一、LOAD
Hive在将数据加载到表中时不进行任何转换。加载操作目前是纯拷贝/移动操作,将数据文件移动到与配置单元表相对应的位置。
语法:
load data [local] inpath 'filepath' [overwrite] into table tablename [partition (partcol1=val1, partcol2=val2 ...)]
示例:
建表
create table test.user_msg(id string,telno string,visit_url string,status string,visit_time int,visit_num int)
partitioned by (dt string)
row format delimited
fields terminated by ','
stored as textfile ;制作数据 vi test_user_msg.txt
1,187xxxx6398,baidu.com,200,365,46
2,156xxxx6398,qq.com,200,485,95
3,136xxxx6398,mp.csdn.net,200,9659,184
4,177xxxx6398,cwiki.apache.org,200,112,6
5,166xxxx6398,www.antlr.org,200,30,2
6,185xxxx6398,pan.baidu.com,200,26815,849
7,188xxxx6398,kuaishou.cn,200,695811,9154
8,190xxxx6398,www.cloudera.com,200,75,3
9,144xxxx6398,douyin.com,200,1568492,1026
9,134xxxx6398,weixin.qq.com,200,6941611,2984
执行:
load data local inpath '/root/temp/test_user_msg.txt' into table test.user_msg partition(dt='20240415');
select * from test.user_msg;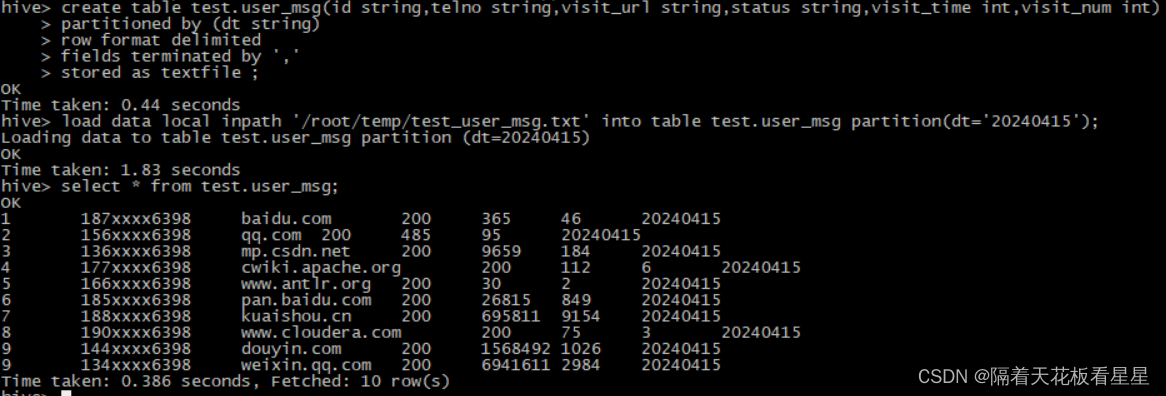
Hive3.0之前的加载操作是纯粹的复制/移动操作,将数据文件移动到与配置单元表相对应的位置。
filepath 可以是以下三种情况(filepath可以指一个文件也可以指一个目录,Hive3.0以后可以包含子目录)
1、相对路径,例如temp/test_user_msg.txt
2、绝对路径,如/root/temp
3、HDFS路径:hdfs://namenode:9000/user/hive/temp/test_user_msg.txt
