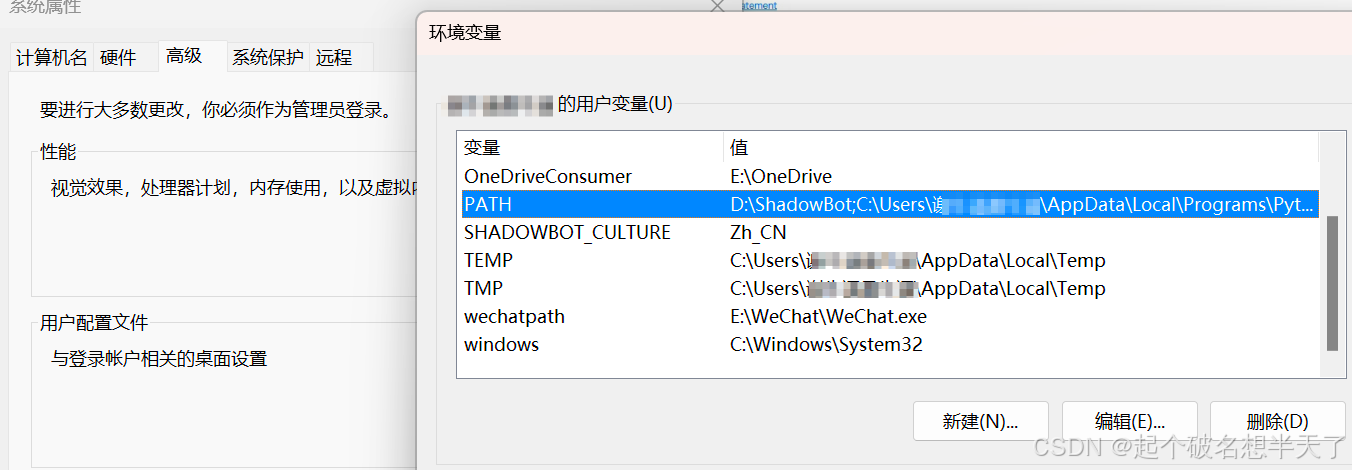
win+s搜索编辑系统环境变量,点击第一个搜索结果后,点击环境变量按钮,选中上方用户变量中的PATH(python安装时默认添加到系统的的那个环境变量名称) 点击编辑按钮进入到PATH中。
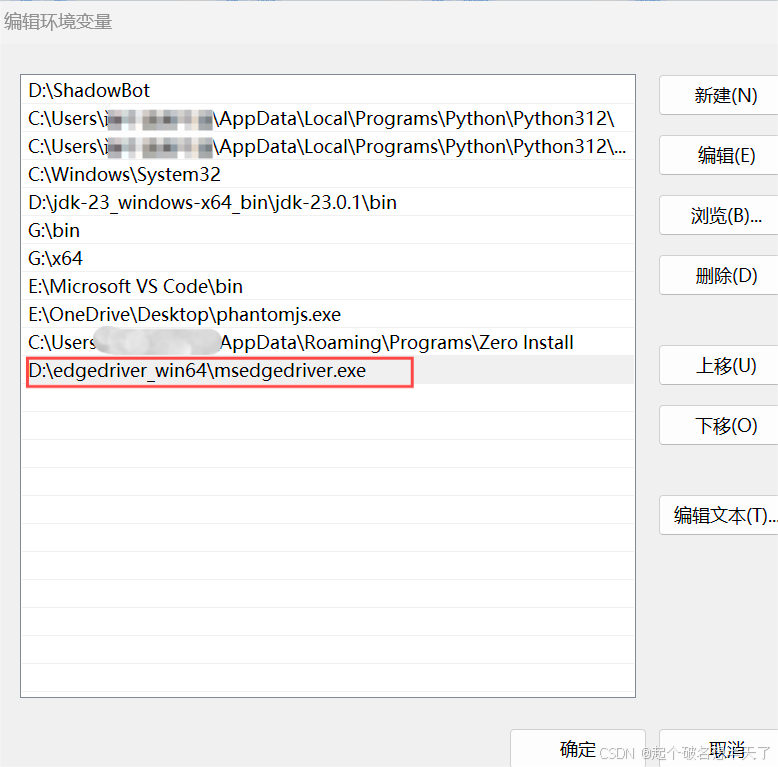
将刚刚下载好的edgedriver.exe的路径复制到里边,然后点击三个已经打开的窗口的确定,退出设置系统环境变量的窗口后,至此已将edgedriver的路径添加到了环境变量中。我们可以使用python代码来进行web自动化了
selenium%E6%95%99%E7%A8%8B" name="selenium%E6%95%99%E7%A8%8B">selenium教程
以下的python selenium代码和操作技巧是作者本人在进行web自动化过程中常用到的一些基本方法,基本涵盖了常见操作。
模块导入
当我们在学习python的一个模块或框架时,一定要多看这个模块的源码,对整个模块的基本结构要十分熟悉,只有这样我们在导入库或模块时写起代码来才能得心应手。
以下是Selenium官方github链接:
https://github.com/SeleniumHQ/selenium/tree/trunk/py![]() https://github.com/SeleniumHQ/selenium/tree/trunk/py 仔细阅读源代码,我们不难画出这样一个树状结构图来描述Selenium的各个模块的关系,以便我们在代码中导入各个模块
https://github.com/SeleniumHQ/selenium/tree/trunk/py 仔细阅读源代码,我们不难画出这样一个树状结构图来描述Selenium的各个模块的关系,以便我们在代码中导入各个模块

python">from selenium import webdriver#webdriver对象
from selenium.webdriver.edge.options import Options#options选项因webdriver类型而异,这里使用edge
from selenium.webdriver.common.by import By#定位元素By类
from selenium.webdriver.common.keys import Keys#模拟按键操作Keys类
from selenium.webdriver.support.ui import WebDriverWait#显性等待
from selenium.webdriver import ActionChains#用来模拟人为操作鼠标的一系列动作
from selenium.webdriver.support import expected_conditions as EC#条件等待,配合显性等待使用
from selenium.common.exceptions import TimeoutException#超时错误
from selenium.common.exceptions import NoSuchElementException#元素定位错误设置webdriver对象
python">browser=webdriver.ChromiumEdge()#设定一个webdriver对象,Edge浏览器
browser=webdriver.Chrome()#设定一个webdriver对象,Chrome浏览器
browser=webdriver.Firefox()#设定一个webdriver对象,Firefox浏览器这里需要注意的是,要使用哪一个类型的浏览器作为webdriver,那么我们需要下载该浏览器的driver.exe文件,并按照之前的流程将其添加到环境变量中,这里我们使用Edgedriver,故webdriver对象是ChromiumEdge()
设定options
selenium中的options是用来设定浏览器的一些属性和必要的操作选项的。
同样的,options也因浏览器的类型而异,导入时也应该按照你的webdriver类型选择
python">from selenium.webdriver.firefox.options import Options#火狐浏览器
from selenium.webdriver.edge.options import Options#Edge浏览器
from selenium.webdriver.chrome.options import Options#Chrome浏览器以下是一些常见的options选项(主要是用来隐藏自动化控制的痕迹并且设置文件下载路径)