要加载到的目标可以是表或分区
local 表示选择本地文件或目录进行加载数据
如果没有指定local,Hive将使用filepath的完整URI(默认使用使用hadoop配置变量fs.default.name中指定Namenode URI的scheme和authority)如果路径不是绝对路径,Hive将自动添加/user/<username>对其进行解释
overwrite 表示目标表(或分区)的内容将被删除,并由filepath引用的文件替换;否则,filepath引用的文件将被添加到表中
Hive3.0以后版本支持额外的 load 操作,因为Hive在内部将 load 重写为 insert as select。
1、若表有分区,而load命令并没有分区,则加载将转换为INSERT AS SELECT,并假设最后一组列是分区列
2、如果表为分桶表,要看Hive当前是否是严格模式
a、如果是,启动INSERT AS SELECT作业
b、如果不是,如果文件名符合命名约定(如果文件属于bucket 0,则应命名为000000_0或000000_0_copy_1,或者如果属于bucket 2,则名称应类似于000002_0或000002_0_copy_3等),则它将是纯复制/移动操作,否则它将启动INSERT AS SELECT作业
inputformat 可以是任何Hive输入格式,例如文本、ORC等 (区分大小写)
serde 可以是相关联的Hive serde (区分大小写)
二、INSERT
1、将数据从查询插入表
语法1:
insert overwrite table tablename1 [partition (partcol1=val1, partcol2=val2 ...) [if not exists]] select_statement1 from from_statement;
insert overwrite将覆盖表或分区中的任何现有数据除非为分区提供了if not exists
自hive2.3.0起,如果表具有tblproperties(“auto.pruge”=“true”),则在进行插入时不会将表的先前数据移动到垃圾桶(如果配置了Trash)。此功能仅适用于托管表。当“auto.purge”属性未设置或设置为false时,此功能将关闭。
insert overwrite table test.user_msg_2 partition(dt='20240417') select id,telno,visit_url,status,visit_time,visit_num from test.user_msg where dt = '20240415' ;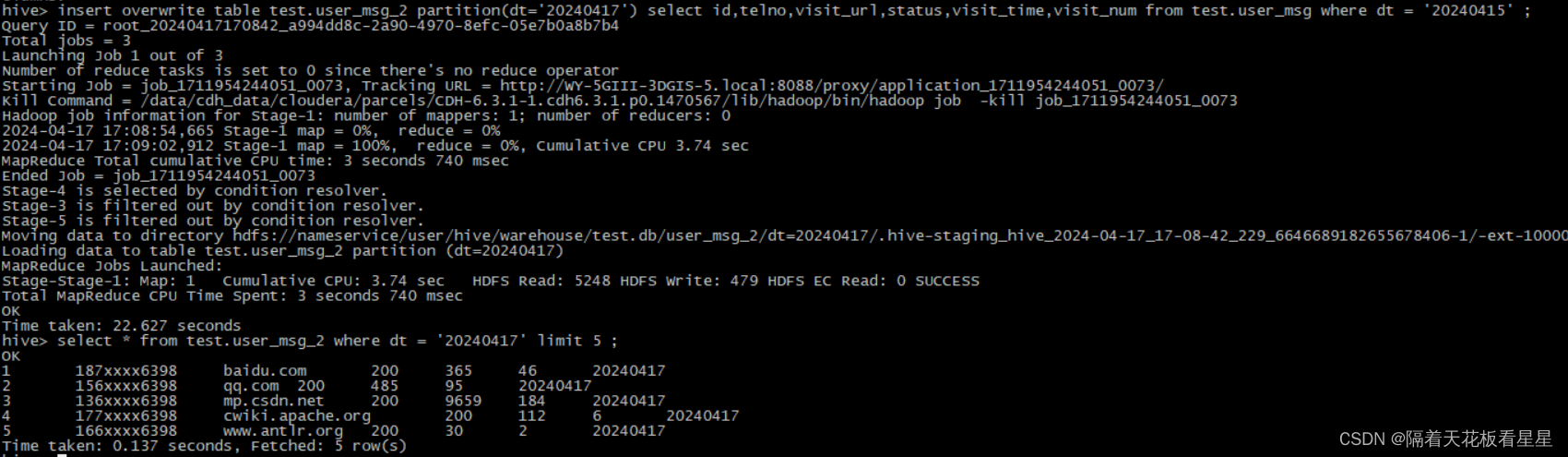
语法2:
insert into table tablename1 [partition (partcol1=val1, partcol2=val2 ...)] select_statement1 from from_statement;
insert into将追加到表或分区,保持现有数据的完整性
从Hive 0.13.0开始,可以通过使用 TBLPROPERTIES ("immutable"="true") 默认为false 将表设置为不可变表,如果不可变表已经存在任何数据,则不允许将insert into行为插入其中,如果不可变表为空,则insert into仍然有效,不可变表对insert overwrite无效
不可变表可以防止意外更新,第一次插入不可变表成功,后续连续插入失败,这样表中就只有一组数据,而不是静默地成功插入表中的多个数据副本
insert into table test.user_msg_2 partition(dt='20240417') select id,telno,visit_url,status,visit_time,visit_num from test.user_msg where dt = '20240415' ;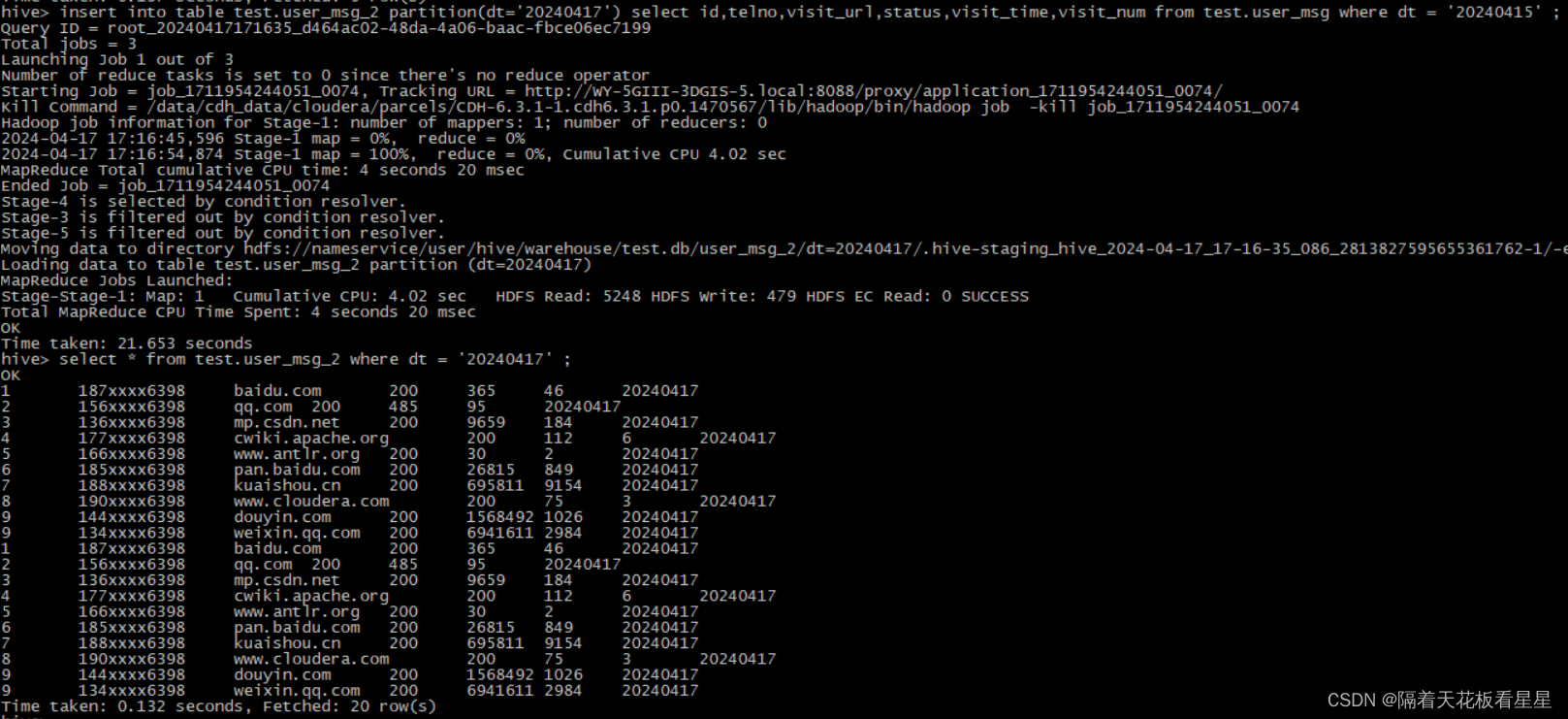
语法3:多个插入
from from_statement
insert overwrite table tablename1 [partition (partcol1=val1, partcol2=val2 ...) [if not exists]] select_statement1
[insert overwrite table tablename2 [partition ... [if not exists]] select_statement2]
[insert into table tablename2 [partition ...] select_statement2] ...;
可以在同一查询中指定多个插入子句(也称为多表插入)。
每个select语句的输出都被写入所选的表(或分区)
from test.user_msg
insert overwrite table test.user_msg_2 partition(dt='20240417') select id,telno,visit_url,status,visit_time,visit_num
insert into table test.user_msg_3 partition(dt='20240417') select id,telno,visit_url,status,visit_time,visit_num ;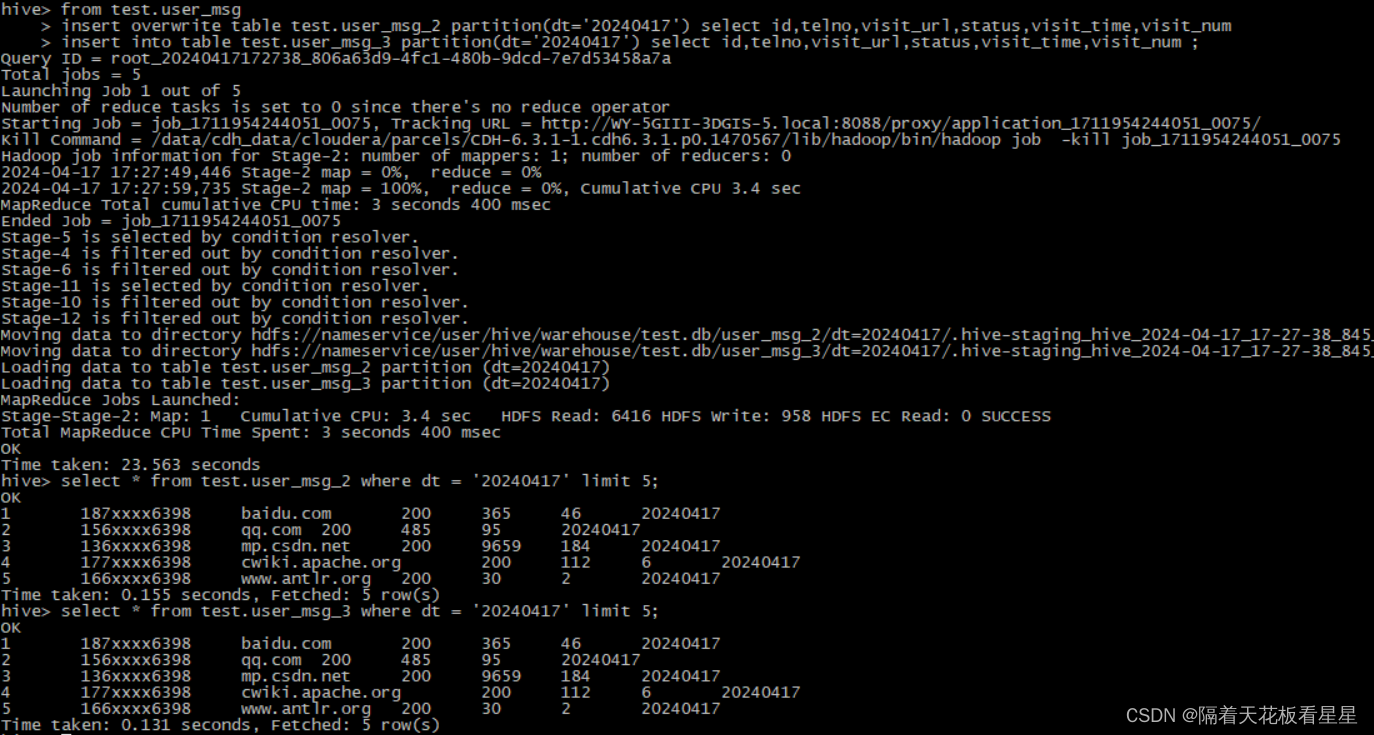