python">options=Options()#先声明一个options变量
Options.add_argument(‘--disable-blink-features=AutomationControlled)#隐藏自动化控制标头
Option.add_experimental_option('excludeSwitches',['enable-automation'])#隐藏自动化标头
Options.add_argument('--ignore-ssl-errosr')#忽略ssl错误
Options.add_argument('--ignore-certificate-errors')#忽略证书错误
prefs = {'download.default_directory': '文件夹路径', # 设置文件默认下载路径"profile.default_content_setting_values.automatic_downloads": True # 允许多文件下载}options.add_experimental_option("prefs", prefs)#将prefs字典传入options
最后,我们需要将已经设定好的options传入到先前设定的webdriver对象中
python">browser=webdriver.ChromiumEdge(options)#将options传入到webdriver中这样,我们便可以使用browser(已经设定好的options 的webdriver对象进行web自动化时,浏览器就会带有options中的特性了)进行后续自动化流程了。
打开网页
接着我们使用已经配置好的webdriver使用get方法即可打开网页
python">url=''
browser.get(url)查找和定位元素
查找元素
selenium中查找元素有两种方法:find_element()与find_elements()
使用find_element或find_elements方法时,其内部第一个参数为定位方式,使用By类下的8个属性指明,后边紧跟着的是元素的在html页面中的定位值,类型为字符串。
python">browser.find_element(By.XPATH,'')#根据条件查找单个元素,返回结果为webelementpython">browser.find_elements(By.XPATH,'')#查找所有符合条件的元素,返回结果为webelement构成的列表特别地,在使用find_elements方法时,它会返回所有匹配给定定位器和值的元素列表。如果没有找到任何元素,它将返回一个空列表。这与find_element方法不同,后者在找不到元素时会抛出NoSuchElementException异常。因此,在使用find_elements方法时,我们需要检查返回的列表是否为空,以避免出现错误。
同时,selenium还支持链式查找,即:你可以在查找到一个顶层元素后,直接对该元素使用find_element()和find_elements()方法来定位其内部的子元素。
python">top_element=browser.find_element(By.ID,'')
sub_elements=top_element.find_elements(By.TAG_NAME,'')定位元素
selenium定位元素时共有八种方式:
python">brwoser.find_element(By.XPATH,’’)#根据元素xpath定位元素,因为获取简单,所以用的最多
brwoser.find_element(By.CSS_SELECTOR,’’)#根据元素的css_selector定位,因为获取简单,用的最多
#除xpath和css-selector是可以在浏览器直接复制得到以外,其余定位方法都需要观察html源代码来定位
brwoser.find_element(By.ID,’’)
brwoser.find_element(By.CLASS_NAME,’’)
brwoser.find_element(By.PARTIAL_LINK_TEXT,’’)
brwoser.find_element(By.LINK_TEXT,’’)
brwoser.find_element(By.TAG_NAME,’’)
brwoser.find_element(By.NAME,’’)
XPATH和CSS_SELECTOR 定位

XPATAH和CSS_SELECTOR,在浏览器中打开开发者工具,找到指定元素后,右击,点击复制,便可以直接复制该元素的XPATH和CSS_SELECTOR路径用于定位。