语法4:动态分区插入
insert overwrite table tablename partition (partcol1[=val1], partcol2[=val2] ...) select_statement from from_statement;
insert into table tablename partition (partcol1[=val1], partcol2[=val2] ...) select_statement from from_statement;
在动态分区插入中,用户可以给出部分分区规范,比如:只需在partition子句中指定分区列名的列表。列值是可选的。
如果给定了分区列值,我们将其称为静态分区,否则它就是动态分区。
每个动态分区列都有来自select语句的相应输入列。这意味着动态分区的创建是由输入列的值决定的。动态分区列必须在select语句中的列中最后指定,并且指定顺序与它们在partition()子句中的显示顺序相同
从Hive3.0.0起,动态分区列也可以不指定,Hive会自动生成分区规范。
在Hive0.9.0之前,默认情况下禁用动态分区插入,目前默认情况下启用动态分区插入。
以下是动态分区插入的相关配置属性:
| 配置属性 | 默认值 | 备注 |
| hive.exec.max.dynamic.partitions.pernode | 100 | 允许在每个mr节点中创建的最大动态分区数 |
| hive.exec.max.dynamic.partitions | 1000 | 允许创建的动态分区的最大总数 |
| hive.exec.max.created.files | 100000 | MapReduce作业中所有mr创建的HDFS文件的最大数量 |
| hive.exec.dynamic.partition.mode | strict | 严格模式,该模式下必须至少指定一个静态分区 |
| hive.exec.dynamic.partition | true | 启用动态分区 |
| hive.error.on.empty.partition | false | 如果动态分区插入空结果,是否引发异常 |
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table test.user_msg_2 partition(dt) select id,telno,visit_url,status,visit_time,visit_num,dt from test.user_msg where dt = '20240415' ;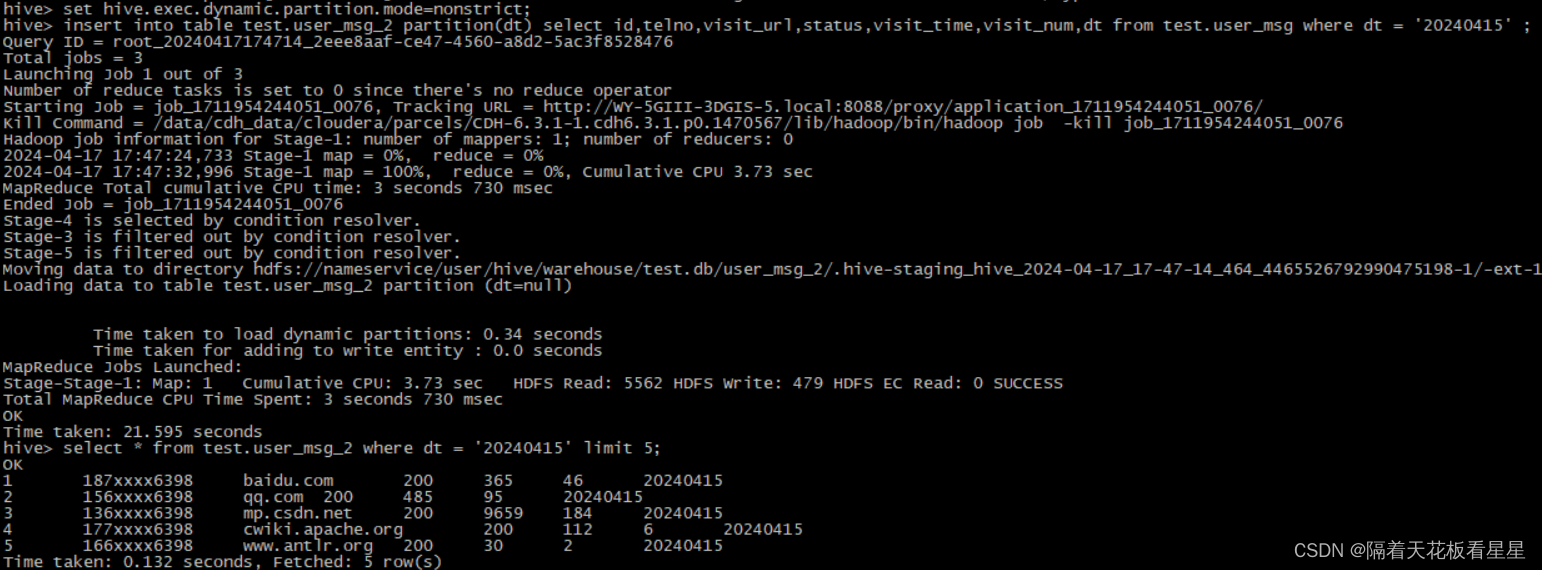
2、将数据从查询写入文件系统
语法1:
insert overwrite [local] directory directory1
[row format row_format] [stored as file_format]
select ... from ...
Hive会默认将数据放到HDFS上,且可以从 MR 作业中并行写入HDFS
如果使用 local 关键字,Hive将把数据写入本地文件系统上
写入文件系统的数据被序列化为文本,列用^A(\001)分隔,行用换行符分隔。如果任何列不是基元类型,那么这些列将被序列化为JSON格式
insert overwrite directory '/data/test/user_msg' select * from test.user_msg ;
dfs -du -h /data/test/user_msg ; 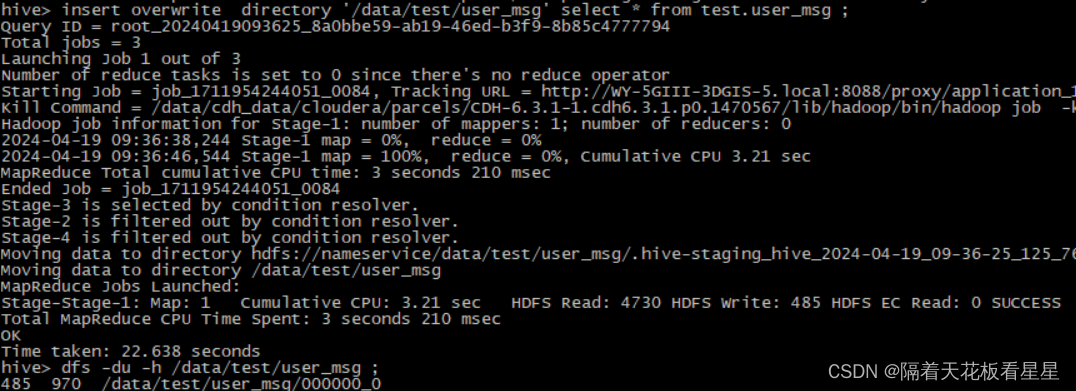
语法2:多个插入
from from_statement
insert overwrite [local] directory directory1 select_statement1
[insert overwrite [local] directory directory2 select_statement2] ...
from test.user_msg
insert overwrite directory '/data/test/user_msg_2' select *
insert overwrite local directory '/root/temp/user_msg_local' select * ;
语法3:格式化
: delimited [fields terminated by char [escaped by char]] [collection items terminated by char]
[map keys terminated by char] [lines terminated by char]
[null defined as char]
insert overwrite directory '/data/test/user_msg'
row format delimited
fields terminated by '|'
select * from test.user_msg;
dfs -cat /data/test/user_msg/* ;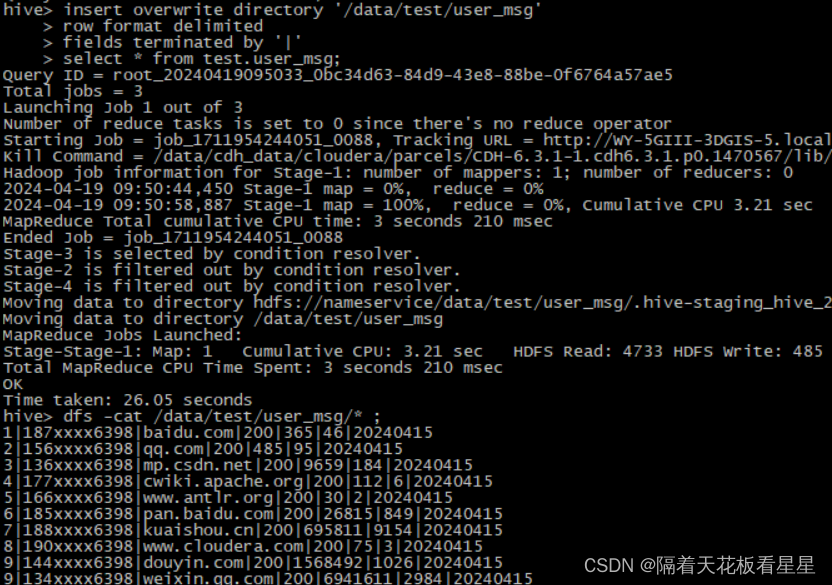
3、将值从sql插入表
语法:
insert into table tablename [partition (partcol1[=val1], partcol2[=val2] ...)] values values_row [, values_row ...]