python">#复制到的XPATH用于定位
element=browser.find_element(By.XPATH,'//*[@id="home-content-box"]/div[3]/div[2]/div[5]/div/div/div/div/a[1]')python">#复制到的CSS_SELECTOR用于定位
element=browser.find_element(By.CSS_SELECTOR,'#home-content-box > div.home-article > div.home-article-cont > div:nth-child(5) > div > div > div > div > a.article-title.word-1')ID定位
使用ID定位元素时需要待定位元素具有id属性才可以,id属性通常在Input输入框和Button按钮这两个组件中较为常见。

该组件为一个id为“toolbar-search-button”名为搜索的按钮,那么我们在定位该元素时便可以
python">search_button=browser.find_element(By.ID,'toolbar-search-button')
search_button.click()#点击search_buttonCLASS_NAME定位
同样的,使用CLASS_NAME定位元素时,元素需要具有class_name属性,一般来说class_name在html中常见于div标签(盒子)。

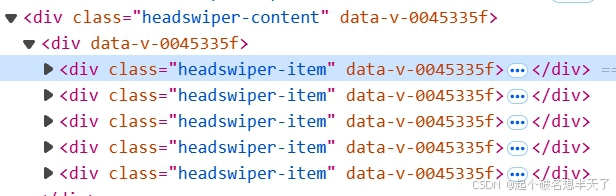
上边是一些由div组件构成的新闻列表,我们想要获得每个div组件内的所有新闻名称,即每个div元素的text属性,那么便可以使用class_name的定位方式。
python">divs=brower.find_elements(By.CLASS_NAME.'headswiper-item')#定位到所有div
titles=[div.text for div in divs]#在所有div中遍历获取text属性
print(titles)#打印结果结果:

LINK_TEXT与PARTIAL_LINK_TEXT定位
LINK_TEXT与PARTIAL_LINK_TEXT在定位元素时主要根据链接的全部文本或部分文本进行定位。LINK_TEXT指的是完整的链接文本,而PARTIAL_LINK_TEXT则是链接文本的一部分。
例如,如果页面中有一个链接是“点击这里访问百度”,那么可以使用LINK_TEXT('点击这里访问百度')或PARTIAL_LINK_TEXT('点击这里')来定位这个链接。这种定位方式对于页面中的链接元素非常有效,尤其是当链接文本较为独特,不容易与其他元素混淆时。

这里我们以csdn网页中的最顶层一栏为例

对于顶层一栏中的下载文本,在开发者工具中观察其原码,我们不难发现这就是一个典型的LinkText,并且当我们点击这个文本后,页面便会跳转到新的链接。对此,我们便可以使用LINK_TEXT方法定位。
python">download=browser.find_element(By.LINK_TEXT,'下载')
download.click()#点击下载文字TAG_NAME定位
TAG_NAME是HTML标签的名称,通过元素的标签名来定位元素时,若html中不止一个元素具有此标签名的话,我们通常使用find_elements()函数查找。

比如上边的网页中,每个论文的都被放在标签名为'li'的容器内

其内部的text属性是我们想要获取的文章标题,那么我们的代码便可以这样写:
python">ssay_container=browser.find_element(By.XPATH,'//*[@id="new-article-list"]/div/ul ')#这是一个存放多篇论文题目的div容器
essaies=essay_container.find_elements(By.TAG_NAME,"li")#在div容器中遍历查找tagname是li的元素
essay_titles=[essay.text for essay in essaies]#遍历essaies内所有元素,使用text方法获取essay题目NAME定位
NAME定位是通过元素的name属性来定位元素。在HTML中,一些元素如input、select等都可以设置name属性。使用NAME定位时,我们只需传入元素的name属性值即可。
python">input=browser.find_element(By.NAME,'username')#定位NAME属性为username的输入框