values 子句中列出的每一行都插入到表中。
必须为表中的每一列提供值。目前还不支持仅在某些列中插入值的标准SQL语法。但可以将列值设为null。
如果插入的表支持ACID,并且正在使用支持ACID的事务管理器,则此操作将在成功完成后自动提交
Hive不支持复杂类型(数组、映射、结构、联合)的数据通过这种方式插入
insert into table test.user_msg partition (dt = '20240420')values ('100', '187xxxx3695', 'sports.com','200',653,74), ('101', '156xxxx3689', 'mail.com','200',94569,368);
select * from test.user_msg where dt = '20240420' ;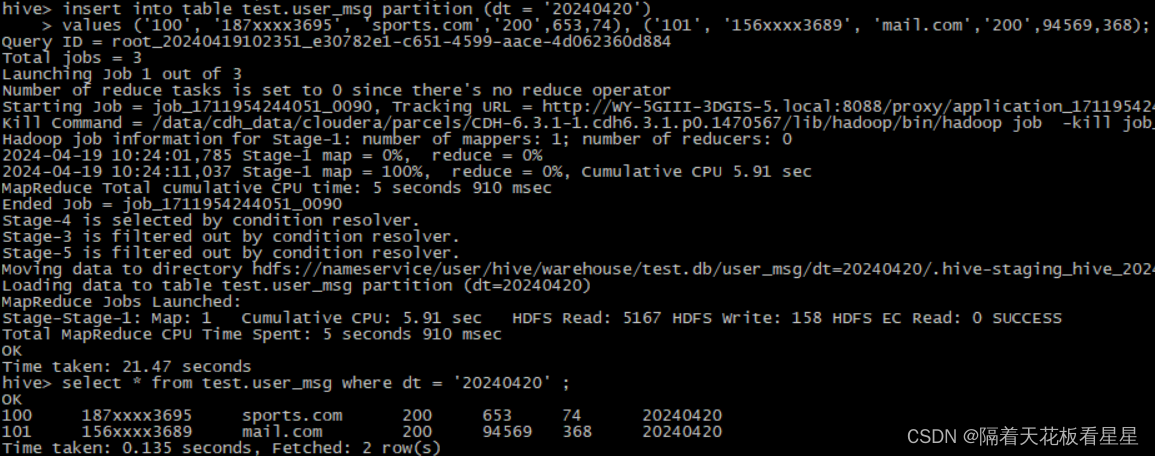
三、UPDATE
只能对支持ACID的表执行更新
语法:
update tablename set column = value [, column = value ...] [where expression]
无法更新分区列和分桶列
Hive 0.14中,成功完成,更改将自动提交。
更新时,矢量化将自动关闭,更新后的表仍然可以使用矢量化进行查询(在Hive中,矢量化是一种优化技术,它通过减少I/O操作和CPU计算来提高查询性能)
建议您在进行更新时将hive.optimity.sort.dynamic.partition=false设置为false,因为这会产生更高效的执行计划
对Hive表启用 ACID(Atomicity, Consistency, Isolation, Durability)功能并将且转变为事务表
#创建事务表
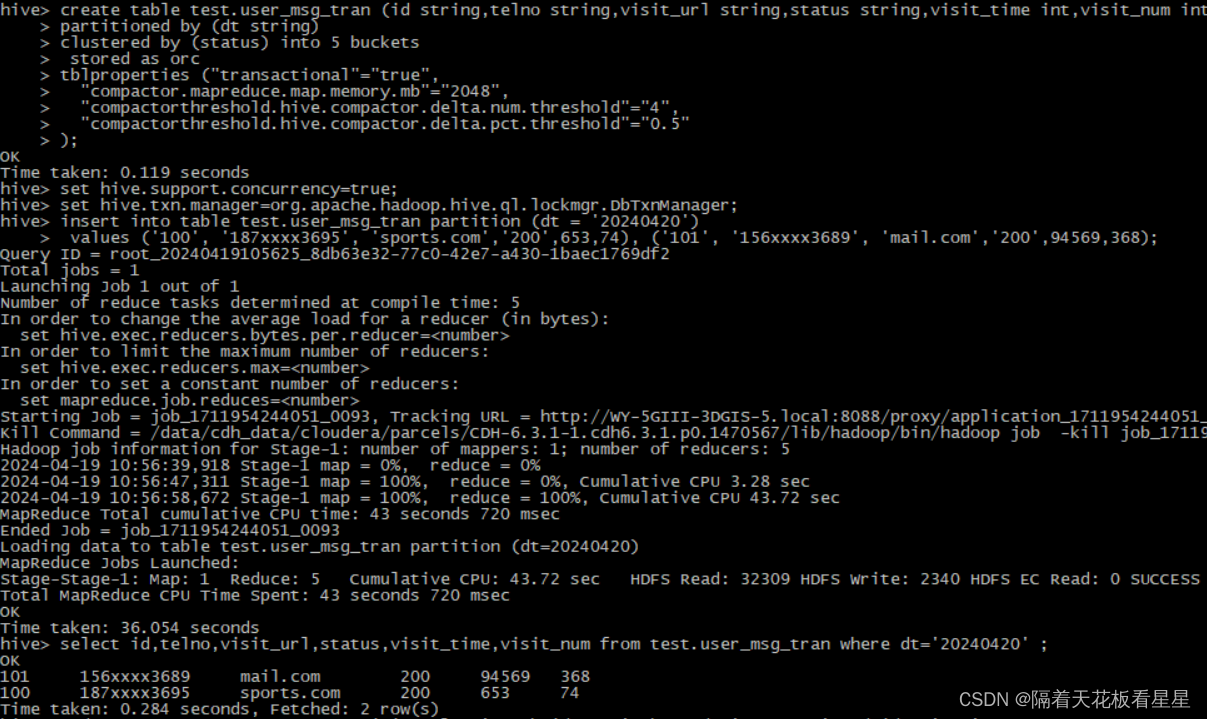
create table test.user_msg_tran (id string,telno string,visit_url string,status string,visit_time int,visit_num int)
partitioned by (dt string)
clustered by (status) into 5 bucketsstored as orc
tblproperties ("transactional"="true","compactor.mapreduce.map.memory.mb"="2048","compactorthreshold.hive.compactor.delta.num.threshold"="4", "compactorthreshold.hive.compactor.delta.pct.threshold"="0.5"