input.send_keys('user')#向输入框内填写user总结
在使用selenium定位元素时,最简单好用的是XPATH和CSS_SELECTOR,因为其获取方式简单,但是XPATH和CSS_SELECTOR,在定位速度上不如ID等其他定位方式,因为ID和其他的定位方式都是html元素的属性,其在DOM树中是唯一的,查找速度最快。
同时,还有一点值得注意的是,虽然XPATH和CSS_SELECTOR可以非常灵活地定位页面元素,但是在一些复杂的页面中,XPATH和CSS_SELECTOR可能会变得非常冗长和复杂,且由于网页内容的变动二者也会随之产生变化,这会增加代码的复杂性和维护难度。
因此,在进行web自动化任务时我们应该先观察网页原码,定位元素时尽量先考虑使用元素的属性来进行定位,实在找不到再使用XPATH和CSS_SELECTOR对其进行定位。
WebDriver常用方法
这里我们假设browser为已经设定好的一个webdriver对象
打开网页
python">browser.get(url)#打开网页获得当前浏览器界面内打开过的所有窗口句柄列表
python">browser.window_handles#获得当前所有打开的窗口句柄,是一个列表,获得最新的当期界面可以用利用browser.window_handles切换当前窗口至最新打开的窗口
python">#利用browser.window_handles切换当前窗口至最新打开的窗口
Latest_window=browser.window_handles[-1]
browser.switch_to.window(Latest_window)切换到iframe
python">browser.switch_to.frame()#切换到iframe给当前webdriver添加cookie
python">browser.add_cookie()#给当前webdriver添加cookie,通常出现在免登录情境下获得当前页面url的cookies
python">browser.get_cookies()#获得当前页面url的cookies删除当前webdriver已经添加过的所有cookies
python">browser.delete_all_cookies()#删除当前所有cookies关闭警告或广告弹窗
browser.switch_to.alert.dismiss()#注意,该方法只能关闭使用js的alert函数实现的弹窗,其余弹窗无法关闭,还会引发错误回退至上一个网页
python">browser.back()#回退至前一个网页跳转至下一个网页
python">browser.forward()#跳转至下一个网页关闭当前窗口
python">browser.close()#关闭当前窗口获得当前窗口的url
python">browser.current_url#返回当前窗口的url获得当前的窗口句柄
python">browser.current_window()#获得当前的窗口句柄,常与browser.switch_to.window()配合使用刷新当前界面
python">browser.refresh()#刷新一下当前界面在当前页面内执行js脚本
python">browser.execute_script()#在当前页面内执行js脚本,传入参数是js代码的字符串形式在当前页面内执行异步js脚本
python">browser.execute_async_script()#在当前页面内执行异步js脚本向元素输入指定内容
python">send_keys()#用来向一个输入框输入字符串
Input_element=browser.find_element(By.XPATH,’’)
Input_element.send_keys('待输入内容')
模拟元素被按下键盘上的指定按键
python">Send_keys(Keys.按键名称(英文单词大写))#可以模拟按下键盘上的某个按键
#使用Keys需要from selenium.webdriver.common.keys import Keys
Input_element.send_keys(Keys.ENTER)#按下enter健页面截图
获取当前网页页面截图有以下3种方法:
python">browser.get_screenshot_as_png()
browser.get_screenshot_as_base64()
browser.get_screenshot(filename)用法详解:
python">pic_data=browser.get_screenshot_as_png()