);
#环境参数设置
set hive.support.concurrency=true;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
#插入数据
insert into table test.user_msg_tran partition (dt = '20240420')values ('100', '187xxxx3695', 'sports.com','200',653,74), ('101', '156xxxx3689', 'mail.com','200',94569,368);
#查询
select id,telno,visit_url,status,visit_time,visit_num from test.user_msg_tran where dt='20240420' ;
修改
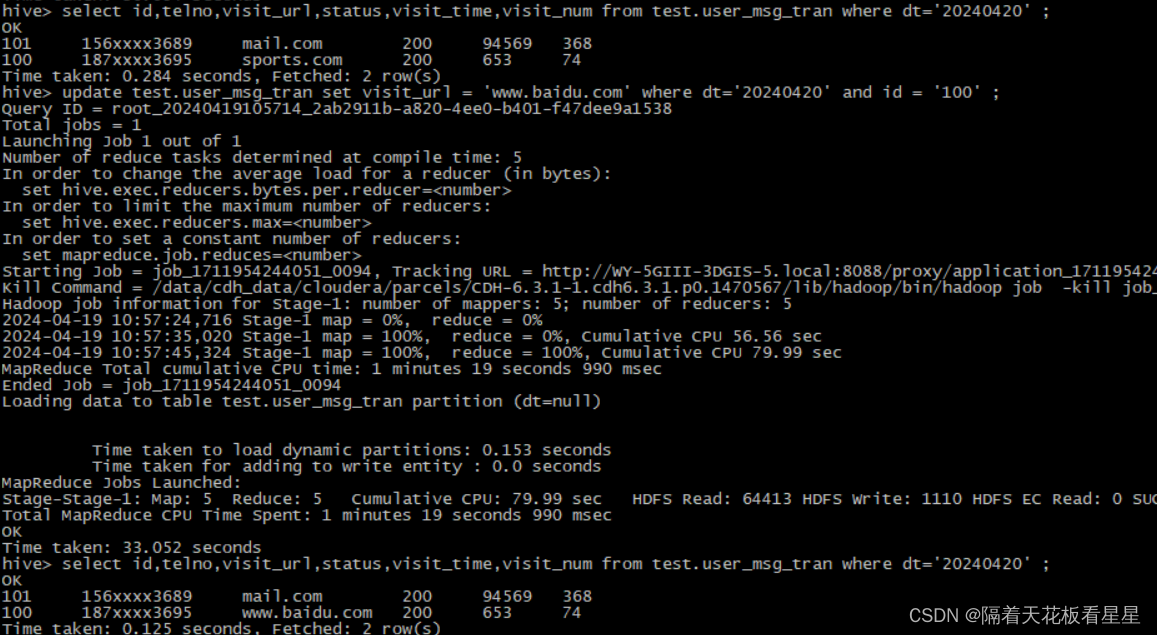
update test.user_msg_tran set visit_url = 'www.baidu.com' where dt='20240420' and id = '100' ;
#查询
select id,telno,visit_url,status,visit_time,visit_num from test.user_msg_tran where dt='20240420' ;
四、DELETE
只能对支持ACID的表执行删除
语法:
delete from tablename [where expression]
Hive 0.14中,成功完成,更改将自动提交。
删除时,矢量化将自动关闭,删除后的表仍然可以使用矢量化进行查询(在Hive中,矢量化是一种优化技术,它通过减少I/O操作和CPU计算来提高查询性能)
建议您在执行删除操作时将hive.optimity.sort.dynamic.partition=false设置为false,因为这会产生更高效的执行计划。
delete from test.user_msg_tran where id = '101' ;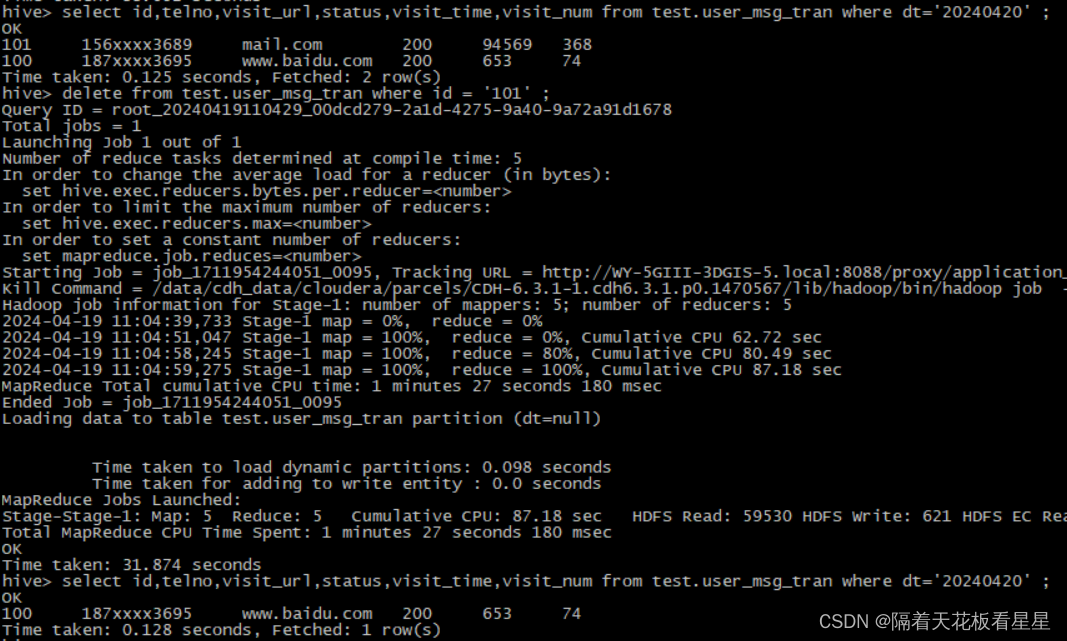
五、MERGE
只能对支持ACID的表执行合并
语法:
merge into <target table> as t using <source expression/table> as s
on <boolean expression1>
when matched [and <boolean expression2>] then update set <set clause list>
when matched [and <boolean expression3>] then delete
when not matched [and <boolean expression4>] then insert values<value list>
合并允许根据与源表的联接结果对目标表执行操作
从Hive2.2以后才提供该语法,成功完成此操作后,更改将自动提交。
如果ON子句使得源中有1行以上与目标中的行匹配,则 标准sql 要求引发错误。会导致性能下降,可以通过设置参数 hive.merge.cardinatity.check=false禁用检查,但如果禁用了检查,会导致数据质量问题。
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.support.concurrency=true;create table test.user_msg_tran_merge_source(id string,telno string,visit_url string,status string,visit_time int,visit_num int)
partitioned by (dt string)
stored as orc;insert into table test.user_msg_tran_merge_source partition (dt = '20240420')values ('666', '188xxxx4562', 'blog.csdn.net','200',632594,3894), ('888', '136xxxx5972', 'fanyi.youdao.com','200',7864,945), ('100', '188xxxx4562', 'test_merge.com','200',11111,121);merge into test.user_msg_tran as t using test.user_msg_tran_merge_source as s
on t.id = s.id and t.status = s.status
when matched and (t.visit_url != s.visit_url and s.visit_url is not null) then update set visit_url = s.visit_url
when matched and s.visit_url is null then delete
when not matched then insert values (s.id,s.telno,'visit_url',s.status,s.visit_time,s.visit_num);