#使用get_screenshot_as_png获得的是当前页面截图的bytes型数据
#若要保存至本地需要使用with open语句写入
with open('页面截图.png','wb') as f:f.write(pic_data)base64_string=browser.get_screenshot_as_base64()#直接返回页面截图的base64字符串browser.get_screenshot(filename)#直接将页面截图保存到本地,需要传入一个filename参数,注意文件名的结尾必须是.png否则会引发warning元素截图
获取某个元素的截图有以下3种方法:
python">element.screenshot_as_png
element.screenshot_as_base64
element.screenshot(filename)用法详解:
python">element=browser.find_element(By.XPATH,’’)pic_data=element.screenshot_as_png
#使用screenshot_as_png获得的是图片的bytes型数据,若要保存本地需要with open保存
with open('filename.png','wb') as f:f.write(pic_data)base64_sring=element.screenshot_as_base64#直接返回元素截图的base64字符串element.screenshot(filename)#直接将元素截图保存到本地,需要传入一个filename参数,注意文件名的结尾必须是.png否则会引发warning
添加Cookie实现免登录
说明:不同网站的cookie失效时间不同,一般而言为了安全,很多网站的cookie设置为30min或会话,有的网站也有可能时间更长,总之使用cookie实现免登录的思路就是先保存登陆过的页面的cookie至本地,然后下载打开网页时直接添加到webdriver中,刷新后此时webdriver内的页面便是已登录的状态了。
python">import json
#这里假设我们已经有一个设定好的webdriver
首先获取登录后页面的cookie,
cookies=browser.get_cookies()
with open('cookies.json','w') as cookies #将当前页面的cookie保存到本地json文件中json.dump(cookies)#在下次登录页面时我们只需要将之前保存的的登录后的页面的cookie添加到webdriver中,
with open('cookies.json','r') as cookies:cookies=json.loads(cookies.read())for cookie in cookies:cookie_dict = {'domain': cookie.get('domain'),#这里是固定的每个网站都不同'name': cookie.get('name'),'value': cookie.get('value'),"expires": cookie.get('value'),'path': '/','httpOnly': False,'HostOnly': False,'Secure': False}browser.add_cookie(cookie_dict)
#刷新页面后,页面便瞬间恢复到已登录状态
browser.refresh()关闭webdriver
python">browser.quit()等待机制
在使用selenium进行web自动化任务时,有三种等待机制,隐性等待,显性等待,以及time.sleep
隐形等待
implicately_wait
python">browser.implicately_wait(秒数)等待页面内的元素在dom中出现,在全局中只需要设定一次即可,不需要到处写
显性等待
WebdriverWait,可以结合expected_conditions查找元素时进行条件等待
python">from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC#最多等待10秒直到元素出现
#等待时间内没有找到元素超时会抛出TimeoutException
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH,'')))#还可以等待这个元素不出现
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH,'')))
#等待时间内找到元素超时会抛出TimeoutException#二者唯一的区别是until和until_nottime.sleep
这个最常用,他的作用就是阻塞当前程序内线程,让整个程序停下来,等待已经打开的webdriver内的元素加载完毕,相较于implicately_wait不具有太多的灵活性,但确实是最稳定的等待机制。
使用时需要:
python">import time
time.sleep(秒数)异常处理机制
在selenium进行web自动化任务过程中,最常见的两个异常分别是:NoSuchElementExecption与TimeoutException。
其中,TimeoutException主要出现在显性等待元素中,NoSuchElementExecption主要出现在find_element的失败情况中。对此,我们使用try except语句捕获异常进行处理即可,不过,在这之前我们需要先从selenium内的exceptions模块中导入这两个异常
python">from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import NoSuchElementExceptionpython">try:element=browser.find_element(By.XPATH,'')element.click()
except NosuchElementException:print('无法找到该元素!')browser.quit()ActionChains常用方法
首先,我们需要将Actionchains导入并与webdriver绑定
python">from selenium.webdriver import ActionChains
action=ActionChains(browser)#绑定之前的webdriver接着对于action,我们便可以用来模拟鼠标的一系列复杂动作,如拖动、点击、双击、悬停等。
假设我们已经定位到一个元素
python">element=browser.find_element(By.XPATH,’’)鼠标左键单击元素
python">action.click(element).perform()鼠标右键单击元素
python">action.context_click(element).perform()鼠标移动并悬停在元素
python">action.move_to_element(element).perform()鼠标左键单击长按一个元素
python">action.click_and_hold(element).perform()双击元素
python">action.double_click(element).perform(将元素1拖动到元素2上(比如:上传文件)
python">action.drag_and_drop(element1,element2).perform()模拟鼠标从当前位置按照偏移量移动到指定位置
python">action.move_by_offset(xoffset,yoffset).perform()将一个元素按照指定偏移量拖转到目的地(滑块验证)
python">action.drag_and_drop_by_offset(element,xoffset,yoffset).perform()点击元素时出现 element click intercepted exception的两个解决办法
1.使用webdriver的execute_script()方法执行"arguments[0].click()"这串js代码
python">button=browser.find_element(By.XPATH,“”)#假设我们查找到一个按钮
在使用button.click()时可能会出现报错:element click intercepted exception,这时我们使用下边这行代码,可以解决这个问题
browser.execute_script(‘arguments[0].click()’,button)#即执行点击按钮的js代码2.使用ActionChains 的模拟鼠标移动到元素上后单击
python">action.move_to_element(element).click(element).perform()结语:
以上便是作者本人关于python Selenium在web自动化中的使用方法与常用技巧的总结。当然,Selenium的功能远不止于此,它还有许多高级特性和用法等待我们去探索和掌握。但无论如何,掌握以上这些基础知识和技巧,已经能够帮助我们解决大部分Web自动化测试中的问题了。希





